

双线性模型(一)(RESCAL、LFM、DistMult)
今天开始,就要开始阅读双线性模型的文章了。大约有十七八篇文章,都是在综述经常见到的经典双线性模型,计划在八月中旬之前看完。虽然后面不会去做这类方法,但是作为这个领域的研究者,觉得还是应该读一读,否则总感觉自己的知识体系是有漏洞的。
开题报告里对于这一类模型的简介:
语义匹配模型采用基于相似性的打分函数,通过匹配实体和关系在嵌入向量空间的潜在语义衡量三元组事实成立的可能性。该类模型的典型代表有:RESCAL[28]、DistMult[29]、HolE[30]、ComplEx[31]、ANALOGY[32]、SEEK[50]等。RESCAL[28]又称双线性模型,该模型用向量表示实体,用矩阵表示关系,并通过自定义的打分函数捕捉三元组的内部交互。DistMult[29]通过将RESCAL的关系矩阵限制为对角矩阵对其进行了简化。HolE(Holographic Embedding)[30]结合了RESCAL的表示能力与DistMult的简洁高效,将实体和关系都表示为 空间中的向量,并定义了头尾实体进行交互的循环关联操作,操作结果与关系的表示进行匹配以计算三元组得分。ComplEx(Complex Embedding)[31]在DistMult的基础上引入复值嵌入,实体和关系的embedding不再位于实值空间而是复空间。此外ComplEx的三元组打分函数并非对称形式,对于非对称关系类型的三元组可根据头尾实体的位置关系得到不同的得分,从而可以更好地建模非对称关系。ANALOGY[32]在RESCAL的基础上进行扩展,以更好地建模实体和关系的推理属性。它采用了和RESCAL同样的双线性函数作为三元组打分函数。 SEEK(Segmented Embedding of Knowledge)[50]针对现有模型的表示能力与复杂度不能兼顾的问题,提出轻量级的嵌入框架,核心思想是对实体和关系进行分段嵌入,并通过段间组合计算三元组得分,可以在不增加模型复杂度的情况下获得较好的表示能力,并实现对于对称和非对称关系类型的处理能力。
RESCAL
【paper】 A Three-Way Model for Collective Learning on Multi-Relational Data
【简介】 这篇文章应该算是双线性模型的开山之作。是德国的一个团队发表在 ICML 2011 上的工作,比较老了,主要思想是三维张量分解。
模型
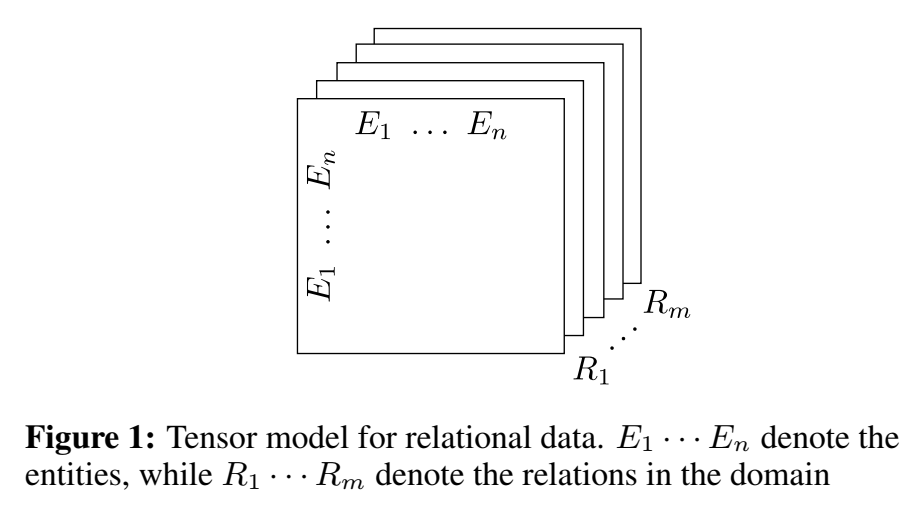
定义了一个 tensor,m 是关系数,n 是实体数,每个关系对应于 tensor 中的一个 slice,即一个矩阵,每个矩阵相当于表示图的邻接矩阵。位置元素为 1 代表两个实体之间存在这种关系,为 0 表示不存在。
对 tensor 进行分解:
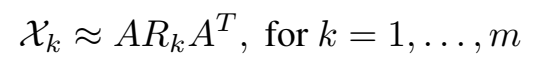
是 n×r 的矩阵,表示每个实体的隐性表示(latent-component representation), 是 r×r 的非对称矩阵,建模第 k 个属性/关系中的实体 latent component 的交互。
矩阵 和 通过约束最小化问题来计算:
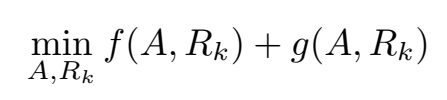
特别要提的是 是非对称矩阵,这样可以建模非对称关系,在同一个实体作为头实体或尾实体时会得到不同的 latent component representation。
其中,
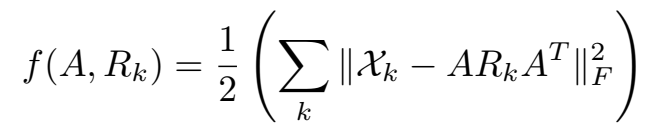
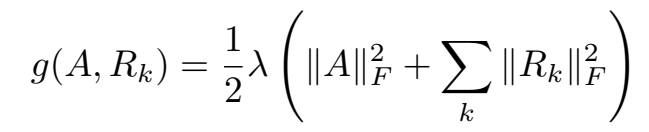
更具体地,
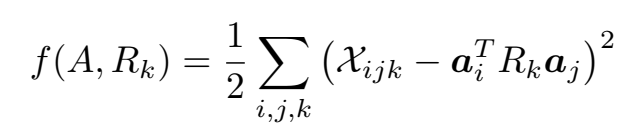 (其实贴图时可以不用定义高度)
(其实贴图时可以不用定义高度)
这样的分解机制可以利用相关实体提供的信息进行表示,类似推荐里的协同过滤,这里称为 collective learning,举了一个栗子:
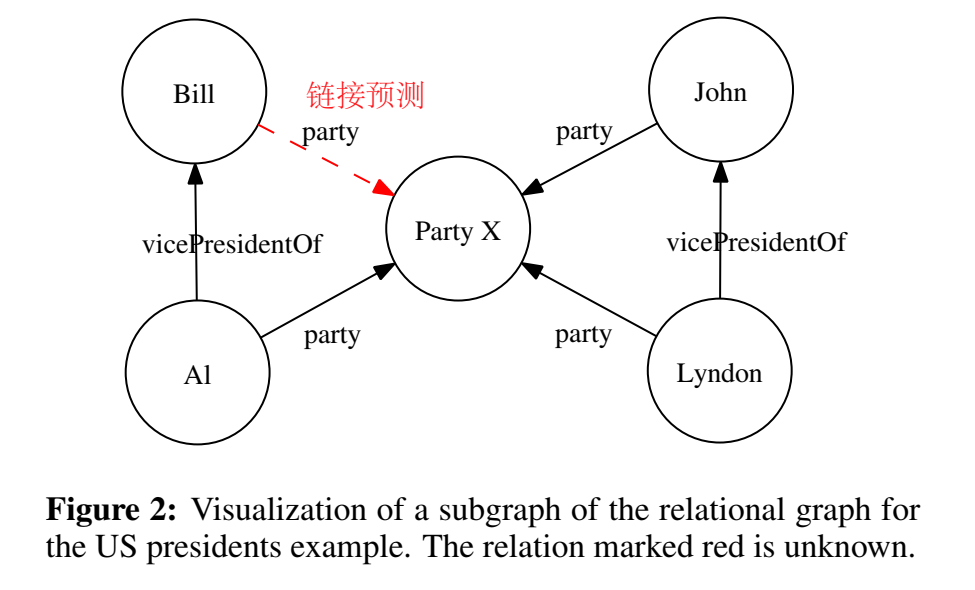
以上就是 Rescal 的核心思想了,后面有几个小节讲和其他方法的联系以及计算 factorization 的方法,没有仔细看。
实验
collective classification
该实验使用自建的政党数据集,包括 93 个实体和 3 个关系,因此构建了 93×93×5 的 tensor。政党分类效果如下。
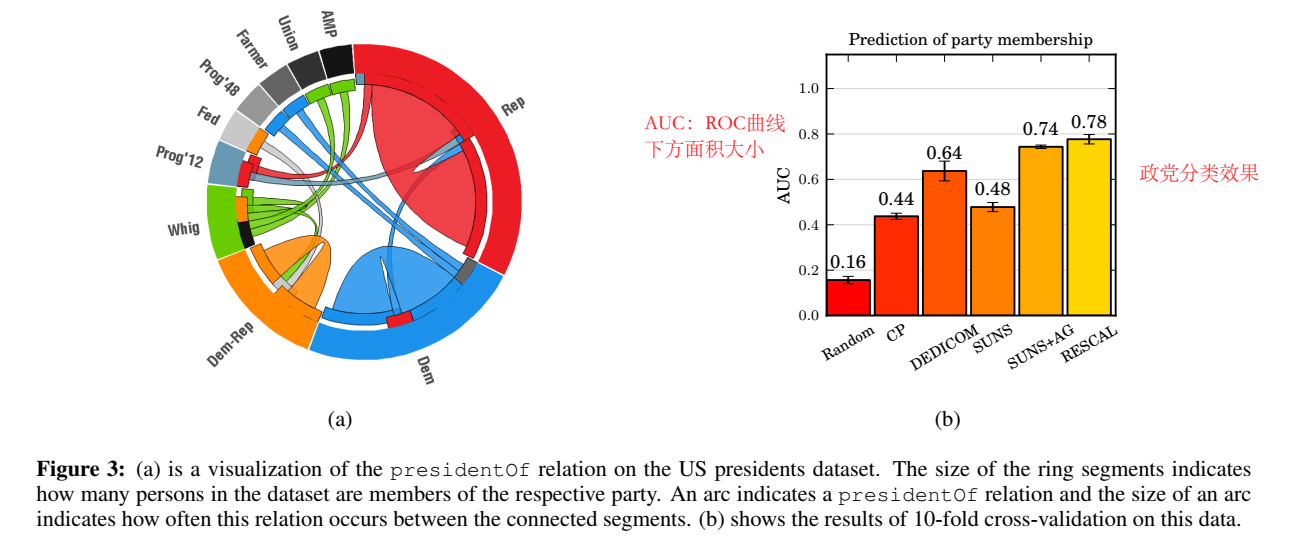
collective 实体消歧
实体消歧可以视为 isEqual 关系的链接预测,在 Cora 数据集上进行了实验:
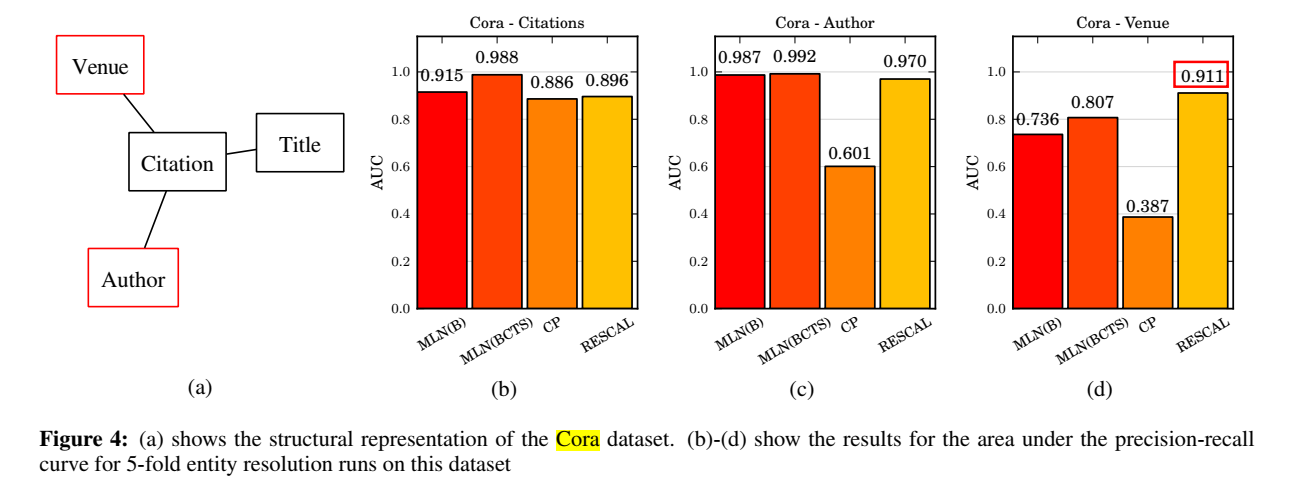
除了上述两个实验,还在 Kinships, Nations 和 UMLS 数据集上进行了链接预测,并在 Nations 数据集上进行了聚类实验。并在各个数据集上进行了与其他两个算法的运行效率的比较,不再贴图了。
代码
文章中说 Rescal 是用不超过 120 行的 Python/Numpy实现的,但没有给出代码。Pykg2vec 实现了 Rescal,但我没有看明白,实现的比较巧妙。因为也没有打算做这块,就不继续花时间研究了。
class Rescal(PairwiseModel):
"""
`A Three-Way Model for Collective Learning on Multi-Relational Data`_ (RESCAL) is a tensor factorization approach to knowledge representation learning,
which is able to perform collective learning via the latent components of the factorization.
Rescal is a latent feature model where each relation is represented as a matrix modeling the iteraction between latent factors. It utilizes a weight matrix which specify how much the latent features of head and tail entities interact in the relation.
Portion of the code based on mnick_ and `OpenKE_Rescal`_.
Args:
config (object): Model configuration parameters.
.. _mnick: https://github.com/mnick/rescal.py/blob/master/rescal/rescal.py
.. _OpenKE_Rescal: https://github.com/thunlp/OpenKE/blob/master/models/RESCAL.py
.. _A Three-Way Model for Collective Learning on Multi-Relational Data : http://www.icml-2011.org/papers/438_icmlpaper.pdf
"""
def __init__(self, **kwargs):
super(Rescal, self).__init__(self.__class__.__name__.lower())
param_list = ["tot_entity", "tot_relation", "hidden_size", "margin"]
param_dict = self.load_params(param_list, kwargs)
self.__dict__.update(param_dict)
self.ent_embeddings = NamedEmbedding("ent_embedding", self.tot_entity, self.hidden_size)
self.rel_matrices = NamedEmbedding("rel_matrices", self.tot_relation, self.hidden_size * self.hidden_size)
nn.init.xavier_uniform_(self.ent_embeddings.weight)
nn.init.xavier_uniform_(self.rel_matrices.weight)
self.parameter_list = [
self.ent_embeddings,
self.rel_matrices,
]
self.loss = Criterion.pairwise_hinge
def embed(self, h, r, t):
""" Function to get the embedding value.
Args:
h (Tensor): Head entities ids.
r (Tensor): Relation ids of the triple.
t (Tensor): Tail entity ids of the triple.
Returns:
Tensors: Returns head, relation and tail embedding Tensors.
"""
k = self.hidden_size
self.ent_embeddings.weight.data = self.get_normalized_data(self.ent_embeddings, self.tot_entity, dim=-1)
self.rel_matrices.weight.data = self.get_normalized_data(self.rel_matrices, self.tot_relation, dim=-1)
emb_h = self.ent_embeddings(h)
emb_r = self.rel_matrices(r)
emb_t = self.ent_embeddings(t)
emb_h = emb_h.view(-1, k, 1)
emb_r = emb_r.view(-1, k, k)
emb_t = emb_t.view(-1, k, 1)
return emb_h, emb_r, emb_t
def forward(self, h, r, t):
h_e, r_e, t_e = self.embed(h, r, t)
# dim of h: [m, k, 1]
# r: [m, k, k]
# t: [m, k, 1]
return -torch.sum(h_e * torch.matmul(r_e, t_e), [1, 2])
@staticmethod
def get_normalized_data(embedding, num_embeddings, p=2, dim=1):
norms = torch.norm(embedding.weight, p, dim).data
return embedding.weight.data.div(norms.view(num_embeddings, 1).expand_as(embedding.weight))
在 FB15k 数据集上尝试运行了一下,效果很差:
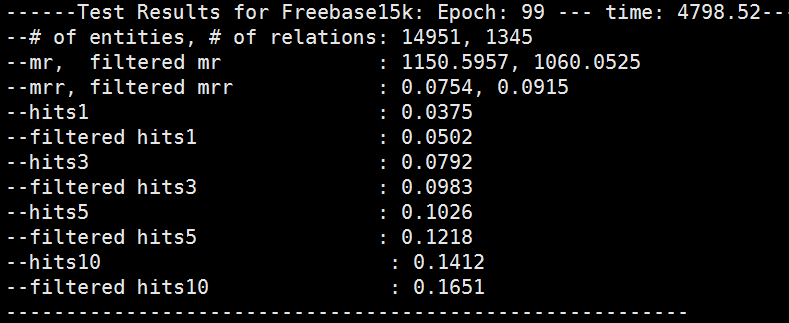
【小结】 本文用三维张量分解进行三元组嵌入。
LFM(Latent Factor Model)
【paper】 A latent factor model for highly multi-relational data
【简介】 这篇文章是法国的研究团队发表在 NIPS 2012 上的文章,还挂了 Antoine Bordes 的名字。文章提出了 LFM(Latent Factor Model),主要贡献有两点:一是定义了 unigram、bigram、trigram 三种方式组合的三元组打分函数;二是将关系矩阵分解为低阶矩阵的组合,这样可以实现参数共享。其实这种比较老的论文的表达方式、行文结构跟现在的论文都不太一样,再加上时间有限,所以没有看太明白。但这类模型终究是要过一遍的,就这样吧。
模型
文章在 intro 部分介绍了统计关系数据建模的现存难点:
- 频繁出现的关系类型只是一小部分(长尾现象)
- 数据存在噪声并且不完整
- 数据集规模有限
文章称 LFM 是基于概率的,明确考虑了数据的不确定性。这里的不确定性应该不是指的实体和关系包含语义的不确定性,只是指对三元组进行概率打分。
早期的论文中三元组表示都是(subject, relation, object),若三元组成立,写作 。
表示及打分函数
logistic 模型进行了如下的定义:
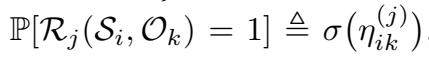
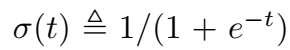
其中, 是一个线性函数:
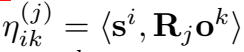
贡献一: 对打分函数 进行了重新定义
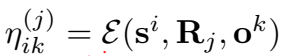
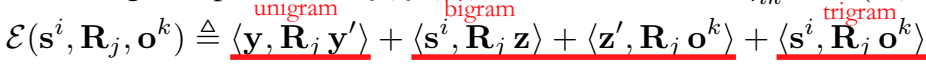
贡献二: 对关系矩阵进行分解
当关系数量比较多时,每个关系下的样本很少,容易引起过拟合。之前的模型曾经使用两种解决方法,一是聚类,二是用向量表示关系。与 RESCAL 的使用一个通用矩阵进行参数化的方法不同,本文提出的解决方法是将关系矩阵分解为 d 秩一矩阵(不知道这里的“一矩阵”是不是指对角矩阵)。
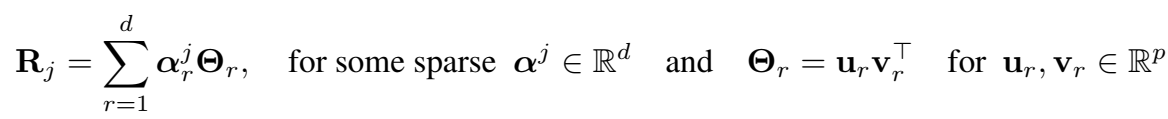
分解的稀疏性和 可以保证不同关系的参数共享。
Loss
模型训练的目标是最大化下面的 likelihood:
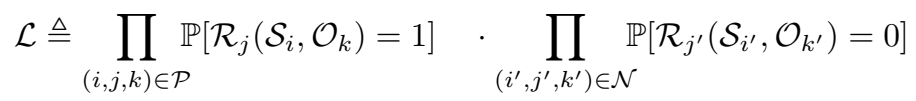
经过推导,可以得到 log-likelihood:
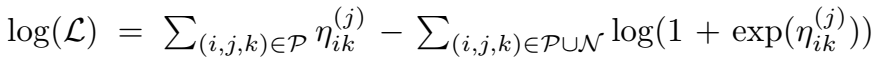
上午推导了一下,前半部分没有对上,可能中间有近似约减消掉的项。
训练目标等价于最小化负的 log-likelihood:
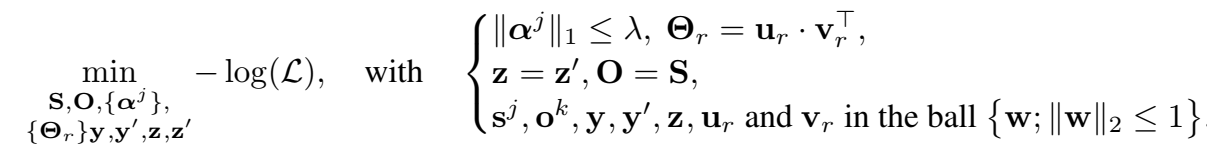
实验
和 RESCAL 一样,在 Kinships、UMLS、Nations 数据集上进行了实验,与 RESCAL、MRC 和 SME 三个 baseline 对比了 AUC 和 log-likelihood。
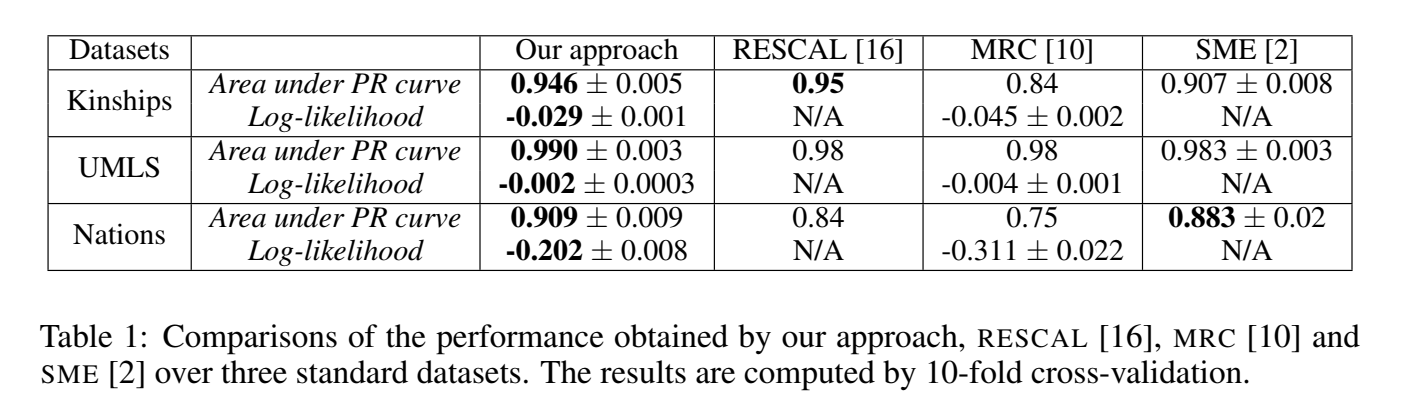
除了进行关系数据建模,实验部分还学习了动词的语义表示。这部分没细看。
代码
没有代码。
【总结】 本文定义了 unigram、bigram、trigram 进行组合的线性打分函数,并对关系矩阵进行分解实现参数共享。
DistMult
【paper】 Embedding entities and relations for learning and inference in knowledge bases
【简介】 这篇文章是康奈尔大学和微软的研究者发表在深度学习顶会无冕之王 ICLR 2015 上的工作,文章提出了 DistMult。模型的改进微乎其微,就是把双线性模型的关系矩阵限制为了对角矩阵,然后重点是用 embedding-based 的方法做了规则挖掘。看文章署名的话应该都是中国人,行文结构也很典型,因此看起来感觉比上一篇舒服多了,大部分内容基本能看懂。
Intro 与 Related Work
文章将 TransE 和 NTN 都归类为神经网络,并且 motivation 来源于这两个模型:
- 不同的设计如何影响学习结果
- 链接预测实验只是间接展示低维 embedding 的效果,关系属性如何捕捉以及如何作用很难解释。
文章贡献如下:
- 提出通用框架整合现有模型
- 链接预测实验评价
- 挖掘逻辑规则
(看 related work 有感:第一点是,一直不知道 related work 该写什么、怎么写。我写论文一个很大的问题是一开始的引入总是从很大很宏观的角度,本想由浅入深引到自己的工作上,但是由于一开始没有聚焦,并且一写开就刹不住车,所以会有一种顾左右而言他、文不对题的感觉,小论文、开题报告里都有这个问题。这篇的 related work 就是由浅入深,先列出 multi-relational learning 的一些方法,然后详细介绍了 NTN,然后引到自己的规则抽取工作(虽然中间少了点衔接)。以后我在写 related work 也要再聚焦一些,多说与自己工作有密切关联的相关工作;第二点是 DistMult 这篇文章,模型本身的改进几乎没有,很鸡肋,但是它把展示的重点放在了规则挖掘上,这就是扬长避短的作用了,就像衣服的穿搭,身材不好也没有关系,关键是如何凸显优势、弱化劣势。)
模型
模型部分文章说,呈现的是一个通用的 NN 框架,讨论了不同设计的选择,并对比了效果。其实都是比较 naive 的东西,没什么新的。
实体表示
实体表示就是用 “one-hot” 向量查询实体矩阵:
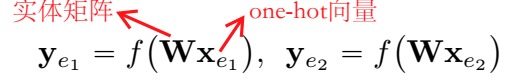
NTN 用预训练的词向量做为实体的初始表示。
关系表示
关系的表示通常反映在打分函数中,打分函数通常被定义为线性、双线性或二者组合的转换函数:
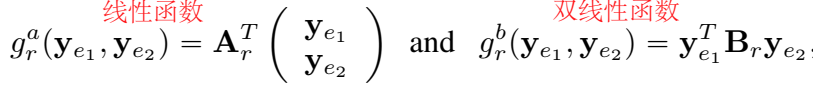
几个模型的关系表示及打分函数:

本文只考虑最基本的双线性打分函数:
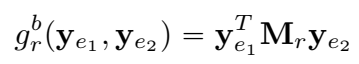
本文提出了将关系矩阵 限制为对角矩阵(DistMult),这样可以将双线性模型的参数量减少到与 TransE 相同。
上面提出的通用框架同样适用于深层语义模型和多层 NN。
参数学习
和 TransE 一样使用负采样操作构建负样本,并定义 margin-loss:
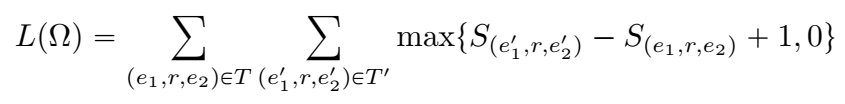
实验
链接预测
在 WN 和 FB15k 上进行链接预测实验。
比较了五个模型(按照复杂度降序排列)的效果:
- 4个 tensor slice 的 NTN
- Bilinear + Linear:一个tensor slice 的 NTN,且只有线性层
- TransE
- Bilinear:最基本的双线性打分函数
- Bilinear-diag:关系矩阵限制为对角矩阵的双线性模型
五个模型效果如下:
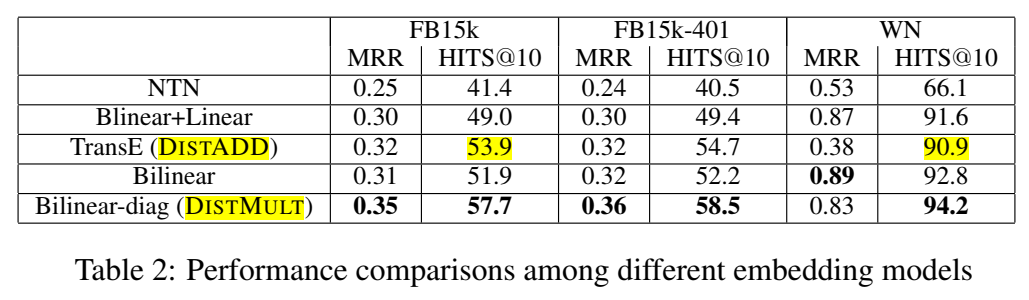
NTN 最复杂,但是效果最差,相反,最简单的 DistMult 效果最好。但是文中也提到了,将关系矩阵限制为对角矩阵丧失了对非对称关系建模的能力,这是 DistMult 的缺陷。
还在不同的关系类型上对比了乘法(bilinear-diag,即 DistMult)和加法(TransE,DistAdd)的特征交互的效果。

显然,DistMult 比 DistAdd 效果要好。
此外,还试验了使用非线性的投影函数 tanh,并使用预训练词向量进行实体表示的初始化。在预测实体时,利用实体类型信息进行结果过滤。
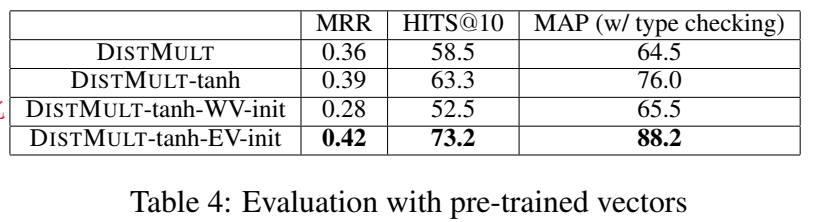
规则抽取
规则抽取是本文的重要工作。逻辑规则有很重要的意义:
- 可用于推断新事实进行 KB 补全
- 优化数据存储,只存储逻辑规则比存储事实节省空间
- 支持复杂推理
- 为推断结果提供解释
文中说 embedding-based 的规则挖掘不必受 KB 规模的影响,但后面做实验还是只做了两跳和三跳的,不可能不受 KB 规模的影响。
该任务的目的就是挖掘如下的 Horn 规则:
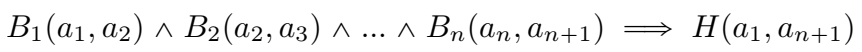
用两种方式建模关系的组合:关系用向量表示的用加法(欧式距离),用矩阵表示的用乘法(Frobenius 范数)。
规则挖掘算法:

挖掘结果如下,横坐标代表挖掘的数量,纵坐标代表挖掘的质量/精度,DistMult 的效果是好于 AMIE 的。
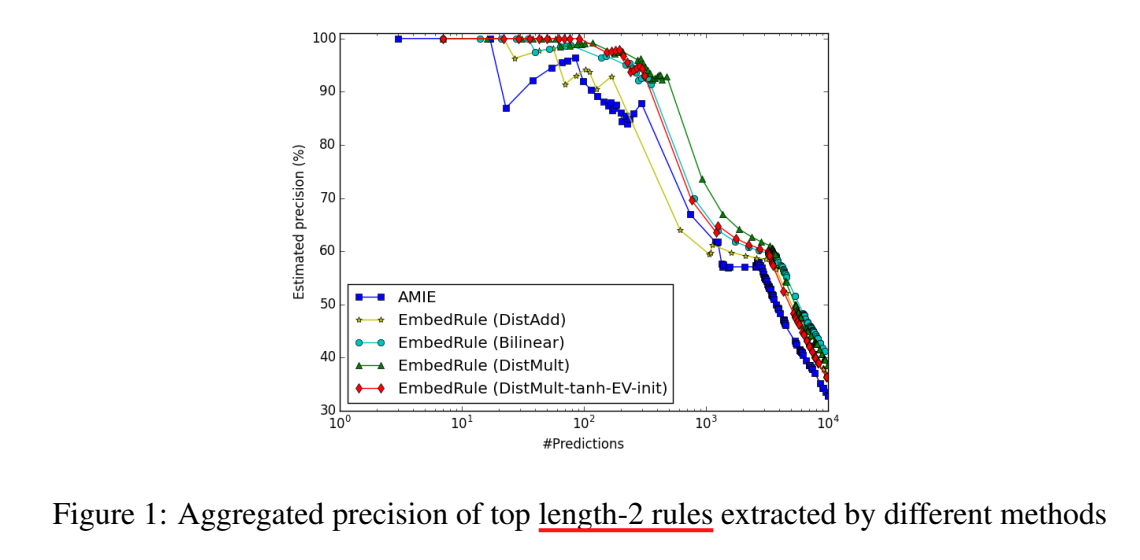
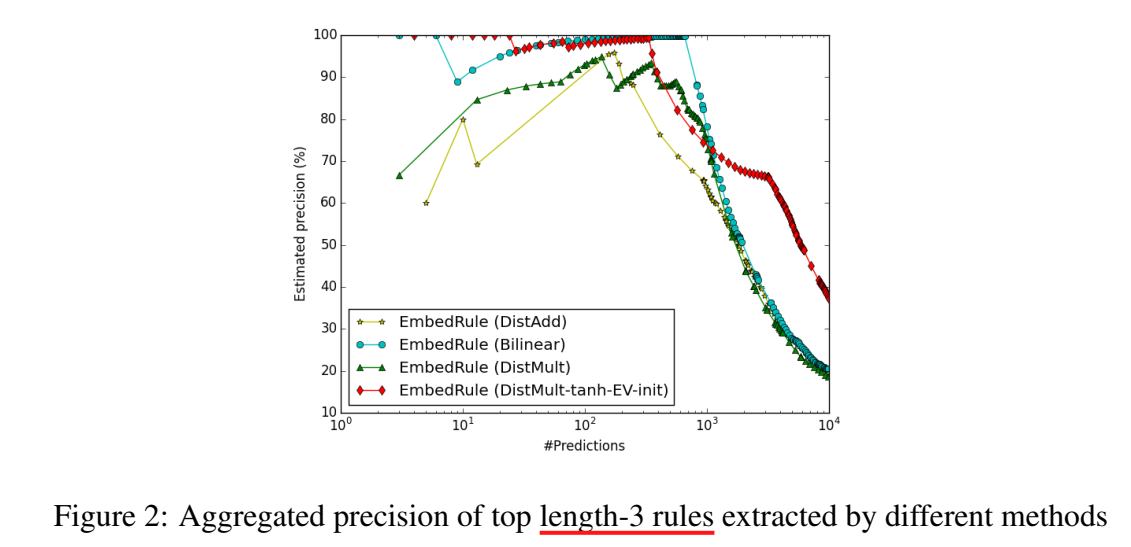
并且,bilinear 在长路径下效果更好。
代码
原文没有给出代码,pykg2vec 给出了 DistMult 的实现
class DistMult(PointwiseModel):
"""
`EMBEDDING ENTITIES AND RELATIONS FOR LEARNING AND INFERENCE IN KNOWLEDGE BASES`_ (DistMult) is a simpler model comparing with RESCAL in that it simplifies
the weight matrix used in RESCAL to a diagonal matrix. The scoring
function used DistMult can capture the pairwise interactions between
the head and the tail entities. However, DistMult has limitation on modeling asymmetric relations.
Args:
config (object): Model configuration parameters.
.. _EMBEDDING ENTITIES AND RELATIONS FOR LEARNING AND INFERENCE IN KNOWLEDGE BASES:
https://arxiv.org/pdf/1412.6575.pdf
"""
def __init__(self, **kwargs):
super(DistMult, self).__init__(self.__class__.__name__.lower())
param_list = ["tot_entity", "tot_relation", "hidden_size", "lmbda"]
param_dict = self.load_params(param_list, kwargs)
self.__dict__.update(param_dict)
num_total_ent = self.tot_entity
num_total_rel = self.tot_relation
k = self.hidden_size
self.ent_embeddings = NamedEmbedding("ent_embedding", num_total_ent, k)
self.rel_embeddings = NamedEmbedding("rel_embedding", num_total_rel, k)
nn.init.xavier_uniform_(self.ent_embeddings.weight)
nn.init.xavier_uniform_(self.rel_embeddings.weight)
self.parameter_list = [
self.ent_embeddings,
self.rel_embeddings,
]
self.loss = Criterion.pointwise_logistic
def embed(self, h, r, t):
"""Function to get the embedding value.
Args:
h (Tensor): Head entities ids.
r (Tensor): Relation ids of the triple.
t (Tensor): Tail entity ids of the triple.
Returns:
Tensors: Returns head, relation and tail embedding Tensors.
"""
h_emb = self.ent_embeddings(h)
r_emb = self.rel_embeddings(r)
t_emb = self.ent_embeddings(t)
return h_emb, r_emb, t_emb
def forward(self, h, r, t):
h_e, r_e, t_e = self.embed(h, r, t)
return -torch.sum(h_e*r_e*t_e, -1)
def get_reg(self, h, r, t, reg_type="F2"):
h_e, r_e, t_e = self.embed(h, r, t)
if reg_type.lower() == 'f2':
regul_term = torch.mean(torch.sum(h_e ** 2, -1) + torch.sum(r_e ** 2, -1) + torch.sum(t_e ** 2, -1))
elif reg_type.lower() == 'n3':
regul_term = torch.mean(torch.sum(h_e ** 3, -1) + torch.sum(r_e ** 3, -1) + torch.sum(t_e ** 3, -1))
else:
raise NotImplementedError('Unknown regularizer type: %s' % reg_type)
return self.lmbda*regul_term
【总结】 本文提出了 neural-embedding 的通用框架,并把 NTN、TransE 等模型套在框架里进行对比;提出了将关系矩阵限制为对角矩阵的 DistMult;并用 embedding-based 方法挖掘逻辑规则。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix