
sql优化小tips
sql优化小tips
基础sql优化
1、避免使用select * 尽量要什么字段查什么字段,
select * 多查出来的数据在网络上IO传输的过程中,会增加数据传输的是的时间。且 select *不会走覆盖索引,会出现大量的回表操作,而从导致查询sql的性能很低。
覆盖索引(Covering Index):
覆盖索引是指一个索引不仅包含了查询中的所有列,而且还包含了查询结果中的所有列。使用覆盖索引可以提高查询性能,因为数据库查询可以直接从索引中获取所需的数据,而不需要回表到主表中去检索额外的数据。这样可以减少磁盘I/O操作,提高查询效率。
例如,如果有一个查询:
SELECT column1, column2 FROM table WHERE column3 = value;
如果存在一个索引同时包含了 column1、column2 和 column3,那么这个索引就是一个覆盖索引。
回表(Back to Table):
回表是指在使用索引查找数据时,如果索引中没有包含查询所需的所有列,数据库就需要回到主表中去检索那些未包含在索引中的列。这个过程称为回表。回表可能会降低查询性能,因为它需要额外的磁盘I/O操作。
继续上面的例子,如果索引只包含了 column3,而没有包含 column1 和 column2,那么在找到符合条件的行后,数据库还需要回到主表中去检索 column1 和 column2 的值,这个过程就是回表。
2、用union all代替union
UNION 操作符用于连接两个以上的 SELECT 语句的结果组合到一个结果集合,并去除重复的行
我们都知道sql语句使用union关键字后,可以获取排重后的数据。而如果使用union all关键字,可以获取所有数据,包含重复的数据。排重的过程需要遍历、排序和比较,它更耗时,更消耗cpu资源。所以如果能用union all的时候,尽量不用union。
演示数据库
在本教程中,我们将使用 RUNOOB 样本数据库。
下面是选自 "Websites" 表的数据:
mysql> SELECT * FROM Websites;
+----+--------------+---------------------------+-------+---------+
| id | name | url | alexa | country |
+----+--------------+---------------------------+-------+---------+
| 1 | Google | https://www.google.cm/ | 1 | USA |
| 2 | 淘宝 | https://www.taobao.com/ | 13 | CN |
| 3 | 菜鸟教程 | http://www.runoob.com/ | 4689 | CN |
| 4 | 微博 | http://weibo.com/ | 20 | CN |
| 5 | Facebook | https://www.facebook.com/ | 3 | USA |
| 7 | stackoverflow | http://stackoverflow.com/ | 0 | IND |
+----+---------------+---------------------------+-------+---------+
下面是 "apps" APP 的数据:
mysql> SELECT * FROM apps;
+----+------------+-------------------------+---------+
| id | app_name | url | country |
+----+------------+-------------------------+---------+
| 1 | QQ APP | http://im.qq.com/ | CN |
| 2 | 微博 APP | http://weibo.com/ | CN |
| 3 | 淘宝 APP | https://www.taobao.com/ | CN |
+----+------------+-------------------------+---------+
3 rows in set (0.00 sec)
SQL UNION 实例
下面的 SQL 语句从 "Websites" 和 "apps" 表中选取所有不同的country(只有不同的值):
实例
SELECT country FROM Websites UNION SELECT country FROM appsORDER BY country;
执行以上 SQL 输出结果如下:
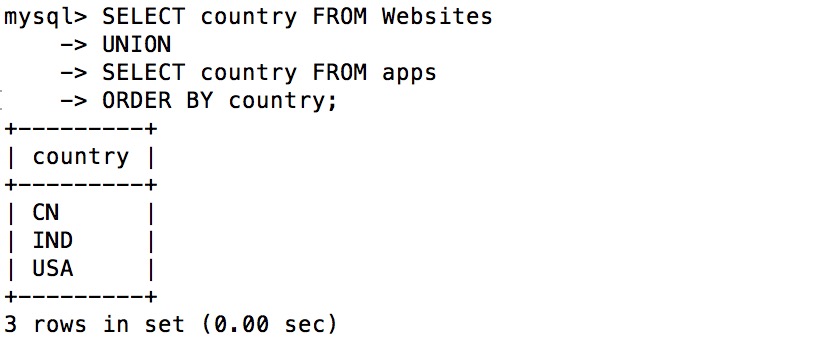
注释:UNION 不能用于列出两个表中所有的country。如果一些网站和APP来自同一个国家,每个国家只会列出一次。UNION 只会选取不同的值。请使用 UNION ALL 来选取重复的值!
SQL UNION ALL 实例
下面的 SQL 语句使用 UNION ALL 从 "Websites" 和 "apps" 表中选取所有的country(也有重复的值):
实例
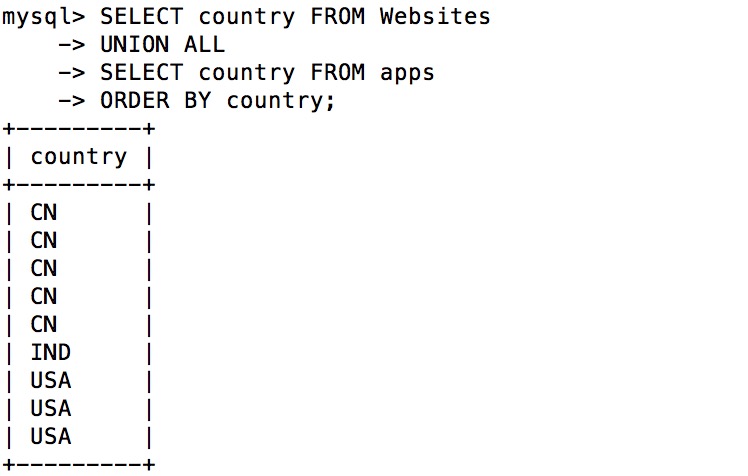
SELECT country FROM Websites UNION ALL SELECT country FROM apps
ORDER BY country;
执行以上 SQL 输出结果如下:
带有 WHERE 的 SQL UNION ALL
下面的 SQL 语句使用 UNION ALL 从 "Websites" 和 "apps" 表中选取所有的中国(CN)的数据(也有重复的值):
实例
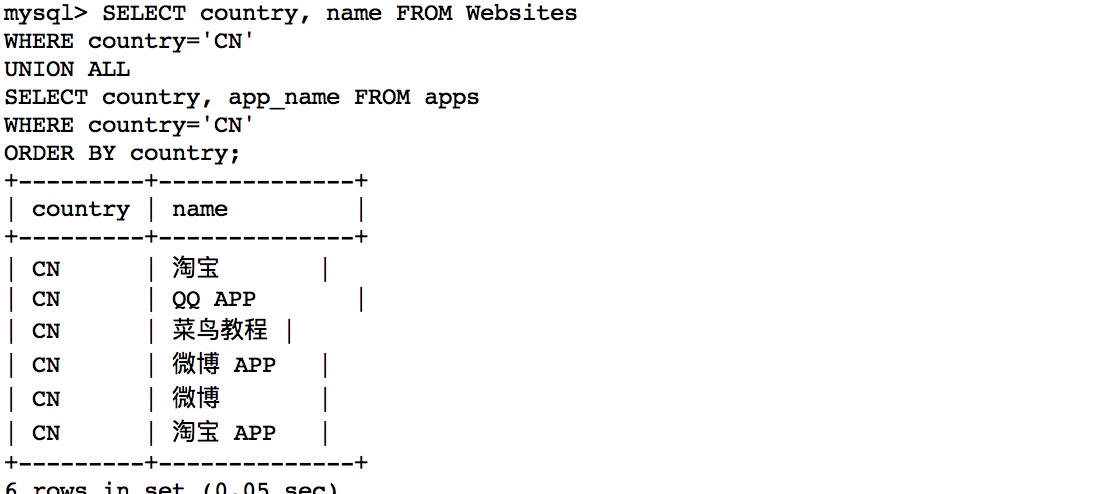
SELECT country, name FROM Websites WHERE country='CN'
UNION ALL
SELECT country, app_name FROM apps WHERE country='CN'ORDER BY
country;
执行以上 SQL 输出结果如下:
3、小表驱动大表
减少数据集、减少回表操作、减少内存和CPU使用
4、批量操作
减少请求数据次数,利用批量操作来减轻CPU压力,sql性能会得到提升,数据量越多,提升越大。为防止数据库响应过慢,需要注意的是把握好每批数据的量,控制在500以内。
insert into order(id,code,user_id)
values(123,'001',100),(124,'002',100),(125,'003',101);
5、多用limit
减少数据查找
6、SQL查找是否"存在",别再count了!
7、高效的分页
记录上次的查询的maxID,用条件ID>max limit ??,来分页
8、连接查询代替子查询
mysql中如果需要从两张以上的表中查询出数据的话,一般有两种实现方式:子查询 和 连接查询。
子查询的例子如下:
select * from order
where user_id in (select id from user where status=1)
子查询语句可以通过in关键字实现,一个查询语句的条件落在另一个select语句的查询结果中。程序先运行在嵌套在最内层的语句,再运行外层的语句。
子查询语句的优点是简单,结构化,如果涉及的表数量不多的话。
但缺点是mysql执行子查询时,需要创建临时表,查询完毕后,需要再删除这些临时表,有一些额外的性能消耗。
这时可以改成连接查询。具体例子如下:
select o.* from order o
inner join user u on o.user_id = u.id
where u.status=1
9、选择合理的字段类型
减少空间浪费


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义