第二周
一、Linux安全模型
Linux是一个多用户多任务操作系统,它允许多个用户从本地或远程登录到系统。
-
Authentication认证:对用户的身份进行认证。
-
Authorization授权:认证之后对你能进行的工作进行授权。
-
Accounting审计:记录你所做的所有工作。
当用户登录成功时,系统会自动分配令牌token,包括:用户标识和组成员等信息。
1.1 用户
用户的类型:用户的类型通过用户标识符UID来区分,系统中所有用户UID具有唯一性。
Linux中的用户类型包括三种类型:超级用户、系统用户和普通用户。
- 系统管理员:root账户,UID号为0,拥有对系统的最高访问权限
- 系统用户:为满足Linux系统管理所内建的账号,通常在安装服务过程中自动创建,不能用于登陆操作系统。UID的范围为1-999,如halt、mail,nginx,mysql账号等,一般不需要修改该类用户的默认设置
- 普通用户:由root管理员创建,供用户登录系统操作使用的账号,UID在1000开始
可以使用id命令显示有关当前已登录用户的信息:
$ id
uid=0(root) gid=0(root) groups=0(root)
1.1.1 用户等配置文件
-
/etc/passwd: 用户的配置文件
用户名:口令:用户标识号(UID):组标识号(GID):注释性描述:家目录:登录shell -
/etc/shadow: 账户密码的配置文件
登录名:加密口令:最后一次修改时间:多少天后才能修改密码:密码有效期:密码过期前提示的天数:密码过期后的宽限时间:账号有效期 # 注:如最后一次修改时间为19197 ,表示是1970年1月1日后的19197天修改了密码信息。也就是2022年7月24号修改了密码信息。 $ date -d '1970-01-01 19197 day' '+%F %T' 2022-07-24 00:00:00
1.2 用户组
每个用户都有一个用户组,系统可以对一个用户组中的所有用户进行集中管理。不同Linux 系统对用户组的规定有所不同,如Linux下的用户属于与它同名的用户组,这个用户组在创建用户时同时创建。
1.2.1 用户组配置文件
-
/etc/group:组的配置文件,记录Linux包含的组的信息
组名:口令:组标识号:组内用户列表 -
/etc/gshadow:组的密码配置文件
组名:口令:组管理员:组内用户列表
二、文件权限和属性
Linux的文件权限和属性如下所示:
$ ll /etc/hosts
-rw-r--r--. 1 root root 182 Jan 3 02:21 /etc/hosts
按照分类,以上可分为八个部分:
-
第一部分,也就是第一位,表示文件类型:
- 表示此文件是普通文件
d 表示此文件是目录
l 表示此文件是软链接文件
b 表示此文件是设备文件(块设备)
c 表示此文件是设备文件(字符设备)
p 表示此文件是管道文件
s 表示此文件是socket文件
-
第二部分,也就是二到十位,表示文件的属性。一共有9位,每3位为一组(每组分别表示 u(所有者)、 g(所属组)和 o(其它者)的权限)。其中,每组的三个权限位分别为r(读),w(写),x(执行)权限。
这三个权限可以用数字表示,分别为4,2,1
-
第三部分,也就是第十一位:
当为点(.)时,表示selinux机制,当系统在selinux开启状态下生成的文件就会有此标识
当为加号(+)时,表示此文件设置了acl
-
第四部分,表示此文件的硬链接数量
-
第五部分,表示此文件的所有者和所属组
-
第六部分,表示文件的大小,单位字节
-
第七部分,表示文件最后一次被修改的日期和时间
-
第八部分,文件名
2.1 设置文件的权限
设置文件权限的命令有chmod,chown。
- chmod:修改文件的权限。
- chown:修改文件的所有者和所属组。
2.1.1 chmod
语法格式:
chmod [OPTION]... MODE[,MODE]... FILE...
OPTION:
-R 递归更改
MODE:
表示要设置的权限,上面提到,权限可以用数字表示,这里也可以用数字设置权限。如644(rw-r--r--)
也可以使用字母表示,此方法用法较多,在下面的范例展示
FILE:
可以同时设置多个文件
范例:
# 数字法
$ chmod 644 test
$ ll
total 0
-rw-r--r-- 1 root root 0 Jan 6 03:51 test
# 字母法
# 给所有者添加可执行权限,给所属组添加可写权限,取出其他者的读读权限
$ chmod u+x,g+w,o-r test
$ ll
total 0
-rwxrw---- 1 root root 0 Jan 6 03:51 test
# 还可以使用等号表示
$ chmod g=rw,o=r test
$ ll
total 0
-rwxrw-r-- 1 root root 0 Jan 6 03:51 test
# 也可以不指定用户,为所有人加上可执行权限
$ chmod +x test
$ ll
total 0
-rwxrwxr-x 1 root root 0 Jan 6 03:51 test
2.1.2 chown
格式
chown [OPTION]... [OWNER][:[GROUP]] FILE...
OPTION:
-R 递归更改
[OWNER][:[GROUP]]:
所有者和所属组
范例
# 将文件的所属组更改为dev
$ chown :dev test
$ ll
total 0
-rwxrwxr-x 1 root dev 0 Jan 6 03:51 test
# 将文件的所有者和所属组都设置为admin
$ chown admin: test
$ ll
total 0
-rwxrwxr-x 1 admin admin 0 Jan 6 03:51 test
$ chown root:admin test
$ ll
total 0
-rwxrwxr-x 1 root admin 0 Jan 6 03:51 test
2.2 权限分别在文件和目录下的区别
| r | w | x | |
|---|---|---|---|
| 文件 | 可读,如cat | 可写,如修改文件内容 | 可执行,如./file |
| 目录 | 可查看,如ls | 可写,创建文件,如touch | 可进入文件,如cd |
其实,只有当目录的权限至少为wx时,才能创建、删除(在知道路径的情况下)文件。
2.3 特殊权限
除了以上常见的rwx权限以外,还有三个特殊权限,它们分别是SUID、SGID、SBIT。
-
SUID,用于设置在可执行文件上。当执行有SUID权限的文件时,使用者就会临时获得文件所有者的权限。比如,使用passwd设置密码时会将信息写入到/etc/shadow文件中,而此文件对于普通用户是没有任何权限的,普通用户之所以能够设置密码是因为/bin/passwd就拥有SUID权限。
设置方法:u+s 4
-
SGID,用于设置在可执行文件或目录上。和SUID的功能类似,设置在文件上时,使用者会临时获得文件所属组的权限。当设置在目录上时,创建的文件就会自动继承所属组的名字。
设置方法:g+s 2
-
SBIT,用于设置在目录上。可以确保用户只能删除自己的文件,而不能删除其他人的文件。(除了设置了SBIT目录的所有者,也就是说设置了SBIT的目录的所有者可以删除任意用户的文件,所以目录所有者建议设置为root)。
设置方法:o+t 1
SUID,SGID,SBIT也有对应的数字表示方法,分别是4,2,1。也就是说777并不是最大权限,最大权限应该是7+777(rwsrwsrwt)。第一位表示特殊权限。
当特殊权限位为大写时,表示此权限位有一般权限,当特殊权限位为大写时,表示此权限位没有一般权限。
-
比如在
rwxr-xr-t的权限中,最后一位是t,说明一般权限为rwxr-xr-x(755),而SBIT为1,合并在一起则是1775。 -
如果权限是
rwsrwSr--,第一个s为小写s,则一般权限为x;第二个为S,则一般权限为-。所以整体的一般权限为rwxrw-r--(764)。而SUID和SGID分别为4和2。合并在一起则是6764。
2.3.1 设置特殊权限
SUID:
# 只有root能够读取,修改shadow文件
$ ll /etc/shadow
---------- 1 root root 1215 Jan 6 05:30 /etc/shadow
# passwd命令具有SUID权限
$ ll /bin/passwd
-rwsr-xr-x. 1 root root 33424 Apr 20 2022 /bin/passwd
# 取消SUID权限
$ chmod u-s /bin/passwd
$ ll /bin/passwd
-rwxr-xr-x. 1 root root 33424 Apr 20 2022 /bin/passwd
# 切换普通用户并修改密码
$ su - test
$ passwd
Changing password for user test.
Current password:
New password:
Retype new password:
passwd: Authentication token manipulation error # 无法读取文件
# 切换回root,恢复权限
$ chmod u+s /bin/passwd
# 再次修改密码
$ su - test
$ passwd
Changing password for user test.
Current password:
New password:
Retype new password:
passwd: all authentication tokens updated successfully.
SGID:
# 设置权限
$ chmod g+s /opt/
$ ll -d /opt
drwxr-srwx. 2 root root 18 Jan 6 05:51 /opt/
# 切换用户
$ su - test
$ touch /opt/test
$ ll /opt/test
-rw-rw-r-- 1 test root 0 Jan 6 05:51 /opt/test # 自动继承了root组
SBIT:
# 设置权限
$ chmod o+t /tmp/
$ chown test:test /tmp/
$ ll -d /tmp/
drwxrwxrwt. 7 test test 93 Jan 6 05:54 /tmp/
# 创建文件
$ cd /tmp
$ touch root
# 切换用户
$ su test
$ touch test
# 切换用户
$ su admin
$ touch admin
# 切换至test用户
$ su test
$ ll
total 0
-rw-rw-r-- 1 admin admin 0 Jan 6 06:01 admin
-rw-r--r-- 1 root root 0 Jan 6 06:01 root
-rw-rw-r-- 1 test test 0 Jan 6 06:01 test
# 此时test可以删除任意用户的文件,因为/tmp目录的所有者为test
$ rm -rf root
$ ls
admin test
# 切换至admin用户
$ su admin
$ ls
admin test
$ rm -rf test
rm: cannot remove 'test': Operation not permitted # 不能删除其他用户的文件
$ rm -rf admin # 仅能删除自己的文件
$ ls
test
SBIT对于root用户来说是没有限制的。
2.4 ACL 文件访问控制列表
文件访问控制列表可以针对单个用户/组来设置权限。
此功能来自acl包。主要包含setfacl、getfacl命令。
- setfacl:用于设置文件访问控制列表。
- getfacl:用于查看文件访问控制列表。
2.5.1 setfacl命令
语法格式
setfacl [-bkndRLPvh] [{-m|-x} acl_spec] [{-M|-X} acl_file] file ...
-m:修改权限
-M:从文件中读取权限
-x:删除某个权限
-b:删除全部权限
-R:递归子目录
# 只列出了常见的选项,更多的选项请查看man手册
2.5.2 getfacl命令
语法格式
getfacl [-aceEsRLPtpndvh] file ...
-a:显示文件访问控制列表,可以省略
-d:显示默认的文件访问控制列表
-c:不要显示注释头
-R:递归列出所有文件和目录的ACL
-t:使用表格的格式显示
-n:将用户和组显示为UID和GID
2.5.3 范例
# 设置acl
$
$ setfacl -m u:admin:rw test
# 前面提到过,当文件权限的第十一位为+时,表示此文件设置了acl
$ ll test
-rw-rw-r--+ 1 root root 0 Jan 6 16:09 test
# 查看acl
$ getfacl -ct test
# file: test
USER root rw-
user admin rw-
GROUP root r--
mask rw-
other r--
# 验证
$ su admin
$ echo hello > test
$ cat test
hello
----------------------------------------------------------------------------------
# 设置acl
$ setfacl -m u:admin:r test
$ getfacl -ct test
# file: test
USER root rw-
user admin r--
GROUP root r--
mask r--
other r--
$ chmod o=rw test
$ ll test
-rw-r--rw-+ 1 root root 6 Jan 6 16:16 test
# 验证
$ su admin
$ echo nihao > test
bash: test: Permission denied
# 可以看到,当文件普通权限和acl权限同时存在时,acl权限优先级高。
---------------------------------------------------------------------------------
# 删除权限
$ setfacl -x u:admin test
三、VIM
vim三种模式 命令模式,输入模式,底线命令模式。
- 命令模式:使用vim打开一个文件时就是此模式。
- 输入模式:在命令模式下,按i(当然其他键也可以)就可以进入输入模式。
- 底线命令模式:在任何模式下,只要按Esc + : 就可以进入此模式。
3.1 练习
# 打开文件
$ vim /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
"/etc/hosts" 2L, 158C
-----------------------------------------------------------------------------------
# 退出文件:进入底线命令模式,并输入q
# q表示在没有修改文件的情况下退出文件
# wq表示保存退出文件
# q!表示强制退出,不保存退出文件
编辑文件
$ vim test
"test" [New File]
----------------------------------------------------------------------------------
# 输入i进入插入模式
-- INSERT --
-----------------------------------------------------------------------------------
# 输入内容
马哥出品,必属精品
-----------------------------------------------------------------------------------
# 按ESC + : wq保存退出
:wq
-----------------------------------------------------------------------------------
# 查看内容
$ cat test
马哥出品,必属精品
在命令模式下,有很多命令可选。比如可以按"0"将光标跳转到本行的最前,按shift+$可以将光标跳转到本行的结尾。使用yy可以复制一行的内容,使用p在光标后一行插入复制的内容,使用P在光标前一行插入复制的内容。
当然,vim在命令模式下和底线命令模式下还有很多命令,可以查看vim手册来获取更多使用方法。
四、正则表达式
正则表达式是一种可供Linux工具过滤文本的自定义模板。Linux工具(grep,sed,awk等工具)会在读取数据时使用正则表达式对数据进行模式(PATTERN)匹配。如果数据匹配模式,它就会被处理,反之被丢弃。
正则表达式是由正则表达式引擎实现的。这是一种底层软件,负责解释正则表达式。主要分为两种:
-
POSIX 基础正则表达式(BRE)引擎
-
POSIX 扩展正则表达式(ERE)引擎
由于扩展表达式的格式比基本表达式简单,下面介绍扩展正则表达式
^ # 匹配行首,比如\^a\表示匹配以a开头的字符
$ # 匹配行尾,比如\a$\表示匹配以a结尾的字符
^$ # 匹配空行
[] # 匹配指定范围内的任意单个字符
[^] # 匹配不在指定范围内的任意单个字符
. # 匹配任意单个字符,也可以是汉字
* # 匹配前面的字符0到任意次
.* # 匹配任意字符
? # 匹配前面的字符0或1次,即可有可无
+ # 匹配前面的字符至少一次或多次,即肯定有一个
{n} # 匹配前面的字符n次
{m,n} # 匹配前面的字符至少m次,至多n次
{,n} # 匹配前面的字符至多n次,0-n次
{n,} # 匹配前面的字符至少n次,n-m次
\< # 匹配以什么开头的单词,例如 \<tom 就会匹配 "tomcat"
\> # 匹配以什么结尾的单词,例如 cat\> 就会匹配 "tomcat"
() # 分组,将多个字符作为整体处理
\n # 内置变量。n表示数字,表示前面第n个分组
| # 表示or的逻辑关系
[[:alnum:]] # 字母和数字
[[:alpha:]] # 任何大小写的字母
[[:lower:]] # 小写字母
[[:upper:]] # 大写字母
[[:blank:]] # 空白字符(空格和制表符)
[[:space:]] # 水平或垂直的空白字符
[[:cntrl:]] # 不可打印的控制字符,退格,删除
[[:digit:]] # 十进制数字
[[:xdigit:]] # 十六进制数字
[[:graph:]] # 可打印的非空白字符
[[:print:]] # 可打印字符
[[:punct:]] # 标点符号
五、文本工具
Linux里面有很多文本工具,大多数命令都是来自于GUN coreutils包。
5.1 文本查看工具
下面只是列出了常用文件查看工具,详细使用方法请查看man手册。
- cat命令:查看文件
- head命令:从头开始查看文件
- tail命令:从结尾开始查看文件
- more命令:过滤、分页显示文件
- less命令:过滤、分页显示文件,支持上下键翻页显示
- wc命令:显示每个文件的换行符、单词和字节计数
5.2 文本处理工具
-
sort命令:排序工具
-
uniq命令:去重工具
-
cut命令:切片工具
5.3 文本查找工具
-
locate:非实时查找。
来自于mlocate包,需要手动安装。包含locate和updatedb命令
-
find:实时查找。
来自于findutils包。包含find和xargs命令
5.3.1 locate
使用locate之前,需要使用updatedb命令创建/var/lib/mlocate/mlocate.db索引文件。所以说locate并不是实时查找,每一次变更时都需要使用updatedb更新索引文件。优点是查找速度快。
locate命令格式:
locate [OPTION]... PATTERN...
OPTION:
-w:将整个路径名与模式匹配,默认
-b:仅将基名与模式匹配
-c:计数,统计匹配的个数
-d:指定索引文件
-i:忽略大小写
-q:不显示错误信息
-r:正则匹配
范例:
# 生成索引文件
$ updatedb
# 以路径的方式搜索文件
$ locate "/etc/passwd"
/etc/passwd
/etc/passwd-
# 查找以.conf结尾的文件
$ locate -br "\.conf$"
5.3.2 find命令
find用于实时查找,查找速度略慢。优点是查找条件丰富,精确查找。
命令格式
find [-H] [-L] [-P] [-D debugopts] [-Olevel] [starting-point...] [expression]
-D:显示诊断信息
-O:启用查询优化,0-3,默认为1
starting-point:查找起点,默认为当前路径
expression:表达式
TESTS:
-name:匹配basename
-name # 按特定名称搜索文件
-iname # 忽略文件名大小写
-inum # 按inode号查找
-samefile file # 查找与file相同inode号的文件
-type # 指定文件类型
-depth # 先处理文件,再处理目录
-atime # 最后一次读取文件的时间,+表示以后,-表示之前
-mtime # 文件内容最后一次被修改的时间
-ctime # 上次更改文件元数据的时间(例如:所有权,位置,文件类型和权限设置)
-size # 指定大小来查找文件
b:块大小,512字节。默认为此
c:字节
w:双字节
k:千字节
M:兆字节
G:千兆字节
-maxdepth # 文件最大搜索目录深度,指定目录下的文件为1级
-mindepth # 文件最小搜索目录深度
-perm # 指定权限查找文件
-user # 搜索属于指定用户的文件
-group # 搜索属于指定组的文件
-uid # 查找所有者的文件
-gid # 查找所有组的文件
-links # 搜索指定链接数的文件
-regex # 使用正则表达式搜索文件
-empty # 查找空目录
-executable # 可执行文件
-readable # 可读文件
-writable # 可写文件
-a # 与,多个条件默认是与,可以省略
cmd -o cmd # 或
! cmd # 非
ACTIONS:
-delete # 删除文件
-ls # 以ls-dils格式列出当前文件
-print0 # 不换行打印文件
-printf # 格式化输出
-exec command {} \; # 执行命令
# {}表示占位符,表示的是搜索匹配的文件,否则命令将会对所有文件执行。
# -exec必须以";"分号结束,\反斜杠用于转义字符
范例:
# 删除/tmp下名为test的文件
$ find /tmp -name test -type f -exec rm -f {} \;
# 查找可执行但不可读的文件
$ find /bin /sbin -executable \! -readable
# 删除当前目录下30天以前大于100M的日志文件
find . -name "*.log" -size +100M -mtime +30 -exec rm -f {} \;
5.3 文本处理三剑客
- grep:过滤工具
- sed:查找替换工具
- awk:文本处理工具
5.3.1 grep 基本用法
命令格式
grep [OPTIONS] PATTERN [FILE...]
OPTIONS:
-m n # 匹配n次(行)后停止
-i # 忽略字符大小写
-n # 显示匹配的行号
-c # 统计匹配的行数
-o # 仅显示匹配到的字符串
-q # 静默模式,不输出任何信息
-e # 实现多个选项间的逻辑or关系
-v # 反转查找,显示不被匹配的行
-w # 匹配整个单词
-A n # 显示匹配字符的后n行
-B n # 显示匹配字符的前n行
-C n # 显示匹配字符的前后n行
-E # 支持扩展正则表达式
-f file # 根据文件处理
-r # 递归目录过滤查找,不处理软连接
-R # 递归目录,处理软连接
—l # 显示文件名
--color=auto # 将匹配的字符以高亮颜色标记出来
范例:
# 查找以bash或nologin结尾的行
$ grep -E "bash$|nologin$" /etc/passwd
5.3.2 sed 基本用法
sed是流编辑器。sed具有grep查看文件的功能,又具有编辑文本的功能。
命令格式:
sed [option] [script] file
选项:
-n # 取消自动打印,只打印包含匹配文本模式的行
-e # 执行多个script
-E # 使用扩展正则表达式
-i # 对文件进行编辑
-i.bak # 编辑文件并生成 原文件.bak 的备份文件
-f file # 从指定文件中读取编辑脚本
script格式:(多个script使用分号 ; 或-e隔开:'script;script' 或 -e 'script' -e 'script' )
'[地址][指令]'
地址:
- 地址为空,对全文进行处理
$ sed ' ' /etc/passwd
# 打印全文
- 地址可以是数字。可以使用行号来引用文本流中的行,sed将文本流中的第一行编号为1,第二行为2。地址可以是单个行号,也可以是
起始行号,结束行号的方式来表示地址范围。$表示最后一行。
$ sed -n '1p' /etc/passwd # 第1行
$ sed -n '1,5p' /etc/passwd # 第1-5行
$ sed -n '1,+5p' /etc/passwd # 第1行和后5行
$ sed -n '$p' /etc/passwd # 打印最后一行
# 步进
n~m # n开始行,m步进
1~2 # 匹配奇数行
2~2 # 匹配偶数行
- 地址也可以是字符串或模式,
/pattern/可以匹配包含模式的行。
$ sed -n '/root/p' /etc/passwd # 打印包含root的行
$ sed -n '/^[^#]/p' /etc/fstab # 打印非#开头的行
指令:
多个指令使用分号 ; 隔开。
- 打印指令:
p # 打印当前模式空间的内容,追加到默认输出之后
= # 打印行号
!p # 为匹配行取反处理,需要加上-n选项
l # 用于打印不可见字符
- 修改指令:
d # 删除模式空间匹配的行
a text # 在指定行后面追加文本,支持\n实现多行追加,\ 表示空格
i text # 在行前面插入文本
c text # 修改单行或多行文本
y/inchars/outchars # 修改单个字符,inchars和outchars是一一对应的,如果长度不同就会报错
w path/file # 保存模式匹配的行至指定文件
r path/file # 读取指定文件的文本,并插入到匹配行之后
- 替换指令:
s/pattern/string/修饰符 # 查找替换,允许使用其他字符代替/分隔符,例如s|||,s!!!等
# 修饰符:
number # 指定替换第n处
g # 行内全局替换
p # 显示替换成功的行,常和-n选项一起使用
w /PATH/FILE # 将替换成功的行保存至文件中
i # 忽略大小写
范例:
# 修改selinux配置文件
$ sed -Ei 's/^(SELINUX=).*/\1disabled/' /etc/selinux/config
5.3.3 awk基本用法
gawk是UNIX awk的GNU版本。是一个功能更加强大的文本文件处理工具:
-
定义变量来保存数据
-
使用算术和字符运算符来处理数据
-
使用结构化编程语句(if判断或for循环)
-
提取文件中的数据将其格式化输出
命令格式:
awk [options] 'program' file # /usr/bin/akw -> /usr/bin/gawk
常见选项:
-F "分隔符" # 指明输入时用到的字段分隔符,默认是若干连续的空白。可以使用|或[]定义多个分隔符
-f file # 指定从文件读取gawk代码
-v var=value # 变量赋值
program格式:
'[pattern]{action};...'
'BEGIN{action};/pattern/{action};END{action}'
多个program使用空格或分号隔开,并放在同一个单引号内。或者使用-e将多个program分开
- pattern:决定action语句何时触发,比如:BEGIN,END,模式(正则表达式)等
- action:对数据进行处理,放在{ }内声明,常见:print,printf。字符串需要使用双引号" " 括起来。否则awk会当初变量来处理。
pattern:(条件)
- BEGIN关键字:awk在处理文本之前(预处理)执行的指令,用于打印开头文本或定义变量等。
- 正则表达式:/模式匹配/,用于正则匹配行。逐行处理文本内容。
- 条件匹配:使用条件比较符,算术运算符,模式匹配,等符号进行匹配。
- END关键字:awk最后(文本处理完毕)执行的指令,用于在结尾打印文本或变量等。
当pattern为0或空字符串时,也不会执行后面的action。
action:(动作)
当没有pattern时,对全文逐行进行处理
- print:可以打印字符串,变量值(打印自定义的变量不用加$),算术运算等
- printf:格式化打印
范例:
模式匹配:
/模式匹配/,~匹配模式,!~不匹配模式
# 找出是bash结尾的行
$ awk -F":" '/bash$/{print}' /etc/passwd
# 找出不是以#开头的行
$ awk '!/^#/{print}' /etc/fstab
# 找出第一个字段包含a的行
$ awk -F":" '$1~"a"{print}' /etc/passwd
条件比较符:
==等于,!=不等于,>大于,<小于,>=大于等于,<=小于等于,&&表示and,||表示or
# 查看root用户
$ awk 'BEGIN{FS=":"};$1=="root"{print}' /etc/passwd
# 查看系统中的普通用户
$ awk 'BEGIN{FS=":"};$3>=1000{print}' /etc/passwd
# and,找到UID大于等于1000且小于1100的用户
$ awk 'BEGIN{FS=":"};$3>=1000 && $3<1100{print}' /etc/passwd
# or,查找UID等于1000,或者等于0的用户
$ awk 'BEGIN{FS=":"};$3==1000 || $3==0' /etc/passwd
算术运算符:
+加,-减,*乘,/除,%取余,^平方
# 取余数
$ awk 'BEGIN{print 10%3}'
1
# 查找20以内3的倍数或者含3的整数
$ seq 20 | awk '$1%3==0 || $1~/3/{print}'
3
6
9
12
13
15
18
# 打印文本文件的行数:
# 预处理时变量x为0,然后逐行读入/etc/passwd文件,每读一行,x的值就加1。全部处理完后,就打印变量x的值。
$ awk 'BEGIN{x=0};{x++};END{print x}' /etc/passwd
52
# 打印文本文件中以bash结尾的行数:
$ awk 'BEGIN{x=0};/bash$/{x++};END{print x}' /etc/passwd
3
printf格式化打印
格式:
printf "FORMAT",item1,item2,...
说明:
- 必须指定FORMAT
- 不会自动换行,需要显式给出\n换行控制符
- FORMAT中需要分别为后面每个item指定格式符
格式符:与item一一对应
%s # 显示字符串
%d,%i # 显示十进制整数
%f # 显示为浮点数
%e,%E # 显示科学计数法数值
%c # 显示字符的ASCII码
%g,%G # 以科学计数法或浮点数形式显示数值
%u # 无符号整数
%% # 显示%自身
修饰符
#[.#] # 第一个数字控制显示的宽度;第二个#表示小数点后精度,如:%3.1f
- # 左对齐(默认右对齐),如:%-15s
+ # 显示数值的正负号,如:%+d
六、shell变量
shell有以下几种变量:
- 内置变量
- 局部变量
- 全局(环境)变量
- 只读变量
- 状态变量
- 位置变量
- 数组变量
变量名称可以是数字,字母,下划线,但是不能是以数字开头。不能是保留字和内置变量。
6.1 内置变量
系统内置的变量,可以使用echo $ + TAB 查看。
6.2 局部变量
局部变量不能再子shell中使用。
# 定义局部变量
$ name=xiaoming
$ echo $name
xiaoming
# 当我们开启一个子shell,发现不能再次输出变量的值,因为这是一个自定义变量不能被子进程使用
$ bash
$ echo $name
# 空
# 取消变量
$ unset name
6.3 全局(环境)变量
全局变量可以在子shell中使用。
# 定义全局变量
$ export name=xiaoming
$ bash
$ echo $name
xiaoming
6.4 只读变量
只读变量只能声明定义,但后续不能修改和删除。
# 定义只读变量
$ readonly name=xiaoming
=======或者==============
$ declare -r name=xiaoming
# 查看只读变量
$ readonly -p
========或者============
$ declare -r
# 不能删除或修改只读变量,删除只读变量最简单的方法就是重新进入当前的shell即可。
$ unset name
bash: unset: name: cannot unset: readonly variable
$ name=xiaowang
bash: name: readonly variable
6.5 状态变量
状态变量用于返回上一条命令的状态码。
$? # 来显示上一条命令执行的返回值,0为成功,1-255为错误码
$ ll &> /dev/null;echo $?
0
$ hh &> /dev/null;echo $?
127
6.6 位置变量
位置变量主要用于获取命令后面的参数。
$_ # 取出上一个命令的最后一个参数
$0 # 获取shell脚本文件名,以及脚本路径
$n # 获取shell脚本的第n个参数,n在1-9之间。大于9需要写${10}
$# # 执行的shell脚本后面的参数总数
$* # 传递给脚本的所有参数,全部参数合为一个字符串
$@ # 传递给脚本的所有参数,每个参数为独立字符串
# 注意:$*和$@只有在被双引号" "括起来才有差异
范例
$ cat example.sh
#!/bin/bash
echo 当前的脚本是"$0"
echo 当前有"$#"个参数,分别是"$*"
echo 第一个参数为"$1",第三个参数为"$3"
$ bash example.sh a b c d e
当前的脚本是example.sh
当前有5个参数,分别是a b c d e
第一个参数为a,第三个参数为c
6.7 数组变量
数组变量可以存储多个变量。
数组使用索引定位数据:
- 索引变量从0开始,属于数值索引。
- 索引还可以使用自定义格式,即为关联索引。
- 索引支持稀疏格式(索引不连续)。
4.1.1 定义数组变量
声明数组
# 声明普通索引,也可以不声明。
declare -a var_name
# 声明关联索引,必须先声明在使用
declare -A var_name
定义数组
一次只赋值一个元素
var_name[index]=value
范例:
student[0]="tony"
student[1]="jack"
一次赋值全部元素
var_name=("value1" "value2" "value3")
范例:
student=("tony" "tom" "jack" "bob")
num=({1..10})
file=( *.sh )
只赋值特定元素
var_name=([0]="value1" [2]="value2" [4]="value3")
通过read生成
$ read -a car
benz bmw audi
4.1.2 使用数组变量
显示所有数组
declare -a
查看数组的元素
# 查看单个元素
echo ${var_name[index]}
# 查看所有元素
echo ${var_name[*]}
查看元素的个数
echo ${#var_name[*]}
删除元素
unset var_name[index]
删除数组变量
unset var_name
4.1.3 数组数据处理
数组切片
$ sum=({0..10})
$ echo ${sum[*]}
0 1 2 3 4 5 6 7 8 9 10
# 跳过三个只取四个元素
$ echo ${sum[*]:3:4}
3 4 5 6
# 跳过前三个取后面所有元素
$ echo ${sum[*]:3}
3 4 5 6 7 8 9 10
向数组中追加元素
$ echo ${sum[*]}
0 1 2 3 4 5 6 7 8 9 10
# 追加元素
$ sum[${#sum[*]}]=11
$ echo ${sum[*]}
0 1 2 3 4 5 6 7 8 9 10 11
七、使用shell计算鸡兔同笼
30个头,80个脚,分别有几只鸡,几只兔?
#!/bin/bash
head=30
foot=80
T=$(( ( foot - ( head * 2 ) ) / ( 4 - 2 ) ))
J=$(( head - T ))
echo "有$J只鸡,有$T只兔"
$ ./jttl.sh
有20只鸡,10只兔
八、使用shell脚本批量创建用户
创建用户user1 ... user100
#!/bin/bash
U=user
for i in {1..100};do
id ${U}${i} &> /dev/null && echo "${U}${i} is exist" || (useradd ${U}${i} ; echo "add ${U}${i}")
done
九、 磁盘术语
机械硬盘的结构主要分为磁头,磁道、扇区和拄面。
-
磁头:由于每个盘面都有自己的磁头,因此,盘面数等于总的磁头数。
-
磁道:每个盘片都在逻辑上有很多的同心圆,最外面的同心圆就是 0 磁道。我们将每个同心圆称作磁道(注意,磁道只是逻辑结构,在盘面上并没有真正的同心圆)。硬盘的磁道密度非常高,通常一面上就有上千个磁道。
-
扇区:在磁盘上每个同心圆是磁道,从圆心向外呈放射状地产生分割线(扇骨),将每个磁道等分为若干弧段,每个弧段就是一个扇区。每个扇区的大小是固定的,为 512Byte。扇区是磁盘的最小存储单位。
-
柱面:如果硬盘是由多个盘片组成的,每个盘面都被划分为数目相等的磁道,那么所有盘片都会从外向内进行磁道编号,最外侧的就是 0 磁道。具有相同编号的磁道会形成一个圆柱,这个圆柱就被称作磁盘的柱面。磁盘的柱面数与一个盘面上的磁道数是相等的。
存储容量 = 磁头数 × 磁道(柱面)数 × 每道扇区数 × 每扇区字节数(512B)
十、MBR和GPT
10.1 MBR
MBR:Master Boot Record,主引导记录。使用32位表示扇区数(2^32*512B=2TB),所以最大只支持2TB容量的硬盘,在Linux中可以创建3个主分区+任意扩展分区。
在MBR分区表中,第一个扇区(512bytes)包含主引导记录
-
前446字节存放boot loader启动相关
-
64字节存放分区表,每个分区占用16字节
-
2字节表示标识位,55 aa
MBR只支持4个主分区,如果想要划分多个分区,则需要创建至多1个扩展分区,然后在扩展分区创建多个逻辑分区。(扩展分区需要转换为多个若干逻辑分区,才能使用)。
如下图所示:一块20GB的MBR分区格式的硬盘分了9个分区,其中3个主分区,1个扩展分区(5个逻辑分区)
Disk /dev/sdb: 20 GiB, 21474836480 bytes, 41943040 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disklabel type: dos
Disk identifier: 0xf8c4b9ac
Device Boot Start End Sectors Size Id Type
/dev/sdb1 2048 10487807 10485760 5G 83 Linux
/dev/sdb2 31459328 35653631 4194304 2G 83 Linux
/dev/sdb3 35653632 41943039 6289408 3G 83 Linux
/dev/sdb4 10487808 31459327 20971520 10G 5 Extended
/dev/sdb5 10489856 14684159 4194304 2G 83 Linux
/dev/sdb6 14686208 18880511 4194304 2G 83 Linux
/dev/sdb7 18882560 23076863 4194304 2G 83 Linux
/dev/sdb8 23078912 27273215 4194304 2G 83 Linux
/dev/sdb9 27275264 31459327 4184064 2G 83 Linux
10.2 GPT
GPT:GUID,Globals Unique Identifiers(全局唯一标识符)。GPT没有逻辑分区和扩展分区的概念,在Linux中主分区的个数没有限制,使用64位表示扇区数,最大支持8ZB容量的硬盘。GPT支持UEFI启动。
十一、磁盘管理
磁盘管理工具:
-
fdisk:为分区类型的MBR硬盘分区。(centos7开始支持GPT)
-
gdisk:为GPT分区类型的硬盘分区。
-
perted :为GPT和MBR分区类型的硬盘分区。
11.1 添加/挂载硬盘
1、添加硬盘设备:在虚拟机中添加一个20G的硬盘。
$ lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 50G 0 disk
├─sda1 8:1 0 1G 0 part /boot
└─sda2 8:2 0 49G 0 part
├─rl-root 253:0 0 47G 0 lvm /
└─rl-swap 253:1 0 2G 0 lvm [SWAP]
sdb 8:16 0 20G 0 disk # 新添加的硬盘
让内核发现新硬盘的方法:
#!/bin/bash
for host in /sys/class/scsi_host/*
do
echo "####### $host"
echo "- - -" > $host/scan
# ls /dev/sd*
done
fdisk命令用于新建,修改及删除磁盘的分区表信息。语法格式为:
fdisk [options] device
fdisk -l [device...]
options:
m:查看全部 可用的参数
n:添加新的分区
d:删除分区信息
l:列出所有可用的分区类型
t:改变某个分区类型
p:查看分区表信息
g:创建gpt分区表
o:创建mbr分区表
w:保存并退出
q:不保存直接退出
2、创建分区:
$ fdisk /dev/sdb
Welcome to fdisk (util-linux 2.32.1).
Changes will remain in memory only, until you decide to write them.
Be careful before using the write command.
Command (m for help): n # 添加分区
Partition type
p primary (0 primary, 0 extended, 4 free)
e extended (container for logical partitions)
Select (default p): p # 主分区
Partition number (1-4, default 1): 1 # 分区编号
First sector (2048-41943039, default 2048): # 起始扇区
Last sector, +sectors or +size{K,M,G,T,P} (2048-41943039, default 41943039): +1G # 结束扇区
Created a new partition 1 of type 'Linux' and of size 1 GiB.
Command (m for help): w # 保存退出
The partition table has been altered.
Calling ioctl() to re-read partition table.
Syncing disks.
3、查看创建的分区
$ lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 50G 0 disk
├─sda1 8:1 0 1G 0 part /boot
└─sda2 8:2 0 49G 0 part
├─rl-root 253:0 0 47G 0 lvm /
└─rl-swap 253:1 0 2G 0 lvm [SWAP]
sdb 8:16 0 20G 0 disk
└─sdb1 8:17 0 1G 0 part
4、使用mkfs创建文件系统
mkfs [options] [-t type] [fs-options] device [size]
-b:指定块大小
$ mkfs.ext4 /dev/sdb1
5、使用blkid或lsblk -f查看文件系统
$ blkid /dev/sdb1
/dev/sdb1: UUID="73a96cac-7693-4604-9573-73f497611833" BLOCK_SIZE="4096" TYPE="ext4" PARTUUID="4ad54fe3-01"
$ lsblk -f
NAME FSTYPE LABEL UUID MOUNTPOINT
sda
├─sda1 xfs 214b755a-b225-40ee-bbfb-0509995a24fb /boot
└─sda2 LVM2_member nrUg2Q-MFR4-Vfrp-xh5d-nKLo-8Rep-WJ8w3c
├─rl-root xfs be15b003-d46d-423b-82e2-b1fec6d657d1 /
└─rl-swap swap ab946ba1-177a-4add-aef8-a198ab542946 [SWAP]
sdb
└─sdb1 ext4 73a96cac-7693-4604-9573-73f497611833
6、挂载分区
只有将创建完成文件系统的设备关联至目录,才能使用设备。mount命令用于挂载文件系统。
格式:
mount [选项] 设备 挂载目录
-a:挂载所有在/etc/fstab中定义的文件系统
-t:指定文件系统的类型
-ro:只读挂载
-rw:以读写方式挂载(默认)
-o:挂载选项列表,以英文逗号分隔
将/dev/sdb1挂载到/backup目录。系统会自动判断要挂载文件系统的类型。
$ mount /dev/sdb1 /backup
UUID是一串用于识别每块独立硬盘的字符串,具有唯一性和稳定性。也可以使用UUID值来挂载设备:
$ mount 73a96cac-7693-4604-9573-73f497611833 /backup
7、使用df命令查看挂载的设备。
$ df -hT
Filesystem Type Size Used Avail Use% Mounted on
/dev/sdb1 ext4 974M 24K 907M 1% /backup
8、以上挂载方式为临时挂载,系统重启后就会解除挂载。如果想要永久挂载,就需要将挂载信息写入至/etc/fstab文件中。
$ head -n1 /etc/fstab
/dev/mapper/rl-root / xfs defaults 0 0
" 设备文件 挂载目录 文件系统 挂载选项 是否备份 是否自检 "
1. 设备文件:一般为设备的路径+设备名称,也可以写通用唯一识别码(UUID)
2. 挂载目录:指定要挂载的目录,需要在挂载前创建好
3. 文件系统类型:文件系统类型,比如ext4、xfs、swap(交换分区)、ios9660(光盘文件系统)
4. 挂载选项:若设为defaults,则默认权限为rw,suid,dev,exec,auto,nouser,async。
5. 是否备份:若为1则开机后使用dump进行磁盘备份,为0则不备份
6. 是否自检:若为1则开机后自动进行磁盘自检,为0则不自检
如果是网络存储设备,建议加上`_netdev`参数。表示系统会等联网成功后才会挂载此硬盘。从而避免开机时间过长或失败的情况。
9、设置开机自动挂载
# 卸载
$ umount /backup
# 写入配置文件
$ echo "/dev/sdb1 /backup ext4 defaults 0 0" >> /etc/fstab
# 使用-a选项读取配置文件中的信息
$ mount -a
$ df -hT
/dev/sdb1 ext4 974M 24K 907M 1% /backup
11.2 添加交换分区
1、使用fdisk命令为sdb添加一个大小为1G的分区2。然后修改硬盘的标识符,修改为82(Linux swap):
Command (m for help): n
Partition type
p primary (1 primary, 0 extended, 3 free)
e extended (container for logical partitions)
Select (default p): p
Partition number (2-4, default 2):
First sector (2099200-41943039, default 2099200):
Last sector, +sectors or +size{K,M,G,T,P} (2099200-41943039, default 41943039): +1G
Created a new partition 2 of type 'Linux' and of size 1 GiB.
Partition #2 contains a xfs signature.
The signature will be removed by a write command.
Command (m for help): t
Partition number (1,2, default 2): 2
Hex code (type L to list all codes): 82
Changed type of partition 'Linux' to 'Linux swap / Solaris'.
Command (m for help): w
The partition table has been altered.
Syncing disks.
2、mkswap命令用于对分区创建交换分区
$ mkswap /dev/sdb2
Setting up swapspace version 1, size = 1024 MiB (1073737728 bytes)
no label, UUID=f1372ea2-5dce-43a5-a7ac-d196919030cb
3、swapon命令用于激活新的交换分区设备,如果已经将配置信息写入/etc/fstab,就可以使用swapon -a 来读取配置文件。
$ free -h
total used free shared buff/cache available
Mem: 1.7Gi 266Mi 1.0Gi 8.0Mi 459Mi 1.3Gi
Swap: 2.0Gi 0B 2.0Gi
$ swapon /dev/sdb2
$ free -h
total used free shared buff/cache available
Mem: 1.7Gi 266Mi 1.0Gi 8.0Mi 459Mi 1.3Gi
Swap: 3.0Gi 0B 3.0Gi
4、在/etc/fstab中写入新增加交换分区信息:
$ echo "/dev/sdb2 swap swap defaults 0 0" >> /etc/fstab
还使用swapoff来禁用交换分区:
$ swapon -s # 查看使用的设备
Filename Type Size Used Priority
/dev/dm-1 partition 2125820 0 -2
/dev/sdb2 partition 1048572 0 -3
$ swapoff /dev/sdb2
11.2.1 使用文件方式提供swap功能
$ dd if=/dev/zero of=/swapfile bs=1M count=1024
1024+0 records in
1024+0 records out
1073741824 bytes (1.1 GB, 1.0 GiB) copied, 1.84864 s, 581 MB/s
$ mkswap /swapfile
mkswap: /swapfile: insecure permissions 0644, 0600 suggested.
Setting up swapspace version 1, size = 1024 MiB (1073737728 bytes)
no label, UUID=88d7aa70-d1be-4936-8553-6a8301d4b3db
$ chmod 600 /swapfile
$ echo "/swapfile swap swap defaults 0 0" >> /etc/fstab
$ swapon -a
$ free -h
total used free shared buff/cache available
Mem: 1.7Gi 264Mi 76Mi 8.0Mi 1.4Gi 1.3Gi
Swap: 3.0Gi 0.0Ki 3.0Gi
$ swapon -s
Filename Type Size Used Priority
/dev/dm-1 partition 2125820 268 -2
/swapfile file 1048572 0 -3
十二、raid技术
磁盘阵列是由很多块独立的磁盘,组合成一个容量巨大的磁盘组,利用个别磁盘提供数据所产生加成效果提升整个磁盘系统效能。利用这项技术,将数据切割成许多区段,分别存放在各个硬盘上。
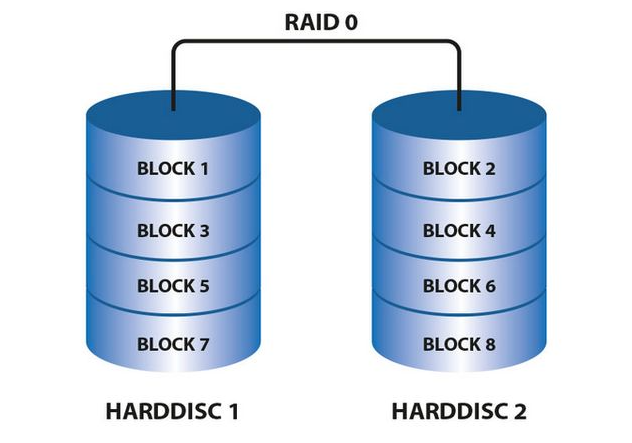
RAID0技术把多块物理硬盘设备(至少为两块)通过硬件或软件的方式串联到一起,组成一个大的卷组,并将数据依次写入各个物理硬盘中。RAID0技术能够有效地提升硬盘数据的吞吐速度,但是不具备数据备份和错误修复能力。如图所示,数据会被分别写入到不同的硬盘设备中,即硬盘1和硬盘2都会保存数据,最终提升读取,写入效果。可用空间为所有硬盘的空间。
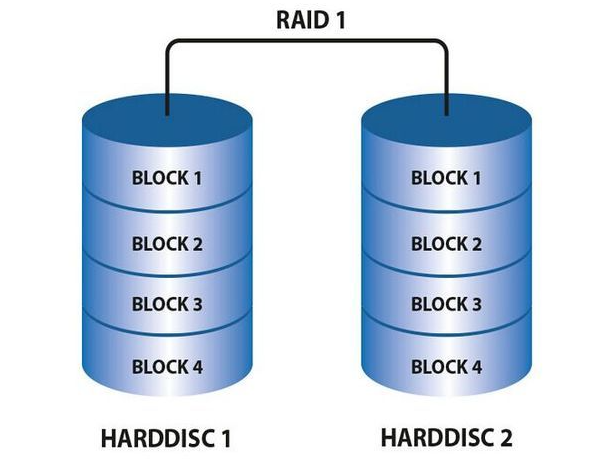
RAID1技术把两块以上的硬盘设备进行绑定,在写入数据时,是将数据同时写入到多块硬盘设备上(可以将其视为数据的镜像或备份),当其中某一块硬盘发生故障后,一般会立即自动以热交换的方式来恢复数据的正常使用。在写入操作时考虑到因硬盘切换带来的开销,因此RAID1的速度会比RAID0有稍微的降低。但在读取数据的时候,操作系统可以分别从两块硬盘中读取信息,因此理论读取速度的峰值可以说硬盘数量的倍数。但是因为是在多块硬盘中写入相同的数据,因此硬盘利用率得以下降。从理论上来说,下图的硬盘空间利用率只有50%,当有3块硬盘的时候,空间利用率只有33%左右,以此类推。
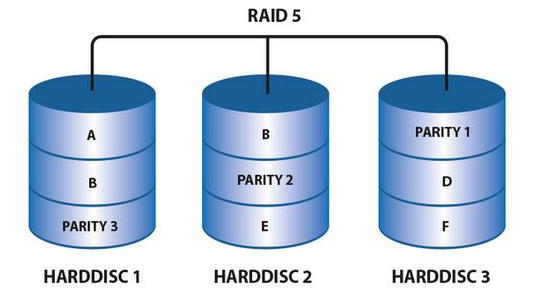
RAID5技术是把硬盘设备的奇偶校验信息保存到其他硬盘设备中。RAID5磁盘阵列中的数据的奇偶校验信息并不是单独保存到某一块硬盘设备中,而是存储到其他每一块硬盘上。这样的好处是,其中任何一块硬盘损坏后不至于出现致命的错误。在下图中,parity部分存放的就是数据的奇偶校验信息。RAID5最少由3块硬盘组成,使用的是硬盘切割(Disk Striping)技术。相较于RAID1级别,好处就在于保存的是奇偶校验信息而不是一模一样的文件内容。其可用容量是N-1(块硬盘)。
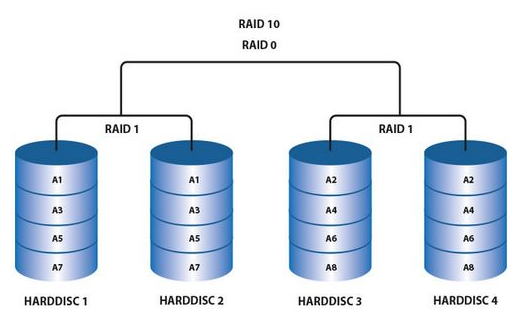
RAID10技术是RAID1+RAID0技术的一个”组合体“。如图所示,RAID10至少需要4块硬盘来组建,其中先分别两两制作成RAID1磁盘阵列,以保证数据的安全性;然后再对两个RAID1磁盘阵列组建RAID0磁盘阵列,进一步提高设备的读写速度。这样从理论上来讲,如果坏的不是同一个(RAID1)磁盘阵列中的所有硬盘,那么最多可以损坏50%的硬盘设备而不丢失数据。其可用容量为50%。
十三、LVM磁盘扩容及缩容
LVM(逻辑卷管理器)允许用户对硬盘资源进行动态调整。LVM技术是在硬盘分区和文件系统之间添加了一个逻辑层,它提供了一个抽象的卷组,可以把多块硬盘进行卷组合并。这样一来,用户不必关心物理硬盘设备的底层架构和布局,就可以实现对硬盘分区的动态调整。
物理设备是用于保存逻辑卷中所存储数据的存储设备。它是块设备,可以是磁盘分区、整个磁盘、RAID磁盘阵列或SAN磁盘。物理设备必须初始化为LVM物理卷(PV),才能结合LVM使用。
- 物理卷(PV)处于LVM中的最底层,可以将其理解为物理硬盘、硬盘分区或者RAID磁盘阵列。
- 卷组(VG)建立在物理卷之上,一个卷组能够包含多个物理卷,而且在卷组创建之后也可以继续向其中添加新的物理卷。
- 逻辑卷(LV)是用卷组中空闲的资源建立的,并且逻辑卷在建立后可以动态地扩展或缩小空间。这就是LVM的核心理念。
- 文件统:文件系统位于逻辑卷上。
13.1 扩展逻辑卷
用户在使用存储设备时感知不到设备底层的架构和布局,更不用关心底层是由多少块硬盘组成的,只要卷组中有足够的资源,就可以一直为逻辑卷扩容。扩容之前需要卸载设备和挂载点的关联。
# 卸载挂载点
$ umount /media/lv0
# 查看vg剩余空间,还有9.96G的空间
$ vgs
VG PV LV SN Attr VSize VFree
rl 1 2 0 wz--n- <49.00g 0
vg0 4 1 0 wz--n- 19.96g 9.96g
# -l +100%free表示使用卷组的全部剩余空间。还可以-L +9G指定增加的容量或使用-L 19G将容量扩容至19G。
# -r选项扩展文件系统。
$ lvextend -r -l +100%free /dev/vg0/lv0
重新挂载硬盘并查看挂载状态
$ mount -a
$ df -h
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/vg0-lv0 20G 24K 19G 1% /media/lv0
13.2 缩小逻辑卷
只能缩减ext4文件系统的逻辑卷,不支持xfs文件系统。
1、卸载挂载
$ umount /media/lv0
2、缩小逻辑卷至10GB,同时缩小文件系统。
$ lvreduce -L 10G -r /dev/vg0/lv0
3、重新挂载逻辑卷
$ mount -a
$ df -h
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/vg0-lv0 9.8G 25M 9.3G 1% /media/lv0

 浙公网安备 33010602011771号
浙公网安备 33010602011771号