翻译模型(三)(KG2E、TransG)
我并不确定 KG2E 是否应当被归至翻译模型的类别,因为它的物理解释已经脱离了之前的向量表示方法。因为论文正好看到这里,所以笔记先记下来,后面写大论文的时候应当好好整理一下模型的分类方法。
KG2E
paper: Learning to Represent Knowledge Graphs with Gaussian Embedding
论文
这篇论文已经很熟悉很熟悉了,笔记都做的密密麻麻了。文章还是自动化所赵军刘康老师团队的工作,一作是何世柱同学(现在是老师了),发表在 CIKM 2015 上。文章的核心思想是使用高斯分布代替向量进行 KGE,但是因为将分布的协方差矩阵限制为对角矩阵,所以本质还是用两个向量表示实体/关系,只是在衡量相似性的时候按照衡量分布相似性的方法进行。
文章的出发点是因为实体和关系的语义具有不确定性,为了建模这种不确定性,使用高斯分布进行表示。高斯分布的均值表示实体或关系在语义空间的中心位置,协方差表示不确定度。
两个打分函数
KGE 方法的关键就是三元组评分函数的定义,所以文章开门见山地在模型部分直接放了两个打分函数。
- 非对称相似性:KL divergence
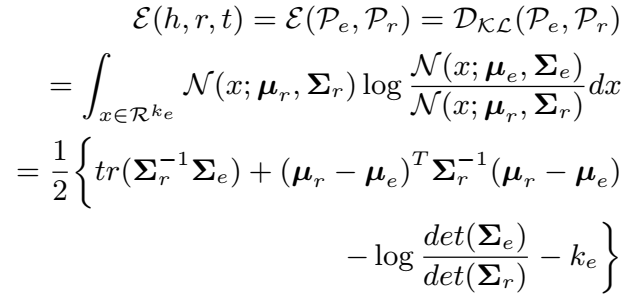
KL散度是两个概率分布P和Q差别的非对称性的度量。始终是>=0的,当两分布完全相同时,等于0。所以是越小越好。
文章尝试了将 KL 散度对称化,但是效果没有更好。
- 对称相似性:EL(Expected Likelihood)
EL 就是两个分布的内积取对数。
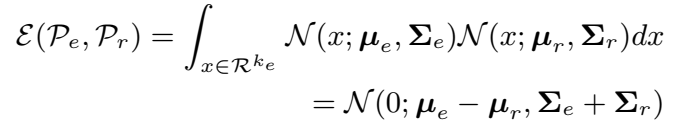
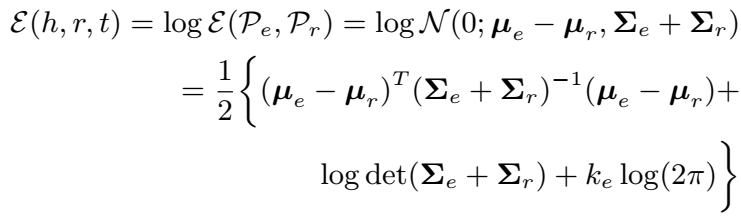
文章还给出了两种打分函数对参数求导的结果,但是在模型实现的时候都是使用框架自动求导的,因此可以省去这部分的工作。
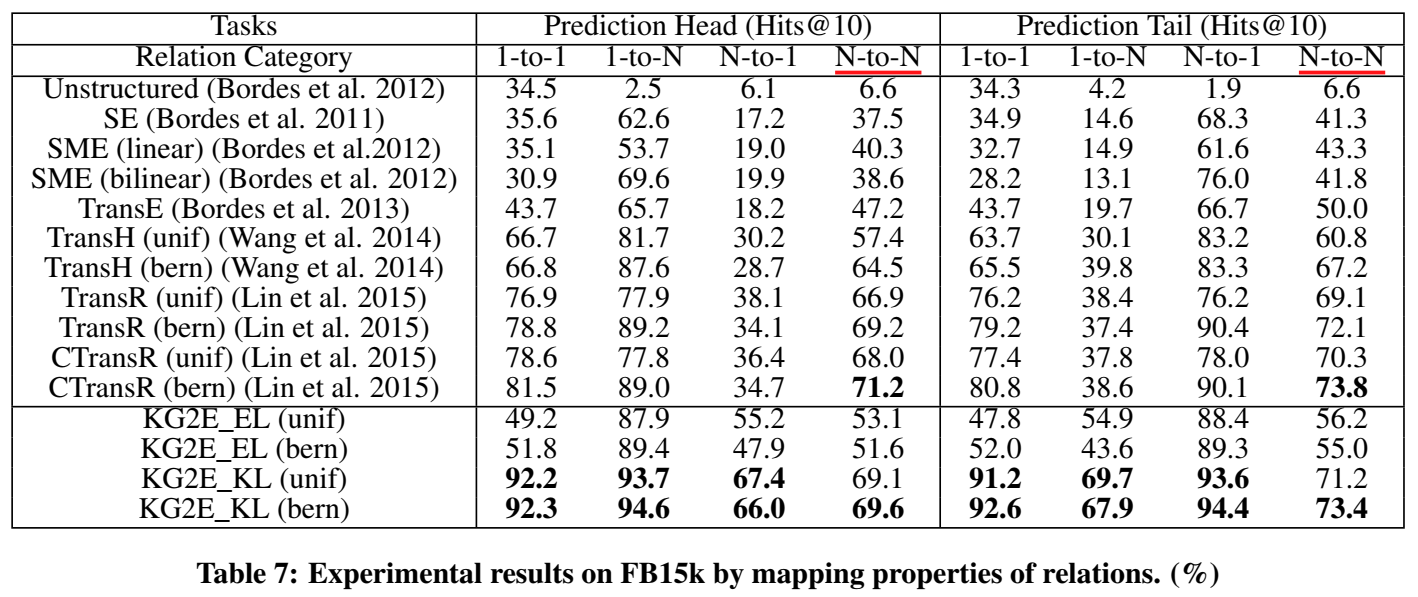
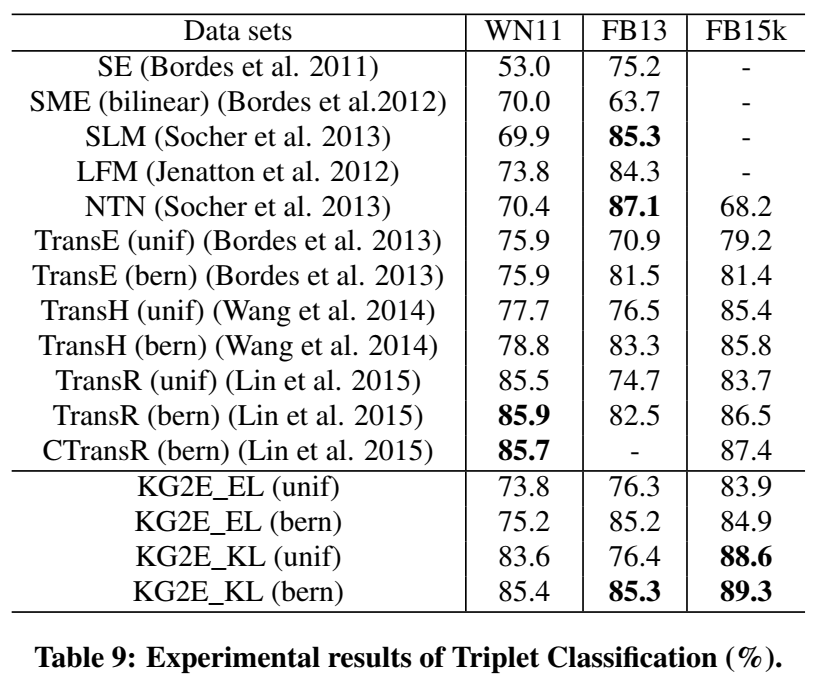
实验
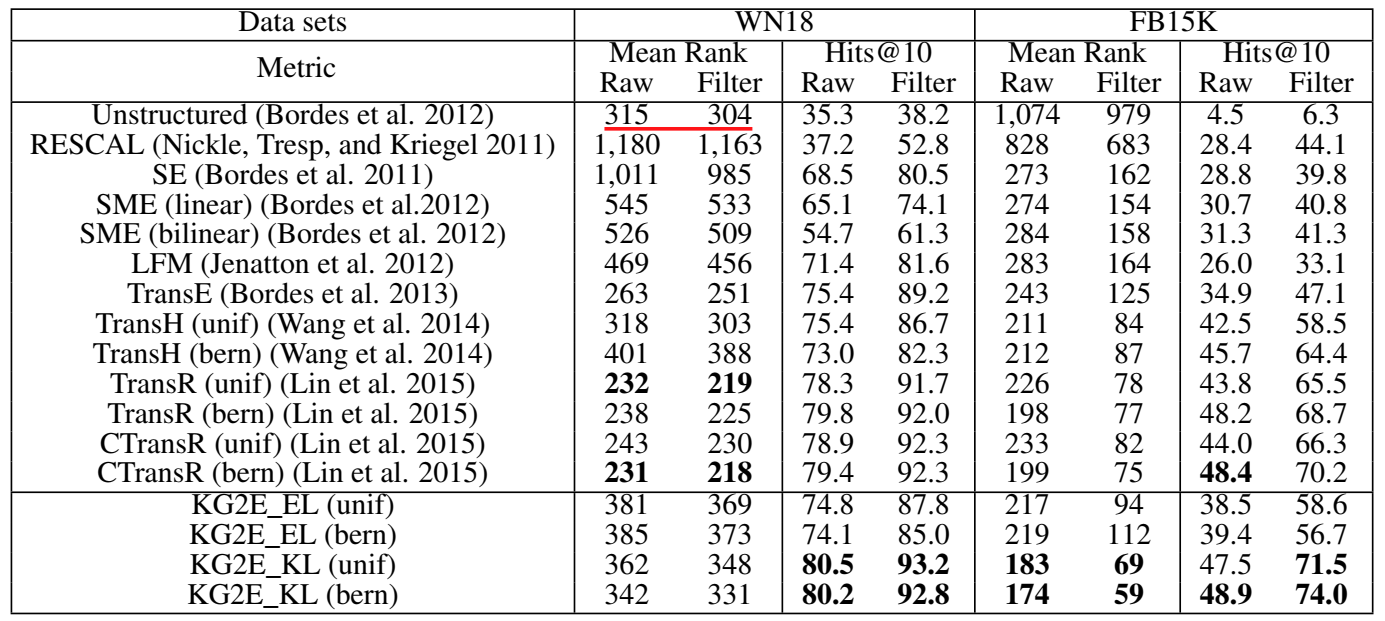
实验部分首先进行了定性分析,证明了实体和关系的不确定性确实是可以通过其分布的 \((log)det\) 或 \(trace\) 的大小来表示的,并给出 case study。然后进行了通用的链接预测和三元组分类实验。
代码
PyTorch 版本
\(Pykg2vec\) 的实现:
class KG2E(PairwiseModel):
def __init__(self, **kwargs):
super(KG2E, self).__init__(self.__class__.__name__.lower())
param_list = ["tot_entity", "tot_relation", "hidden_size", "cmax", "cmin"]
param_dict = self.load_params(param_list, kwargs)
self.__dict__.update(param_dict)
# the mean for each element in the embedding space.
self.ent_embeddings_mu = NamedEmbedding("ent_embeddings_mu", self.tot_entity, self.hidden_size)
self.rel_embeddings_mu = NamedEmbedding("rel_embeddings_mu", self.tot_relation, self.hidden_size)
# as the paper suggested, sigma is simplified to be the diagonal element in the covariance matrix.
self.ent_embeddings_sigma = NamedEmbedding("ent_embeddings_sigma", self.tot_entity, self.hidden_size)
self.rel_embeddings_sigma = NamedEmbedding("rel_embeddings_sigma", self.tot_relation, self.hidden_size)
nn.init.xavier_uniform_(self.ent_embeddings_mu.weight)
nn.init.xavier_uniform_(self.rel_embeddings_mu.weight)
nn.init.xavier_uniform_(self.ent_embeddings_sigma.weight)
nn.init.xavier_uniform_(self.rel_embeddings_sigma.weight)
self.parameter_list = [
self.ent_embeddings_mu,
self.ent_embeddings_sigma,
self.rel_embeddings_mu,
self.rel_embeddings_sigma,
]
min_ent = torch.min(torch.FloatTensor().new_full(self.ent_embeddings_sigma.weight.shape, self.cmax), torch.add(self.ent_embeddings_sigma.weight, 1.0))
self.ent_embeddings_sigma.weight = nn.Parameter(torch.max(torch.FloatTensor().new_full(self.ent_embeddings_sigma.weight.shape, self.cmin), min_ent))
min_rel = torch.min(torch.FloatTensor().new_full(self.rel_embeddings_sigma.weight.shape, self.cmax), torch.add(self.rel_embeddings_sigma.weight, 1.0))
self.rel_embeddings_sigma.weight = nn.Parameter(torch.max(torch.FloatTensor().new_full(self.rel_embeddings_sigma.weight.shape, self.cmin), min_rel))
self.loss = Criterion.pairwise_hinge
def forward(self, h, r, t):
h_mu, h_sigma, r_mu, r_sigma, t_mu, t_sigma = self.embed(h, r, t)
return self._cal_score_kl_divergence(h_mu, h_sigma, r_mu, r_sigma, t_mu, t_sigma)
def embed(self, h, r, t):
"""
Function to get the embedding value.
Args:
h (Tensor): Head entities ids.
r (Tensor): Relation ids of the triple.
t (Tensor): Tail entity ids of the triple.
Returns:
tuple: Returns a 6-tuple of head, relation and tail embedding tensors (both real and img parts).
"""
emb_h_mu = self.ent_embeddings_mu(h)
emb_r_mu = self.rel_embeddings_mu(r)
emb_t_mu = self.ent_embeddings_mu(t)
emb_h_sigma = self.ent_embeddings_sigma(h)
emb_r_sigma = self.rel_embeddings_sigma(r)
emb_t_sigma = self.ent_embeddings_sigma(t)
emb_h_mu = self.get_normalized_data(emb_h_mu)
emb_r_mu = self.get_normalized_data(emb_r_mu)
emb_t_mu = self.get_normalized_data(emb_t_mu)
emb_h_sigma = self.get_normalized_data(emb_h_sigma)
emb_r_sigma = self.get_normalized_data(emb_r_sigma)
emb_t_sigma = self.get_normalized_data(emb_t_sigma)
return emb_h_mu, emb_h_sigma, emb_r_mu, emb_r_sigma, emb_t_mu, emb_t_sigma
@staticmethod
def get_normalized_data(embedding, p=2, dim=1):
norms = torch.norm(embedding, p, dim)
return embedding.div(norms.view(-1, 1).expand_as(embedding))
def _cal_score_kl_divergence(self, h_mu, h_sigma, r_mu, r_sigma, t_mu, t_sigma):
""" It calculates the kl_divergence as a score.
trace_fac: tr(sigma_r-1 * (sigma_h + sigma_t))
mul_fac: (mu_h + mu_r - mu_t).T * sigma_r-1 * (mu_h + mu_r - mu_t)
det_fac: log(det(sigma_r)/det(sigma_h + sigma_t))
Args:
h_mu (Tensor): Mean of the embedding value of the head.
h_sigma(Tensor): Variance of the embedding value of the head.
r_mu(Tensor): Mean of the embedding value of the relation.
r_sigma(Tensor): Variance of the embedding value of the relation.
t_mu(Tensor): Mean of the embedding value of the tail.
t_sigma(Tensor): Variance of the embedding value of the tail.
Returns:
Tensor: Score after calculating the KL_Divergence.
"""
comp_sigma = h_sigma + r_sigma
comp_mu = h_mu + r_mu
trace_fac = (comp_sigma / t_sigma).sum(-1)
mul_fac = ((t_mu - comp_mu) ** 2 / t_sigma).sum(-1)
det_fac = (torch.log(t_sigma) - torch.log(comp_sigma)).sum(-1)
return trace_fac + mul_fac + det_fac - self.hidden_size
note: 这个版本的实现,在计算 KL 散度的时候是度量 \(h+r\) 与 \(t\) 的相似度,而原文中是计算 \(h-t\) 与 \(r\) 的相似度。
C++ 版本
之前的 TransE、TransH、TransR 原版应该都是用 C++ 实现的,因此 KG2E 也不例外,因为当时深度学习的框架都还没有出来。因为短时间内没有向 C++ 发展的打算,所以没有基于 C++ 的源码做改进。不过源码中的手动梯度更新是真的硬核。下面把 KG2E C++ 的源码贴出来,是 KL 版,EL 应该只在打分的地方大同小异。
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include <iostream>
#include <fstream>
#include <map>
#include <set>
#include <vector>
#include <string>
#include <ctime>
#include <cstring>
#include <omp.h>
#include "experiment.h"
using namespace std;
#define E 2.718281828459
#define THREAD_NUM 64//线程个数
double EPSILON = 1e-6;
//string model_base_path = "G:/temp/TransX/fb15k/GEKL/";
string model_base_path = "";//currrent path
double loss_sum;
//global parameters
bool Neg_Scope = 1;
bool Neg_Method = 1;//bern和unif
int Grad_Method = 1;
int Batch_Size = 120;
int Epoch_Size = 1500;
int n = 50;
double rate = 0.001;
double margin = 2;
double para_min = 0.05;
double para_max = 5;
//global variables
vector<vector<double> > ent_mean, ent_vari, ent_mean_temp, ent_vari_temp; //均值和方差
vector<vector<double> > rel_mean, rel_vari, rel_mean_temp, rel_vari_temp;
//for AdaGrad gradient update
vector<vector<double> > ada_ent_mean, ada_ent_vari, ada_rel_mean, ada_rel_vari;
//origin data
long ent_num, rel_num, tri_num;
map<string, unsigned> ent2id, rel2id;
map<unsigned, string> id2ent, id2rel;
map<unsigned, map<unsigned, set<unsigned> > > sub_rel_objs;
map<unsigned, vector<unsigned> > rel_heads, rel_tails;
vector<double> head_num_per_tail, tail_num_per_head;//平均每个head有多少个tail, 平均每个tail有多少个head
//train data
vector<triple> train_triples;
bool exist(triple tri){
if (sub_rel_objs.count(tri.h) == 0)
return false;
if (sub_rel_objs[tri.h].count(tri.r) == 0)
return false;
if (sub_rel_objs[tri.h][tri.r].count(tri.t) == 0)
return false;
return true;
}
void saveModel(int epoch){
string version = "unif";
if (Neg_Method == 1) version = "bern";
char dim_ch[5];
sprintf(dim_ch, "%d", n);
string dim_str = dim_ch;
FILE* f1 = fopen(("ent2gau." + dim_str + "." + version).c_str(), "w");
for (int kk = 0; kk < ent_num; kk++){
for (int dim = 0; dim < n; dim++)
fprintf(f1, "%.6lf\t", ent_mean[kk][dim]);
fprintf(f1, "\n");
for (int dim = 0; dim < n; dim++)
fprintf(f1, "%.6lf\t", ent_vari[kk][dim]);
fprintf(f1, "\n");
}
fclose(f1);
FILE* f2 = fopen(("rel2gau." + dim_str + "." + version).c_str(), "w");
for (int kk = 0; kk < rel_num; kk++){
for (int dim = 0; dim < n; dim++)
fprintf(f2, "%.6lf\t", rel_mean[kk][dim]);
fprintf(f2, "\n");
for (int dim = 0; dim < n; dim++)
fprintf(f2, "%.6lf\t", rel_vari[kk][dim]);
fprintf(f2, "\n");
}
fclose(f2);
}
void paramater_update(
map<unsigned, vector<double> > &grad_temp,
vector<vector<double> > &store_grad,
vector<vector<double> > &ada_grad, bool is_vari){
for (map<unsigned, vector<double> >::iterator it_inner = grad_temp.begin();
it_inner != grad_temp.end(); it_inner++){
int id = it_inner->first;
for (int ii = 0; ii < n; ii++){
double grad = it_inner->second[ii];
if (Grad_Method == 2){
ada_grad[id][ii] += square(grad);
store_grad[id][ii] -= (grad * fast_rev_sqrt(ada_grad[id][ii] + EPSILON) * rate);
}
else
store_grad[id][ii] -= (rate * grad);
}
if (is_vari){
for (int ii = 0; ii < n; ii++){
if (store_grad[id][ii] < para_min) store_grad[id][ii] = para_min;
if (store_grad[id][ii] > para_max) store_grad[id][ii] = para_max;
}
}
else
normalize(store_grad[id]);
}
}
void paramater_update(
map<unsigned, vector<double> > &ent_mean_grad_temp,
map<unsigned, vector<double> > &ent_vari_grad_temp,
map<unsigned, vector<double> > &rel_mean_grad_temp,
map<unsigned, vector<double> > &rel_vari_grad_temp){
paramater_update(ent_mean_grad_temp, ent_mean, ada_ent_mean, false);
paramater_update(ent_vari_grad_temp, ent_vari, ada_ent_vari, true);
paramater_update(rel_mean_grad_temp, rel_mean, ada_rel_mean, false);
paramater_update(rel_vari_grad_temp, rel_vari, ada_rel_vari, true);
}
double energyFunction(triple tri){
double score = 0;
for (int d = 0; d < n; d++){
double ent_mean = ent_mean_temp[tri.h][d] - ent_mean_temp[tri.t][d];
double ent_vari = ent_vari_temp[tri.h][d] + ent_vari_temp[tri.t][d];
score += (ent_vari + square(ent_mean - rel_mean_temp[tri.r][d])) / rel_vari_temp[tri.r][d];
score += (log(rel_vari_temp[tri.r][d]) - log(ent_vari));
}
return 0.5 * score;
}
double energyFunction(triple tri, vector<double> &ent_mean, vector<double> &ent_vari){
double score = 0;
for (int d = 0; d < n; d++){
ent_mean[d] = ent_mean_temp[tri.h][d] - ent_mean_temp[tri.t][d];
ent_vari[d] = ent_vari_temp[tri.h][d] + ent_vari_temp[tri.t][d];
score += (ent_vari[d] + square(ent_mean[d] - rel_mean_temp[tri.r][d])) / rel_vari_temp[tri.r][d];
score += (log(rel_vari_temp[tri.r][d]) - log(ent_vari[d]));
}
return 0.5 * score;
}
void trainTriple(triple pos_tri, triple neg_tri){
vector<double> pos_ent_mean(n, 0), pos_ent_vari(n, 0);
vector<double> pos_rel_mean = rel_mean_temp[pos_tri.r];
vector<double> pos_rel_vari = rel_vari_temp[pos_tri.r];
vector<double> neg_ent_mean(n, 0), neg_ent_vari(n, 0);
vector<double> neg_rel_mean = rel_mean_temp[neg_tri.r];
vector<double> neg_rel_vari = rel_vari_temp[neg_tri.r];
double pos_energy = energyFunction(pos_tri, pos_ent_mean, pos_ent_vari);
double neg_energy = energyFunction(neg_tri, neg_ent_mean, neg_ent_vari);
if (pos_energy + margin <= neg_energy) return;
loss_sum += (pos_energy + margin - neg_energy);
map<unsigned, vector<double> > ent_mean_grad_temp, ent_vari_grad_temp;
map<unsigned, vector<double> > rel_mean_grad_temp, rel_vari_grad_temp;
ent_mean_grad_temp[pos_tri.h].resize(n);
ent_vari_grad_temp[pos_tri.h].resize(n);
ent_mean_grad_temp[pos_tri.t].resize(n);
ent_vari_grad_temp[pos_tri.t].resize(n);
rel_mean_grad_temp[pos_tri.r].resize(n);
rel_vari_grad_temp[pos_tri.r].resize(n);
ent_mean_grad_temp[neg_tri.h].resize(n);
ent_vari_grad_temp[neg_tri.h].resize(n);
ent_mean_grad_temp[neg_tri.t].resize(n);
ent_vari_grad_temp[neg_tri.t].resize(n);
rel_mean_grad_temp[neg_tri.r].resize(n);
rel_vari_grad_temp[neg_tri.r].resize(n);
//求解梯度
for (int dd = 0; dd < n; dd++){
//pos部分
double pos_loss_temp = (pos_ent_mean[dd] - pos_rel_mean[dd]) / pos_rel_vari[dd];
ent_mean_grad_temp[pos_tri.h][dd] += pos_loss_temp;
ent_mean_grad_temp[pos_tri.t][dd] -= pos_loss_temp;
rel_mean_grad_temp[pos_tri.r][dd] -= pos_loss_temp;
ent_vari_grad_temp[pos_tri.h][dd] += (0.5 / pos_rel_vari[dd] - 0.5 / pos_ent_vari[dd]);
ent_vari_grad_temp[pos_tri.t][dd] += (0.5 / pos_rel_vari[dd] - 0.5 / pos_ent_vari[dd]);
double pos_rel_vari_temp = pos_ent_vari[dd] / square(pos_rel_vari[dd]) + square(pos_loss_temp);
rel_vari_grad_temp[pos_tri.r][dd] -= 0.5 * pos_rel_vari_temp;
rel_vari_grad_temp[pos_tri.r][dd] += 0.5 / pos_rel_vari[dd];
//neg部分
double neg_loss_temp = (neg_ent_mean[dd] - neg_rel_mean[dd]) / neg_rel_vari[dd];
ent_mean_grad_temp[neg_tri.h][dd] -= neg_loss_temp;
ent_mean_grad_temp[neg_tri.t][dd] += neg_loss_temp;
rel_mean_grad_temp[neg_tri.r][dd] += neg_loss_temp;
ent_vari_grad_temp[neg_tri.h][dd] += (0.5 / neg_ent_vari[dd] - 0.5 / neg_rel_vari[dd]);
ent_vari_grad_temp[neg_tri.t][dd] += (0.5 / neg_ent_vari[dd] - 0.5 / neg_rel_vari[dd]);
double neg_rel_vari_temp = neg_ent_vari[dd] / square(neg_rel_vari[dd]) + square(neg_loss_temp);
rel_vari_grad_temp[neg_tri.r][dd] += 0.5 * neg_rel_vari_temp;
rel_vari_grad_temp[neg_tri.r][dd] -= 0.5 / neg_rel_vari[dd];
}
#pragma omp critical
{
paramater_update(ent_mean_grad_temp, ent_vari_grad_temp, rel_mean_grad_temp, rel_vari_grad_temp);
}
}
triple sampleNegTriple(triple pos_tri, bool is_head){
triple neg_tri(pos_tri);
bool in_relation = Neg_Scope;//是否在关系中选择
int loop_size = 0;
while (1){
if (in_relation){
if (is_head) neg_tri.h = rel_heads[neg_tri.r][rand() % rel_heads[neg_tri.r].size()];
else neg_tri.t = rel_tails[neg_tri.r][rand() % rel_tails[neg_tri.r].size()];
}
else{
if (is_head) neg_tri.h = rand() % ent_num;
else neg_tri.t = rand() % ent_num;
}
if (!exist(neg_tri)) break;
else if (loop_size++ > 10) in_relation = 0;//连续10次收不到,则在全局中抽
}
return neg_tri;
}
void trainTriple(triple pos_tri){
int head_pro = 500;//选择调换head作为负样本的概率
if (Neg_Method){//bern
double tph = tail_num_per_head[pos_tri.r];
double hpt = head_num_per_tail[pos_tri.r];
head_pro = 1000 * tph / (tph + hpt);
}
bool is_head = false;
if ((rand() % 1000) < head_pro)
is_head = true;
trainTriple(pos_tri, sampleNegTriple(pos_tri, is_head));
//随机抽取关系
triple neg_tri(pos_tri);
int loop_size = 0;
while (1){
neg_tri.r = rand() % rel_num;
if (!exist(neg_tri)) break;
else if (loop_size++ > 10) return;//抽取10次都不行就不训练了
}
trainTriple(pos_tri, neg_tri);
}
void trainTriple(){
//random select batch,0 - tri_num
vector<unsigned> batch_list(tri_num);
for (int k = 0; k < tri_num; k++) batch_list[k] = k;
random_disorder_list(batch_list);
int batchs = tri_num / Batch_Size;//每个batch有batch_size个样本
for (int bat = 0; bat < batchs; bat++){
int start = bat * Batch_Size;
int end = (bat + 1) * Batch_Size;
if (end > tri_num)
end = tri_num;
ent_mean_temp = ent_mean;
ent_vari_temp = ent_vari;
rel_mean_temp = rel_mean;
rel_vari_temp = rel_vari;
#pragma omp parallel for schedule(dynamic) num_threads(THREAD_NUM)
for (int index = start; index < end; index++)
trainTriple(train_triples[batch_list[index]]);
}
}
void trainModel(){
time_t lt;
for (int epoch = 0; epoch < Epoch_Size; epoch++){
lt = time(NULL);
cout << "*************************" << endl;
cout << "epoch " << epoch << " begin at: " << ctime(<);
double last_loss_sum = loss_sum;
loss_sum = 0;
trainTriple();//基于三元组的约束
lt = time(NULL);
cout << "epoch " << epoch << " over at: " << ctime(<);
cout << "last loss sum : " << last_loss_sum << endl;
cout << "this loss sum : " << loss_sum << endl;
cout << "*************************" << endl;
saveModel(epoch);
}
}
void initModel(){
ent_mean.resize(ent_num);
ent_vari.resize(ent_num);
for (int ee = 0; ee < ent_num; ee++){
ent_mean[ee].resize(n);
for (int dd = 0; dd < n; dd++)
ent_mean[ee][dd] = rand(-1, 1);
normalize(ent_mean[ee]);
ent_vari[ee].resize(n, 0.33);
}
rel_mean.resize(rel_num);
rel_vari.resize(rel_num);
for (int rr = 0; rr < rel_num; rr++){
rel_mean[rr].resize(n);
for (int dd = 0; dd < n; dd++)
rel_mean[rr][dd] = rand(-1, 1);
normalize(rel_mean[rr]);
rel_vari[rr].resize(n, 0.33);
}
cout << "init entity vector, relation means and variables are over" << endl;
//or AdaGrad gradient update, sum of square of every steps
ada_ent_mean.resize(ent_num);
ada_ent_vari.resize(ent_num);
for (int kk = 0; kk < ent_num; kk++){
ada_ent_mean[kk].resize(n, 0);
ada_ent_vari[kk].resize(n, 0);
}
ada_rel_mean.resize(rel_num);
ada_rel_vari.resize(rel_num);
for (int kk = 0; kk < rel_num; kk++){
ada_rel_mean[kk].resize(n, 0);
ada_rel_vari[kk].resize(n, 0);
}
cout << "init adagrad parameters are over" << endl;
}
void loadCorpus(){
char buf[1000];
int id;
FILE *f_ent_id = fopen((model_base_path + "../data/entity2id.txt").c_str(), "r");
while (fscanf(f_ent_id, "%s%d", buf, &id) == 2){
string ent = buf; ent2id[ent] = id; id2ent[id] = ent; ent_num++;
}
fclose(f_ent_id);
FILE *f_rel_id = fopen((model_base_path + "../data/relation2id.txt").c_str(), "r");
while (fscanf(f_rel_id, "%s%d", buf, &id) == 2){
string rel = buf; rel2id[rel] = id; id2rel[id] = rel; rel_num++;
}
fclose(f_rel_id);
cout << "entity number = " << ent_num << endl;
cout << "relation number = " << rel_num << endl;
unsigned sub_id, rel_id, obj_id;
string line;
//读取三元组
ifstream f_kb((model_base_path + "../data/train.txt").c_str());
map<unsigned, set<unsigned> > rel_heads_temp, rel_tails_temp;
map<unsigned, map<unsigned, set<unsigned> > > relation_head_tails;//计算平均一个head有多少个tail
map<unsigned, map<unsigned, set<unsigned> > > relation_tail_heads;//计算平均一个tail有多少个head
while (getline(f_kb, line)){
vector<string> terms = split(line, "\t");
sub_id = ent2id[terms[0]]; rel_id = rel2id[terms[1]]; obj_id = ent2id[terms[2]];
train_triples.push_back(triple(sub_id, rel_id, obj_id)); tri_num++;
sub_rel_objs[sub_id][rel_id].insert(obj_id);
rel_heads_temp[rel_id].insert(sub_id);
rel_tails_temp[rel_id].insert(obj_id);
relation_head_tails[rel_id][sub_id].insert(obj_id);
relation_tail_heads[rel_id][obj_id].insert(sub_id);
}
f_kb.close();
cout << "tripe number = " << tri_num << endl;
for (map<unsigned, set<unsigned> >::iterator iter = rel_heads_temp.begin(); iter != rel_heads_temp.end(); iter++){
unsigned rel_id = iter->first;
for (set<unsigned>::iterator inner_iter = iter->second.begin(); inner_iter != iter->second.end(); inner_iter++)
rel_heads[rel_id].push_back(*inner_iter);
}
for (map<unsigned, set<unsigned> >::iterator iter = rel_tails_temp.begin(); iter != rel_tails_temp.end(); iter++){
unsigned rel_id = iter->first;
for (set<unsigned>::iterator inner_iter = iter->second.begin(); inner_iter != iter->second.end(); inner_iter++)
rel_tails[rel_id].push_back(*inner_iter);
}
tail_num_per_head.resize(rel_num);
head_num_per_tail.resize(rel_num);
for (int rel_id = 0; rel_id < rel_num; rel_id++){
//计算平均一个head有多少个tail
map<unsigned, set<unsigned> > tails_per_head = relation_head_tails[rel_id];
unsigned head_number = 0, tail_count = 0;
for (map<unsigned, set<unsigned> > ::iterator iter = tails_per_head.begin(); iter != tails_per_head.end(); iter++){
if (iter->second.size() > 0){ head_number++; tail_count += iter->second.size(); }
}
tail_num_per_head[rel_id] = 1.0 * tail_count / head_number;
//计算平均一个tail有多少个head
map<unsigned, set<unsigned> > heads_per_tail = relation_tail_heads[rel_id];
unsigned tail_number = 0, head_count = 0;
for (map<unsigned, set<unsigned> > ::iterator iter = heads_per_tail.begin();
iter != heads_per_tail.end(); iter++){
if (iter->second.size() > 0){ tail_number++; head_count += iter->second.size(); }
}
head_num_per_tail[rel_id] = 1.0 * head_count / tail_number;
}
}
int main(int argc, char**argv){
int i;
if ((i = ArgPos((char *)"-negScope", argc, argv)) > 0) Neg_Scope = atoi(argv[i + 1]);
if ((i = ArgPos((char *)"-negMethod", argc, argv)) > 0) Neg_Method = atoi(argv[i + 1]);
if ((i = ArgPos((char *)"-grad", argc, argv)) > 0) Grad_Method = atoi(argv[i + 1]);
if ((i = ArgPos((char *)"-batch", argc, argv)) > 0) Batch_Size = atoi(argv[i + 1]);
if ((i = ArgPos((char *)"-epoch", argc, argv)) > 0) Epoch_Size = atoi(argv[i + 1]);
if ((i = ArgPos((char *)"-size", argc, argv)) > 0) n = atoi(argv[i + 1]);
if ((i = ArgPos((char *)"-rate", argc, argv)) > 0) rate = atof(argv[i + 1]);
if ((i = ArgPos((char *)"-margin", argc, argv)) > 0) margin = atof(argv[i + 1]);
if ((i = ArgPos((char *)"-min", argc, argv)) > 0) para_min = atof(argv[i + 1]);
if ((i = ArgPos((char *)"-max", argc, argv)) > 0) para_max = atof(argv[i + 1]);
cout << "negative scope = " << Neg_Scope << endl;
cout << "negative method = " << Neg_Method << endl;
cout << "grad method = " << Grad_Method << endl;
cout << "batch = " << Batch_Size << endl;
cout << "epoch = " << Epoch_Size << endl;
cout << "dim = " << n << endl;
cout << "rate = " << rate << endl;
cout << "margin = " << margin << endl;
cout << "vari from = [" << para_min << "," << para_max << "]" << endl;
time_t lt = time(NULL);
cout << "begin at: " << ctime(<);
loadCorpus();
lt = time(NULL);
cout << "prepare over at: " << ctime(<);
initModel();
lt = time(NULL);
cout << "init net over at: " << ctime(<);
trainModel();
lt = time(NULL);
cout << "train over at: " << ctime(<);
return 1;
}
对这篇文章的感情可以说是非常特殊了,因为翻来覆去不知看了多少遍了,我的第一篇拍脑瓜的烂论文就是基于它做的。KG2E 是基于词的高斯分布,后来出来了词的混合高斯分布,所以打算照葫芦画个瓢。本想先复现出 KG2E 的结果,但是网上实现的版本都没有跑出理想的结果,出了各种各样的问题。2021 年春节寒假的时候,发邮件问作者要代码,竟然很快得到了回复,并得到了 C++ 版本的代码,但是作者说 KG2E 效果并不很好,不建议我跟进(=.=),但是因为我已经在这块徘徊了很久,所以还是选择做下去了,草草地水了一篇文章,正在等结果。当时还错把已经是自动化所老师的作者称呼成了同学,好尴尬-_-||。下次选 idea 要吸取教训,要选择有代码、能复现出结果的论文做改进。
TransG
paper: TransG : A Generative Model for Knowledge Graph Embedding
论文
这篇文章是清华大学朱小燕黄民烈老师团队发表在 ACL 2016 上的工作,和 TransA 是同一团队,G 代表生成(generative)。很多综述将这篇文章归类为高斯模型,其实它的重点根本不在高斯,高斯只是用于初始化实体向量的采样,虽然在后面的一些条件计算中用到了高斯分布的均值和方差。它的主要创新点是能自适应地生成新的关系语义成分,解决多关系语义的问题。
多关系语义问题
本文提出了多关系语义(multiple relation semantics)问题,其实这个问题,CTransR 已经通过聚类解决过,但是这里是正儿八经地提出来,并花了很长的篇幅介绍。问题就是一个关系可能包含多种语义(如果细分的话),比如 “HasPart” 关系,有 “composition” 和 “location” 两种语义关系,其实就是对关系的一个细粒度的划分。号称是第一个生成式的模型。
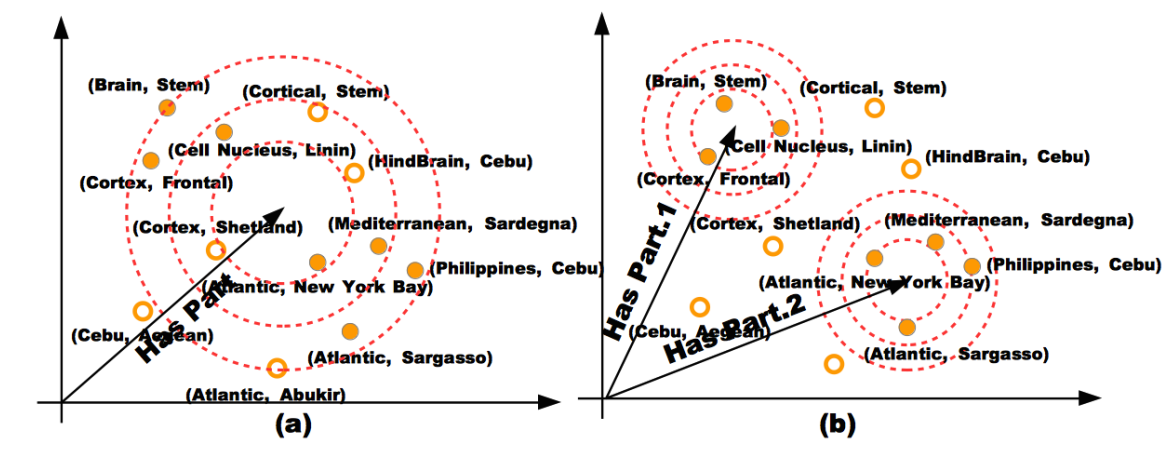
如果只对 “HasPart” 赋一个向量的话,会有很多错误的实体对被囊括,而赋两个向量就不会出现这种情况。
成分生成

这个生成的过程也是没太看明白,不知道是每个实体向量是从它所属的高斯分布中抽取一个向量,还是说所有的实体的实体向量一共服从一个高斯分布,应该是前者。对于关系的新的语义成分,模型通过中国餐馆过程(Chinese Restaurant Process,CRP)自动检测新的成分并赋向量和权重,新来成分的权重会比较小。
新的成分以如下的概率被采样:
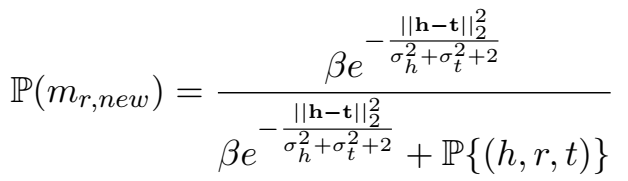
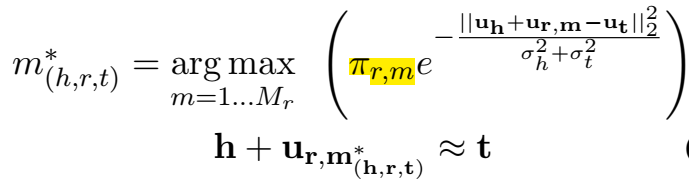
每个关系会有一个基础成分,为加权得分最大的成分。在计算三元组得分时,TransG 会自动选择最优的成分向量。
三元组打分函数及 Loss

三元组的得分是每个关系成分下的三元组得分的加权组合,权重通过吉布斯采样生成。
Loss 中的三元组打分函数要取 ln,和之前的 loss、训练方法都不太一样:
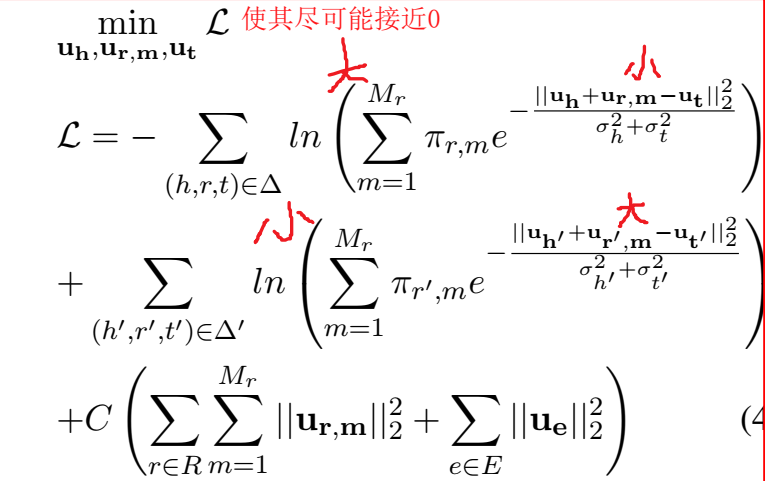
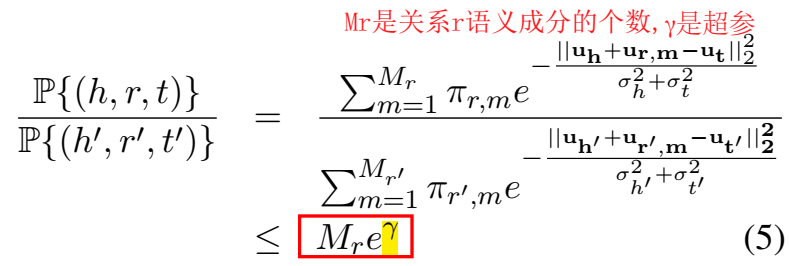
训练优化器使用 SGD,但是要正负样本的得分比要满足如下的条件才会更新 embedding,感觉这种操作增加了很多的计算量。
实验
进行了链接预测、三元组分类和定性分析 case study。
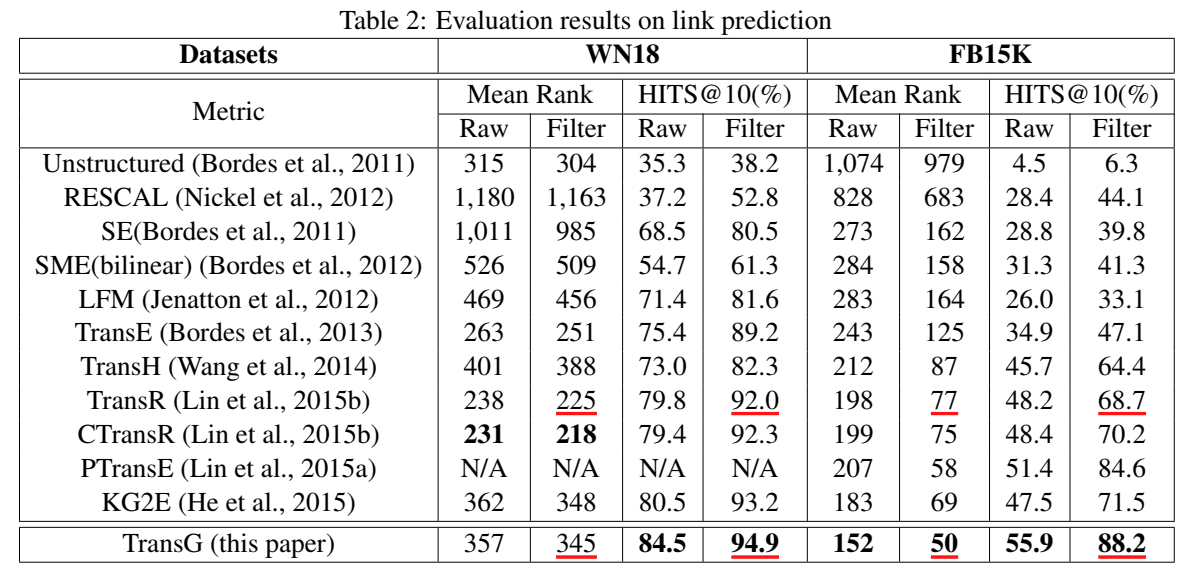
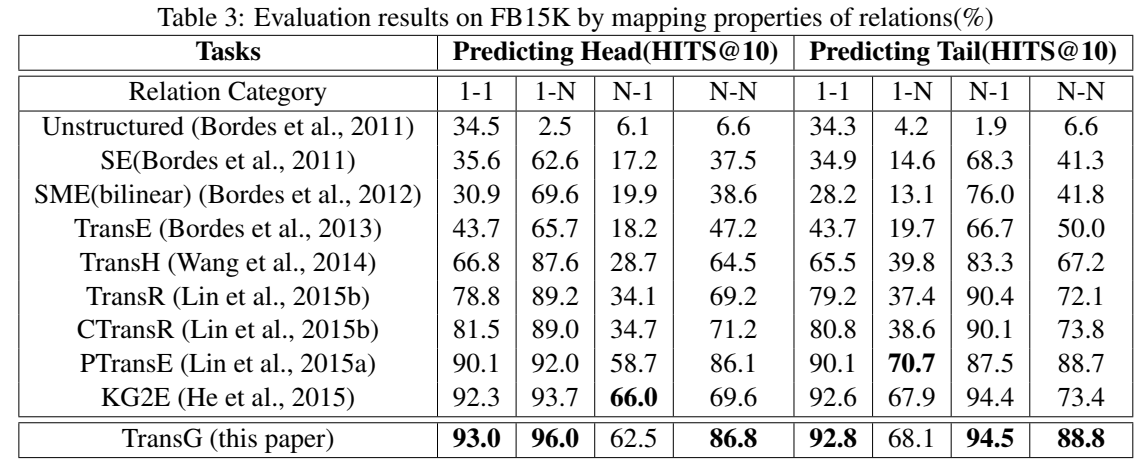
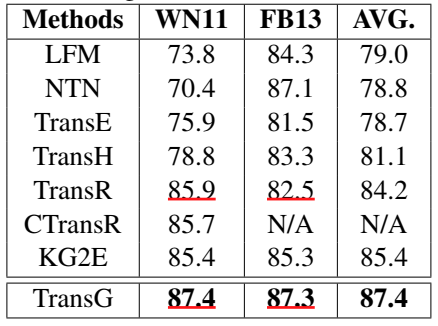
文章还分析了 WN11、FB13 和 WN18 三个数据集中每个关系所含语义成分的个数:
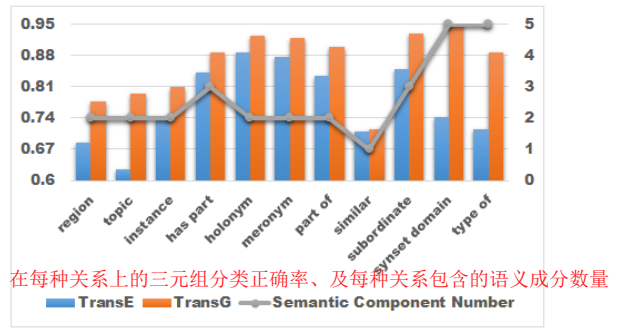
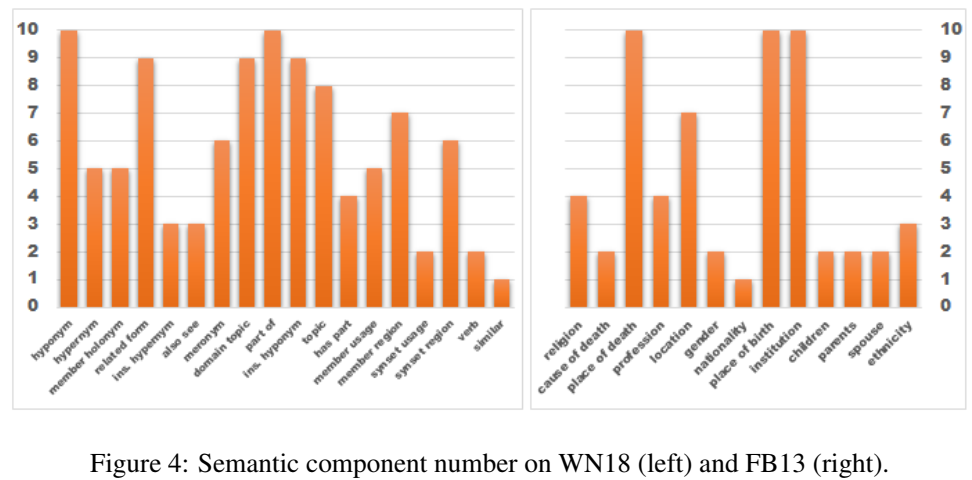
因为最初以为这是一篇用高斯做的 KGE,所以把这篇文章也看了很多遍,但每次看完都感觉晕晕乎乎、乱七八糟的,在网上找到过视频讲解,也是讲的不清不楚的。看过这个团队的两篇文章,都感觉不太好,总感觉不够踏实,多多少少有投机取巧的成分。
代码
\(Pykg2vec\) 和 \(OpenKE\) 都没有实现 TransG,可以理解了,这个模型涉及的东西实在太多了,不像之前的模型,不过是多定义个向量或矩阵,进行一下投影操作,这个比较复杂了,难怪大家实现不出来=.=,都不是神,再厉害也没办法在没有参照的前提下,对论文在短时间内从无到有实现出来吧。
原作有用 C++ 实现的版本,里面也有 TransA 的: https://github.com/BookmanHan/Embedding
另外,还找到了一个野路子的 python 版本,没有用框架,这个版本的实现比较 naive、臃肿,没有用框架实现的优雅。而且在本机上跑起来实在太慢了,训了半天什么都没训出来,只学习一下代码吧。之前仔细学习过这一版代码,做了很多笔记,后来可能清理垃圾给删了 orz。
class TransG:
dim, n_cluster, epos, step_before = 0, 0, 0, 0
alpha, threshold, CRP= 0.0, 0.0, 0.0
be_weight_normalized = True
dir = ""
entity, rel_clusters, weights_clusters = {}, {}, {}
head_entity, tail_entity = [], []
train_triples, test_triples, dev_triples = [], [], []
relation_tph, relation_hpt = {}, {}
result = []
def __init__(self, datadir, dim, alpha, threshold, ncluster, CRP_factor, weight_norm = True, step_before = 10):
train_dir = datadir + "train.txt"
rel_cnt = {}
self.dir = datadir
self.dim = dim
self.alpha = alpha
self.threshold = threshold
self.n_cluster = ncluster
self.be_weight_normalized = weight_norm
self.step_before = step_before
with open(train_dir) as file:
lines = file.readlines()
for line in lines:
[head, rel, tail] = line.strip().split("\t")
if head not in self.entity:
self.entity[head] = np.empty([1, dim], dtype=float)
self.head_entity.append(head)
if tail not in self.entity:
self.entity[tail] = np.empty([1, dim], dtype=float)
self.tail_entity.append(tail)
if rel not in self.rel_clusters:
self.rel_clusters[rel] = {}
self.weights_clusters[rel] = np.zeros([1, 20], dtype=float)
for i in range(0, ncluster):
self.rel_clusters[rel][i] = np.empty([1, dim], dtype=float)
self.weights_clusters[rel][0, i] = 1.0 / ncluster
rel_cnt[rel] = {"head": [], "tail": [], "total": 0.0}
self.train_triples.append([head, rel, tail])
if head not in rel_cnt[rel]["head"]:
rel_cnt[rel]["head"].append(head)
if tail not in rel_cnt[rel]["tail"]:
rel_cnt[rel]["tail"].append(tail)
rel_cnt[rel]["total"] += 1
for enitiy in self.entity:
for elem in range(0, dim):
self.entity[enitiy][0, elem] = random.random()
for rel in self.rel_clusters:
for cluster in self.rel_clusters[rel]:
for elem in range(0, dim):
self.rel_clusters[rel][cluster][0, elem] = (2 * random.random() - 1) * math.sqrt(6.0 / dim)
for rel in rel_cnt:
self.relation_tph[rel] = rel_cnt[rel]["total"] / len(rel_cnt[rel]["head"])
self.relation_hpt[rel] = rel_cnt[rel]["total"] / len(rel_cnt[rel]["tail"])
self.CRP = CRP_factor / len(self.train_triples) * len(rel_cnt)
self.result.append(["dim:" + str(dim), "alpha:" + str(alpha), "threshold:" + str(threshold),
"n_cluster:" + str(ncluster), "CRP_factor" + str(CRP_factor)])
print "Ready"
def load_testing(self):
with open(self.dir + "test.txt") as file:
lines = file.readlines()
for line in lines:
self.test_triples.append(line.strip().split("\t"))
def load_dev(self):
with open(self.dir + "dev.txt") as file:
lines = file.readlines()
for line in lines:
self.dev_triples.append(line.strip().split("\t"))
def sample_false_triple(self, triple):
[head, rel, tail] = triple
prob = self.relation_hpt[rel] / (self.relation_hpt[rel] + self.relation_tph[rel])
while 1:
if random.random() < prob:
tail = random.choice(self.tail_entity)
else:
head = random.choice(self.head_entity)
triple_f = [head, rel, tail]
if triple_f not in self.train_triples:
return triple_f
def prob_triples(self, triple):
mixed_prob = 1e-100
[head, rel, tail] = triple
for c in range(0, len(self.rel_clusters[rel])):
error_c = self.entity[head] + self.rel_clusters[rel][c] - self.entity[tail]
mixed_prob = max(mixed_prob, math.fabs(self.weights_clusters[rel][0, c]) * math.exp(-np.sum(np.abs(error_c))))
return mixed_prob
def training_prob_triples(self, triple):
mixed_prob = 1e-100
[head, rel, tail] = triple
for c in range(0, len(self.rel_clusters[rel])):
error_c = self.entity[head] + self.rel_clusters[rel][c] - self.entity[tail]
mixed_prob += math.fabs(self.weights_clusters[rel][0, c]) * math.exp(-np.sum(np.abs(error_c)))
return mixed_prob
def train_cluster_once(self, triple, triple_f, cluster, prob_true, prob_false, factor):
[head, rel, tail] = triple
[head_f, rel_f, tail_f] = triple_f
prob_local_true = math.exp(-np.sum(np.abs(self.entity[head] + self.rel_clusters[rel][cluster] -
self.entity[tail])))
prob_local_false = math.exp(-np.sum(np.abs(self.entity[head_f] + self.rel_clusters[rel_f][cluster] -
self.entity[tail_f])))
self.weights_clusters[rel][0, cluster] += \
factor / prob_true * prob_local_true * np.sign(self.weights_clusters[rel][0, cluster])
self.weights_clusters[rel_f][0, cluster] -= \
factor / prob_false * prob_local_false * np.sign(self.weights_clusters[rel_f][0, cluster])
change = factor * prob_local_true / prob_true * math.fabs(self.weights_clusters[rel][0, cluster])
change_f = factor * prob_local_false / prob_false * math.fabs(self.weights_clusters[rel_f][0, cluster])
self.entity[head] -= change * np.sign(self.entity[head] + self.rel_clusters[rel][cluster] - self.entity[tail])
self.entity[tail] += change * np.sign(self.entity[head] + self.rel_clusters[rel][cluster] - self.entity[tail])
self.rel_clusters[rel][cluster] -= change * np.sign(self.entity[head] + self.rel_clusters[rel][cluster] -
self.entity[tail])
self.entity[head_f] += change_f * np.sign(self.entity[head_f] + self.rel_clusters[rel_f][cluster] -
self.entity[tail_f])
self.entity[tail_f] -= change_f * np.sign(self.entity[head_f] + self.rel_clusters[rel_f][cluster] -
self.entity[tail_f])
self.rel_clusters[rel_f][cluster] += change_f * np.sign(self.entity[head_f] +
self.rel_clusters[rel_f][cluster] - self.entity[tail_f])
# print la.norm(self.rel_clusters[rel][cluster])
if la.norm(self.rel_clusters[rel][cluster]) > 1.0:
self.rel_clusters[rel][cluster] = preprocessing.normalize(self.rel_clusters[rel][cluster], norm='l2')
if la.norm(self.rel_clusters[rel_f][cluster]) > 1.0:
self.rel_clusters[rel_f][cluster] = preprocessing.normalize(self.rel_clusters[rel_f][cluster])
def train_triplet(self, triple):
[head, rel, tail] = triple
triple_f = self.sample_false_triple(triple)
[head_f, rel_f, tail_f] = triple_f
prob_true = self.training_prob_triples(triple)
prob_false = self.training_prob_triples(triple_f)
if prob_true / prob_false > math.exp(self.threshold):
return
for c in range(0, len(self.rel_clusters[rel])):
self.train_cluster_once(triple, triple_f, c, prob_true, prob_false, self.alpha)
prob_new_component = self.CRP * math.exp(-np.sum(np.abs(self.entity[head] - self.entity[tail])))
if random.random() < prob_new_component / (prob_new_component + prob_true) \
and len(self.rel_clusters[rel]) < 20 and self.epos >= self.step_before:
component = len(self.rel_clusters[rel])
self.weights_clusters[rel][0, component] = self.CRP
self.rel_clusters[rel][component] = np.empty([1, self.dim], dtype=float)
for elem in range(0, self.dim):
self.rel_clusters[rel][component][0, elem] = (2 * random.random() - 1) * math.sqrt(6.0 / self.dim)
if la.norm(self.entity[head]) > 1.0:
self.entity[head] = preprocessing.normalize(self.entity[head])
if la.norm(self.entity[tail]) > 1.0:
self.entity[tail] = preprocessing.normalize(self.entity[tail])
if la.norm(self.entity[head_f]) > 1.0:
self.entity[head_f] = preprocessing.normalize(self.entity[head_f])
if la.norm(self.entity[tail_f]) > 1.0:
self.entity[tail_f] = preprocessing.normalize(self.entity[tail_f])
if self.be_weight_normalized:
self.weights_clusters[rel] = preprocessing.normalize(self.weights_clusters[rel])
def train(self, total_epos):
print "Progress:"
while total_epos != self.epos:
self.epos += 1
if self.epos % (0.01 * total_epos) == 0:
print str(self.epos / (0.01 * total_epos)) + "%"
for item in self.train_triples:
self.train_triplet(item)
def test(self, hit_rank):
hits = 0.0
self.load_testing()
print "testing:"
for [head, rel, tail] in self.test_triples:
mean = 0
if head not in self.head_entity or tail not in self.tail_entity:
self.result.append([head, rel, tail, '1'])
else:
score = self.prob_triples([head, rel, tail])
for r in self.rel_clusters:
if score >= self.prob_triples([head, r, tail]):
continue
mean += 1
if mean < hit_rank:
hits += 1
self.result.append([head, rel, tail, '0'])
else:
self.result.append([head, rel, tail, '1'])
total = len(self.test_triples)
accu = hits / total
self.result.append(["accu:" + str(accu)])
writefile = open(self.dir + "result.txt", 'w')
for info in self.result:
for item in info:
writefile.write(item + "\t")
writefile.write("\n")
def save(self, dir=""):
if dir == "":
dir = self.dir
writeentity = open(dir + "entity.txt", 'w')
for entity in self.entity:
writeentity.write(entity + "\t")
for elem in range(0, self.dim):
writeentity.write(str(self.entity[entity][0, elem]) + "\t")
writeentity.write("\n")
writeentity.close()
writeweight = open(dir + "weight.txt", 'w')
for rel in self.rel_clusters:
writerelation = open(dir + "relation_" + rel + ".txt", 'w')
writeweight.write(rel + "\t")
for cluster in self.rel_clusters[rel]:
writerelation.write(str(cluster) + "\t")
writeweight.write(str(self.weights_clusters[rel][0, cluster]) + "\t")
for elem in range(0, self.dim):
writerelation.write(str(self.rel_clusters[rel][cluster][0, elem]) + "\t")
writerelation.write("\n")
writeweight.write("\n")
writerelation.close()
writeweight.close()
def draw(self, r, dir=""):
x_good, y_good = [], []
x_neu, y_neu = [], []
x_bad, y_bad= [], []
if dir == "":
dir = self.dir
savepath = dir + "map.png"
for triple in self.train_triples:
[head, rel, tail] = triple
if rel == "_good":
x_good.append(r * (self.entity[tail][0, 0] - self.entity[head][0, 0]))
y_good.append(r * (self.entity[tail][0, 1] - self.entity[head][0, 1]))
elif rel == "_bad":
x_neu.append(r * (self.entity[tail][0, 0] - self.entity[head][0, 0]))
y_neu.append(r * (self.entity[tail][0, 1] - self.entity[head][0, 1]))
else:
x_bad.append(r * (self.entity[tail][0, 0] - self.entity[head][0, 0]))
y_bad.append(r * (self.entity[tail][0, 1] - self.entity[head][0, 1]))
plt.clf()
plt.figure(dpi=1000)
plt.scatter(x_good, y_good, s = 0.01, color='r', marker='x')
plt.scatter(x_bad, y_bad, s = 0.01, color='b', marker='x')
plt.scatter(x_neu, y_neu, s = 0.01, color='tab:gray', marker='x')
plt.xlim(-500, 500)
plt.ylim(-500, 500)
plt.axis('off')
plt.savefig(savepath)
虽然这个 python 实现的没有框架代码那么规范和全面,但是很好理解,文件和函数没有错综复杂的依赖,一个类包含了读数据、负采样、三元组打分、训练、测试、存模型等所有的步骤,非常适合我这种新手小白。能实现到这种程度,才是我这种水平通过努力能达到的,也是很不错的呢。
到此为止所有之前学习过的模型都整理完了,也算是对过去有个交待,老方法用的大概是什么套路也都了解一些了,以后就要按部就班学习新模型了,终于可以向前走了。继续学下去、做下去,无论多慢,总是有进步的;只要坚持播种,总是会有收获的。没有天赋的努力总比躺着好,我们一定会越来越好的。
(题外话:早上打开草稿箱想继续写博,发觉昨晚写的 KG2E 竟未保存草稿,还好随笔新建有保存,虚惊一场,下次写了博一定要第一时间存草稿!!)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号