
202103226-1 编程作业
| 这个作业属于哪个课程 | 软工-2018级计算机2班 |
|---|---|
| 这个作业要求在哪里 | 作业要求 |
| 这个作业的目标 | 学习使用GITHUB或者码云 |
| 学号 | 20188452 |
| 参考文献 | eclipse中使用GIT或者码云(eclipse最新版自带GIT插件) |
| 参考文献 | 正则表达式的使用 |
文章主体
码云项目地址
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 8 | 20 |
| Estimate | 估计这个任务需要多少时间 | 60 | 360 |
| Development | 开发 | 120 | 240 |
| Analysis | 需求分析 (包括学习新技术) | 30 | 120 |
| Design Spec | 生成设计文档 | 30 | 15 |
| Design Review | 设计复审 | 5 | 3 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 30 | 0 |
| Design | 具体设计 | 15 | 30 |
| Coding | 具体编码 | 100 | 180 |
| Code Review | 代码复审 | 15 | 30 |
| Test | 测试(自我测试,修改代码,提交修改) | 20 | 60 |
| Reporting | 报告 | 30 | 30 |
| Test Repor | 测试报告 | 40 | 10 |
| Size Measurement | 计算工作量 | 0 | 0 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 15 | 5 |
| 合计 | 521 | 1178 |
解题思路描述
*1.通过控制台输入命令读取文件地址。
*2.通过BufferedReader读取文件。
*3.通过readLine()逐行读入计算字符长度和计算行数。
*4.逐个分隔读取单词计算单词总数(正则表达式)
*5.通过HASmap进行单个单词的统计。
代码规范连接:
https://gitee.com/fengmixinluo/project-java.git
计算模块接口的设计与实现过程
通过主函数中的参数对各个方法的路径进行传参。
*WordCount中
Lib.charnumber(f);
Lib.wordsnumber(f);
Lib.line(f);
Lib.Wordsfreqret(f);
*Lab中对各个方法的实现。
public class Lib {
public static int charnumber(File f) throws IOException {
public static int wordsnumber(File f) throws IOException {
public static int line(File f) throws IOException
public static String Wordsfreqret(File f)throws IOException

Lib.charnumber(f):
try {
String str = null;
while ((str = in.readLine()) != null) { //readLine()方法, 用于读取一行,只要读取内容不为空就一直执行
Number_of_characters += str.length(); //用于统计总字符数
}
//System.out.println("该文本共有" + Number_of_characters + "个字符"); //输出总的字符数
} catch (IOException e) {
e.printStackTrace();
}
return Number_of_characters;
}
Lib.wordsnumber(f):
try {
String temp = in.readLine();
cun = new StringBuffer();
while (temp != null) {
cun.append(temp);
cun.append(" "); //每行结束多读一个空格
temp = in.readLine();
}
} catch (Exception e) {
e.printStackTrace();
}
String info = cun.toString();
String regex = "[,。?,.? ]";
String s[] = info.split(regex);
/*统计单词个数*/
for (int i = 0; i < s.length; i++) {
if (s[i].length() >= 4) {
String temp = s[i].substring(0, 4);
temp = temp.replaceAll("[^a-zA-Z]", "");
if (temp.length() >= 4) {
wordnumber++;
}
}
}
计算模块接口部分的性能改进
最终代码测试截图:
测试代码:
long startTime = System.currentTimeMillis();
long endTime=System.currentTimeMillis();
long runetime=endTime - startTime;
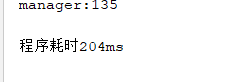
System.out.println("程序耗时"+runetime+"ms");
以前的软件自带测试就没写测试程序了,而我也只会写测试运行时间。
测试数据大小:
characters:59817
words:5581
lines414
以前的测试记录和commit记录:

计算模块部分单元测试展示。
统计文件的字符数(对应输出第一行):
只需要统计Ascii码,汉字不需考虑
空格,水平制表符,换行符,均算字符
统计文件的单词总数(对应输出第二行),单词:至少以4个英文字母开头,跟上字母数字符号,单词以分隔符分割,不区分大小写。
英文字母: A-Z,a-z
字母数字符号:A-Z, a-z,0-9
分割符:空格,非字母数字符号
例:file123是一个单词, 123file不是一个单词。file,File和FILE是同一个单词
统计文件的有效行数(对应输出第三行):任何包含非空白字符的行,都需要统计。
统计文件中各单词的出现次数(对应输出接下来10行),最终只输出频率最高的10个。
频率相同的单词,优先输出字典序靠前的单词。
例如,windows95,windows98和windows2000同时出现时,则先输出windows2000
输出的单词统一为小写格式
测试数据:

结果:
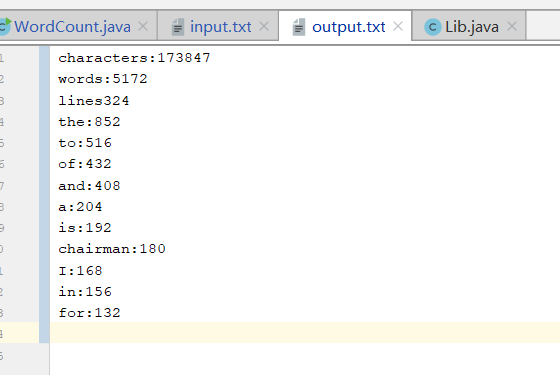
测试数据:
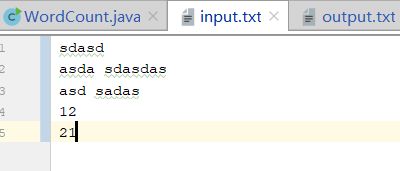
结果:
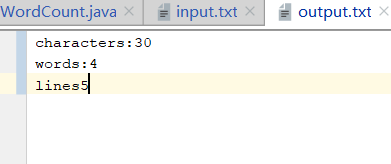
计算模块部分异常处理说明。
MaP返回值读取异常:
List<Map.Entry<String, Integer>> list = new ArrayList<Map.Entry<String, Integer>>(map.entrySet());
Collections.sort(list, valueComparator);
StringBuffer top10Words=new StringBuffer();
for (int i=0;i<10;i++) {
Map.Entry<String, Integer> entry = list.get(i);
System.out.println(entry.getKey() + ":" + entry.getValue());
top10Words.append(entry.getKey() + ":" + entry.getValue()+"\n");
}
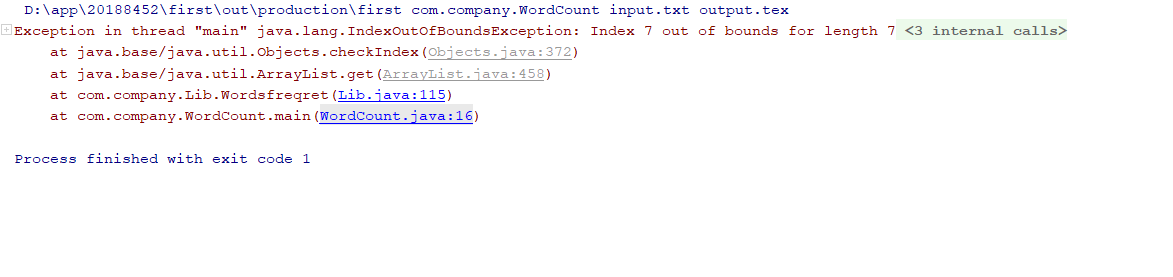
边界异常。。。数据小于10

对边界异常的修改:
List<Map.Entry<String, Integer>> list = new ArrayList<Map.Entry<String, Integer>>(map.entrySet());
Collections.sort(list, valueComparator);
StringBuffer top10Words=new StringBuffer();
for (int i=0;i<((10<=list.size())?10:list.size());i++) { //
Map.Entry<String, Integer> entry = list.get(i);
// 测试 System.out.println(entry.getKey() + ":" + entry.getValue());
top10Words.append(entry.getKey() + ":" + entry.getValue()+"\n");
}
return new String(top10Words);
}
心路历程与收获:
这个作业还是比较困难的,用了很多时间去完成它,但代码还是有很多不如意的地方只能说是勉强完成了吧,
但是也学到了挺多比如
*1.HAsmap的应用
*2.对基础知识的巩固
*3.程序总体设计要加强。

