获取元素信息
来自:https://www.cnblogs.com/yoyoketang/p/6486927.html
https://www.cnblogs.com/yoyoketang/p/6512604.html
前言
通常在做断言之前,都要先获取界面上元素的属性,然后与期望结果对比。本篇介绍几种常见的获取元素属性方法。
一、获取页面title
1.有很多小伙伴都不知道title长在哪里,看下图左上角。
2.获取title方法很简单,直接driver.title就能获取到
from selenium import webdriver driver = webdriver.Chrome() driver.implicitly_wait(10) driver.get("http://www.baidu.com") title = driver.title print(title) 结果: 百度一下,你就知道
二、获取元素的文本
1.如下图这种显示在页面上的文本信息,可以直接获取到
2.查看元素属性:
<a id="setf" href="//www.baidu.com/cache/sethelp/help.html" onmousedown="return ns_c({'fm':'behs','tab':'favorites','pos':0})" target="_blank">把百度设为主页</a>
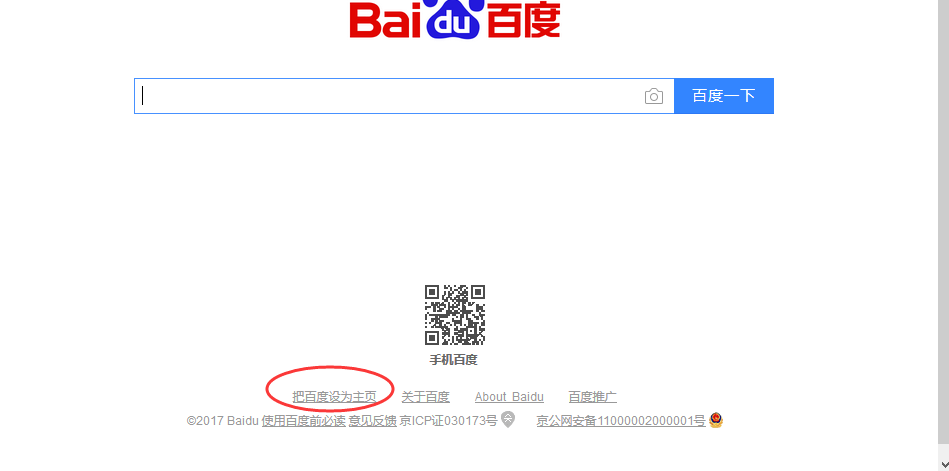
3.通过loc.text获取到文本
from selenium import webdriver driver = webdriver.Chrome() driver.implicitly_wait(10) driver.get("http://www.baidu.com") text = driver.find_element_by_id("setf").text print(text) 结果: 把百度设为主页
三、获取元素的ID、位置、标签名、大小、相对坐标
1.获取百度输入框的id(loc.id)、位置(loc.location)、标签属性(loc.location)、元素大小(高和宽)(loc.size)、元素大小和位置(loc.rect)、元素的相对坐标(loc.location_once_scrolled_into_view)
from selenium import webdriver import time driver = webdriver.Chrome() driver.implicitly_wait(10) driver.get("http://www.baidu.com") driver.set_window_size(400,400) loc = driver.find_element_by_id("su") print(loc.id) # 获取元素id print(loc.location) # 获取元素位置 print(loc.tag_name) # 获取元素标签名 print(loc.size) # 获取元素的大小(高和宽) print(loc.rect) # 获取元素大小和位置的字典 time.sleep(3) # 添加延时观察页面变化 print(loc.location_once_scrolled_into_view) # 将元素滚动到视频可以显示的位置,再返回元素的相对坐标 结果: 0.7024286069944854-1 {'x': 624, 'y': 193} input {'height': 36, 'width': 100} {'height': 36, 'width': 100, 'x': 624, 'y': 193} {'x': 269, 'y': 192}
四、获取元素的其它属性
1.获取其它属性方法:loc.get_attribute("属性"),这里的参数可以是class、name等任意属性
2.如获取百度输入框的class属性
from selenium import webdriver driver = webdriver.Chrome() driver.implicitly_wait(10) driver.get("http://www.baidu.com") name = driver.find_element_by_id("kw").get_attribute("class") print(name) 结果: s_ipt
五、获取输入框内的文本值
1、如果在百度输入框输入了内容,这里输入框的内容也是可以获取到的,获取文本值方法:loc.get_attribute("value")
from selenium import webdriver driver = webdriver.Chrome() driver.implicitly_wait(10) driver.get("http://www.baidu.com") driver.find_element_by_id("kw").send_keys("python") value = driver.find_element_by_id("kw").get_attribute("value") print(value) 结果: python
六、获取浏览器名称
1.获取浏览器名称很简单,用driver.name就能获取到了
from selenium import webdriver driver = webdriver.Chrome() # driver.implicitly_wait(10) # driver.get("http://www.baidu.com") print(driver.name) 结果: chrome
七、获取页面源码
有时候通过元素的属性的查找页面上的某个元素,可能不太好找,这时候可以从源码中爬出想要的信息。selenium的page_source方法可以获取到页面源码。
selenium的page_source方法很少有人用到,小编最近看api不小心发现这个方法,于是突发奇想,这里结合python的re模块用正则表达式爬出页面上所有的url地址,可以批量请求页面url地址,看是否存在404等异常。
获取到页面源码:
from selenium import webdriver driver = webdriver.Chrome() driver.implicitly_wait(10) driver.get("http://www.baidu.com") print(driver.page_source)
结合python的re模块用正则表达式爬出页面上所有的url地址:
from selenium import webdriver import re driver = webdriver.Chrome() driver.implicitly_wait(10) driver.get("http://www.baidu.com") page = driver.page_source # print(page) # 利用正则表达式匹配出页面上所有的url地址 url_list = re.findall('href=\"(.*?)\"',page) # for i in url_list: # print(i) # 匹配出来之后发现有一些不是url链接,可以筛选下。加个if语句判断,‘http’在url里面说明是正常的url地址了 urls = [] for url in url_list: if 'http' in url: urls.append(url) print(urls)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号