
从头设计一个聊天机器人(进化史)
啦啦啦,让我们来设计一个智障聊天机器人吧!
60年代聊天机器人
首先,在1960s,在第一次人工智能浪潮,最早的聊天机器人是设计用于治疗临床心理患者。这些患者因为心理缺乏安全感,会反复的询问医生一些问题求得安慰,于是最早的智障玩意聊天机器人问世了,聊天机器人会反复的回答病人的提问。
所以我们准备一个excel表或者数据库,来进行一个小游戏。
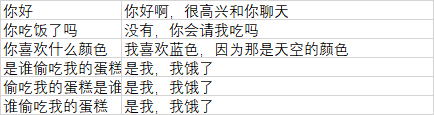
第一列是我们问的问题,第二列是答案。
当我们输入第一列,计算机程序将查找相符的第一列并把第二列的回答显示出来,这就是最简单的聊天机器人了。
文本相似度
在第一次人工智能浪潮失败后之后,计算机又有所发展,机器学习有所发展,文本相似度技术开始提出并取得发展。编辑距离,欧拉距离,余弦相似度,哈希相似等确定两个文本是否相似的算法提出。

我们可以看出三个问题实际上差距非常小,实际上是一个问题。如果一个个的枚举出每个问题,那么对于计算机存储与检索技术来说,代价极其高昂,语料的制作与程序反应速度是我们无法接受的。
想一想我们把“是谁偷吃我的蛋糕”,经过分词工具分成“是 谁 偷 吃 我 的 蛋糕 ”;“偷吃我的蛋糕是谁”,经过分词工具分成“偷 吃 我 的 蛋糕 是 谁”;“谁偷吃我的蛋糕”经过分词工具分成“谁 偷 吃 我 的 蛋糕” 。
我们可以看出它们三个的分词后是由几乎一样的词语构成,那么我们可以看出他们的词语的集合是相似甚至是一样的。如果通过比较其中相同的词语数量和句子中最大词语数量,我们可以区分他们的相似度程度,那么我们需要找个值来形容一下它们文本之间相似程度。
“是谁偷吃我的蛋糕”“偷吃我的蛋糕是谁”他们词语集合是完全相似的,所以公式是
s/MAX(count(l1),count(l2)),l1是“是谁偷吃我的蛋糕”,l2是“偷吃我的蛋糕是谁”,count(l1)是取得l1句子的词语集合的词语数量,count(l2)是取得l2句子的词语集合的词语数量,MAX(count(l1),count(l2))是取两个句子中词语数量最大值,s是两个词语集合之间相同的词语数量,s/MAX(count(l1),count(l2))可以取得一个从0至1之间的数,称之为置信度。我们一般使用1代表完全相似,0代表完全不相似。
所以计算得“是谁偷吃我的蛋糕”“偷吃我的蛋糕是谁”置信度为1,“是谁偷吃我的蛋糕”“谁偷吃我的蛋糕”置信度为6/7,所以相比之下,“是谁偷吃我的蛋糕”“偷吃我的蛋糕是谁”之间更为相似。
其他的编辑距离,余弦相似度等文本相似度算法都是用某种方法确定文本之间的相似度。
如果测试者输入类似于问题的文本,置信度又高于某个值(一般我们选用0.65,因为黄金分割点总是具有魔法力量),我们认为问题是相似的可以使用相似的问题来进行查找回答。
但我们也可以发现问题关于具体的事情,不同的问题实际上是指向一个事情,相似的问题指向不同的问题。这个一直是聊天机器人的难点,这在文章后面的章节会有谈到。
事实上,文本相似度并没有在刚提出并没有在聊天机器人上大规模使用,因为文本相似度虽然有效解决了语料问题,但是会带来内存和计算的压力,在当时的计算机的计算和存储能力来说是成本高昂的,意味着使用的代价计算机界无法承受。
另外对于英文来说,语法句式在书面方面比较固定,所以意味着不会有中文这样迫切的相似问题的需求。
如果你使用数据库,那么在SQL中可以使用differ,MYSQL中可以使用布尔查询,ORCLE中可以使用similar函数来进行简单的文本相似度,也可以在自定义函数中完成文本相似度算法的实现。不过我们一般在程序后台中完成文本相似度便于进行其他操作,而不是在数据库中。
90年代聊天机器人
90年代随着聊天机器人勒布纳奖的设立,旨在奖励最擅长模仿人类真实对话场景的机器人。聊天机器人的设计者们经过多年设计逐渐设计出来模板法来改进聊天机器人,创建了人工智能标记性语言来对回答进行改进。这就是大名鼎鼎的alice机器人。我形容它是类似于诸葛连弩,加特林,电子管步话机等超时代的产物,人类的智慧总是能突破常理。
新型的聊天机器人使用树状结构进行匹配。第一个词作为第一个节点,之后使用指针连接到后面词,每一条路径是一个完整的句子。所有的语料将形成一个森林。


Alice由数千名志愿者以及计算机专家进行制作语料,拥有6万条以上的模板,用于应对谈话人的问题
21世纪聊天机器人
语义理解
知识图谱
大词林
以后有空写这个系列,穷到吃土
