


Day 3 Python语法
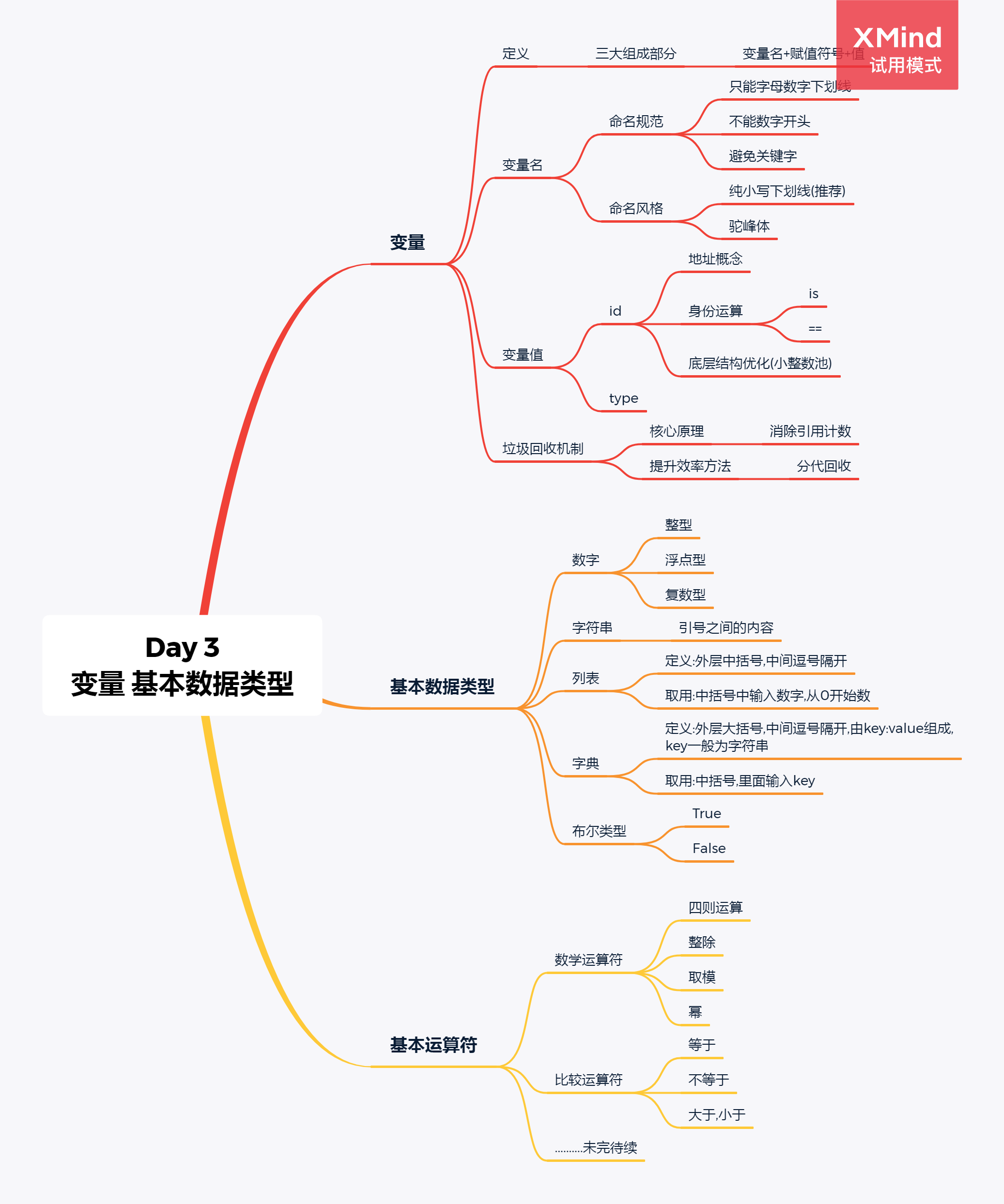
定义
三大组成部分
变量名相当于地址,指向值所在的内存地址
赋值符号为等号,将变量值的内存地址绑定给变量名
变量的值就是存储的数据,表示事物的状态
变量名
变量名命名规范
见名知义
-
变量名只能是 字母、数字或下划线的任意组合
-
变量名的第一个字符不能是数字
-
关键字不能声明为变量名,常用关键字如下
['and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'exec', 'finally', 'for', 'from','global', 'if', 'import', 'in', 'is', 'lambda', 'not', 'or', 'pass', 'print', 'raise', 'return', 'try', 'while', 'with', 'yield']
变量名命名风格
-
纯小写下划线(python中推荐)
matthews_is_genius
-
驼峰体
MatthewsIsGenius
变量值
两大特性
id
变量值的内存地址,内存地址不同id则不同
身份运算 is 和 ==
is是指前后两个变量id相等
==只是前后两个变量的值相等
(如果id相同,type和value一定相同)
小整数池
整数在程序中的使用非常广泛,Python为了优化速度,使用了小整数对象池, 避免为整数频繁申请和销毁内存空间。
Python 对小整数的定义是 [-5, 256] 这些整数对象是提前建立好的,不会被垃圾回收。在一个 Python 的程序中,无论这个整数处于LEGB中的哪个位置,
所有位于这个范围内的整数使用的都是同一个对象。同理,单个字母也是这样的。
#定义两个不同的变量,他们的值相同,但是id不同,来验证身份运算is和"=="
x = 10
y = 10
x == y
True
x is y
True # 因为小整数池
x = 10.23
y = 10.23
x == y
True
x is y
False # 内存地址不同(仅限于交互式环境,因为pycharm扩展了小整数池)
#pycharm中连复数的内存地址都是一样的
x=8+5j
y=8+5j
print(x is y)
运行结果
True
type
变量值的类型
垃圾回收机制 gc
garbage collection
核心原理
标记清除引用计数
提升效率方法
分代回收
更多的知识: https://stackify.com/python-garbage-collection/
二 基本数据类型
1.数字
定义
整型 Integers
浮点型 Floating-point numbers
复数型 Complex numbers
a+bj
(a为实部, b为虚部, 在电气领域因为与电流i容易搞混,所以改用j)
用法
# 数字类型的使用
level = 1 # 运算
level = level + 1
print(level)
print(10 + 2.7) # 整型和浮点型可以相加
age = 19
print(age > 18) # 整型和浮点型可以用来比较大小
# 运行结果
2
12.7
True
2.字符串 String
定义
在字符串两端使用引号
"cat" # 代表字符串
cat # 代表变量名
单引号和双引号没有任何区别,只是如果其中之一在字符串内部嵌套,那么代表字符串格式的就要用另一种,以防混淆
多引号可以用来引用多行内容
其他用法
字符串也有加法和乘法,只是开发过程中一般不使用
# 字符串加法
a = "Matthews"
b = " is "
c = "genius"
print(a + b + c)
Matthews is genius
# 字符串乘法应用
greeting = " i love u | "
print("*" * 80)
print(greeting * 6)
print("*" * 80)
********************************************************************************
i love u | i love u | i love u | i love u | i love u | i love u |
********************************************************************************
3.列表 list
定义
索引对应值,索引从0开始,对应第一个
在[]内用逗号分隔,可以存放n个任意类型的值
用法
stu_names='张三 李四 王五',但存的目的是为了取,此时若想取出第二个学生的姓名实现起来相当麻烦,而列表类型就是专门用来记录多个同种属性的值(比如同一个班级多个学生的姓名、同一个人的多个爱好等),并且存取都十分方便
可以嵌套使用
倒数
从后往前数也可以,第一个是-1
注意
取的时候第一项为0
# 列表的用法
hobby = ["chi", "he", "piao", "du"]
# 取出第三个爱好
print(hobby[2]) # 注意第一项是0
# 取出第二个组学生的第二个爱好
students_info = [
["boy", 32, ["piao", "du"]],
["girl", 28, ['chi', 'he']]
]
print(students_info[1][2][1])
piao
he
4.字典 dictionary
因为索引反应的是顺序,位置,对值没有描述性的功能,所以引入字典类型
key对应值,,其中key通常为字符串类型,所以key可以描述值
作用
如果我们需要用一个变量记录多个值,但多个值是不同属性的,比如人的姓名、年龄、身高,用列表可以存,但列表是用索引对应值的,而索引不能明确地表示值的含义,这就用到字典类型,字典类型是用key:value形式来存储数据,其中key可以对value有描述性的功能
定义
person_info={'name':'tony','age':18,'height':185.3}
用法
可以嵌套
# 字典嵌套用法
students_info = [
{"name": "boy1", "age": 22, "hobby": ["chi", "he", "piao", "du"]},
{"name": "boy2", "age": 19, "honny": ["la", "sa", "shui"]},
{"name": "boy3", "age": 21, "hobby": ["bu", "wu", "zheng", "ye"]}
]
# 取第三个学生的hobby的第三项
print(students_info[2]["hobby"][2])
zheng
5.布尔 Boolean
作用
用来记录真假的状态
定义
只有 true 和 false
'也可以用0和1表示
三 基本运算符
1.数学运算符
加减乘除 +-*/
取整除 //
取模 %
幂 **
2.比较运算符
相等
==
不等于
!=
大于小于(大于等于,小于等于)
四 补充了解
1.编程大佬不写注释
https://www.zhihu.com/question/27246926/answer/1214585389
1.只有烂的代码才需要注释 2.你什么时候产生了你的代码不烂的错觉?
2.go语言的诞生
https://studygolang.com/articles/25433
古语有云:“往古者,所以知今也”。在决定学习探究 Go 语言之前,了解一下它的诞生背景与发展脉络是很有必要的。这不仅能解开我们心中关于 Google 为什么要重复“造轮子”的疑惑,还有助于我们理解这门语言的设计哲学和应用场景。
3.git的诞生
https://juejin.cn/post/6844903741179576333
git 是世界上最先进的分布式版本控制系统,没有之一。
芬兰人性格内敛,这与 Torvalds 的行事方式不谋而合。但他对开源的信念是近乎执着的,为此不少树敌。
2018 年 10 月,在休假反省一个多月之后,Torvalds 继续接管内核开发。Torvalds 在维护项目上一向言行激烈,不少人因此而受到伤害。他表示「对自己过去的行为表示反悔,对因为他的言行而受到伤害的人表示道歉」。
4.不常用的数学运算
一般,数学运算适用于数字加数字
| 加法 | Str | Int/float | List | Dict |
|---|---|---|---|---|
| Str | √ | X | X | X |
| Int/Float | X | √ | X | X |
| List | X | X | √ | X |
| Dict | X | X | X | X |
字符串加字符串
上文已经提及
列表加列表
把后一个列表的内容加入前一个列表
字符串加数字(包括整型,浮点型,复数型),列表,字典
报错
列表+字典,字典+字典
报错
字符串乘以整型
上文已经提及
其他非数字参与的乘法全为报错
5.不常用的大小比较运算
比较运算一般用于数字之间,且只有同种类型的两者可以相互比较
字符串之间的比较
比较第一个字符的ASCII码大小,若相通,比较第二个,以此类推
列表之间的比较
必须对应位置的元素为同种类型才可比较,否则报错
从第一个元素顺序开始比较,如果相等,则继续,返回第一个不相等元素比较的结果。如果所有元素比较均相等,则长的列表大,一样长则两列表相等
字典之间的比较
报错

