第二次作业:卷积神经网络 part 3
一、代码练习
1.HybridSN
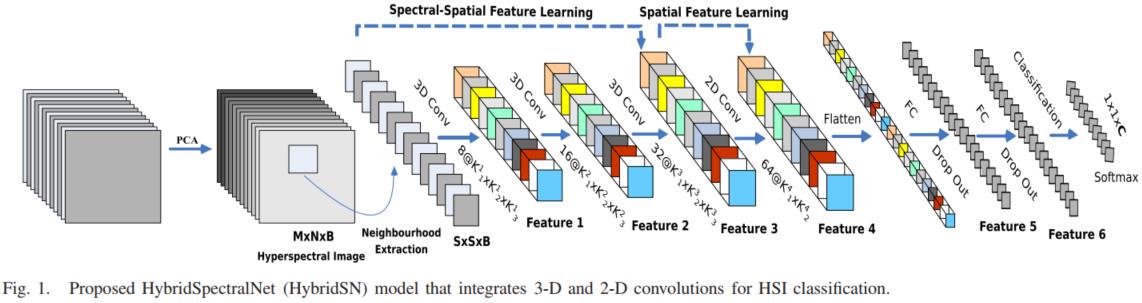
class_num = 16 class HybridSN(nn.Module): def __init__(self): super(HybridSN, self).__init__() # conv1:(1, 30, 25, 25), 8个 7x3x3 的卷积核 ==>(8, 24, 23, 23) self.conv1 = nn.Sequential( nn.Conv3d(1, 8, kernel_size=(7, 3, 3), stride=1, padding=0), nn.BatchNorm3d(8), nn.ReLU() ) # conv2:(8, 24, 23, 23), 16个 5x3x3 的卷积核 ==>(16, 20, 21, 21) self.conv2 = nn.Sequential( nn.Conv3d(8, 16, kernel_size=(5, 3, 3), stride=1, padding=0), nn.BatchNorm3d(16), nn.ReLU() ) # conv3:(16, 20, 21, 21),32个 3x3x3 的卷积核 ==>(32, 18, 19, 19) self.conv3 = nn.Sequential( nn.Conv3d(16, 32, kernel_size=(3, 3, 3), stride=1, padding=0), nn.BatchNorm3d(32), nn.ReLU() ) # conv4: (576, 19, 19), 64个 3x3 的卷积 ==> (64, 17, 17) self.conv4 = nn.Sequential( nn.Conv2d(576, 64, kernel_size=(3, 3), stride=1, padding=0), nn.BatchNorm2d(64), nn.ReLU() ) self.fc1 = nn.Linear(18496, 256) self.fc2 = nn.Linear(256, 128) self.fc3 = nn.Linear(128, class_num) self.dropout = nn.Dropout(p=0.4) def forward(self, x): # 进行三维卷积 out = self.conv1(x) out = self.conv2(out) out = self.conv3(out) # 进行二维卷积,把前面 32*18 reshape 一下,得到 (576, 19, 19) out = self.conv4(out.reshape(out.shape[0], -1, 19, 19)) # out.shape[0]--Batchsize; out.shape[1]--channel; # 接下来是一个 flatten 操作,变为 18496 维的向量 out = out.reshape(out.shape[0], -1) # 接下来依次为256,128节点的全连接层,都使用比例为0.4的 Dropout out = self.fc1(out) out = self.dropout(out) out = self.fc2(out) out = self.dropout(out) # 最后输出为 16 个节点,是最终的分类类别数 out = self.fc3(out) return out # 随机输入,测试网络结构是否通 x = torch.randn(1, 1, 30, 25, 25) net = HybridSN() y = net(x) print(y.shape) print(y)
2.SENet

class SELayer(nn.Module): def __init__(self, channel, r=16): super(SELayer, self).__init__() # Squeeze self.avg_pool = nn.AdaptiveAvgPool2d(1) # Excitation self.fc1 = nn.Linear(channel,round(channel/r)) self.relu = nn.ReLU() self.fc2 = nn.Linear(round(channel/r),channel) self.sigmoid = nn.Sigmoid() def forward(self,x): out = self.avg_pool(x) out = out.view(out.shape[0], out.shape[1]) out = self.fc1(out) out = self.relu(out) out = self.fc2(out) out = self.sigmoid(out) out = out.view(out.shape[0], out.shape[1], 1, 1) return x * out class_num = 16 class HybridSN(nn.Module): def __init__(self): super(HybridSN, self).__init__() self.conv1 = nn.Sequential( nn.Conv3d(1, 8, kernel_size=(7, 3, 3), stride=1, padding=0), nn.BatchNorm3d(8), nn.ReLU() ) self.conv2 = nn.Sequential( nn.Conv3d(8, 16, kernel_size=(5, 3, 3), stride=1, padding=0), nn.BatchNorm3d(16), nn.ReLU() ) self.conv3 = nn.Sequential( nn.Conv3d(16, 32, kernel_size=(3, 3, 3), stride=1, padding=0), nn.BatchNorm3d(32), nn.ReLU() ) self.conv4 = nn.Sequential( nn.Conv2d(576, 64, kernel_size=(3, 3), stride=1, padding=0), nn.BatchNorm2d(64), nn.ReLU() ) self.SELayer = SELayer(64, 16) self.fc1 = nn.Linear(18496, 256) self.fc2 = nn.Linear(256, 128) self.fc3 = nn.Linear(128, class_num) self.dropout = nn.Dropout(p=0.4) def forward(self, x): out = self.conv1(x) out = self.conv2(out) out = self.conv3(out) out = self.conv4(out.reshape(out.shape[0], -1, 19, 19)) out = self.SELayer(out) # 二维卷积后面添加SENet out = out.reshape(out.shape[0], -1) out = self.fc1(out) out = self.dropout(out) out = self.fc2(out) out = self.dropout(out) out = self.fc3(out) return out
二、视频学习
1.《语义分割中的自注意力机制和低秩重建》-李夏
语义分割:对图像每个像素进行分类并同时输出多个像素。
自注意力机制:注意力机制模仿了生物观察行为的内部过程,即一种将内部经验和外部感觉对其从而增加部分区域的观察精细度的机制。注意力机制可以快速提取稀疏数据的重要特征,因而被广泛用于自然语言处理任务。而自注意力机制是注意力机制的改进,其减少了对外部信息的依赖,更擅长捕捉数据或特征的内部相关性。
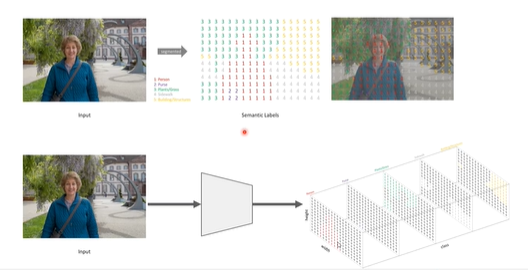
2.《 图像语义分割前沿进展》-程明明
传统神经网络对细节信息提取较好,但对全局信息来说消耗资源非常多。
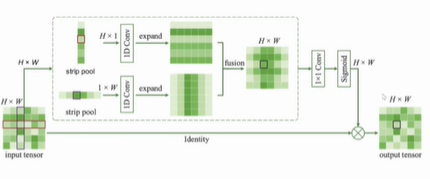
带状池化:使用条形的Pooling,可以得到各向异性的信息。
Strip Pooling模块
在进行语义分割的过程中,我们既需要细节信息,同时又需要捕捉全局的信息。
捕捉全局信息的方法,如:Non-local modules,Self-Attention,需要计算一个很大的affinity matrix; Dilated convolution,Pyramid/globlal pooling,很难获得各向异性的信息。
采用 Strip pooling 可以在一个方向上获得全局的信息,同时在另一个方向上获得细节信息。
采用横向和纵向的条状池化可以获得各向异性的信息。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号