第二次作业:卷积神经网络 part 2
1、代码练习
MobileNetV1 网络
class Block(nn.Module): '''Depthwise conv + Pointwise conv''' def __init__(self, in_planes, out_planes, stride=1): super(Block, self).__init__() # Depthwise 卷积,3*3 的卷积核,分为 in_planes,即各层单独进行卷积 self.conv1 = nn.Conv2d(in_planes, in_planes, kernel_size=3, stride=stride, padding=1, groups=in_planes, bias=False) self.bn1 = nn.BatchNorm2d(in_planes) # Pointwise 卷积,1*1 的卷积核 self.conv2 = nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=1, padding=0, bias=False) self.bn2 = nn.BatchNorm2d(out_planes) def forward(self, x): out = F.relu(self.bn1(self.conv1(x))) out = F.relu(self.bn2(self.conv2(out))) return out
class MobileNetV1(nn.Module): # (128,2) means conv planes=128, stride=2 cfg = [(64,1), (128,2), (128,1), (256,2), (256,1), (512,2), (512,1), (1024,2), (1024,1)] def __init__(self, num_classes=10): super(MobileNetV1, self).__init__() self.conv1 = nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=1, bias=False) self.bn1 = nn.BatchNorm2d(32) self.layers = self._make_layers(in_planes=32) self.linear = nn.Linear(1024, num_classes) def _make_layers(self, in_planes): layers = [] for x in self.cfg: out_planes = x[0] stride = x[1] layers.append(Block(in_planes, out_planes, stride)) in_planes = out_planes return nn.Sequential(*layers) def forward(self, x): out = F.relu(self.bn1(self.conv1(x))) out = self.layers(out) out = F.avg_pool2d(out, 2) out = out.view(out.size(0), -1) out = self.linear(out) return out
输出结果:
Accuracy of the network on the 10000 test images: 78.81 %
MobileNet V1 的主要问题:
1、结构非常简单,但是没有使用RestNet里的residual learning;
2、Depthwise Conv确实是大大降低了计算量,但实际中,发现不少训练出来的kernel是空的。
MobileNetV2 网络
主要改进点:
1、先用1x1卷积提升通道数,然后用Depthwise 3x3的卷积,再使用1x1的卷积降维
2、去掉输出部分的ReLU6,避免信息损失
class Block(nn.Module): '''expand + depthwise + pointwise''' def __init__(self, in_planes, out_planes, expansion, stride): super(Block, self).__init__() self.stride = stride # 通过 expansion 增大 feature map 的数量 planes = expansion * in_planes self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=1, stride=1, padding=0, bias=False) self.bn1 = nn.BatchNorm2d(planes) self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride, padding=1, groups=planes, bias=False) self.bn2 = nn.BatchNorm2d(planes) self.conv3 = nn.Conv2d(planes, out_planes, kernel_size=1, stride=1, padding=0, bias=False) self.bn3 = nn.BatchNorm2d(out_planes) # 步长为 1 时,如果 in 和 out 的 feature map 通道不同,用一个卷积改变通道数 if stride == 1 and in_planes != out_planes: self.shortcut = nn.Sequential( nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=1, padding=0, bias=False), nn.BatchNorm2d(out_planes)) # 步长为 1 时,如果 in 和 out 的 feature map 通道相同,直接返回输入 if stride == 1 and in_planes == out_planes: self.shortcut = nn.Sequential() def forward(self, x): out = F.relu(self.bn1(self.conv1(x))) out = F.relu(self.bn2(self.conv2(out))) out = self.bn3(self.conv3(out)) # 步长为1,加 shortcut 操作 if self.stride == 1: return out + self.shortcut(x) # 步长为2,直接输出 else: return out
class MobileNetV2(nn.Module): # (expansion, out_planes, num_blocks, stride) cfg = [(1, 16, 1, 1), (6, 24, 2, 1), (6, 32, 3, 2), (6, 64, 4, 2), (6, 96, 3, 1), (6, 160, 3, 2), (6, 320, 1, 1)] def __init__(self, num_classes=10): super(MobileNetV2, self).__init__() self.conv1 = nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=1, bias=False) self.bn1 = nn.BatchNorm2d(32) self.layers = self._make_layers(in_planes=32) self.conv2 = nn.Conv2d(320, 1280, kernel_size=1, stride=1, padding=0, bias=False) self.bn2 = nn.BatchNorm2d(1280) self.linear = nn.Linear(1280, num_classes) def _make_layers(self, in_planes): layers = [] for expansion, out_planes, num_blocks, stride in self.cfg: strides = [stride] + [1]*(num_blocks-1) for stride in strides: layers.append(Block(in_planes, out_planes, expansion, stride)) in_planes = out_planes return nn.Sequential(*layers) def forward(self, x): out = F.relu(self.bn1(self.conv1(x))) out = self.layers(out) out = F.relu(self.bn2(self.conv2(out))) out = F.avg_pool2d(out, 4) out = out.view(out.size(0), -1) out = self.linear(out) return out
输出结果:
Accuracy of the network on the 10000 test images: 80.10 %
2、论文阅读心得
1、《Beyond a Gaussian Denoiser: Residual Learning of Deep CNN for Image Denoising》
本论文最大的贡献就是第一次在图像降噪领域使用深度学习。
本论文提出了一种用于高斯去噪的端到端可训练深度CNN。与现有的基于深度神经网络的直接估计潜伏清洁图像的方法相比,该网络采用了残差学习策略从噪声观测中去除潜伏清洁图像。
残差学习和批量归一化可以极大地使CNN学习受益,因为它们不仅可以加快训练速度,而且可以提高去噪性能。对于具有一定噪声水平的高斯去噪,在定量指标和视觉质量方面,DnCNN均优于最新技术。
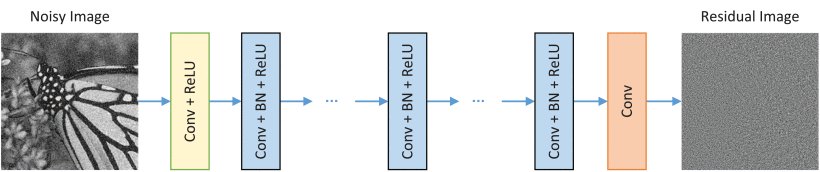
残差学习:在DnCNN中使用单个残差单元来预测残差图像。
网络模型:
2、Squeeze-and-Excitation Networks
Squeeze-and-Excitation Networks(SENet)是由自动驾驶公司Momenta在2017年公布的一种全新的图像识别结构,它通过对特征通道间的相关性进行建模,把重要的特征进行强化来提升准确率。
SENet的结构如下:
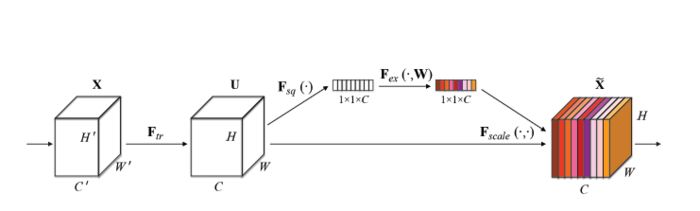
SENet把重要通道的特征强化,非重要通道的特征弱化,得到了很好的效果。
3、Deep Supervised Cross-modal Retrieval
本文提出了一种新的跨模态检索方法——深度监督跨模态检索(DSCMR)。它的目的是找到一个共同的表示空间,在这个空间中可以直接比较来自不同模式的样本。具体来说,DSCMR最大限度地减少了标签空间和公共表示空间的识别损失,以监督模型学习的识别特征。在此基础上,利用权值共享策略消除多媒体数据在公共表示空间中的交叉模态差异,学习模态不变特征。
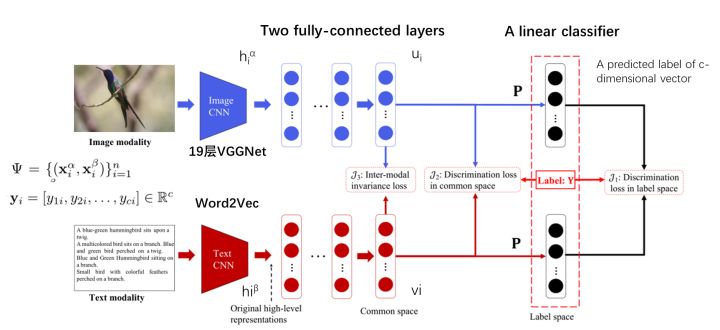
做出的贡献:
1.提出了一种基于深度监督的多模态学习结构,以弥补多模态间的异构性。通过端到端同时保持语义区分和模态不变性,可以有效地学习异构数据的公共表示。
2.提出了两种具有权值共享约束的子网络来学习图像和文本模态之间的交叉模态相关。另外,将模态不变性损失直接转化为目标函数,以消除模态间的差异。
3.利用线性分类器对公共表示空间中的样本进行分类。这样,DSCMR最大限度地减少了标签空间和公共表示空间的辨别损失,使得学习的公共表示具有显著的可区分性。
4.在广泛使用的基准数据集上进行了大量的实验。结果表明,该方法在跨模态检索方面优于现有的方法,表明了该方法的有效性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号