
kafka系列四:consumer端开发
上一篇介绍了producer端的开发,本篇介绍一下consumer端的开发。
一、consumer端示例程序开发
和开发producer端程序一样,首先检查pom文件是否有已经有kafka相关jar包依赖,如果没有,则需要在pom.xml中添加如下依赖:
<!--kafka-->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.12</artifactId>
<version>2.2.0</version>
</dependency>
然后在resouces下面新建 kafka-consumer.properties 配置文件,用于配置consumer端相关参数,配置内容如下:
bootstrap.servers=192.168.184.128:9092,192.168.184.128:9093,192.168.184.128:9094 key.deserializer=org.apache.kafka.common.serialization.StringDeserializer value.deserializer=org.apache.kafka.common.serialization.StringDeserializer group.id=testGroup enable.auto.commit=true auto.commit.interval.ms=1000 auto.offset.reset=earliest
上面配置中前4个参数是没有默认值的,所以必须显示配置取值(注:consumer的参数配置可以参考:http://kafka.apache.org/documentation/#consumerconfigs),接下来编写测试代码:
/** * consumer接收消息测试 */ public void receiveMsg() throws IOException { String topicName = "testTopic"; //1.构造Properties对象 Properties consumerProps = new Properties(); FileInputStream fileInputStream = new FileInputStream("F:\\javaCode\\jvmdemo\\src\\main\\resources\\kafka-consumer.properties"); consumerProps.load(fileInputStream); fileInputStream.close(); //2.使用Properties构造KafkaConsumer对象 KafkaConsumer consumer = new KafkaConsumer(consumerProps); //3.调用KafkaConsumer的subscribe方法订阅consumer group感兴趣的topic列表 consumer.subscribe(Arrays.asList(topicName)); try { while (true) { //4.调用conusmer.poll方法 获取封装在consumerRecord中的消息 ConsumerRecords<String, String> records = consumer.poll(1000); for (ConsumerRecord<String, String> record : records) { //5.处理获取到的consumerRecord对象 System.out.printf("offset=%d,key=%s,value=%s%n", record.offset(), record.key(), record.value()); } } } finally { //6.关闭cnsumer consumer.close(); } }
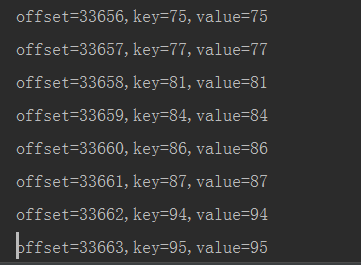
运行以上代码之后,IEDA会处于一个监听状态,然后再运行上一篇中的producer程序,向testTopic主题中添加消息,此时会在IEDA的控制台上看到consumer端可以接收到producer端发送的消息:
二、consumer位移管理
1.位移的概念
consumer端需要为每个它要读取的分区保存消费进度,即分区中当前消费消息的位置,该位置称为位移(offset)。kafka中的consumer group中使用一个map来保存其订阅的topic所属分区的offset:
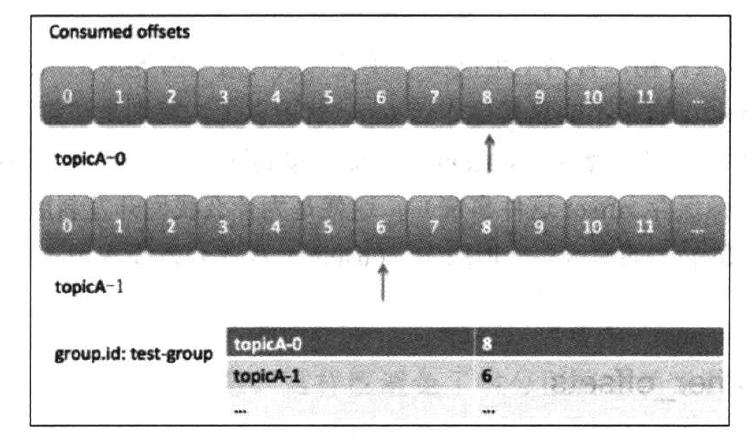
实际上,这里的位移值通常是下一条待消费的消息的位置,因为位移是从0开始的,所以位移为N的消息其实是第N+1条消息。在consumer中有如下位置信息:

上次提交位移:consumer最后一次提交的offset值;
当前位置:consumer已经读取,但尚未提交时的位置;
水位:也称为高水位,严格来说它属于分区日志的概念,对于处于水位以下(水位左侧)的所有消息,consumer是可以读取的,水位以上的消息consumer无法读取;
日志最新位移:也称日志终端位移,严格来说也属于分区日志的概念,表示了某个分区副本当前保存消息对应的最大位移值。
2.位移提交原理
consumer需要定期向Kafka提交自己的位置信息,这一过程称为位移提交(offset commit)。consumer会在所有的broker中选择一个broker作为consumer group的coordinator,用于实现组成员管理、消费分配方案制定以及位移提交等。选择该coordinator的依据就是kafka的内置topic(_consumer_offsets)。该topic与普通topic一样,配置多个分区,每个分区有多个副本,它存在的唯一目的就是保存consumer提交的位移。
当消费者组首次启动的时候,由于没有初始的位移信息,coordinator需要为其确定初始位移值,这就是consumer参数 auto.offset.reset 的作用,通常情况下,consumer要么从最开始位移开始读取,要么从最新的位移开始读取。当cosumer运行一段时间之后,就需要提交自己的位移信息,如果consumer奔溃或者被关闭,它负责的分区就会被分配给其他consumer,因此一定要在其他consumer读取这些分区前就做好位移提交,否则会出现重复消费。
consumer提交位移的主要机制是通过向所属的coordinator发送位移提交请求来实现的,每个位移提交请求都会向_consumer_offsets对应分区写入一条消息,消息的key是group.id,topic和分区的元组,value是位移值,如果consumer为同一个group的同一个topic分区提交了多次位移,那么只有最新的那次提交的位移值是有效的,其余几次提交的位移值都已经过期,Kafka通过压实(compact)策略来处理这种消息使用模式,
3.位移的自动提交与手动提交
默认情况下,consumer是自动提交位移的,可以修改consumer端参数 enable.auto.commit=false 来设置提交方式为手动提交。默认情况下自动提交间隔为5秒,可以通过修改 auto.commit.interval.ms=1000 来配置自动提交的时间间隔。
自动提交降低了开发成本,但是不能细粒度处理位移提交。例如一个典型的consumer应用场景:用户需要对poll方法返回的消息集合中的消息执行业务级处理,只有消息真正被处理完之后再提交位移,使用自动提交位移显然没法保证这种时序性,因此这种情况下需要使用手动提交位移。手动提交位移时候,设置完 enable.auto.commit=false 之后,在需要提交位移的地方调用 consumer.commitAsync() 方法或者 consumer.commitSync() 方法即可,如以下例子所示:
/** * consumer接收消息测试 */ public void receiveMsg() throws IOException { String topicName = "testTopic"; //1.构造Properties对象 Properties consumerProps = new Properties(); FileInputStream fileInputStream = new FileInputStream("F:\\javaCode\\jvmdemo\\src\\main\\resources\\kafka-consumer.properties"); consumerProps.load(fileInputStream); fileInputStream.close(); //2.使用Properties构造KafkaConsumer对象 KafkaConsumer consumer = new KafkaConsumer(consumerProps); //3.调用KafkaConsumer的subscribe方法订阅consumer group感兴趣的topic列表 consumer.subscribe(Arrays.asList(topicName)); try { final int minBatchSize = 500; List<ConsumerRecord<String, String>> buffer = new ArrayList<>(); while (true) { //4.调用conusmer.poll方法 获取封装在consumerRecord中的消息 ConsumerRecords<String, String> records = consumer.poll(1000); System.out.println("调用poll"); for (ConsumerRecord<String, String> record : records) { //5.处理获取到的consumerRecord对象 buffer.add(record); } if (buffer.size() >= minBatchSize) { // 入库操作完之后提交位移 insertToDb(buffer); consumer.commitSync(); buffer.clear(); } } } finally { //6.关闭consumer consumer.close(); } }
在手动提交位移的时候, consumer.commitAsync() 方法是一个异步非阻塞提交,consumer在后续poll调用的时候会轮询该位移提交的结果。 consumer.commitSync() 方法是一个同步提交方法,当位移提交结束后才会执行下一条命令。
以上手动提交位移的时候,使用的 consumer.commitAsync() 及 consumer.commitSync() 是一个无参的提交方法,它会为所有它订阅的分区提交位移,可以选择有参方法只对consumer所拥有的分区进行位移提交,如下代码所示:
public void receiveMsg() throws IOException { String topicName = "testTopic"; //1.构造Properties对象 Properties consumerProps = new Properties(); FileInputStream fileInputStream = new FileInputStream("F:\\javaCode\\jvmdemo\\src\\main\\resources\\kafka-consumer.properties"); consumerProps.load(fileInputStream); fileInputStream.close(); //2.使用Properties构造KafkaConsumer对象 KafkaConsumer consumer = new KafkaConsumer(consumerProps); //3.调用KafkaConsumer的subscribe方法订阅consumer group感兴趣的topic列表 consumer.subscribe(Arrays.asList(topicName)); try { while (true) { //4.调用conusmer.poll方法 获取封装在consumerRecord中的消息 ConsumerRecords<String, String> records = consumer.poll(1000); System.out.println("调用poll"); for (TopicPartition partition : records.partitions()) { // 按照分区获取消息 List<ConsumerRecord<String, String>> partitionRecords = records.records(partition); for (ConsumerRecord<String, String> partitionRecord : partitionRecords) { System.out.println(partitionRecord.offset()+":"+partitionRecord.value()); } long lastOffset = partitionRecords.get(partitionRecords.size() - 1).offset(); // 按照分区提交位移 consumer.commitSync(Collections.singletonMap(partition,new OffsetAndMetadata(lastOffset+1))); } } } finally { //6.关闭cnsumer consumer.close(); } }
三、消费者组重平衡(rebalance)
rebalance只对cnosume group有效,对于standalone consumer,不存在rebalance的概念。rebalance实质上是一种协议,它规定了一个consumer group下所有的consumer如何达成一致性来分配订阅topic的所有分区。例如有个consumer group下有20个consumer,而该consumer group订阅了一个具有100个分区的topic,那么正常情况下,consumer group会为每个consumer分配5个分区,即每个consumer负责读取5个分区的数据,这个分配的过程称为rebalance。
1.rebalance触发条件
(1)组成员变更,如新的consumer加入组,或者consumer离开,亦或是consumer发生奔溃;
(2)组订阅的topic数发生变更;
(3)组订阅的topic的分区数发生变更。
2.rebalance分区分配
rebalance的时候group下面的consumer都会协调在一起共同参与分区分配。consumer默认提供了3种分区分配策略,分别是range策略,round-robin策略和sticky策略。
range策略主要基于范围的思想,它将单个topic的分区按照顺序排列,然后把这些分区划分为固定大小的分区段并依次分配给每个consumer;
round-robin策略则会把所有的topic分区顺序摆开,然后轮询式的分配各各个consumer;
sticky策略有效地避免了上述两种策略完全无视历史分配方案的缺陷,采用了“有黏性”的策略对所有consumer实例进行分配,可以避免极端情况下的数据倾斜并且在两次rebalance间最大限度的维持了之前的分配方案。
3.rebalance协议
rebalance本质上是一组协议,group和coordinator共同使用这组协议完成group的rebalance,最新版本kafka提供了如下5个协议来处理rebalance相关事宜:
JoinGroup请求:consumer请求加入组;
SyncGroup请求:group leader把分配方案同步更新到组内所有成员中;
HeartBeat请求:consumer定期向coordinator汇报心跳表明自己依然存活;
LeaveGroup请求:cosumer主动通知coordinator该consumer即将离组;
DescripeGroup请求:查看组的所有信息,包括成员信息,协议信息,分配信息以及订阅信息等。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号