生成对抗网用于 KGE(KBGAN)
KBGAN
paper: KBGAN: Adversarial Learning for Knowledge Graph Embeddings
论文
本文是清华大学的一名同学发表在 NAACL(虽然是 C,但是是北美的 ACL) 2018 上的一篇文章,提出了 KBGAN,首次使用生成对抗网的思想做 KGE,效果一般,但是想法很新颖。具体是用两个 KGE 模型,一个作为生成器,生成高质量的负样本,用于第二个模型的训练。
负采样的重要性(普通均匀随机采样的局限)
普通的负采样方法,对正样本三元组的头实体或尾实体从实体集中随机采样替换,生成的负样本是很明显的错误样本,很容易通过实体的类型区分开来,比较“高级”的负样本是尽量“替换同类型实体”的负样本三元组。
Trans 系列 KGE 模型的 loss 是 margin-based 的,训练时候正负样本是一对一的,不好的负采样方法会使它们性能差;而双线性模型(如 ComplEx 和 DistMult)训练时一个正样本对应多个负样本,负样本的好坏对其没有太大的影响。
生成对抗网
生成对抗网(Generative Adversarial Network, GAN)最初提出被用于图像领域。一个 GAN 包括两部分:生成器(generator)和判别器(discriminator),生成器接受噪声输入,尽量生成看起来 real 的图像来欺骗判别器,判别器的作用是对生成器给出的样本做分类,尽量识别出生成器给出的样本是负样本。
将生成对抗的思想引入到 KGE,本文的具体做法是对每个 KGE 任务,使用两个模型,一个模型(双线性模型如 DistMult 或 ComplEx)用作生成器,生成高质量的负样本,另一个模型(TransE 或 TransD)做判别器,用正样本和生成器给出的负样本训练 embedding。生成器选用 基于概率的、log-loss 的模型(双线性模型,会输出 softmax 概率分布),给出的概率分布可以用于选择高质量的负样本;判别器选用 基于距离的、margin-loss 的模型,不太同于 GAN 中的分类器。
训练目标的两种类型
不同嵌入模型的本质就是采用不同的打分函数,并为其赋不同的解释,不同的打分函数导致不同的训练目标。目标函数主要有如下两类:
- 第一种是 Trans 系列普遍采用的 margin-based 的 loss:
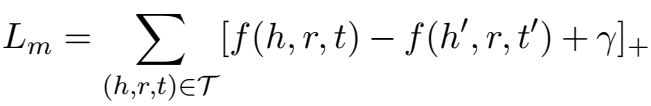
- 第二种是双线性模型普遍采用的 log-softmax 的 loss:
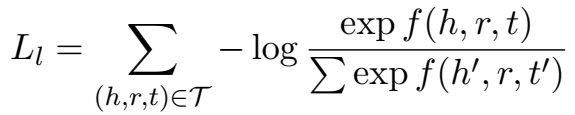
生成对抗训练 for KGE

生成器对从实体集中随机采样的子实体集打分,选择得分最高的(图中例子是“Florida”),构建负样本,输送到判别器进行训练。
判别器的 loss 就是普通的 marginal loss,负样本是生成器提供的:
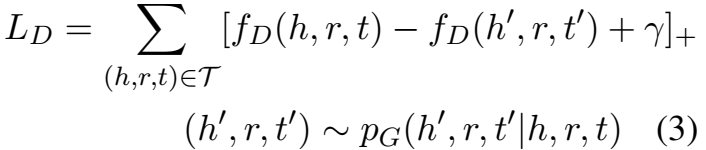
生成器的目标是对判别器对其提供的三元组的距离得分最小化,具体定义为最大化负样本的负得分期望:
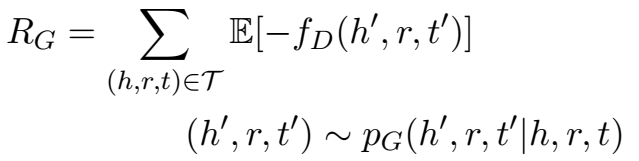
\(R_G\) 涉及离散的采样步骤,不能用梯度下降训练,因此文章采用“Policy Gradient Theorem”获取 \(R_G\) 的梯度:
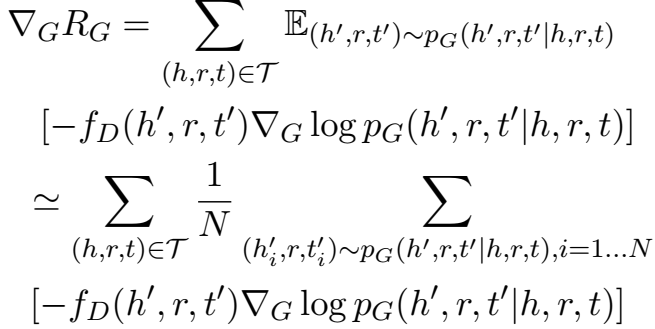
“Policy Gradient Theorem” 起源于强化学习(RL)领域,文中给出了本文模型和 RL 类比解释:生成器被视为一个 agent,与环境(environment)交互执行 action,目标是最大化从环境中获得的奖赏(reward);判别器可以被视为环境,三元组样本 \((h,r,t)\) 是状态(state),决定 agent 采取什么 action;\(p_G(h',r,t'|h,r,t)\) 是 policy,指导 agent 如何选择 action;\(-f_D(h',r,t')\) 作为奖赏。与一般的 RL 过程不同的是,这里的 action 并不影响 state,而是在一个 action 结束后开始一个新的不相关的 state,所以本文的模型可以被视为 RL 的一个简单的特例(one-step RL)。【这里的这段解释非常 plausible,可以学习一下~】
模型为 \(-f_D(h',r,t')\) 增加了一项 \(-b(h,r,t)\)(没看懂为什么),\(b\) 设置为训练集上的平均奖赏。
生成器输出的概率分布为:
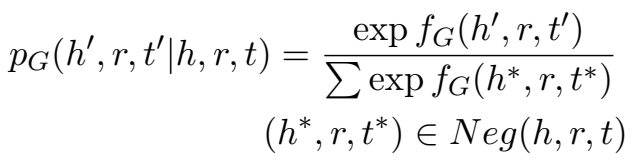
整体训练算法:

生成器和判别器都需要预训练。
实验
- 链接预测
在三个数据集:FB15k-237、WN18 和 WN18RR 上进行了链接预测实验。
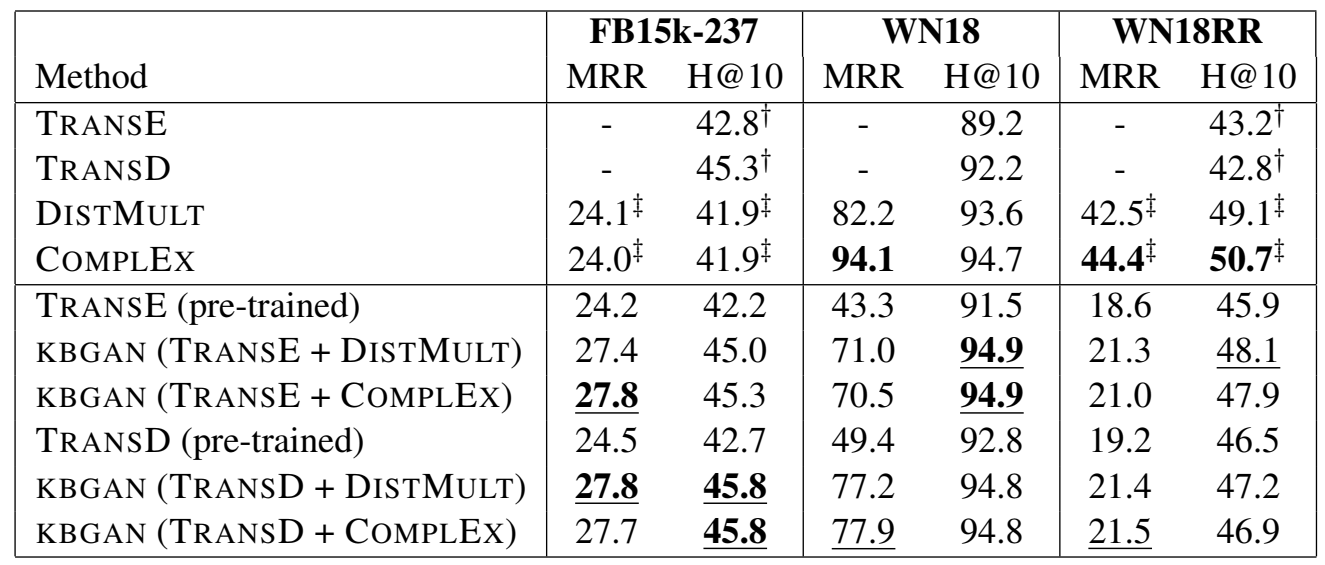
讲真从结果看,加了 KBGAN 比原来模型的效果并没有提升很多,主要还是胜在了思想上了吧。
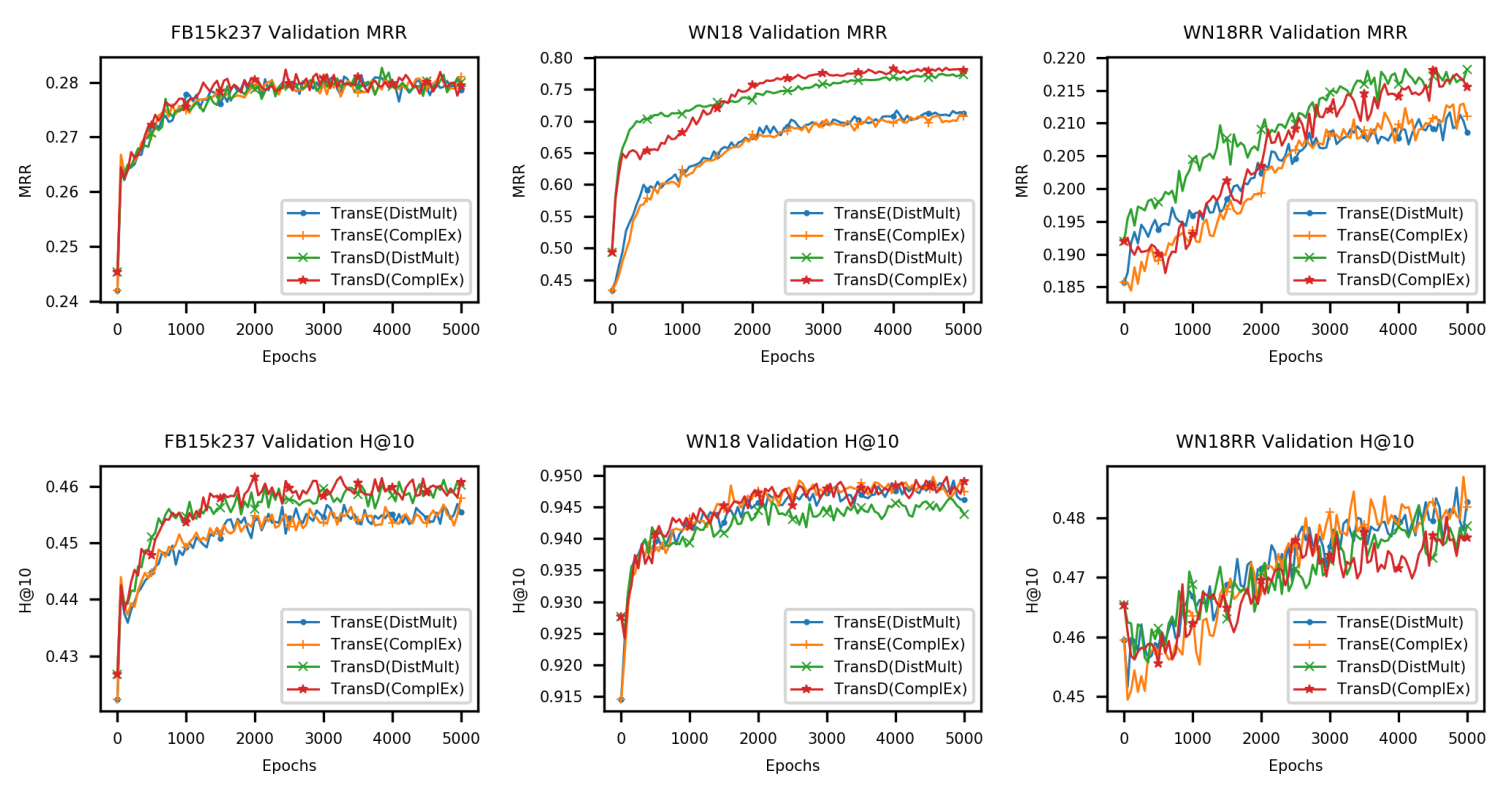
训练了几千轮,在 WN18RR 上还没有完全收敛。
- case study
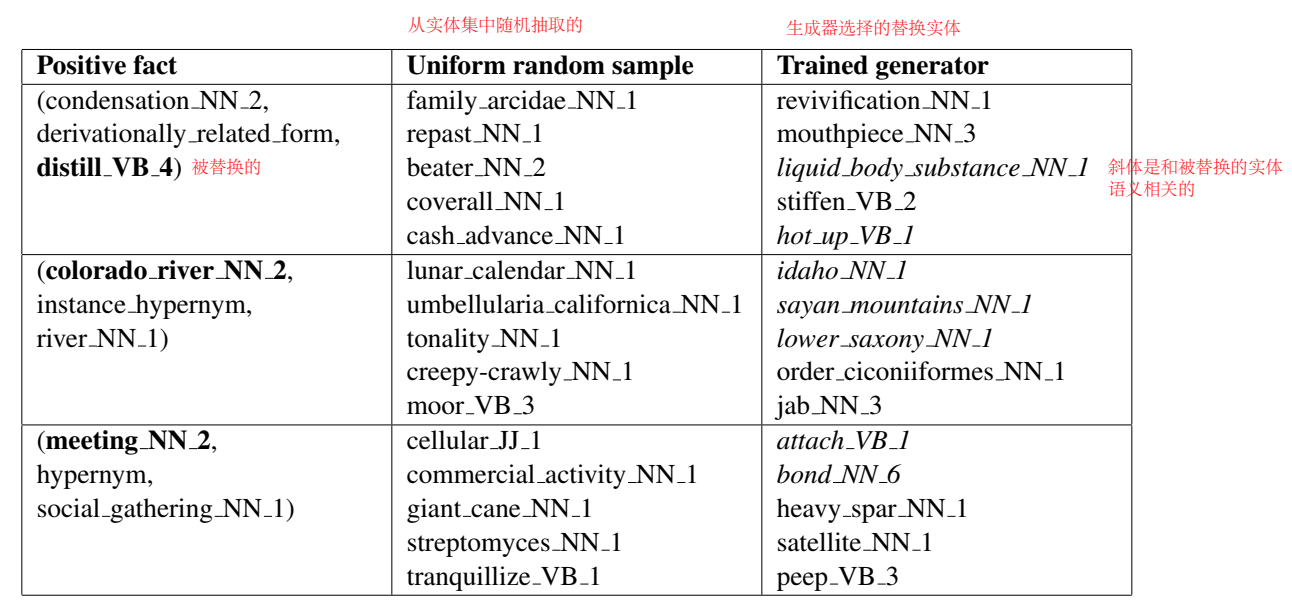
相比于从实体集中随机选择实体构建负样本,生成器选择的替换实体能选择与被替换实体更语义相关的实体做替换(斜体),这样高质量的负样本会一定程度上提升模型的效果。
代码
文章给出了代码:https://github.com/cai-lw/KBGAN 。
运行文章中给出的代码,在 FB15k-237 上预训练了 TransE 和 DistMult,然后用两个模型进行对抗训练,结果如下:

结果和论文中展示的结果相差无几,甚至还好一点点。训练时间也非常快,在 1080 上很快就训练好了。这算是第一次正儿八经的论文结果复现成功吧(祝贺~
\\^_^//)。
小结: 文章提出用 GAN 的思想做 KGE,将对抗学习的思想引入 KG,用生成器生成高质量的负样本用于判别器的学习,训练过程采用强化学习的思想解释,想法非常新颖。
