神经网络模型(一)(ProjE、TransEdge、TransGate)
这篇博文要记录的是三个基于神经网络的模型:ProjE、TransEdge、TransGate。最近看的论文不像一开始的 Trans 系列那么简单了,需要多花些时间和功夫。
ProjE
paper: ProjE: Embedding Projection for Knowledge Graph Completion
论文
这篇文章是之前没有听说过的研究者——美国圣母大学(University of Notre Dame)的两名作者发表在 AAAI 2017 上的工作。这是我正儿八经读的第一篇基于神经网络的模型,要好好记录一下。文章提出了 ProjE 模型,思想是:输入的一个实体 e 和一个关系 r,它们的 embedding 经过组合,得到一个 target vector,然后将候选实体“投影”(其实就是矩阵相乘再过激活函数)到该目标向量上,得到相似度得分(即三元组得分)。
模型架构
ProjE 的训练思想是这样的,给定两个输入 h、r 的 embedding,将预测任务视为候选实体的排序任务(其他的模型在测试时才会这样),因此将每个候选实体投影到由两个输入的 embedding 组合而生的 target vector 上:
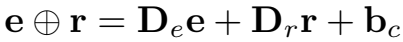
\(D_e\) 和 \(D_r\) 是 \(k×k\) 的对角矩阵,\(b_c\) 是偏置。
然后将候选实体投影到上面得到的 target vector,得到三元组得分:
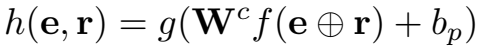
其中,\(f\) 和 \(g\) 是两个激活函数,\(W_c\) 是候选实体矩阵,\(b_p\) 是投影操作的偏置项。\(h(e,r)\) 最后得到的结果是一个得分向量,向量的每个元素代表 \(W_c\) 中的候选实体与 target vector \(e \bigoplus r\) 的相似性。
网络可视化展示
ProjE 可以被视为一个两层的神经网络,包括一个组合层(combination layer)和一个投影(输出)层。下图是网络结构的可视化展示:
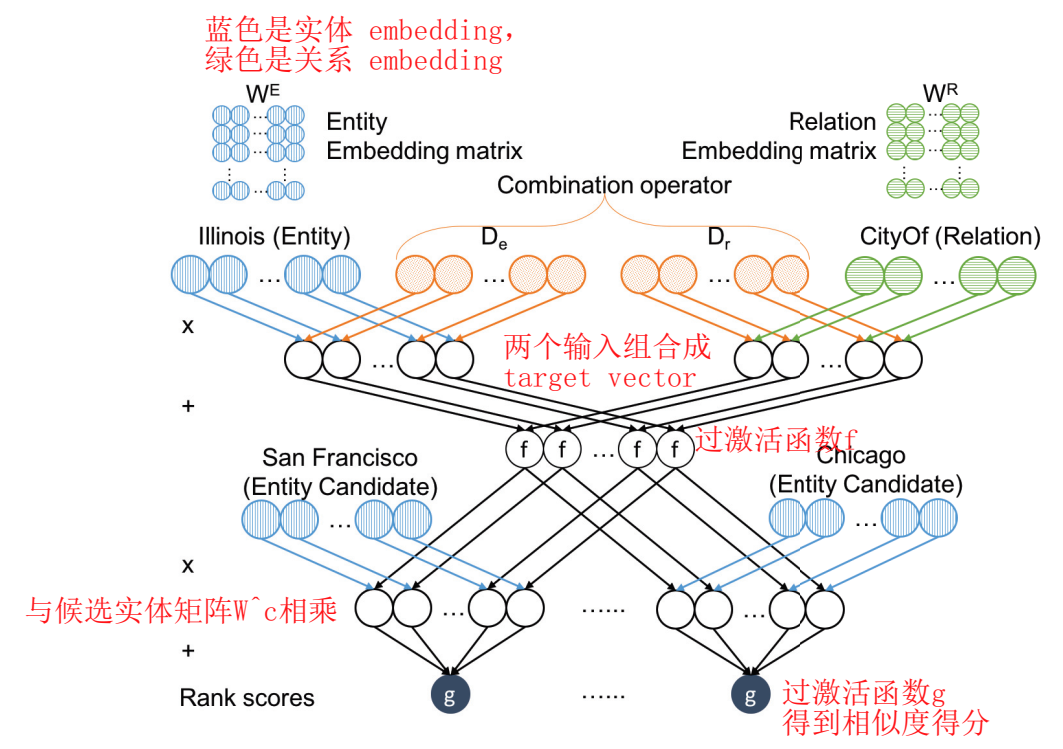
图中的例子给出了尾实体 Illinois 和关系 CityOf,需要预测头实体,计算每个候选头实体的得分。其中,蓝色圆点代表的 \(W^E\) 是实体的 embedding 矩阵,绿色圆点代表的 \(W^R\) 是关系的 embedding 矩阵,橙色圆点是用于 combination 操作的两个对角矩阵。得到 target vector 后,过激活函数 \(f\),为了方便展示,图中只给出了两个候选实体示例 San Francisco、Chicago,候选实体矩阵与 \(f\) 的结果相乘后,加偏置,然后过激活函数 \(g\) 得到相似度得分向量。
loss 定义
损失函数的定义形式与之前 Trasns 系列的 pairwise 的形式完全不同,定义了两种 loss 计算方法。
- ProjE_pointwise
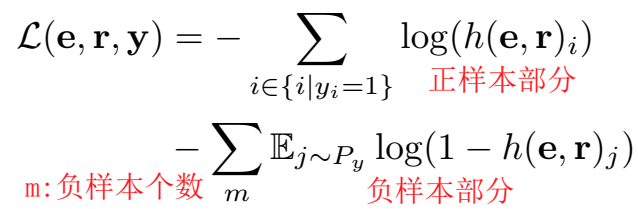
定义正样本的候选实体的标签为 1,负样本的标签为 0。可以将该任务直观地试做多分类任务,对于给定的 h 和 r,候选实体列表作为候选类别,判定经过组合后的 h 和 r 属于哪几个实体类别。训练目标就是最大化打分向量 \(h(e,r)\) 和二值的标签向量之间的似然。公式中前半部分是标签为 1 的样本对应的部分,正确候选实体在该部分的得分应该接近标签 1;公式的后半部分是标签为 0 的样本对应的部分,错误的候选实体标签为 0,在这部分得分为0。
这种 loss 计算方式是 pointwise 的,不像 margin-based 的 loss,样本成对出现,每个正样本对应一个负样本,正负样本的对应比例不一定是 1。在这种方式下,定义两个激活函数 \(g\) 和 \(f\) 分别为 \(sigmoid\) 和 \(tanh\),因此,三元组打分函数为:
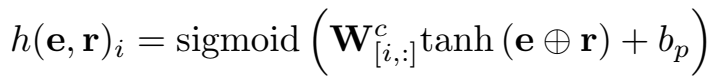
- ProjE_listwise
由于 softmax 回归 loss 在多分类的图像标注任务中表现良好,因此这里也定义了用 softmax 激活函数计算的 loss,这种方式称为 listwise。
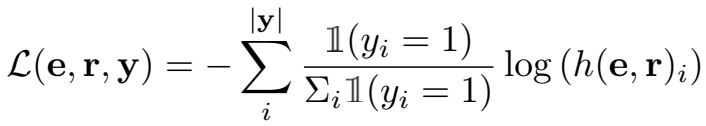
这里,只用正样本候选实体计算 loss,对正样本候选实体平均分配概率,计算加权得分和作为 loss。
两个激活函数 \(g\) 和 \(f\) 分别设为 \(softmax\) 和 \(tanh\),因此打分函数为:
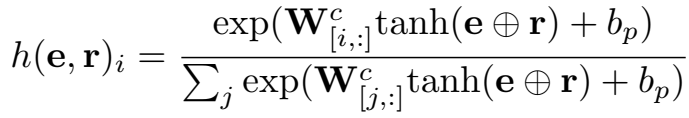
候选样本的负采样
如果将实体集中的所有实体都作为候选实体的话计算量会非常大,因此使用 Word2Vec 采用的负采样方法,区实体集 \(W^E\) 中的一部分(子集)作为候选实体集 \(W^c\),用负采样来减少训练时模型需要的候选实体的数量。采样概率遵循 \(P_y \sim B(1,p_y)\) 的二项分布,\(p_y\) 是负样本被采样的概率,\(1-P_y\) 是不被采样的概率,概率采样决定该候选实体是否被选入 \(W^c\)。
实验
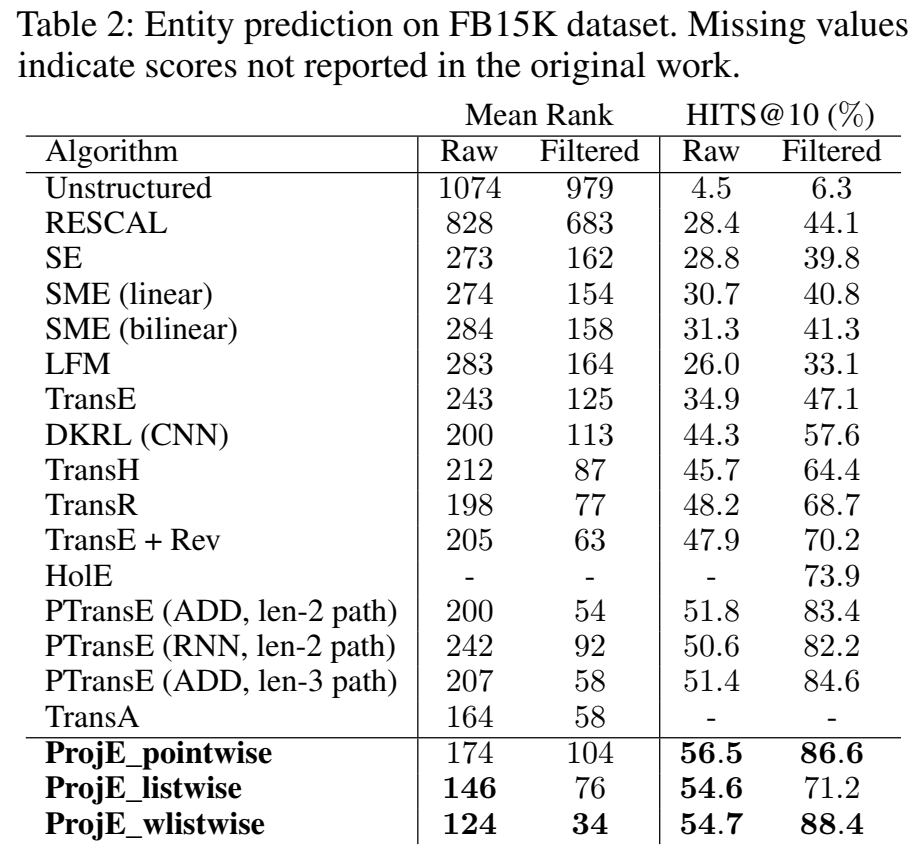
进行了实体预测、关系预测和本文新提出来的 "fact checking task" 作为实验。链接预测的数据集使用 FB15K。
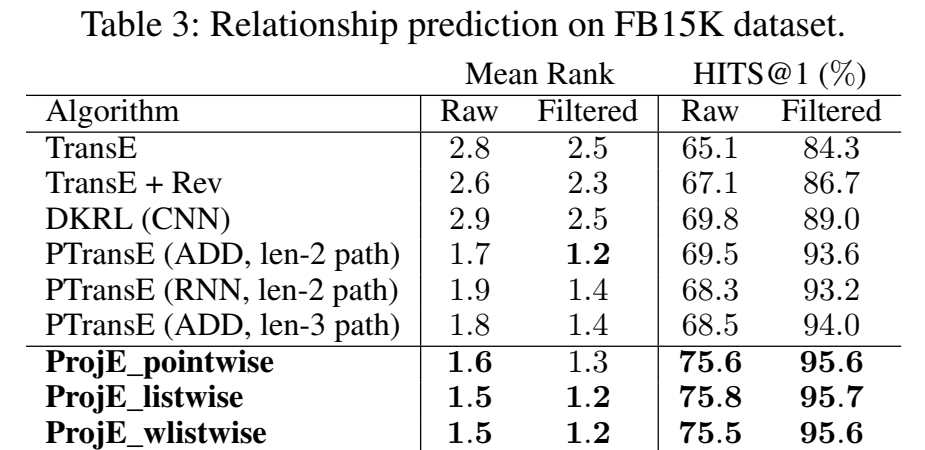
在 DBpedia 和 SemMedDB 数据集上的 "fact checking test" 任务结果。这个任务没有细看,不知道它和链接预测有什么本质的区别。
代码
文中给出了代码,最新的版本是:https://github.com/bxshi/ProjE
后面要读到的差不多都是基于神经网络做的模型了,应该是使用框架实现,可读性会比较强,有时间都应该仔细学习一下代码、尝试运行。读论文的时候总是求快,不想去仔细看代码,所以代码能力越来越差,这个毛病要改一改,以后框架实现的论文代码一定要尝试运行一下,这样才能对文章有更深入更具体的理解。
在尝试运行代码的过程中,可能会遇到各种问题,如需要搭建环境、装各种包,在搭环境的过程中可能会遇到各种问题,甚至一搞就是一天,往往因为没有这样的时间而选择放弃运行代码,需要做这个模型的时候解再决这些问题,是比较有意义的。这时候,只阅读代码,学习其实现方式而暂时不去运行,或许是一种折衷的办法。
小结: 这篇文章虽然不是大牛团队提出来的,但感觉做的内容还是很不错的。可能因为是中国人写的,文章本身读起来也很容易理解。一点小小的不足可能就是章节内部结构划分不是很清晰,加上标号可能会清楚一些。如果看过一篇文章立刻就放过的话,很快就会忘掉,写笔记的过程就是再次理解一遍的过程,看代码就是第三次理解的过程,模型梳理归纳画思维导图的过程就是第四次理解的过程,最终这些就会转化成知识体系的一部分,坚不可摧,也是面对新论文时候的力量和底气。
TransEdge
paper: TransEdge: Translating Relation-Contextualized Embeddings for Knowledge Graphs
论文
这篇文章是南京大学的研究者发表在 ISWC(CCF-B) 2019 上的工作,主要思想是针对“一对多”和“多对一”(虽然论文中没明确这么说,但就是这么回事)的复杂关系类型,提出"edge-centric"的嵌入方法,对关系根据其所处的头尾实体的不同(上下文环境)决定不同的表示,具体有"context compression"和"context projection"两种方式,但是说白了就是把实体和关系本身的 embedding 搅和搅和,共同作为关系的表示。
这篇文章虽然讲了很多,但整体感觉下来,没有很多新的东西,提出的问题还是复杂关系建模的问题,只是换了种说法,用的方法:MLP、投影操作,也都不是新的。个人认为它可以被录用的原因可能是因为做了大量的实验。
问题提出
问题提的很模糊,说使用线性/双线性的映射函数的关系水平的嵌入模型对于不同的相关实体(存在这种关系的实体对)只有一种 embedding 表示,因此不能区分关系的不同上下文,不能捕捉 KG 里复杂的关系结构(真心觉得这个问题的提出有点勉强的感觉)。然后文章提出了例子来说明这个问题,例如一部电影有多个主演,训练出的演员实体就会有相近的表示,其中一个演员正好是电影的编剧,因此又会进一步导致"主演"和"编剧"这两个关系的嵌入相近。之前有模型通过投影操作解决这个问题,但作者说针对具体关系进行投影的操作会给实体 embedding 注入歧义。TransEdge 是一个 edge-centric 的嵌入模型,根据实体上下文区分关系的表示。模型受到 KG 图结构的启发:一对实体可以有多重关系(该关系有多个标签);不同实体对可以有相同的关系(不同的关系可以有相同的标签)(这个说法有点像多语义关系的问题)。反正就感觉说了半天也不知道它到底想解决个什么问题。
这篇文章与其他模型不太一样的一点就是,用 KGE 来做实体对齐,因此相关工作模型综述部分和其他的文章不太一样,从任务出发,将模型分为用于链接预测和实体对齐的两部分。链接预测模型都是常规的 KGE 模型,也是分为了翻译模型、双线性和神经网络三大类。实体对齐模型主要罗列了一些用于实体对齐的方法。
整体架构及能量函数
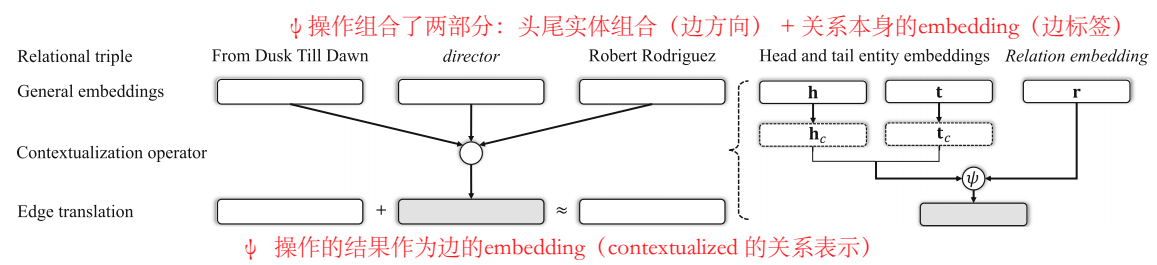
模型整体架构如图,\(\psi\) 是 contextualization 操作,其结果得到关系的最终 embedding,文章将头尾实体的嵌入组合视为"edge direction",关系本身的嵌入视为"edge label",\(\psi\) 操作把这两部分整合到一起,得到 contextualized 的关系表示。\(h_c\) 和 \(t_c\) 是实体的 interaction embedding。
因此,三元组打分函数定义为:
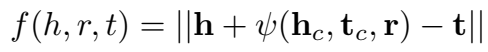
其中,h 和 t 是实体的 general embedding,带脚标 c 的 embedding 是交互表示。通用表示用于捕捉实体的几何位置和关系语义,交互表示编码它们参与边的 embedding 的计算。正样本的能量低,负样本的能量高。
两种 Contextualization 操作
contextualization 操作 \(\psi\) 具体给出了两种形式:context compression 和 context projection。
- context compression
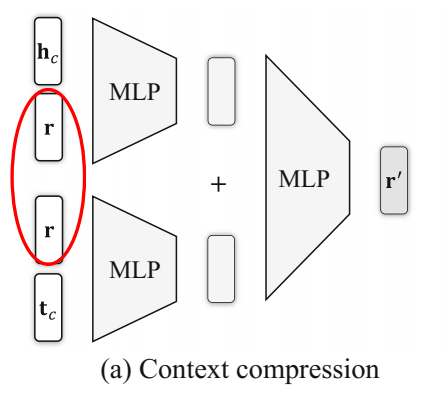
context compression 的方式使用多层感知机(可视为多层前馈神经网络,包括输入、输出和隐藏层),这里的 MLP 使用的是单隐层的,公式化表示为:
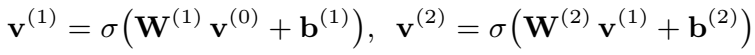
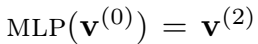
激活函数 \(\sigma\) 使用 \(tanh()\)。最终的边(关系)的表示为:
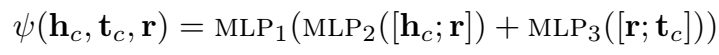
说白了就是头尾实体分别都和关系拼接一下,分别过 MLP,然后各自得到的结果再过一个 MLP。
- context projection
明明前面说的具体关系投影的操作会引入歧义,但还是用了投影的操作。
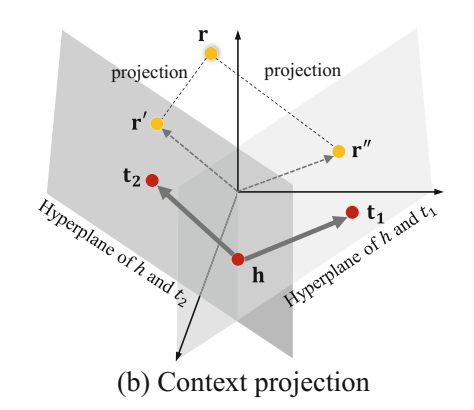
将 edge label (关系本身的 embedding) 投影到 edge direction (hc 和 rc 的组合) 所在的超平面上,超平面由其法向量 \(w_{(h,t)}\) 表示。
法向量由 h、t 的拼接经过 MLP 计算而得:
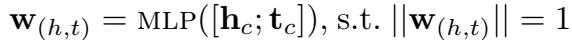
不清楚这个法向量的计算依据是什么=.=。前面还说 edge direction 和 label 是正交的,正交的点积不是 0 么,为什么可以投影?觉得也是一个漏洞。
损失函数
损失函数也和其他模型不太一样,是对正负样本分别定义了 margin:
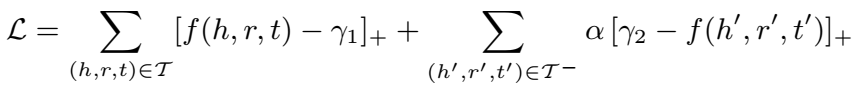
约束 \(\gamma_1<\gamma_2\),\(\alpha\) 是用于平衡正负样本的超参。
实体对齐的实现
实体对齐是给定两个 KG,从中找出指代同一对象的实体。处在 seed alignment 中的实体对共享 embedding(称为参数共享)。模型规定对于新发现的可能对齐的实体,不必完全共享 embedding,定义了一个基于实体相似度的误差函数,只需保证相似度误差在一定范围内即可。
测试时的具体任务是:给出 KG \(K1\) 里的一个实体,对 KG \(K2\) 里的候选实体排序(基于余弦相似度),正确对齐实体应该被排在高位。
实验
- 实体对齐
用了 DBP15K 和 DWY100K 两个数据集进行实体对齐实验,这两个数据集又可分别划分为几个小数据集。
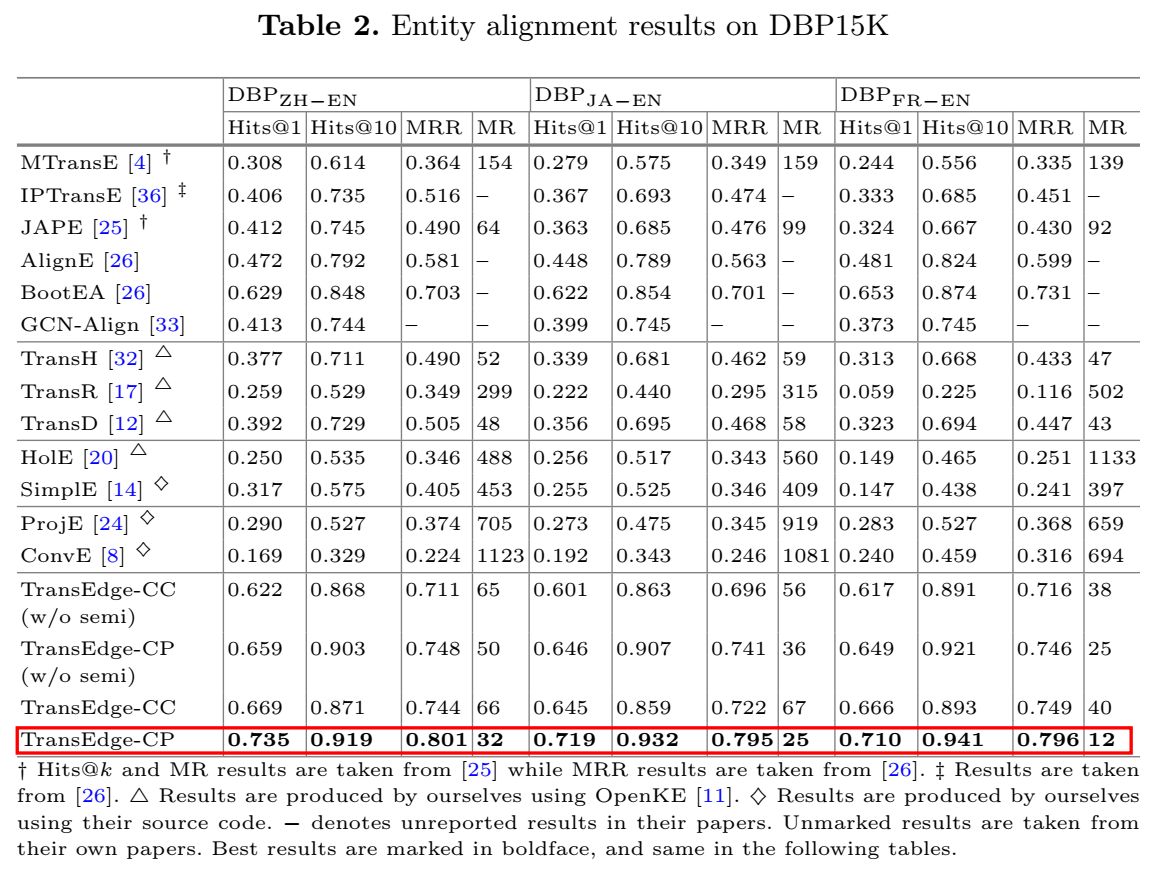
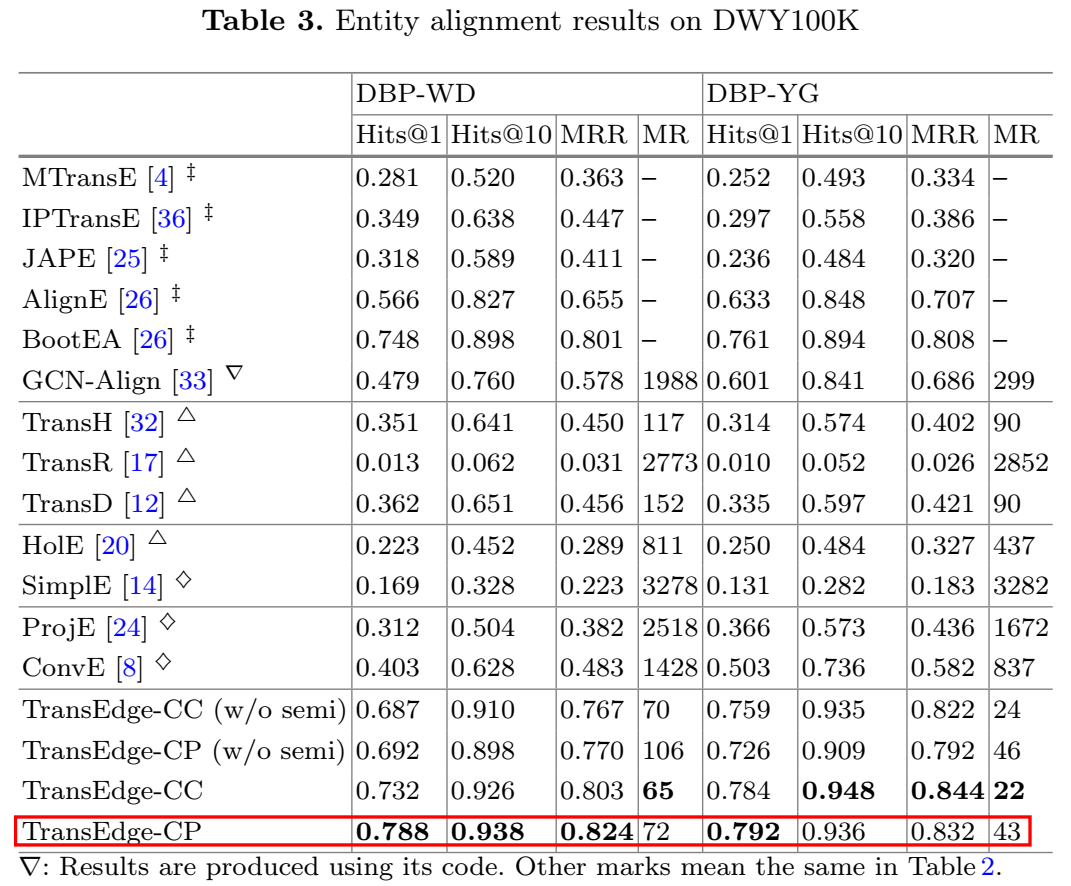
实体对齐的指标和链接预测居然是一样的,也是 Hits@n、MR、MRR。这里论文中提到了一点: MRR 比 MR 更鲁棒,因为它可以避免少数表现极差的测试样本对整体平均结果的影响。
- 链接预测
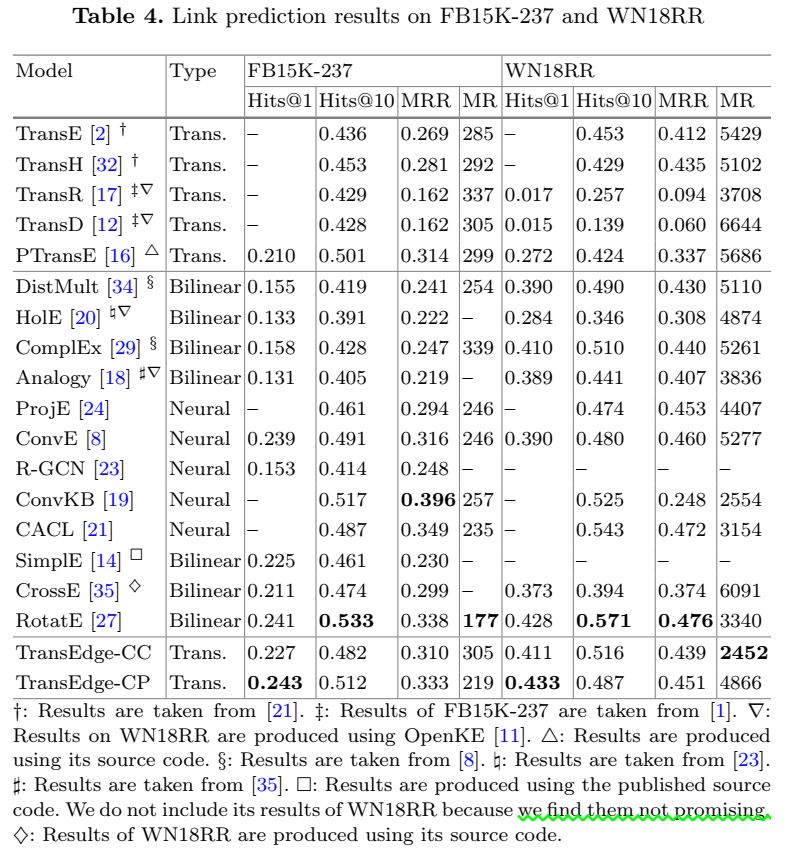
- 复杂关系结构分析
论文还对复杂关系结构进行了分析,分为两种情况:
(1)一个实体对存在多种关系
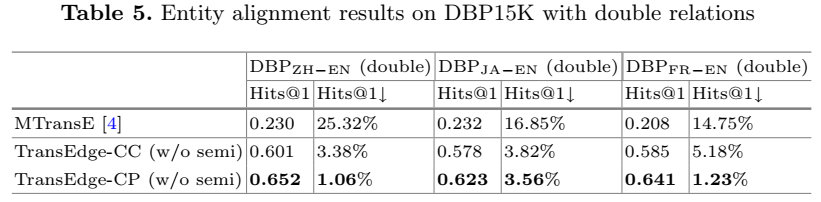
TransEdge 比 MTransE 可以更好地处理这种情况。
(2)多个实体对存在同一种关系
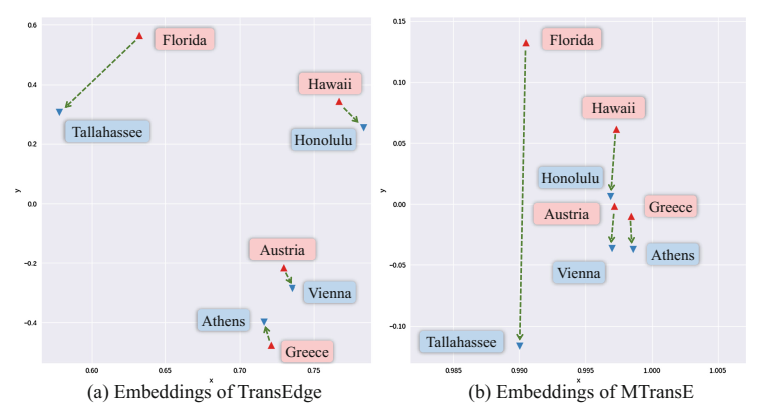
对存在"capital"关系的实体降维可视化,发现 TransEdge 训练出的实体的关系在不同的实体上下文有不同的方向,而 MTransE 却没有,它们更容易获得相似的表示,即使在不同的实体上下文环境中。
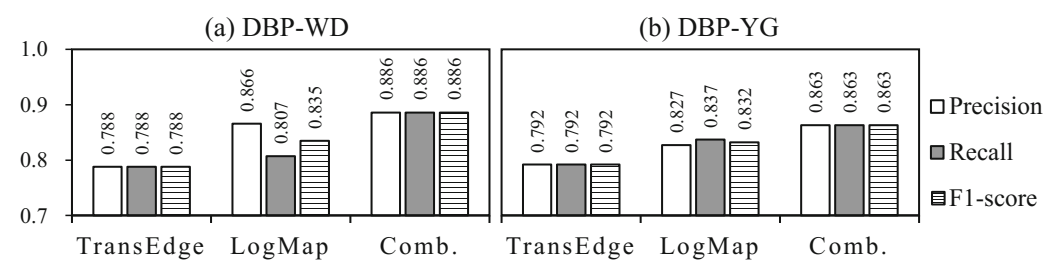
- 实体对齐效果对比
论文还将 TransEdge 与传统的实体对齐方法对比了正确率、召回率和 F1 的效果:
代码
论文中给出了代码:https://github.com/nju-websoft/TransEdge ,是基于 tensorflow 实现的。
小结: 这篇论文给我的整体感觉就是——不知所云,常常不知道作者想要表达的是什么。个人认为方法没有什么新的东西,不难理解,解决的问题也是之前有模型提到过的模型。但这篇文章实验的体量非常大,或许是被 B 类会议录用的原因。因为这几篇论文放一起连着看的,所以归位了神经网络类的方法,但严格来说,用了 MLP 的 context compression 部分是神经网络方法,context projection 部分应该被归为 Trans 系列方法。
TransGate
paper: TransGate: Knowledge Graph Embedding with Shared Gate Structure
论文
这篇文章是袁珺师兄发表在 AAAI 2019 上的一篇文章,本来听说是篇短文,原来是长文。个人认为这篇文章做得非常棒,能中顶会也是理所当然的。我觉得能被录用的主要原因有两个:一是文章的方法很新,会给人眼前一亮的感觉;二是文章的写作很清楚,不但方法讲的很明白,而且没有任何模棱两可的表述,所有的比较都给出确切的数据支撑,所有的原则性表述也都给出了出处。对于和常规做法有出入的做法,也给出了自己的处理方式("filter"那里)。一直不敢翻开顶会的文章,即使是自己组里师兄写的,即使是与自己同一个方向的,而且之前一直抱有偏见,但读了之后才有资格评价,真正感觉实至名归。
文章提出在进行三元组嵌入时引入门结构控制信息的通过量,从而捕捉关系之间的内在关联,在时间复杂度和空间复杂度上都表现了优势。模型的idea虽然不复杂,但是很新,而且主打轻量级,在复杂度上给出了详实的研究数据,以证明模型适用于大规模真实世界 KG。
问题提出及文献综述
问题就是很多模型为关系训练一个单独的表示,却忽略了关系之间是存在关联的。文章将模型分为两类: indiscriminate 和 discriminate 的。TransE 和一些双线性模型属于前者,参数量较少,精度也较低,比较轻便,适用于真实世界 KG;后续的 Trans 系列模型和 NTN 属于后者,这类模型通常包括两步:relation-specific 信息判别(投影等转换操作)和打分,通常参数比较多,专注于提升模型的精度。除这两类外,还有一些其他的基于 NN 的模型。
门结构
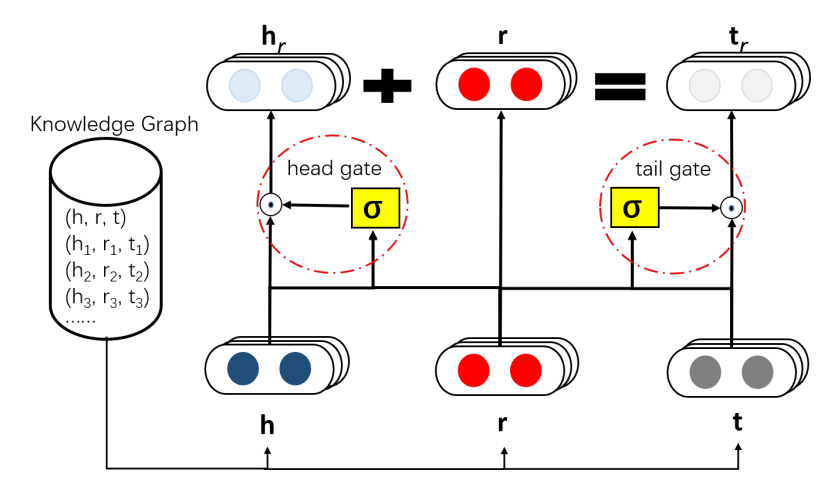
模型的整体架构如图所示,圆圈的部分是门结构,作用是让 h 和 r 的信息有选择地通过。一个门结构包括两部分:sigmoid 激活函数 + Hadamard 积。标准的门结构使用全连接层。
sigmoid 操作逐点进行,控制信息的通过量:
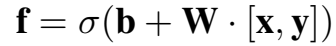
Hadamard 积是矩阵对应元素的乘积,用于过滤信息:
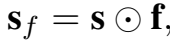
TransGate 架构
在 TransGate 中,两个共享门对于不同的关系共享统计强度,实现了非线性的 discrimination。对照架构图的模型描述为:(1)实体/关系 embed 到相同的维度;(2)设置两个共享门;(3)实体/关系的embedding 进sigmoid层;(4)将sigmoid输出与实体embedding逐点相乘;(5)translation计算三元组得分。
具体地,论文提出了两种实现方式:
- TransGate(fc)
fc 表示 fully connected,这种模式下,使用全连接层的标准门结构,W 是权重矩阵,b 是偏置。
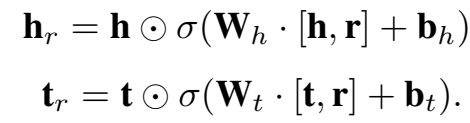
- TransGate(wv)
为了减少参数量,使模型更 scalable,文章提出了 wv 版本,wv 表示 weighted vectors。出发点是认为 embedding 的各维度是独立的,因此将 fc 模式下的权重矩阵 W 用两个权重向量来表示,可以避免"矩阵-向量"相乘的计算量。
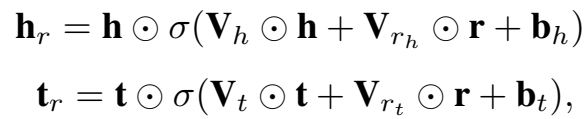
打分函数及 loss
打分函数和 loss 都是常规的定义:
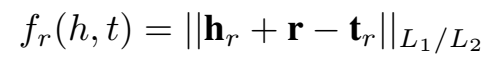
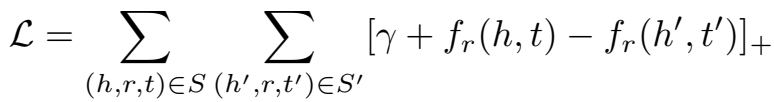
训练时使用 Adam 优化。
复杂度分析
因为模型本身并不复杂,所以文章一个很大的卖点就是复杂度上的优势,因此对时间和空间复杂度作了详细的比较。

实验
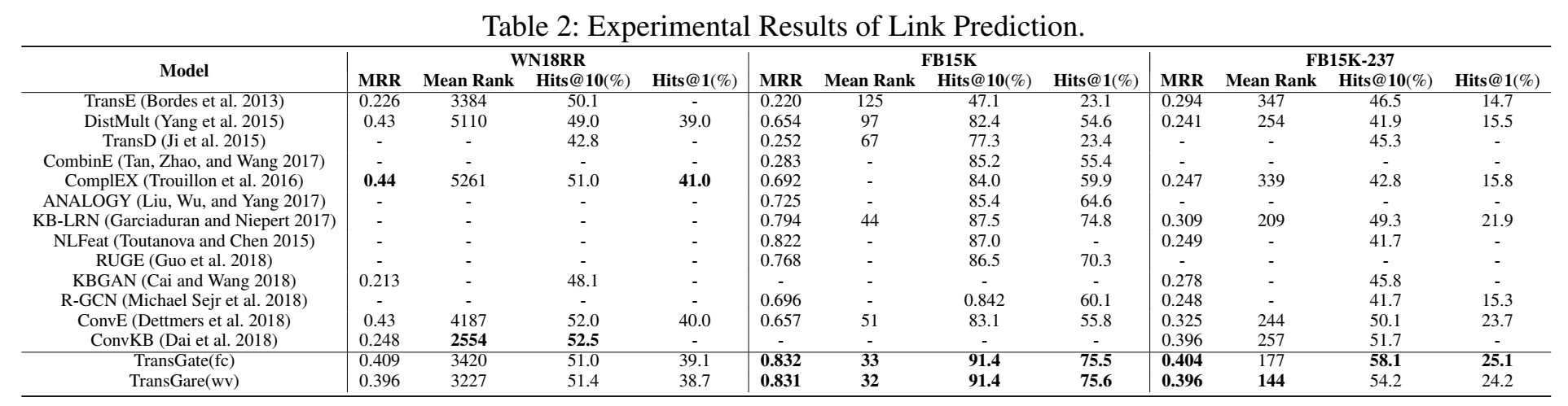
- 链接预测
链接预测实验使用 WN18RR、FB15K、FB15K-237 三个数据集。这里详细介绍了数据集 WN18RR 和 FB15K-237 的来历,学习一下:来源于2015年的一篇文献,指出 WN18 和 FB15K 存在 test leakage,因为测试集中存在很多反向的三元组是对训练集中的三元组做反向操作得到的。为了解决该问题,因而剔除两个数据集中的冗余关系三元组得到 WN18RR 和 FB15K-237。超参的选取规则采用:验证集上 Hits@10 效果的 grid search
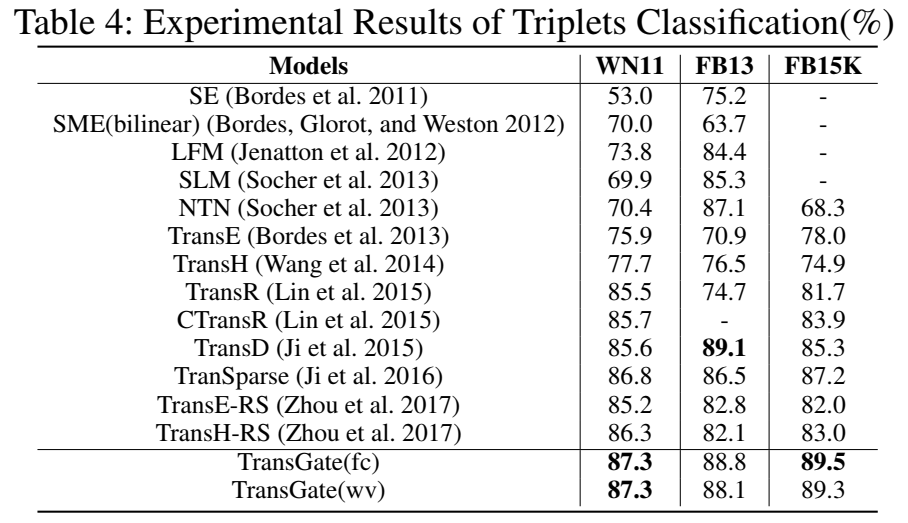
- 三元组分类
三元组分类实验的数据集使用 WN11、FB13 和 FB15K。
最后,作者还进行了不同模型的参数量的比较。
TransGate 没有给出代码,Github 上也没有找到。
小结: 除了没有代码,感觉这篇文章还是很棒的,至少读着很清晰明白,没有明显的短处。
