
Tackling Business Complexity in a Microservice with DDD and CQRS Patterns (2)
Implement value objects
As discussed in earlier sections about entities and aggregates, identity is fundamental for entities. However, there are many objects and data items in a system that do not require an identity and identity tracking, such as value objects.
A value object can reference other entities. For example, in an application that generates a route that describes how to get from one point to another, that route would be a value object. It would be a snapshot of points on a specific route, but this suggested route would not have an identity, even though internally it might refer to entities like City, Road, etc.
Figure 7-13 shows the Address value object within the Order aggregate.

Figure 7-13. Address value object within the Order aggregate
As shown in Figure 7-13, an entity is usually composed of multiple atrributes. For example, the Order entity can be modeled as an entity with an identity and composed internally of a set of attributes such as OrderId, OrderDate, OrderItems, etc. But the address, which is simply a complex-value composed of country/region, street, city, etc., and has no identity in this domain, must be modeled and treated as a value object.
Important characteristics of value objects
There are two main characteristics for value objects:
- They have no identity.
- They are immutable.
The first characteristic was already discussed. Immutability is an important requirement. The values of a value object must be immutable once the object is created. Therefore, when the object is constructed, you must provide the required values, but you must not allow them to change during the object's lifetime.
Value objects allow you to perform certain tricks for performance, thanks to their immutable nature. This is especially true in systems where there may be thousands of value object instance, many of which have the same values. Their immutable nature allows them to be reused; they can be interchangeable objects, since their values are the same and they have no identity. This type of optimization can sometimes make a difference between software that runs slowly and software with good performance. Of course, all these cases depend on the application environment and deployment context.
Value object implementation in C#
In terms of implementation, you can have a value object base class that has basic utility methods like equality based on the comparison between all the attributes (since a value object must not be based on identity) and other fundamental characteristics. The following example shows a value object base class used in the ordering microservice from eShopOnContainers.
public abstract class ValueObject { protected static bool EqualOperator(ValueObject left, ValueObject right) { if (ReferenceEquals(left, null) ^ ReferenceEquals(right, null)) { return false; } return ReferenceEquals(left, right) || left.Equals(right); } protected static bool NotEqualOperator(ValueObject left, ValueObject right) { return !(EqualOperator(left, right)); } protected abstract IEnumerable<object> GetEqualityComponents(); public override bool Equals(object obj) { if (obj == null || obj.GetType() != GetType()) { return false; } var other = (ValueObject)obj; return this.GetEqualityComponents().SequenceEqual(other.GetEqualityComponents()); } public override int GetHashCode() { return GetEqualityComponents() .Select(x => x != null ? x.GetHashCode() : 0) .Aggregate((x, y) => x ^ y); } // Other utility methods }
The ValueObject is an abstract class type, but in this example, it doesn't overload the == and != operators. You could choose to do so, making comparisons delegate to the Equals override. For example, consider the following operator overloads to the ValueObject type:
public static bool operator ==(ValueObject one, ValueObject two) { return EqualOperator(one, two); } public static bool operator !=(ValueObject one, ValueObject two) { return NotEqualOperator(one, two); }
You can use this class when implementing your actual value object, as with the Address value object shown in the following example:
public class Address : ValueObject { public String Street { get; private set; } public String City { get; private set; } public String State { get; private set; } public String Country { get; private set; } public String ZipCode { get; private set; } public Address() { } public Address(string street, string city, string state, string country, string zipcode) { Street = street; City = city; State = state; Country = country; ZipCode = zipcode; } protected override IEnumerable<object> GetEqualityComponents() { // Using a yield return statement to return each element one at a time yield return Street; yield return City; yield return State; yield return Country; yield return ZipCode; } }
This value object implementation of Address has no identity, and therefore no ID field is defined for it, either in the Address class definition or the ValueObject class definition.
Having no ID filed in a class to be used by Entity Framework (EF) was not possible until EF Core 2.0, which greatly helps to implement better value objects with no ID. That is precisely the explanation of the next section.
It could be argued that value objects, beging immutable, should be read-only (that is, have get-only properties), and that's indeed true. However, value objects are usually serialized and deserialized to go through message queues, and being read-only stops the deserializer from assigning values, so you just leave them as private set, which is read-only enough to be practical.
Value object comparison semantics
Two instances of the Address type can be compared using all the following methods:
var one = new Address("1 Microsoft Way", "Redmond", "WA", "US", "98052"); var two = new Address("1 Microsoft Way", "Redmond", "WA", "US", "98052"); Console.WriteLine(EqualityComparer<Address>.Default.Equals(one, two)); // True Console.WriteLine(object.Equals(one, two)); // True Console.WriteLine(one.Equals(two)); // True Console.WriteLine(one == two); // True
When all the values are the same, the comparisons are correctly evaluated as true. If you didn't choose to overload the == and != operators, then the last comparison of one == two would evaluate as false. For more information, see Overload ValueObject equality operators.
How to persist value objects in the database with EF Core 2.0 and later
You just saw how to define a value object in your domain model. But how can you actually persist it into the database using Entity Framework Core since it usually targets entities with identity?
Background and older approaches using EF Core 1.1
As background, a limitation when using EF Core 1.0 and 1.1 was that you could not use complex types as defined in EF 6.x in the traditional .NET Framework. Therefore, if using EF Core 1.0 or 1.1, you needed to store your value object as an EF entity with an ID field. Then, so it looked more like a value object with no identity, you could hide its ID so you make clear that the identity of a value object is not important in the domain model. You could hide that ID by using the ID as a shadow property. Since that configuration for hiding the ID in the model is set up in the EF infrastructure level, it would be kind of transparent for your domain model.
In the initial version of eShopOnContainers (.NET Core 1.1), the hidden ID needed by EF Core infrastructure was implemented in the following way in the DbContext level, using Fluent API at the infrastructure project. Therefore, the ID was hidden from the domain model point of view, but still present in the infrastructure.
// Old approach with EF Core 1.1 // Fluent API within the OrderingContext:DbContext in the Infrastructure project void ConfigureAddress(EntityTypeBuilder<Address> addressConfiguration) { addressConfiguration.ToTable("address", DEFAULT_SCHEMA); addressConfiguration.Property<int>("Id") // Id is a shadow property .IsRequired(); addressConfiguration.HasKey("Id"); // Id is a shadow property }
However, the persistence of that value object into the database was performed like a regular entity in a different table.
With EF Core 2.0 and later, there are new and better ways to persist value objects.
Persist value objects as owned entity types in EF Core 2.0 and later
Even with some gaps between the canonical value object pattern in DDD and the owned entity type in EF Core, it's currently the best way to persist value objects with EF Core 2.0 and later. You can see limitations at the end of this section.
The owned entity type feature was added to EF Core since version 2.0.
An owned entity type allows you to map types that do not have their own identity explicitly defined in the domain model and are used as properties, such as a value object, within any of your entities. An owned entity type shares the same CLR type with another entity type (that is, it's just a regular class). The entity containing the defining navigation is the owner entity. When querying the owner, the owned types are included by default.
Just by looking at the domain model, an owned type looks like it doesn't have any identity. However, under the convers, owned types do have the identity, but the owner navigation property is part of this identity.
The identity of instances of owned types is not completely their own. It consists of three components:
- The identity of the owner
- The navigation property pointing to them
- In the case of collections of owned types, an independent component (supported in EF Core 2.2 and later).
For example, in the Ordering domain model at eShopOnContainers, as part of the Order entity, the Address value object is implemented as an owned entity type within the owner entity, which is the Order entity. Address is a type with no identity property defined in the domain model. It is used as a property of the Order type to specify the shipping address for a particular order.
By convention, a shadow primary key is created for the owned type and it will be mapped to the same table as the owner by using table splitting. This allows to use owned types similarly to how complex types are used in EF6 in the traditional .NET Framework.
It is important to note that owned types are never discovered by convention in EF Core, so you have to declare them explicitly.
In eShopOnContainers, in the OrderingContext.cs file, within the OnModelCreating() method, multiple infrastructure configurations are applied. One of them is related to the Order entity.
// Part of the OrderingContext.cs class at the Ordering.Infrastructure project // protected override void OnModelCreating(ModelBuilder modelBuilder) { modelBuilder.ApplyConfiguration(new ClientRequestEntityTypeConfiguration()); modelBuilder.ApplyConfiguration(new PaymentMethodEntityTypeConfiguration()); modelBuilder.ApplyConfiguration(new OrderEntityTypeConfiguration()); modelBuilder.ApplyConfiguration(new OrderItemEntityTypeConfiguration()); //...Additional type configurations }
In the following code, the persistence infrastructure is defined for the Order entity:
// Part of the OrderEntityTypeConfiguration.cs class // public void Configure(EntityTypeBuilder<Order> orderConfiguration) { orderConfiguration.ToTable("orders", OrderingContext.DEFAULT_SCHEMA); orderConfiguration.HasKey(o => o.Id); orderConfiguration.Ignore(b => b.DomainEvents); orderConfiguration.Property(o => o.Id) .ForSqlServerUseSequenceHiLo("orderseq", OrderingContext.DEFAULT_SCHEMA); //Address value object persisted as owned entity in EF Core 2.0 orderConfiguration.OwnsOne(o => o.Address); orderConfiguration.Property<DateTime>("OrderDate").IsRequired(); //...Additional validations, constraints and code... //... }
In the previous code, the orderConfiguration.OwnsOne(o => o.Address) method specifies that the Address property is an owned entity of the Order type.
By default, EF Core conventions name the database columns for the properties of the owned entity type as EntityProperty_OwnedEntityProperty. Therefore, the internal properties of Address will appear in the Orders table with the names Address_Street, Address_City (and so on for State, Country, and ZipCode).
You can append the Property().HasColumnName() fluent method to rename those columns. In the case where Address is a public property, the mappings would be like the following:
orderConfiguration.OwnsOne(p => p.Address) .Property(p=>p.Street).HasColumnName("ShippingStreet"); orderConfiguration.OwnsOne(p => p.Address) .Property(p=>p.City).HasColumnName("ShippingCity");
It's possible to chain the OwnsOne method in a fluent mapping. In the following hypothetical example, OrderDetails owns BillingAddress and ShippingAddress, which are both Address types. Then OrderDetails is owned by the Order type.
orderConfiguration.OwnsOne(p => p.OrderDetails, cb => { cb.OwnsOne(c => c.BillingAddress); cb.OwnsOne(c => c.ShippingAddress); }); //... //... public class Order { public int Id { get; set; } public OrderDetails OrderDetails { get; set; } } public class OrderDetails { public Address BillingAddress { get; set; } public Address ShippingAddress { get; set; } } public class Address { public string Street { get; set; } public string City { get; set; } }
Additional details on owned entity types
- Owned types are defined when you configure a navigation property to a particular type using the OwnsOne fluent API.
- The definition of an owned type in our metadata model is a composite of: the owner type, the navigation property, and the CLR type of the owned type.
- The identity (key) of an owned type instance in our stack is a composite of the identity of the owner type and the definition of the owned type.
Owned entities capabilities
- Owned types can reference other entities, either owned (nested owned types) or non-owned (regular reference navigation properties to other entities).
- You can map the same CLR types as different owned types in the same owner entity through separate navigation properties.
- Table splitting is set up by convention, but you can opt out by mapping the owned type to a different table using ToTable.
- Eager loading is performed automatically on owned types, that is, there's no need to call
.Include()on the query. - Can be configured with attribute
[Owned], using EF Core 2.1 and later. - Can handle collections of owned types (using version 2.2 and later).
Owned entities limitations
- You can't create a
DbSet<T>of an owned type (by design). - You can't call
ModelBuilder.Entity<T>()on owned types (currently by design). - No support for optional (that is, nullable) owned types that are mapped with the owner in the same table (that is, using table splitting). This is because mapping is done for each property, there is no separate sentinel for the null complex value as a whole.
- No inheritance-mapping support for owned types, but you should be able to map two leaf types of the same inheritance hierarchies as different owned types. EF Core will not reason about the fact that they are part of the same hierarchy.
Main differences with EF6's complex types
- Table splitting is optional, that is, they can optionally be mapped to a separate table and still be owned types.
Use enumeration classes instead of enum types
Enumerations (or enum types for short) are a thin language wrapper around an intergral type. You might want to limit their use to when you are storing one value from a closed set of values. Classification based on sizes (small, medium, large) is a good example. Using enums for control flow or more robust abstractions can a code smell. This type of usage leads to fragile code with many control flow statements checking values of the enum.
Instead, you can create Enumeration classes that enable all the rich features of an object-oritented language.
However, this isn't a critical topic and in many cases, for simplicity, you can still use regular enum types if that's your preference.The use of enumeration classes is more related to business-related concepts.
Implement an Enumeration base class
The ordering microservice in eShopOnContainers provides a sample Enumeration base class implementation, as shown in the following example:
public abstract class Enumeration : IComparable { public string Name { get; private set; } public int Id { get; private set; } protected Enumeration(int id, string name) => (Id, Name) = (id, name); public override string ToString() => Name; public static IEnumerable<T> GetAll<T>() where T : Enumeration => typeof(T).GetFields(BindingFlags.Public | BindingFlags.Static | BindingFlags.DeclaredOnly) .Select(f => f.GetValue(null)) .Cast<T>(); public override bool Equals(object obj) { if (obj is not Enumeration otherValue) { return false; } var typeMatches = GetType().Equals(obj.GetType()); var valueMatches = Id.Equals(otherValue.Id); return typeMatches && valueMatches; } public int CompareTo(object other) => Id.CompareTo(((Enumeration)other).Id); // Other utility methods ... }
You can use this class as a type in any entity or value object, as for the following CardType : Enumeration class:
public class CardType : Enumeration { public static CardType Amex = new(1, nameof(Amex)); public static CardType Visa = new(2, nameof(Visa)); public static CardType MasterCard = new(3, nameof(MasterCard)); public CardType(int id, string name) : base(id, name) { } }
Design validations in the domain model layer
In DDD, validation rules can be thought as invariants. The main responsibility of an aggregate is to enforce invariants across state changes for all the entities within that aggregate.
Domain entities should always be valid entities. There are a certain number of invariants for an object that should always be true. For example, an order item object always has to have a quantity that must be a positive integer, plus an article name and price. Therefore, invariants enforcement is the responsibility of the domain entities (especially of the aggregate root) and an entity object should not be able to exist without being valid. Invariant rules are simply expressed as contracts, and exceptions or notifications are raised when they are violated.
The reasoning behind this is that many bugs occur because objects are in a state they should never have been in.
Let's propose we now have a SendUserCreationEmailService that takes a UserProfile ... how can we rationalize in that service that Name is not null? Do we check it again? Or more likely ... you just don't bother to check and "hope for the best"—you hope that someone bothered to validate it before sending it to you. Of course, using TDD one of the first tests we should be writing is that if I send a customer with a null name that it should raise an error. But once we start writing these kinds of tests over and over again we realize ... "what if we never allowed name to become null? we wouldn't have all of these tests!".
Implement validations in the domain model layer
Validations are usually implemented in domain entity constructor or in methods that can update the entity. There are multiple ways to implement validations, such as verifying data and raising exceptions if the validation fails. There are also more advanced patterns such as using the Specification pattern for validations, and the Notification pattern to return a collection of errors instead of returning an exception for each validation as it occus.
Validate conditions and throw exceptions
The following code example shows the simplest approach to validation in a domain entity by raising an exception. In the references table at the end of this section you can see links to more advanced implementations based on the patterns we have discussed previously.
public void SetAddress(Address address) { _shippingAddress = address?? throw new ArgumentNullException(nameof(address)); }
A better example would demonstrate the need to ensure that either the internal state did not change, or that all the mutations for a method occurred. For example, the following implementation would leave the object in an invalid state:
public void SetAddress(string line1, string line2, string city, string state, int zip) { _shippingAddress.line1 = line1 ?? throw new ... _shippingAddress.line2 = line2; _shippingAddress.city = city ?? throw new ... _shippingAddress.state = (IsValid(state) ? state : throw new …); }
If the value of the state is invalid, the first address line and the city have already been changed. That might make the address invalid.
A similar approach can be used in the entity's constructor, raising an exception to make sure that the entity is valid once it is created.
Use validation attributes in the model based on data annotations
Data annotations, like the Required or MaxLength attributes, can be used to configure EF Core database field properties, as explained in detail in the Table mapping section, but they no longer work for entity validation in EF Core (neither does the IValidatableObject.Validate method), as they have done since EF 4.x in .NET Framework.
Data annotations and the IValidatableObject interface can still be used for model validation during model binding, prior to the controller's actions invocation as usual, but that model is meant to be a ViewModel or DTO and that's an MVC or API concern not a domain model concern.
Having made the conceptual difference clear, you can still use data annotations and IValidatableObject in the entity class for validation, if your actions receive an entity class object parameter, which is not recommended. In that case, validation will occur upon model binding, just before invoking the action and you can check the controller's ModelState.IsValid property to check the result, but then again, it happens in the controller, not before persisting the entity object in the DbContext, as it had done since EF 4.x.
You can still implement custom validation in the entity class using data annotations and the IValidatableObject.Validate method, by overriding the DbContext's SaveChanges method.
You can see a sample implementation for validating IValidatableObject entities in this comment on GitHub. That sample doesn't do attribute-based validations, but they should be easy to implement using reflection in the same override.
However, from a DDD point of view, the domain model is best kept lean with use of exceptions in your entity's behavior methods, or by implementing the Specification and Notification patterns to enforce validation rules.
It can make sense to use data annotations at the application layer in ViewModel classes (instead of domain entities) that will accept input, to allow for model validation within the UI layer. However, this should not be done at the exclusion of validation within the domain model.
Validate entities by implementing the Specification pattern and the Notification pattern
Finally, a more elaborate approach to implementing validations in the domain model is by implementing the Specification pattern in conjunction with the Notification, as explained in some of the additional resources listed later.
It is worth mentioning that you can also use just one of those patterns—for example, validating manually with control statements, but using the Notification pattern to stack and return a list of validation errors.
Use deferred validation in the domain
There are various approaches to deal with deferred validations in the domain. In his book Implementing Domain-Driven Design, Vaughn Vernon discusses these in the section on validation.
Two-step validation
Also consider two-step validation. Use field-level validation on your command Data Transfer Objects (DTOs) and domain-level validation inside your entities. You can do this by returning a result object instead of exceptions in order to make it easier to deal with the validation errors.
Client-side validation (validation in the presentation layers)
Even when the source of truth is the domain model and ultimately you must have validation at the domain model level, validation can still be handled at both the domain model level (server side) and the UI (client side).
Client-side validation is a great convenience for users. It saves time they would otherwise spend waiting for a round trip to the server that might return validation errors. In business terms, even a few fractions of seconds multiplied hundreds of times each day adds up to a lot of time, expense, and frustration. Straightforward and immediate validation enables users to work more efficiently and produce better quality input and output.
Just as the view model and the domain model are different, view model validation and domain model validation might be similar but serve a different purpose. If you are concerned about DRY (the Don't Repeat Yourself principle), consider that in this case code reuse might also mean coupling, and in enterprise applications it is more important not to couple the server side to the client side than to follow the DRY principle.
Even when using client-side validation, you should always validate your commands or input DTOs in server code, because the server APIs are a possible attack vector. Usually, doing both is your best bet because if you have a client application, from a UX perspective, it is best to be proactive and not allow the user to enter invalid information.
Therefore, in client-side code you typically validate the ViewModels. You could also validate the client output DTOs or commands before you send them to the services.
The implementation of client-side validation depends on what kind of client application you are building. It will be different if you are validating data in a web MVC web application with most of the code in .NET, a SPA web application with that validation being coded in JavaScript or TypeScript, or a mobile app coded with Xamarin and C#.
Domain events: Design and implementation
Use domain events to explicitly implement side effects of changes within your domain. In other words, and using DDD terminology, use domain events to explicitly implement side effects across multiple aggregates. Optionally, for better scalability and less impact in database locks, use eventual consistency between aggregates within the same domain.
What is a domain event?
An event is something that has happened in the past. A domain event is, something that happened in the domain that you want other parts of the same domain (in-process) to be aware of. The notified parts usually react somehow to the events.
An important benefit of domain events is that side effects can be expressed explicitly.
For example, if you're just using Entity Framework and there has to be a reaction to some event, you would probably code whatever you need close to what triggers the event. So the rule gets coupled, implicitly, to the code, and you have to look into the code to, hopefully, realize the rule is implemented there.
On the other hand, using domain events makes the concept explicit, because there's a DomainEvent and at least one DomainEventHandler involved.
For example, in the eShopOnContainers application, when an order is created, the user becomes a buyer, so an OrderStartedDomainEvent is raised and handled in the ValidateOrAddBuyerAggregateWhenOrderStartedDomainEventHandler, so the underlying concept is evident.
In short, domain events help you to express, explicitly, the domain rules, based in the ubiquitous language provided by the domain experts. Domain events also enable a better separation of concerns among classes within the same domain.
It's important to ensue that, just like a database transaction, either all the operations related to a domain event finish successfully or none of them do.
Domain events are similar to messaging-style events, with one important difference. With real messaging, message queuing, message brokers, or a service bus using AMQP, a message is always sent asynchronously and communicated across processes and machines. This is useful for integrating multiple Bounded Contexts, microservices, or even different applications. However, with domain event, you want to raise an event from the domain operation you're currently running, but you want any side effects to occur within the same domain.
The domain events and their side effects (the actions triggered afterwards that are managed by event handlers) should occur almost immediately, usually in-process, and within the same domain. Thus, domain events could be synchronous or asynchronous. Integration events, however, should always be asynchronous.
Domain events versus integration events
Semantically, domain and integration events are the same thing: notifications about something that just happened. However, their implementation must be different. Domain events are just messages pushed to a domain event dispatcher, which could be implemented as an in-memory mediator based on an IoC container or any other method.
On the other hand, the purpose of integration events is to propagate committed transactions and updates to additional subsystems, whether they are other microservices, Bounded Contexts or even external applications. Hence, they should occur only if the entity is successfully persisted, otherwise it's as if the entire operation never happened.
As mentioned before, integration events must be based on asynchronous communication between multiple microservices (other Bounded Contexts) or even external systems/applications.
Thus, the event bus interface needs some infrastructure that allows inter-process and distributed communication between potentially remote services. It can be based on a commercial service bus, queues, a shared database used as a mailbox, or any other distributed and ideally push based messaging system.
Domain events as a preferred way to trigger side effects across multple aggregates within the same domain
If executing a command related to one aggregate instance requires additional domain rules to be run on one or more additional aggregates, you should design and implement those side effects to be triggered by domain events. As shown in Figure 7-14, and as one of the most important use cases, a domain event should be used to propagate state changes across multiple aggregates within the same domain model.

Figure 7-14. Domain events to enforce consistency between multiple aggregates within the same domain
Figure 7-14 shows how consistency between aggregates is achieved by domain events. When the user initiates an order, the Order Aggregate sends an OrderStarted domain event. The OrderStarted domain event is handled by the Buyer Aggregate to create a Buyer object in the ordering microservice, based on the original user info from the identity microservice (with information provided in the CreateOrder command).
Alternately, you can have the aggregate root subscribed for events raised by members of its aggregates (child entities). For instance, each OrderItem child entity can raise an event when the item price is higher than a specific amount, or when the product item amount is too high. The aggregate root can then receive those events and perform a global calculation or aggregation.
It's important to understand that this event-based communication is not implemented directly within the aggregates; you need to implement domain event handlers.
Handling the domain events is an application concern. The domain model layer should only focus on the domain logic—things that a domain expert would understand, not application infrastructure like handlers and side-effect persistence actions using repositories. Therefore, the application layer level is where you should have domain event handlers triggering actions when a domain event is raised.
Domain events can also be used to trigger any number of application actions, and what is more important, must be open to increase that number in the future in a decoupled way. For instance, when the order is started, you might want to publish a domain event to propagate that info to other aggregates or even to raise application actions like notifications.
The key point is the open number of actions to be executed when a domain event occurs. Eventually, the actions and rules in the domain and application will grow. The complexity or number of side-effect actions when something happens will grow, but if your code were coupled with "glue" (that is, creating specific objects with new), then every time you needed to add a new action you would also need to change working and tested code.
This change could result in new bugs and this approach also goes against the Open/Closed principle from SOLID. Not only that, the original class that was orchestrating the operations would grow and grow, which goes against the Single Responsibility Principle (SRP).
On the other hand, if you use domain events, you can create a fine-grained and decoupled implementation by segregating responsibilities using this approach:
- Send a command (for example, CreateOrder).
- Receive the command in a command handler.
- Execute a single aggregate's transaction.
- (Optional) Raise domain events for side effects (for example, OrderStartedDomainEvent).
- Handle domain events (within the current process) that will execute an open number of side effects in multiple aggregates or application actions. For example:
- Verify or create buyer and payment method.
- Create and send a related integration event to the event bus to propagate states across microservices or trigger external actions like sending an email to the buyer.
- Handle other side effects.
As shown in Figure 7-15, starting from the same domain event, you can handle multiple actions related to other aggregates in the domain or additional application actions you need to perform across microservices connecting with integration events and the event bus.

Figure 7-15. Handling multiple actions per domain
There can be several handlers for the same domain event in the Application Layer, one handler can solve consistency between aggregates and another handler can publish an integration event, so other microservices can do something with it. The event handlers are typically in the application layer, because you'll use infrastructure objects like repositories or an application API for the microservice's behavior. In that sense, event handlers are similar to command handlers, so both are part of the application layer. The important difference is that a command should be processed only once. A domain event could be processed zero or n times, because it can be received by multiple receivers or event handlers with a different purpose for each handler.
Having an open number of handlers per domain event allows you to add as many domain rules as needed, without affecting current code. For instance, implementing the following business rule might as easy as adding a few event handlers (or even just one):
When the total amount purchased by a cutomer in the store, across any number of orders, exceeds $6,000, apply a 10% off discount to every new order and notify the customer with an email about that discount for future orders.
Implement domain events
In C#, a domain event is simply a data-holding structure or class, like a DTO, with all the information related to what just happened in the domain, as shown in the following example:
public class OrderStartedDomainEvent : INotification { public string UserId { get; } public string UserName { get; } public int CardTypeId { get; } public string CardNumber { get; } public string CardSecurityNumber { get; } public string CardHolderName { get; } public DateTime CardExpiration { get; } public Order Order { get; } public OrderStartedDomainEvent(Order order, string userId, string userName, int cardTypeId, string cardNumber, string cardSecurityNumber, string cardHolderName, DateTime cardExpiration) { Order = order; UserId = userId; UserName = userName; CardTypeId = cardTypeId; CardNumber = cardNumber; CardSecurityNumber = cardSecurityNumber; CardHolderName = cardHolderName; CardExpiration = cardExpiration; } }
This is essentially a class that holds all the data related to the OrderStarted event.
In terms of the ubiquitous language of the domain, since an event is something that happened in the past, the class name of the event should be represented as a past-tense verb, like OrderStartedDomainEvent or OrderShippedDomainEvent. That's how the domain event is implemented in the ordering microservice in eShopOnContainers.
As noted earlier, an important characteristic of events is that since an event is something that happened in the past, it shouldn't change. Therefore, it must be an immutable class. You can see in the previous code that the properties are read-only. There's no way to update the object, you can only set values when you create it.
It's important to highlight here that if domain events were to be handled asynchronously, using a queue that required serializing and deserializing the event objects, the properties would have to be "private set" instead of read-only, so the deserializer would be able to assign the values upon dequeuing. This is not an issue in the Ordering microservice, as the domain event pub/sub is implemented synchronously using MediatR.
Raise domain events
The next question is how to raise a domain event so it reaches its related event handlers. You can use multiple approaches.
Udi Dahan originally proposed (for example, in several related posts, such as Domain Events – Take 2) using a static class for managing and raising the events. This might include a static class named DomainEvents that would raise domain events immediately when it's called, using syntax like DomainEvents.Raise(Event myEvent). Jimmy Bogard wrote a blog post (Strengthening your domain: Domain Events) that recommends a similar approach.
However, when the domain events class is static, it also dispatches to handlers immediately. This makes testing and debugging more difficult, because the event handlers with side-effects logic are executed immediately after the event is raised. When you're testing and debugging, you just want to focus on what is happening in the current aggregate classes; you don't want to suddenly be redirected to other event handlers for side effects related to other aggregates or application logic. This is why other approaches have evolved, as explained in the next section.
The deferred approach to raise and dispatch events
Instead of dispatching to a domain event handler immediately, a better approach is to add the domain events to a collection and then to dispatch those domain events right before or right after committing the transaction (as with SaveChanges in EF). (This approach was described by Jimmy Bogard in this post A better domain events pattern.)
Deciding if you send the domain events right before or right after committing the transaction is important, since it determines whether you will include the side effects as part of the same transaction or in different transactions. In the latter case, you need to deal with eventual consistency across multiple aggregates. This topic is discussed in the next section.
The deferred approach is what eShopOnContainers uses. First, you add the events happening in your entities into a collection or list of events per entity. That list should be part of the entity object, or even better, part of your base entity class, as shown in the following example of the Entity base class:
public abstract class Entity { //... private List<INotification> _domainEvents; public List<INotification> DomainEvents => _domainEvents; public void AddDomainEvent(INotification eventItem) { _domainEvents = _domainEvents ?? new List<INotification>(); _domainEvents.Add(eventItem); } public void RemoveDomainEvent(INotification eventItem) { _domainEvents?.Remove(eventItem); } //... Additional code }
When you want to raise an event, you just add it to the event collection from code at any method of the aggregate-root entity.
The following code, part of the Order aggregate-root at eShopOnContainers, shows an example:
var orderStartedDomainEvent = new OrderStartedDomainEvent(this, //Order object cardTypeId, cardNumber, cardSecurityNumber, cardHolderName, cardExpiration); this.AddDomainEvent(orderStartedDomainEvent);
Notice that the only thing that the AddDomainEvent method is doing is adding an event to the list. No event is dispatched yet, and no event handler is invoked yet.
You actually want to dispatch the events later on, when you commit hte transaction to the database. If you are using Entity Framework Core, that means in the SaveChanges method of your EF DbContext, as in the following code:
// EF Core DbContext public class OrderingContext : DbContext, IUnitOfWork { // ... public async Task<bool> SaveEntitiesAsync(CancellationToken cancellationToken = default(CancellationToken)) { // Dispatch Domain Events collection. // Choices: // A) Right BEFORE committing data (EF SaveChanges) into the DB. This makes // a single transaction including side effects from the domain event // handlers that are using the same DbContext with Scope lifetime // B) Right AFTER committing data (EF SaveChanges) into the DB. This makes // multiple transactions. You will need to handle eventual consistency and // compensatory actions in case of failures. await _mediator.DispatchDomainEventsAsync(this); // After this line runs, all the changes (from the Command Handler and Domain // event handlers) performed through the DbContext will be committed var result = await base.SaveChangesAsync(); } }
With this code, you dispatch the entity events to their respective event handlers.
The overall result is that you've decoupled the raising of a domain event (a simple add into a list in memory) from dispatching it to an event handler. In addition, depending on what kind of dispatcher you are using, you could dispatch the events synchronously or asynchronously.
Be aware that transactional boundaries come into significant play here. If your unit of work and transaction can span more than one aggregate (as when using EF Core and a relational database), this can work well. But if the transaction cannot span aggregates, you have to implement additional steps to achieve consistency. This is another reason why persistence ignorance is not universal; it depends on the storage system you use.
Single transaction across aggregates versus eventual consistency across aggregates
The question of whether to perform a single transaction across aggregates versus relying on eventual consistency across those aggregates is a controversial one. Many DDD authors like Eric Evans and Vaughn Vernon advocate the rule that one transaction = one aggregate and therefore argue for eventual consistency across aggregates. For example, in his book Domain-Driven Design, Eric Evans says this:
Any rule that spans Aggregates will not be expected to be up-to-date at all times. Through event processing, batch processing, or other update mechanisms, other dependencies can be resolved within some specific time. (page 128)
Vaughn Vernon says the following in Effective Aggregate Design. Part II: Making Aggregates Work Together:
Thus, if executing a command on one aggregate instance requires that additional business rules execute on one or more aggregates, use eventual consistency [...] There is a practical way to support eventual consistency in a DDD model. An aggregate method publishes a domain event that is in time delivered to one or more asynchronous subscribers.
This rationale is based on embracing fine-grained transactions instead of transactions spanning many aggregates or entities. The idea is that in the second case, the number of database locks will be substantial in large-scale applications with high scalability needs. Embracing the fact that highly scalable applications need not have instant transactional consistency between multiple aggregates helps with accepting the concept of eventual consistency. Atomic changes are often not needed by the business, and it is in any case the responsibility of the domain experts to say whether particular operations need atomic transactions or not. If an operation always needs an atomic transaction between multiple aggregates, you might ask whether your aggregate should be larger or wasn't correctly designed.
However, other developers and architects like Jimmy Bogard are okay with spanning a single transaction across several aggregates—but only when those additional aggregates are related to side effects for the same original command. For instance, in A better domain events pattern, Bogard says this:
Typically, I want the side effects of a domain event to occur within the same logical transaction, but not necessarily in the same scope of raising the domain event [...] Just before we commit our transaction, we dispatch our events to their respective handlers.
The domain event dispatcher: mapping from events to event handlers
Once you're able to dispatch or publish the events, you need some kind of artifact that will publish the event, so that every related handler can get it and process side effects based on that event.
One approach is a real messaging system or even an event bus, possibly based on a service bus as opposed to in-memory events. However, for the first case, real messaging would be overkill for processing domain events, since you just need to process those events within the same process (that is, within the same domain and application layer).
How to subscribe to domain events
When you use MediatR, each event handler must use an event type that is provided on the generic parameter of the INotificationHandler interface, as you can see in the following code:
public class ValidateOrAddBuyerAggregateWhenOrderStartedDomainEventHandler : INotificationHandler<OrderStartedDomainEvent>
Based on the relationship between event and event handler, which can be considered the subscription, the MediatR artifact can discover all the event handlers for each event and trigger each one of those event handlers.
How to handle domain events
Finally, the event handler usually implements application layer code that uses infrastructure repositories to obtain the required additional aggregates and to execute side-effect domain logic. The following domain event handler code at eShopOnContainers, shows an implementation example.
public class ValidateOrAddBuyerAggregateWhenOrderStartedDomainEventHandler : INotificationHandler<OrderStartedDomainEvent> { private readonly ILogger _logger; private readonly IBuyerRepository _buyerRepository; private readonly IOrderingIntegrationEventService _orderingIntegrationEventService; public ValidateOrAddBuyerAggregateWhenOrderStartedDomainEventHandler( ILogger<ValidateOrAddBuyerAggregateWhenOrderStartedDomainEventHandler> logger, IBuyerRepository buyerRepository, IOrderingIntegrationEventService orderingIntegrationEventService) { _buyerRepository = buyerRepository ?? throw new ArgumentNullException(nameof(buyerRepository)); _orderingIntegrationEventService = orderingIntegrationEventService ?? throw new ArgumentNullException(nameof(orderingIntegrationEventService)); _logger = logger ?? throw new ArgumentNullException(nameof(logger)); } public async Task Handle( OrderStartedDomainEvent domainEvent, CancellationToken cancellationToken) { var cardTypeId = domainEvent.CardTypeId != 0 ? domainEvent.CardTypeId : 1; var buyer = await _buyerRepository.FindAsync(domainEvent.UserId); var buyerExisted = buyer is not null; if (!buyerExisted) { buyer = new Buyer(domainEvent.UserId, domainEvent.UserName); } buyer.VerifyOrAddPaymentMethod( cardTypeId, $"Payment Method on {DateTime.UtcNow}", domainEvent.CardNumber, domainEvent.CardSecurityNumber, domainEvent.CardHolderName, domainEvent.CardExpiration, domainEvent.Order.Id); var buyerUpdated = buyerExisted ? _buyerRepository.Update(buyer) : _buyerRepository.Add(buyer); await _buyerRepository.UnitOfWork .SaveEntitiesAsync(cancellationToken); var integrationEvent = new OrderStatusChangedToSubmittedIntegrationEvent( domainEvent.Order.Id, domainEvent.Order.OrderStatus.Name, buyer.Name); await _orderingIntegrationEventService.AddAndSaveEventAsync(integrationEvent); OrderingApiTrace.LogOrderBuyerAndPaymentValidatedOrUpdated( _logger, buyerUpdated.Id, domainEvent.Order.Id); } }
The previous domain event handler code is considered application layer code because it uses infrastructure repositories, as explained in the next section on the infrastructure-persistence layer. Event handlers could also use other infrastructure components.
Domain events can generate integration events to be published outside of the microservice boundaries
Finally, it's important to mention that you might sometimes want to propagate events across multiple microservices. That propagation is an integration event, and it could be published through an event bus from any specific domain event handler.
Conclusions on domain events
As stated, use domain events to explicitly implement side effects of changes within your domain. To use DDD terminology, use domain events to explicitly implement side effects across one or multiple aggregates. Additionally, and for better scalability and less impact on database locks, use eventual consistency between aggregates within the same domain.
The reference app uses MediatR to propagate domain events synchronously across aggregates, within a single transaction. However, you could also use some AMQP implementation like RabbitMQ or Azure Service Bus to propagate domain events asynchronously, using eventual consistency but, as mentioned above, you have to consider the need for compensatory actions in case of failures.
Design the infrastructure persistence layer
Data persistence components provide access to the data hosted within the boundaries of a microservice (that is, a microservice's database). They contain the actual implementation of components such as repositories and Unit of Work classes, like custom Entity Framework (EF) DbContext objects. EF DbContext implements both the Repository and the Unit of Work patterns.
The Repository pattern
The Repository pattern is a Domain-Driven Design pattern intended to keep persistence concerns outside of the system's domain model. One or more persistence abstractions - interfaces - are defined in the domain model, and these abstractions have implementations in the form of persistence-specific adapters defined elsewhere in the application.
Repository implementations are classes that encapsulate the logic required to access data sources. They centralize common data access functionality, providing better maintainbility and decoupling the infrastructure or technology used to access databases from the domain model. If you use an Object-Relational Mapper (ORM) like Entity Framework, the code that must be implemented is simplified, thanks to LINQ and strong typing. This lets you focus on the data persistence logic rather than on data access plumbing.
The Repository pattern is a well-documented way of working with a data source. In the book Patterns of Enterprise Application Architecture, Martin Fowler describes a repository as follows:
A repository performs the tasks of an intermediary between the domain model layers and data mapping, acting in a similar way to a set of domain objects in memory. Client objects declarat build queries and send them to the repositories for answers. Conceptually, a repository encapsulates a set of objects stored in the database and operations that can be performed on them, providing a way that is closer to the persistence layer. Repositories, also, support the purpose of separating, clearly and in one direction, the dependency between the work domain and the data allocation or mapping.
Define one repository per aggregate
For each aggregate or aggregate root, you should create one reposiotry class. You may be able to leverage C# Generics to reduce the total number concrete classes you need to maintain (as demonstrated later in this chapter). In a microservice based on Domain-Driven Design (DDD) patterns, the only channel you should use to update the database should be the repositories. This is because they have a one-to-one relationship with the aggregate root, which controls the aggregate's invariants and transactional consistency. It's okay to query the database through other channels (as you can do following a CQRS approach), because queries don't change the state of the database. However, the transactional area (that is, the updates) must always be controlled by the repositories and the aggregate roots.
Basically, a repository allows you to populate data in memory that comes from the database in the form of the domain entities. Once the entities are in memory, they can be changed and then persisted back to the database through transactions.
As noted earlier, if you're using the CQS/CQRS architectural pattern, the initial queries are performed by side queries out of the domain model, performed by simple SQL statements using Dapper. This approach is much more flexible than repositories because you can query and join any tables you need, and these queries aren't restricted by rules from the aggregates. That data goes to the presentation layer or client app.
if the user makes changes, the data to be updated comes from the client app or presentation layer to the application layer (such as a Web API service). When you receive a command in a command handler, you use repositories to get the data you want to update from the database. You update it in memory with the data passed with the commands, and you then add or update the data (domain entities) in the database through a transaction.
It's important to emphasize again that you should only define one repository for each aggregate root, as shown in Figure 7-17. To achieve the goal of the aggregate root to maintian transactional consistency between all the objects within the aggregate, you should never create a repository for each table in the database.

Figure 7-17. The relationship between repositories, aggregates, and database tables
The above diagram shows the relationships between Domain and Infrastructure layers: Buyer Aggregate denpends on the IBuyerRepository and Order Aggregate depends on the IOrderRepository interfaces, these interfaces are implemented in the Infrastructure layer by the corresponding repositories that depend on UnitOfWork, also implemented there, that accesses the tables in the Data tier.
Enforce one aggregate root per repository
It can be valuable to implement your repository design in such a way that it enforces the rule that only aggregate roots should have repositories. You can create a generic or base repository type that constrains the type of entities it works with no ensure have the marker interface.IAggregateRoot
Thus, each repository class implemented at infrastructure layer implements its own contract or interface, as shown in the following code:
namespace Microsoft.eShopOnContainers.Services.Ordering.Infrastructure.Repositories { public class OrderRepository : IOrderRepository { // ... } }
Each specific repository interface implements the generic IRepository interface:
public interface IOrderRepository : IRepository<Order> { Order Add(Order order); // ... }
However, a better way to have the code enforce the convention that each repository is related to
public interface IRepository<T> where T : IAggregateRoot { //.... }
The Repository pattern makes it easier to test your application logic
The Repository pattern allows you to easily test your application with unit tests. Remember that unit tests only test your code, not infrastructure, so the repository abstractions make it easier to achieve that goal.
As noted in an earlier section, it's recommended that you define and place the repository interfaces in the domain model layer so the application layer, such as your Web API microservice, doesn't depend directly on the infrastructure layer where you've implemented the actual repository classes. By doing this and using Dependency Injection in the controllers of your Web API, you can implement mock repositories that return fake data instead of data from the database. This decoupled approach allows you to create and run unit tests that focus the logic of your application without requiring connectivity to the database.
Connections to databases can fail and, more importantly, running hundreds of tests against a database is bad for two reasons. First, it can take a long time because of the large number of tests. Second, the database records might change and impact the results of your tests, especially if your tests are running in parallel, so that they might not be consistent. Unit tests typically can run in parallel; integration tests may not support parallel execution depending on their implementation. Testing against the database isn't a unit test but an integration test. You should have many unit tests running fast, but fewer integration tests against the databases.
In terms of separation of concerns for unit tests, your logic operates on domain entities in memory. It assumes the repository class has delivered those. Once your logic modifies the domain entities, it assumes the repository class will store them correctly. The important point here is to create unit tests against your domain model and its domain logic. Aggregate roots are the main consistency boundaries in DDD.
The repositories implemented in eShopOnContainers rely on EF Core's DbContext implementation of the Repository and Unit of Work patterns using its change tracker, so they don't duplicate this functionality.
The difference between the Repository pattern and the legacy Data Access class (DAL class) pattern
A typical DAL object directly performs data access and persistence operations against storage, often at the level of a single table and row. Simple CRUD operations implemented with a set of DAL classes frequently do not support transactions (though this is not always the case). Most DAL class approaches make minimal use of abstractions, resulting in tight coupling between application or Business Logic Layer (BLL) classes that call the DAL objects.
When using repository, the implementation details of persistence are encapsulated away from the domain model. The use of an abstraction provides ease of extending behavior through patterns like Decorators or Proxies. For instance, cross-cutting concerns like caching, logging, and error handling can all be applied using these patterns rather than hard-coded in the data access code itself. It's also trivial to support multiple repository adapters which may be used in different environments, from local development to shared staging environments to production.
Implementing Unif of Work
A unit of work refers to a single transaction that involves multiple insert, update, or delete operations. In simple terms, it means that for a specific user action, such as a registration on a website, all the insert, update, and delete operations are handled in a single transaction. This is more efficient than handling multiple database operations in a chattier way.
These multiple persistence operations are performed later in a single action when your code from the application layer commands it. The decision about applying the in-memory changes to the actual database storage is typically based on the Unit of Work pattern. In EF, the Unit of Work pattern is implemented by a DbContext and is executed when a call is made to .SaveChanges
In many cases, this pattern or way of applying operations against the storage can increase application performance and reduce the
The Unit of Work pattern can be implemented with or without using the Repository pattern.
Repositories shouldn't be mandatory
Custom repositories are useful for the reasons cited earlier, and that is the approach for the ordering microservice in eShopOnContainers. However, it isn't an essential pattern to implement in a DDD desgin or even in general .NET development.
For instance, Jimmy Bogard, when providing direct feedback for this guide, said the following:
This'll probably be my biggest feedback. I'm really not a fan of repositories, mainly because they hide the important details of the underlying persistence mechanism. It's why I go for MeidatR for commands, too. I can use the full power of the persistence layer, and push all that domain behavior into my aggregate roots. I don't usually want to mock my repositories - I still need to have that intergration test with the real thing. Going CQRS meant that we didn't really have a need for repositories any more.
Repositories might be useful, but they are not critical for your DDD design in the way that the Aggregate pattern and a rich domain model are. Therefore, use the Repository pattern or not, as you see fit.
Implement the infrastructure persistence layer with Entity Framework Core
When you use relational databases such as SQL Server, Oracle, or PostgreSQL, a recommended approach is to implement the persistence layer based on Entity Framework (EF). EF supports LINQ and provides strongly objects for your model, as well as simplified persistence into your database.
Entity Framework has a long history as part of the .NET Framework. When you use .NET, you should also use Entity Framework Core, which runs on Windows or Linux in the same way as .NET. EF Core is a complete rewrite of Entity Framework that's implemented with a much smaller footprint and important improvements in performance.
Introduction to Entity Framework Core
Entity Framework (EF) Core is a lightweight, extensible, and cross-platform version of the popular Entity Framework data access technology. It was introduced with .NET Core in mid-2016.
Since an introduction to EF Core is already available in Microsofte documentation, here we simply provide links to that information.
Infrastructure in Entity Framewok Core from a DDD perspective
From a DDD point of view, an important capability of EF is the ability to use POCO domain entities, also known in EF terminology as POCO code-first entities. If you use POCO domain entities, your domain model classes are persistence-ignorant, following the Persistence Ignorance and the Infrastructure Ignorance principles.
Per DDD patterns, you should encapsulate domain behavior and rules within the entity class itself, so it can control invariants, validations, and rules when accessing any collection. Therefore, it is not a good practise in DDD to allow public access to collections of child entities or value objects. Instead, you want to expose methods that control how and when your fields and property collections can be updated, and what behavior and actions should occur when that happens.
Since EF Core 1.1, to satisfy those DDD requirements, you can have plain fields in your entities instead of public properties. If you do not want an entity field to be externally acessible, you can just create the attribute or field instead of a property. You can also use private property setters.
In a similar way, you can now have read-only access to collections by using a public property typed as IReadOnlyCollection<T>, which is backed by a private field member for the collection (like a List<T>) in your entity that relies on EF for persistence. Previous versions of Entity Framework required collection properties to support ICollection<T>, which meant that any developer using the parent entity class could add or remove items through its property collections. That possibility would be against the recommended patterns in DDD.
You can use a private collection while exposing a read-only IReadOnlyCollection<T> object, as shown in the following code example:
public class Order : Entity { // Using private fields, allowed since EF Core 1.1 private DateTime _orderDate; // Other fields ... private readonly List<OrderItem> _orderItems; public IReadOnlyCollection<OrderItem> OrderItems => _orderItems; protected Order() { } public Order(int buyerId, int paymentMethodId, Address address) { // Initializations ... } public void AddOrderItem(int productId, string productName, decimal unitPrice, decimal discount, string pictureUrl, int units = 1) { // Validation logic... var orderItem = new OrderItem(productId, productName, unitPrice, discount, pictureUrl, units); _orderItems.Add(orderItem); } }
The OrderItems property can only be accessed as read-only using IReadOnlyCollection<OrderItem>. This type is read-only so it is protected against regular external updates.
EF Core provides a way to map the domain model to the physical database without "contaminating" the domain model. It is pure .NET POCO code, because the mapping action is implemented in the persistence layer. In that mapping action, you need to configure the fields-to-database mapping. In the following example of the OnModelCreating method from OrderingContext and the OrderEntityTypeConfiguration class, the call to SetPropertyAccessMode tells EF Core to access the OrderItems property through its field.
// At OrderingContext.cs from eShopOnContainers protected override void OnModelCreating(ModelBuilder modelBuilder) { // ... modelBuilder.ApplyConfiguration(new OrderEntityTypeConfiguration()); // Other entities' configuration ... } // At OrderEntityTypeConfiguration.cs from eShopOnContainers class OrderEntityTypeConfiguration : IEntityTypeConfiguration<Order> { public void Configure(EntityTypeBuilder<Order> orderConfiguration) { orderConfiguration.ToTable("orders", OrderingContext.DEFAULT_SCHEMA); // Other configuration var navigation = orderConfiguration.Metadata.FindNavigation(nameof(Order.OrderItems)); //EF access the OrderItem collection property through its backing field navigation.SetPropertyAccessMode(PropertyAccessMode.Field); // Other configuration } }
When you use fields instead of properties, the OrderItem entity is persisted as if it had a List<OrderItem> property. However, it exposes a single accessor, the AddOrderItem method, for adding new items to the order. As a result, behavior and data are tied together and will be consistent throughout any application code that uses the domain model.
Implement custom repositories with Entity Framework Core
At the implementation level, a repository is simply a class with data persistence code coordinated by a unit of work (DBContext in EF Core) when performing updates, as shown in the following class:
// using directives... namespace Microsoft.eShopOnContainers.Services.Ordering.Infrastructure.Repositories { public class BuyerRepository : IBuyerRepository { private readonly OrderingContext _context; public IUnitOfWork UnitOfWork { get { return _context; } } public BuyerRepository(OrderingContext context) { _context = context ?? throw new ArgumentNullException(nameof(context)); } public Buyer Add(Buyer buyer) { return _context.Buyers.Add(buyer).Entity; } public async Task<Buyer> FindAsync(string buyerIdentityGuid) { var buyer = await _context.Buyers .Include(b => b.Payments) .Where(b => b.FullName == buyerIdentityGuid) .SingleOrDefaultAsync(); return buyer; } } }
The IBuyerRepository interface comes from the domain model layer as a contract. However, the repository implementation is done at the persistence and infrastructure layer.
The EF DbContext comes through the constructor through Dependency Injection. It is shared between multiple repositories within the same HTTP request scope, thanks to its default lifetime (ServiceLifetime.Scoped) in the IoC container (which can also be explicitly set with services.AddDbContext<>).
Methods to implement in a repository (updates or transactions versus queries)
Within each repository class, you should put the persistence methods that update the state of entities contained by its related aggregate. Remember there is one-to-one relationship between an aggregate and its related repository. Consider that an aggregate root entity object might have embedded child entities within its EF graph. For example, a buyer might have multiple payment methods as related child entities.
Since the approach for the ordering microservice in eShopOnContainers is also based on CQS/CQRS, most of the queries are not implemented in custom repositories. Developers have the freedom to create the queries and joins they need for the presentation layer without the restrictions imposed by aggregates, custom repositories per aggregate, and DDD in general. Most of the custom repositories suggested by this guide have several update or transactional methods but just the query methods needed to get data to be updated. For example, the BuyerRepository repository implements a FindAsync method, because the application needs to know whether a particular buyer exists before creating a new buyer related to the order.
However, the real query methods to get data to send to the presentation layer or client apps are implemented, as mentioned, in the CQRS queries based on flexible queries using Dapper.
Using a custom repository versus using EF DbContext directly
The Entity Framework DbContext class is based on the Unit of Work and Repository patterns and can be used directly from your code, such as from an ASP.NET Core MVC controller. The Unit of Work and Repository patterns result in the simplest code, as in the CRUD catalog microservice in eShopOnContainers. In cases where you want the simplest code possible, you might want to directly use the DbContext class, as many developers do.
However, implementing custom repositories provides several benefits when implementing more complex microservices or applications. The Unit of Work and Repository patterns are intended to encapsulate the infrastructure persistence layer so it is decoupled from the application and domain-model layers. Implementing these patterns can facilitate the use of mock repositories simulating access to the database.
In Figure 7-18, you can see the differences between not using repositories (directly using the EF DbContext) versus using repositories, which makes it easier to mock those repositories.
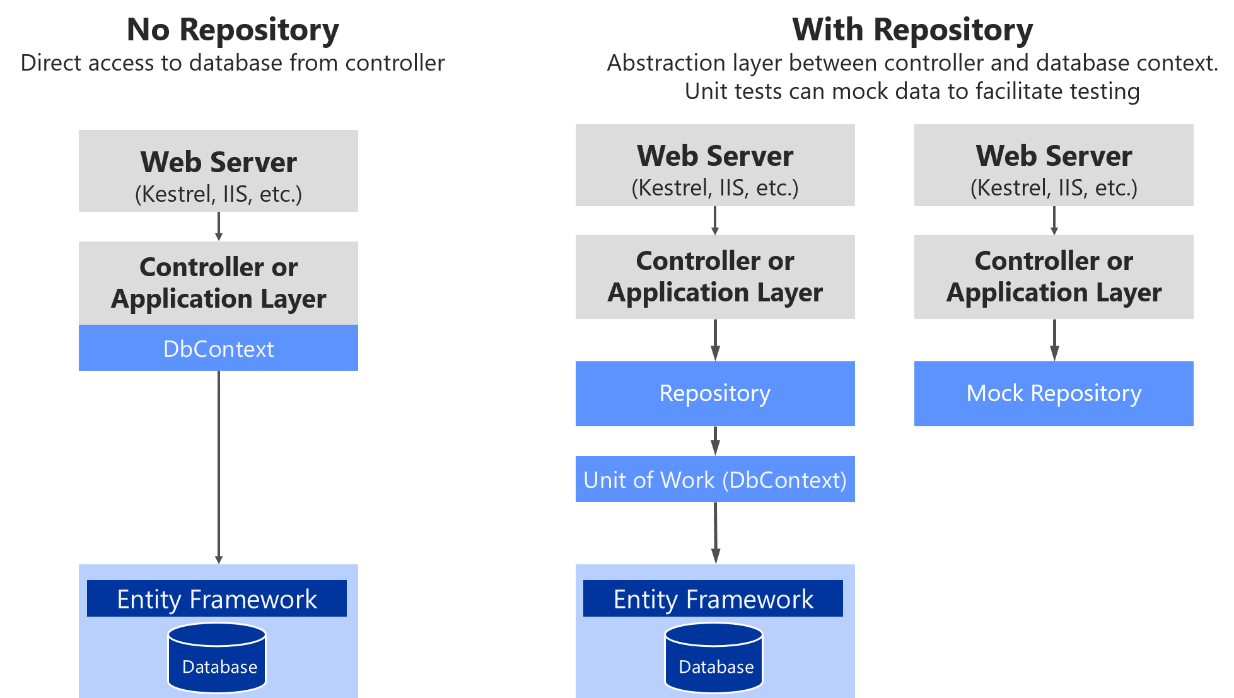
Figure 7-18. Using custom repositories versus a plain DbContext
Figure 7-18 shows that using a custom repository adds an abstraction layer that can be used to ease testing by mocking the repository. There are multiple alternatives when mocking. You could mock just repositories or you could mock a whole unit of work. Usually mocking just the repositories is enough, and the complexity to abstract and mock a whole unit of work is usually not needed.
Later, when we focus on the application layer, you will see how Dependency Injection works in ASP.NET Core and how it is implemented when using repositories.
In short, custom repositories allow you to test code more easily with unit tests that are not impacted by the data tier state. If you run tests that also access the actual database through the Entity Framework, they are not unit tests but integration tests, which are a lot slower.
If you were using DbContext directly, you would have to mock it or to run unit tests by using an in-memory SQL Server with predictable data for unit tests. But mocking the DbContext or controlling fake data requires more work than mocking at the repository level. Of course, you could always test the MVC controllers.
EF DbContext and IUnitOfWork instance lifetiem in your IoC container
The DbContext object (exposed as an IUnitOfWork object) should be shared among multiple repositories within the same HTTP request scope. For example, this is true when the operation being executed must deal with multiple aggregates, or simply because you are using multiple repository instances. It is also important to mention that the IUnitOfWork interface is part of your domain layer, not an EF Core type.
In order to do that, the instance of the DbContext object has to have its service lifetime set to ServiceLifetime.Scoped. This is the default lifetime when registering a DbContext with builder.Services.AddDbContext in your IoC container from the Program.cs file in your ASP.NET Core Web API project. The following code illustrates this.
// Add framework services. builder.Services.AddMvc(options => { options.Filters.Add(typeof(HttpGlobalExceptionFilter)); }).AddControllersAsServices(); builder.Services.AddEntityFrameworkSqlServer() .AddDbContext<OrderingContext>(options => { options.UseSqlServer(Configuration["ConnectionString"], sqlOptions => sqlOptions.MigrationsAssembly(typeof(Startup).GetTypeInfo(). Assembly.GetName().Name)); }, ServiceLifetime.Scoped // Note that Scoped is the default choice // in AddDbContext. It is shown here only for // pedagogic purposes. );
The DbContext instantiation mode should not be configured as ServiceLifetime.Transient or ServiceLifetime.Singleton.
The repository instance lifetime in your Ioc container
In a similar way, repository's lifetime should usually be set as scoped (InstancePerLifetimeScope in Autofac). It could also be transient (InstancePerDependency in Autofac), but your service will be more efficient in regards to memory when using the scoped lifetime.
// Registering a Repository in Autofac IoC container builder.RegisterType<OrderRepository>() .As<IOrderRepository>() .InstancePerLifetimeScope();
Using the singleton lifetime for the repository could cause you serious concurrency problems when your DbContext is set to scoped (InstancePerLifetimeScope) lifetime (the default lifetimes for a DBContext). As long as your service lifetimes for your repositories and your DbContext are both Scoped, you'll avoid these issues.
Table mapping
Table mapping identifies the table data to be queried from and saved to the database. Previously you saw how domain entities (for example, a product or order domain) can be used to generate a related database schema. EF is strongly designed around the concept of conventions. Conventions address questions like "What will the name of a table be?" or "What property is the primary key?" Conventions are typically based on conventional names. For example, it is typical for the primary key to be a property that ends with Id.
By convention, each entity will be set up to map to a table with the same name as the DbSet<TEntity> property that exposes the entity on the derived context. If no DbSet<TEntity> value is provided for the given entity, the class name is used.
Data Annotations versus Fluent API
There are many additional EF Core conventions, and most of them can be changed by using either annotations or Fluent API, implemented within the OnModelCreating method.
Data annotations must be used on the entity model classes themselves, which is a more intrusive way from a DDD point of view. This is because you are contaminating your model with data annotations related to the infrastructure database. On the other hand, Fluent API is a convenient way to change most conventions and mappings within your data persistence infrastructure layer, so the entity model will be clean and decoupled from the persistence infrastructure.
Fluent API and the OnModelCreating method
As mentioned, in order to change conventions and mappings, you can use the OnModelCreating method in the DbContext class.
The ordering microservice in eShopOnContainers implement explicit mapping and configuration, when needed, as shown in the following code.
// At OrderingContext.cs from eShopOnContainers protected override void OnModelCreating(ModelBuilder modelBuilder) { // ... modelBuilder.ApplyConfiguration(new OrderEntityTypeConfiguration()); // Other entities' configuration ... } // At OrderEntityTypeConfiguration.cs from eShopOnContainers class OrderEntityTypeConfiguration : IEntityTypeConfiguration<Order> { public void Configure(EntityTypeBuilder<Order> orderConfiguration) { orderConfiguration.ToTable("orders", OrderingContext.DEFAULT_SCHEMA); orderConfiguration.HasKey(o => o.Id); orderConfiguration.Ignore(b => b.DomainEvents); orderConfiguration.Property(o => o.Id) .UseHiLo("orderseq", OrderingContext.DEFAULT_SCHEMA); //Address value object persisted as owned entity type supported since EF Core 2.0 orderConfiguration .OwnsOne(o => o.Address, a => { a.WithOwner(); }); orderConfiguration .Property<int?>("_buyerId") .UsePropertyAccessMode(PropertyAccessMode.Field) .HasColumnName("BuyerId") .IsRequired(false); orderConfiguration .Property<DateTime>("_orderDate") .UsePropertyAccessMode(PropertyAccessMode.Field) .HasColumnName("OrderDate") .IsRequired(); orderConfiguration .Property<int>("_orderStatusId") .UsePropertyAccessMode(PropertyAccessMode.Field) .HasColumnName("OrderStatusId") .IsRequired(); orderConfiguration .Property<int?>("_paymentMethodId") .UsePropertyAccessMode(PropertyAccessMode.Field) .HasColumnName("PaymentMethodId") .IsRequired(false); orderConfiguration.Property<string>("Description").IsRequired(false); var navigation = orderConfiguration.Metadata.FindNavigation(nameof(Order.OrderItems)); // DDD Patterns comment: //Set as field (New since EF 1.1) to access the OrderItem collection property through its field navigation.SetPropertyAccessMode(PropertyAccessMode.Field); orderConfiguration.HasOne<PaymentMethod>() .WithMany() .HasForeignKey("_paymentMethodId") .IsRequired(false) .OnDelete(DeleteBehavior.Restrict); orderConfiguration.HasOne<Buyer>() .WithMany() .IsRequired(false) .HasForeignKey("_buyerId"); orderConfiguration.HasOne(o => o.OrderStatus) .WithMany() .HasForeignKey("_orderStatusId"); } }
You could set all the Fluent API mappings within the same OnModelCreating method, but it's advisable to partition that code and have multiple configuration classes, one per entity, as shown in the example. Especially for large models, it is advisable to have separate configuration classes for configuring different entity types.
The code in the example shows a few explicit declarations and mapping. However, EF Core conventions do many of those mappings automatically, so the actual code you would need in your case might be smaller.
The Hi/Lo algorithm in EF Core
An interesting aspect of code in the preceding example is that it uses the Hi/Lo algorithm as the key generation strategy.
The Hi/Lo algorithm is useful when you need unique keys before committing changes. As a summary, the Hi-Lo algorithm assigns unique identifiers to table rows while not depending on storing the row in the database immediately. This lets you start using the identifiers right away, as happens with regular sequential database IDs.
The Hi/Lo algorithm describes a mechanism for getting a batch of unique IDs from a related database sequence. These IDs are safe to use because the database guarantees the uniqueness, so there will be no collisions between users. This algorithm is interesting for these reasons:
- It does not break the Unit of Work pattern.
- It gets sequence IDs in batches, to minimize round trips to the database.
- It generates a human readable identifier, unlike techniques that use GUIDs.
EF Core supports HiLo with the UseHiLo method, as shown in the preceding example.
Map fields instead of properties
With this feature, available since EF Core 1.1, you can directly map columns to fields. It is possible to not use properties in the entity class, and just to map columns from a table to fields. A common use for that would be private fields for any internal state that do not need to be accessed from outside the entity.
You can do this with single fields or also with collections, like a List<> field. This point was mentioned earlier when we discussed modeling the domain model classes, but here you can see how that mapping is performed with the PropertyAccessMode.Field configuration highlighted in the previous code.
Use shadow properties in EF Core, hidden at the infrastructure level
Shadow properties in EF Core are properties that do not exist in your entity class model. The values and states of these properties are maintained purely in the ChangeTracker class at the infrastructure level.
Implement the Query Specification pattern
As introduced earlier is the design section, the Query Specification pattern is a Domain-Driven Design pattern designed as the place where you can put the definition of a query with optional sorting and paging logic.
The Query Specification pattern defines a query in an object. For example, in order to encapsulate a paged query that searches for some products you can create a PagedProduct specification that takes the necessary input parameters (pageNumber, pageSize, filter, etc.). Then, within any Repository method (usually a List() overload) it would accept an IQuerySpecification and run the expected query based on that specification.
An example of a generic Specification interface is the following code, which is similar to code used in the eShopOnWeb reference application.
// GENERIC SPECIFICATION INTERFACE // https://github.com/dotnet-architecture/eShopOnWeb public interface ISpecification<T> { Expression<Func<T, bool>> Criteria { get; } List<Expression<Func<T, object>>> Includes { get; } List<string> IncludeStrings { get; } }
Then, the implementation of a generic specification base class is the following.
// GENERIC SPECIFICATION IMPLEMENTATION (BASE CLASS) // https://github.com/dotnet-architecture/eShopOnWeb public abstract class BaseSpecification<T> : ISpecification<T> { public BaseSpecification(Expression<Func<T, bool>> criteria) { Criteria = criteria; } public Expression<Func<T, bool>> Criteria { get; } public List<Expression<Func<T, object>>> Includes { get; } = new List<Expression<Func<T, object>>>(); public List<string> IncludeStrings { get; } = new List<string>(); protected virtual void AddInclude(Expression<Func<T, object>> includeExpression) { Includes.Add(includeExpression); } // string-based includes allow for including children of children // e.g. Basket.Items.Product protected virtual void AddInclude(string includeString) { IncludeStrings.Add(includeString); } }
The following specification loads a single basket entity given either the basket's ID or the ID of the buyer to whom the basket belongs. It will eagerly load the basket's Items collection.
// SAMPLE QUERY SPECIFICATION IMPLEMENTATION public class BasketWithItemsSpecification : BaseSpecification<Basket> { public BasketWithItemsSpecification(int basketId) : base(b => b.Id == basketId) { AddInclude(b => b.Items); } public BasketWithItemsSpecification(string buyerId) : base(b => b.BuyerId == buyerId) { AddInclude(b => b.Items); } }
And finally, you can see below how a generic EF Repository can use such a specification to filter and eager-load data related to a given entity type T.
// GENERIC EF REPOSITORY WITH SPECIFICATION // https://github.com/dotnet-architecture/eShopOnWeb public IEnumerable<T> List(ISpecification<T> spec) { // fetch a Queryable that includes all expression-based includes var queryableResultWithIncludes = spec.Includes .Aggregate(_dbContext.Set<T>().AsQueryable(), (current, include) => current.Include(include)); // modify the IQueryable to include any string-based include statements var secondaryResult = spec.IncludeStrings .Aggregate(queryableResultWithIncludes, (current, include) => current.Include(include)); // return the result of the query using the specification's criteria expression return secondaryResult .Where(spec.Criteria) .AsEnumerable(); }
In addition to encapsulating filtering logic, the specification can specify the shape of the data to be returned, including which properties to populate.
Although we don't recommend returning IQueryable from a repository, it's perfectly fine to use them within the repository to build up a set of results. You can see this approach used in the List method above, which uses intermediate IQueryable expressions to build up the query's list of includes before executing the query with the specification's criteria on the last line.
Learn how the specification pattern is applied in the eShopOnWeb sample.
Use NoSQL databases as a persistence infrastructure
When you use NoSQL databases for your infrastructure data tier, you typically do not use an ORM like Entity Framework Core. Instead you use the API provided by the NoSQL engine, such as Azure Cosmos DB, MonogoDB, Cassandra, RavenDB, CouchDB, or Azure Storage Tables.
However, when you use a NoSQL database, especially a document-oriented database like Azure Cosmos DB, CouchDB, or RavenDB, the way you design your model with DDD aggregates is partically similar to how you can do it in EF Core, in regards to the identification of aggregate roots, child entity classes, and value object classes. But, ultimately, the database selection will impact in your design.
When you use a document-oriented database, you implement an aggregate as a single document, serialized in JSON or another format. However, the use of the database is transparent from a domain model code point of view. When using a NoSQL database, you still are using entity classes and aggregate root classes, but with more flexibility than when using EF Core because the persistence is not relational.
The difference is in how you persist that model. If you implemented your domain model based on POCO entity classes, agnostic to the infrastructure persistence, it might look like you could move to a different persistec infrastructure, even from relational to NoSQL. However, that should not be your goal. There are always constraints and trade-offs in the different database technologies, so you will not be able to have the same model for relational or NoSQL databases. Changing persistence models is not a trivial task, because transactions and persistence operations will be very different.
For example, in a document-oriented database, it is okay for an aggregate root to have multiple child collection properties. In a relational database, querying multiple child collection properties is not easily optimized, because you get a UNION ALL SQL statement back from EF. Having the same domain model for relational databases or NoSQL databases is not simple, and you should not try to do it. You really have to design your model with an understanding of how the data is going to be used in each particular database.
A benefit when using NoSQL databases is that the entities are more denormalized, so you do not set a table mapping. Your domain model can be more flexible than when using a relational database.
When you design your domain model based on aggregates, moving to NoSQL and document-oriented databases might be even easier than using a relational database, because the aggregates you design are similar to serialized documents in a document-oriented database. Then you can include in those "bags" all the information you might need for that aggregate.
For instance, the following JSON code is a sample implementation of an order aggregate when using a document-oriented database. It is similar to the order aggregate we implemented in the eShopOnContainers sample, but without using EF Core underneath.
{
"id": "2024001",
"orderDate": "2/25/2024",
"buyerId": "1234567",
"address": [
{
"street": "100 One Microsoft Way",
"city": "Redmond",
"state": "WA",
"zip": "98052",
"country": "U.S."
}
],
"orderItems": [
{"id": 20240011, "productId": "123456", "productName": ".NET T-Shirt",
"unitPrice": 25, "units": 2, "discount": 0},
{"id": 20240012, "productId": "123457", "productName": ".NET Mug",
"unitPrice": 15, "units": 1, "discount": 0}
]
}
Introduction to Azure Cosmos DB and the native Cosmos DB API
Azure Cosmos DB is Microsoft's globally distributed database service for mission-critical applications. Azure Cosmos DB provides turn-key global distribution, elastic scaling of throughput and storage worldwide, single-digit millisecond latencies at the 99th percentile, five well-defined consistency levels, and guaranteed high availability, all backed by industry-leading SLAs. Azure Cosmos DB automatically indexes data without requiring you to deal with schema and index management. It is multi-model and supports document, key-value, graph, and columnar data models.

Implement .NET code targeting MongoDB and Azure Cosmos DB
Use Azure Cosmos DB from .NET containers
You can access Azure Cosmos DB databases from .NET code running in containers, like from any other .NET application. For instance, the Locations.API and Marketing.API microservices in eShopOnContainers are implemented so they can consume Azure Cosmos DB databases.However, there’s a limitation in Azure Cosmos DB from a Docker development environment point of view. Even though there’s an on-premises Azure Cosmos DB Emulator that can run in a local development machine, it only supports Windows. Linux and macOS aren't supported.
There's also the possibility to run this emulator on Docker, but just on Windows Containers, not with Linux Containers. That's an initial handicap for the development environment if your application is deployed as Linux containers, since, currently, you can't deploy Linux and Windows Containers on Docker for Windows at the same time. Either all containers being deployed have to be for Linux or for Windows.
The ideal and more straightforward deployment for a dev/test solution is to be able to deploy your database systems as containers along with your custom containers so your dev/test environments are always consistent.
Use MongoDB API for local dev/test Linux/Windows containers plus Azure Cosmos DB
Cosmos DB databases support MongoDB API for .NET as well as the native MongoDB wire protocol. This means that by using existing drivers, your application written for MongoDB can now communicate with Cosmos DB and use Cosmos DB databases instead of MongoDB databases, as shown in Figure 7-20.

Figure 7-20. Using MongoDB API and protocol to access Azure Cosmos DB
This is a very convenient approach for proof of concepts in Docker environments with Linux containers because the MongoDB Docker image is a multi-arch image that supports Docker Linux containers and Docker Windows containers.
As shown in the following image, by using the MongoDB API, eShopOnContainers supports MongoDB Linux and Windows containers for the local development environment but then, you can move to a scalable, PaaS cloud solution as Azure Cosmos DB by simply changing the MongoDB connection string to point to Azure Cosmos DB.

Figure 7-21. eShopOnContainers using MongoDB containers for dev-env or Azure Cosmos DB for production
The production Azure Cosmos DB would be running in Azure's cloud as a PaaS and scalable service.
Your custom .NET containers can run on a local development Docker host (that is using Docker for Windows in a Windows 10 machine) or be deployed into a production environment, like Kubernetes in Azure AKS or Azure Service Fabric. In this second environment, you would deploy only the .NET custom containers but not the MongoDB container since you'd be using Azure Cosmos DB in the cloud for handling the data in production.
A clear benefit of using the MongoDB API is that your solution could run in both database engines, MongoDB or Azure Cosmos DB, so migrations to different environments should be easy. However, sometimes it is worthwhile to use a native API (that is the native Cosmos DB API) in order to take full advantage of the capabilities of a specific database engine.
For further comparison between simply using MongoDB versus Cosmos DB in the cloud, see the Benefits of using Azure Cosmos DB in this page.
Analyze your approach for production applications: MongoDB API vs. Cosmos DB API
In eShopOnContainers, we're using MongoDB API because our priority was fundamentally to have a consistent dev/test environment using a NoSQL database that could also work with Azure Cosmos DB.
However, if you are planning to use MongoDB API to access Azure Cosmos DB in Azure for production applications, you should analyze the differences in capabilities and performance when using MongoDB API to access Azure Cosmos DB databases compared to using the native Azure Cosmos DB API. If it is similar you can use MongoDB API and you get the benefit of supporting two NoSQL database engines at the same time.
You could also use MongoDB clusters as the production database in Azure's cloud, too, with MongoDB Azure Service. But that is not a PaaS service provided by Microsoft. In this case, Azure is just hosting that solution coming from MongoDB.
Basically, this is just a disclaimer stating that you shouldn't always use MongoDB API against Azure Cosmos DB, as we did in eShopOnContainers because it was a convenient choice for Linux containers. The decision should be based on the specific needs and tests you need to do for your production application.
The code: Use MongoDB API in .NET applications
MongoDB API for .NET is based on NuGet packages that you need to add to your projects, like in the Locations.API project shown in the following figure.
Figure 7-22. MongoDB API NuGet packages references in a .NET project
Let's investigate the code in the following sections.
A Model used by MongoDB API
First, you need to define a model that will hold the data coming from the database in your application's memory space. Here's an example of the model used for Locations at eShopOnContainers.
using MongoDB.Bson; using MongoDB.Bson.Serialization.Attributes; using MongoDB.Driver.GeoJsonObjectModel; using System.Collections.Generic; public class Locations { [BsonId] [BsonRepresentation(BsonType.ObjectId)] public string Id { get; set; } public int LocationId { get; set; } public string Code { get; set; } [BsonRepresentation(BsonType.ObjectId)] public string Parent_Id { get; set; } public string Description { get; set; } public double Latitude { get; set; } public double Longitude { get; set; } public GeoJsonPoint<GeoJson2DGeographicCoordinates> Location { get; private set; } public GeoJsonPolygon<GeoJson2DGeographicCoordinates> Polygon { get; private set; } public void SetLocation(double lon, double lat) => SetPosition(lon, lat); public void SetArea(List<GeoJson2DGeographicCoordinates> coordinatesList) => SetPolygon(coordinatesList); private void SetPosition(double lon, double lat) { Latitude = lat; Longitude = lon; Location = new GeoJsonPoint<GeoJson2DGeographicCoordinates>( new GeoJson2DGeographicCoordinates(lon, lat)); } private void SetPolygon(List<GeoJson2DGeographicCoordinates> coordinatesList) { Polygon = new GeoJsonPolygon<GeoJson2DGeographicCoordinates>( new GeoJsonPolygonCoordinates<GeoJson2DGeographicCoordinates>( new GeoJsonLinearRingCoordinates<GeoJson2DGeographicCoordinates>( coordinatesList))); } }
You can see there are a few attributes and types coming from the MongoDB NuGet packages.
NoSQL databases are usually very well suited for working with non-relational hierarchical data. In this example, we are using MongoDB types especially made for geo-locations, like GeoJson2DGeographicCoordinates.
Retrieve the database and the collection
In eShopOnContainers, we have created a custom database context where we implement the code to retrieve the database and the MongoCollections, as in the following code.
public class LocationsContext { private readonly IMongoDatabase _database = null; public LocationsContext(IOptions<LocationSettings> settings) { var client = new MongoClient(settings.Value.ConnectionString); if (client != null) _database = client.GetDatabase(settings.Value.Database); } public IMongoCollection<Locations> Locations { get { return _database.GetCollection<Locations>("Locations"); } } }
Retrieve the data
In C# code, like Web API controllers or custom Repositories implementation, you can write similar code to the following when querying through the MongoDB API. Note that the _context object is an instance of the previous LocationsContext class.
public async Task<Locations> GetAsync(int locationId) { var filter = Builders<Locations>.Filter.Eq("LocationId", locationId); return await _context.Locations .Find(filter) .FirstOrDefaultAsync(); }
Use an env-var in the docker-compose.override.yml file for the MongoDB connection string
When creating a MongoClient object, it needs a fundamental parameter which is precisely the ConnectionString parameter pointing to the right database. In the case of eShopOnContainers, the connection string can point to a local MongoDB Docker container or to a "production" Azure Cosmos DB database. That connection string comes from the environment variables defined in the docker-compose.override.yml files used when deploying with docker-compose or Visual Studio, as in the following yml code.
# docker-compose.override.yml
version: '3.4'
services:
# Other services
locations-api:
environment:
# Other settings
- ConnectionString=${ESHOP_AZURE_COSMOSDB:-mongodb://nosqldata}
The ConnectionString environment variable is resolved this way: If the ESHOP_AZURE_COSMOSDB global variable is defined in the .env file with the Azure Cosmos DB connection string, it will use it to access the Azure Cosmos DB database in the cloud. If it’s not defined, it will take the mongodb://nosqldata value and use the development MongoDB container.
The following code shows the .env file with the Azure Cosmos DB connection string global environment variable, as implemented in eShopOnContainers:
# .env file, in eShopOnContainers root folder # Other Docker environment variables ESHOP_EXTERNAL_DNS_NAME_OR_IP=host.docker.internal ESHOP_PROD_EXTERNAL_DNS_NAME_OR_IP=<YourDockerHostIP> #ESHOP_AZURE_COSMOSDB=<YourAzureCosmosDBConnData> #Other environment variables for additional Azure infrastructure assets #ESHOP_AZURE_REDIS_BASKET_DB=<YourAzureRedisBasketInfo> #ESHOP_AZURE_STORAGE_CATALOG_URL=<YourAzureStorage_Catalog_BLOB_URL> #ESHOP_AZURE_SERVICE_BUS=<YourAzureServiceBusInfo>
Uncomment the ESHOP_AZURE_COSMOSDB line and update it with your Azure Cosmos DB connection string obtained from the Azure portal as explained in Connect a MongoDB application to Azure Cosmos DB.
If the ESHOP_AZURE_COSMOSDB global variable is empty, meaning it's commented out in the .env file, then the container uses a default MongoDB connection string. This connection string points to the local MongoDB container deployed in eShopOnContainers that is named nosqldata and was defined at the docker-compose file, as shown in the following .yml code:
# docker-compose.yml
version: '3.4'
services:
# ...Other services...
nosqldata:
image: mongo
Design the microservice application layer and Web API
Use SOLID principles and Dependency Injection
SOLID principles are critical techniques to be used in any modern and mission-critical application, such as developing a microservice with DDD patterns. SOLID is an acronym that groups five fundamental principles:
- Single Responsibility principle
- Open/closed principle
- Liskov substitution principle
- Interface Segregation principle
- Dependency Inversion principle
SOLID is more about how you design your application or microservice internal layers and
Dependency Injection (DI) is one way to implement the Dependency Inversion principle. It is a technique for achieving loose coupling between objects and their dependencies. Rather than directly instantiating collaborators, or using static references (that is, using new…), the objects that a class needs in order to perform its actions are provided to (or "injected into") the class. Most often, classes will declare their dependencies via their constructor, allowing them to follow the Explicit Dependencies principle. Dependency Injection is usually based on specific Inversion of Control (IoC) containers. ASP.NET Core provides a simple built-in IoC container, but you can also use your favorite IoC container, like Autofac or Ninject.
By following the SOLID principles, your classes will tend naturally to be samll, well-factored, and easily tested. But how can you know if too many dependencies are being injected into your classes? If you use DI through the constructor, it will be easy to detect that by just looking at the number of parameters for your constructor. If there are too many dependencies, this is generally a sign (a code smell) that your class is trying to do too much, and is probably violating the Single Responsibility principle.
It would take another guide to cover SOLID in detail. Therefore, this guide requires you to have only a minimum knowledge of these topics.
Implement the microservice application layer using the Web API
Use Dependency Injectin to inject infrastruction objects into your application layer
As mentioned previously, the application layer can be implemented as part of the artifact (assembly) you are building, such as within a Web API project or an MVC web app project. In the case of a microservice built with ASP.NET Core, the application layer will usually be your Web API library. If you want to separate what is coming from ASP.NET Core (its infrastructure plus your controllers) from your custom application layer code, you could also place your application layer in a separate class library, but that is optional.
For instance, the application layer code of the ordering microservice is directly implemented as part of the Ordering.API project (an ASP.NET Core Web API project), as shown in Figure 7-23.

Figure 7-23. The application layer in the Ordering.API ASP.NET Core Web API project
ASP.NET Core includes a simple built-in IoC container (represented by the IServiceProvider interface) that supports constructor injection by default, and ASP.NET makes certain services available through DI. ASP.NET Core uses the term service for any of the types you register that will be injected through DI. You configure the built-in container's services in your application's Program.cs file. Your dependencies are implemented in the services that a type needs and that you register in the IoC container.
Typically, you want to inject dependencies that implement infrastructure objects. A typical dependency to inject is a repository. But you could inject any other infrastructure dependency that you may have. For simpler implementations, you could directly inject your Unit of Work pattern object (the EF DbContext object), because the DBContext is also the implementation of your infrastructure persistence objects.
In the following example, you can see how .NET is injecting the required repository objects through the constructor. The class is a command handler, which will get covered in the next section.
public class CreateOrderCommandHandler : IRequestHandler<CreateOrderCommand, bool> { private readonly IOrderRepository _orderRepository; private readonly IIdentityService _identityService; private readonly IMediator _mediator; private readonly IOrderingIntegrationEventService _orderingIntegrationEventService; private readonly ILogger<CreateOrderCommandHandler> _logger; // Using DI to inject infrastructure persistence Repositories public CreateOrderCommandHandler(IMediator mediator, IOrderingIntegrationEventService orderingIntegrationEventService, IOrderRepository orderRepository, IIdentityService identityService, ILogger<CreateOrderCommandHandler> logger) { _orderRepository = orderRepository ?? throw new ArgumentNullException(nameof(orderRepository)); _identityService = identityService ?? throw new ArgumentNullException(nameof(identityService)); _mediator = mediator ?? throw new ArgumentNullException(nameof(mediator)); _orderingIntegrationEventService = orderingIntegrationEventService ?? throw new ArgumentNullException(nameof(orderingIntegrationEventService)); _logger = logger ?? throw new ArgumentNullException(nameof(logger)); } public async Task<bool> Handle(CreateOrderCommand message, CancellationToken cancellationToken) { // Add Integration event to clean the basket var orderStartedIntegrationEvent = new OrderStartedIntegrationEvent(message.UserId); await _orderingIntegrationEventService.AddAndSaveEventAsync(orderStartedIntegrationEvent); // Add/Update the Buyer AggregateRoot // DDD patterns comment: Add child entities and value-objects through the Order Aggregate-Root // methods and constructor so validations, invariants and business logic // make sure that consistency is preserved across the whole aggregate var address = new Address(message.Street, message.City, message.State, message.Country, message.ZipCode); var order = new Order(message.UserId, message.UserName, address, message.CardTypeId, message.CardNumber, message.CardSecurityNumber, message.CardHolderName, message.CardExpiration); foreach (var item in message.OrderItems) { order.AddOrderItem(item.ProductId, item.ProductName, item.UnitPrice, item.Discount, item.PictureUrl, item.Units); } _logger.LogInformation("----- Creating Order - Order: {@Order}", order); _orderRepository.Add(order); return await _orderRepository.UnitOfWork .SaveEntitiesAsync(cancellationToken); } }
The class uses the injected repositories to execute the transaction and persist the state changes. It does not matter whether that class is a command handler, an ASP.NET Core Web API controller method, or a DDD Application Service. It is ultimately a simple class that uses repositories, domain entities, and other application coordination in a fashion similar to a command handler. Dependency Injection works the same way for all the mentioned classes, as in the example using DI based on the constructor.
Register the dependency implementation types and interfaces or abstractions
Before you use the objects injected through constructors, you need to know where to register the interfaces and classes that produce the objects injected into your application classes through DI. (Like DI based on the constructor, as shown previously.)
Use the built-in IoC container provided by ASP.NET Core
When you use the built-in IoC container provided by ASP.NET Core, you register the types you want to inject in the Program.cs file, as in the following code:
// Register out-of-the-box framework services. builder.Services.AddDbContext<CatalogContext>(c => c.UseSqlServer(Configuration["ConnectionString"]), ServiceLifetime.Scoped); builder.Services.AddMvc(); // Register custom application dependencies. builder.Services.AddScoped<IMyCustomRepository, MyCustomSQLRepository>();
The most common pattern when registering types in an IoC container is to register a pair of types—an interface and its related implementation class. Then when you request an object from the IoC container through any constructor, you request an object of a certain type of interface. For instance, in the previous example, the last line states that when any of your constructors have a dependency on IMyCustomRepository (interface or abstraction), the IoC container will inject an instance of the MyCustomSQLServerRepository implementation class.
Use the built-in IoC container provided by ASP.NET Core
Use Autofac as an Ioc container
You can also use additional IoC containers and plug them into the ASP.NET Core pipeline, as in the ordering microservice in eShopOnContainers, which uses Autofac. When using Autofac you typically register the types via modules, which allow you to split the registration types between multiple files depending on where your types are, just as you could have the application types distributed across multiple class libraries.
For example, the following is the Autofac application module for the Ordering.API Web API project with the types you will want to inject.
public class ApplicationModule : Autofac.Module { public string QueriesConnectionString { get; } public ApplicationModule(string qconstr) { QueriesConnectionString = qconstr; } protected override void Load(ContainerBuilder builder) { builder.Register(c => new OrderQueries(QueriesConnectionString)) .As<IOrderQueries>() .InstancePerLifetimeScope(); builder.RegisterType<BuyerRepository>() .As<IBuyerRepository>() .InstancePerLifetimeScope(); builder.RegisterType<OrderRepository>() .As<IOrderRepository>() .InstancePerLifetimeScope(); builder.RegisterType<RequestManager>() .As<IRequestManager>() .InstancePerLifetimeScope(); } }
Autofac also has a feature to scan assemblies and register types by name conventions.
The registration process and concepts are very similar to the way you can register types with the built-in ASP.NET Core IoC container, but the syntax when using Autofac is a bit different.
In the example code, the abstraction IOrderRepository is registered along with the implementation class OrderRepository. This means that whenever a constructor is declaring a dependency through the IOrderRepository abstraction or interface, the IoC container will inject an instance of the OrderRepository class.
The instance scope type determines how an instance is shared between requests for the same service or dependency. When a request is made for a dependency, the IoC container can return the following:
- A single instance per lifetime scope (referred to in the ASP.NET Core IoC container as scoped).
- A new instance per dependency (referred to in the ASP.NET Core Ioc container as transient).
- A single instance shared across all objects using the IoC container (referred to in the ASP.NET Core IoC container as singleton).
Implement the Command and Command Handler patterns
In the DI-through-constructor example shown in the previous section, the IoC container was injecting repositories through a constructor in a class. But exactly where were they injected? In a simple Web API (for example, the catalog microservice in eShopOnContainers), you inject them at the MVC controllers' level, in a controller constructor, as part of the request pipeline of ASP.NET Core. However, in the initial code of this section (the CreateOrderCommandHandler class from the Ordering.API service in eShopOnContainers), the injection of dependencies is done through the constructor of a particular command handler. Let us explain what a command handler is and why you would want to use it.
The Command pattern is intrinsically related to the CQRS pattern that was introduced earlier in this guide. CQRS has two sides. The first area is queries, using simplified queries with the Dapper micro ORM, which was explained previously. The second area is commands, which are the starting point for transactions, and the input channel from outside the service.
As shown in Figure 7-24, the pattern is based on accepting commands from the client-side, processing them based on the domain model rules, and finally persisting the states with transactions.

Figure 7-24. High-level view of the commands or "transactional side" in a CQRS pattern
Figure 7-24 shows that the UI app sends a command through the API that gets to a CommandHandler, that depends on the Domain model and the Infrastructure, to update the database.
The command class
A command is a request for the system to perform an action that changes the state of the system. Commands are imperative, and should be processed just once.
Since commands are imperatives, they are typically named with a verb in the imperative mood (for example, "create" or "update"), and they might include the aggregate type, such as CreateOrderCommand. Unlike an event, a command is not a fact from the past; it is only a request, and thus may be refused.
Commands can originate from the UI as a result of a user initiating a request, or from a process manager when the process manager is directing an aggregate to perform an action.
An important characteristic of a command is that it should be processed just once by a single receiver. This is because a command is a single action or transaction you want to perform in the application. For example, the same order creation command should not be processed more than once. This is an important difference between commands and events. Events may be processed multiple times, because many systems or microservices might be interested in the event.
In addition, it is important that a command be processed only once in case the command is not idempotent. A command is idempotent if it can be executed multiple times without changing the result, either because of the nature of the command, or because of the way the system handles the command.
It is a good practice to make your commands and updates idempotent when it makes sense under your domain's business rules and invariants. For instance, to use the same example, if for any reason (retry logic, hacking, etc.) the same CreateOrder command reaches your system multiple times, you should be able to identify it and ensure that you do not create multiple orders. To do so, you need to attach some kind of identity in the operations and identify whether the command or update was already processed.
You send a command to a single receiver; you do not publish a command. Publishing is for events that state a fact—that something has happened and might be interesting for event receivers. In the case of events, the publisher has no concerns about which receivers get the event or what they do it. But domain or integration events are a different story already introduced in previous sections.
A command is implemented with a class that contains data fields or collections with all the information that is needed in order to execute that command. A command is a special kind of Data Transfer Object (DTO), one that is specifically used to request changes or transactions. The command itself is based on exactly the information that is needed for processing the command, and nothing more.
The following example shows the simplified CreateOrderCommand class. This is an immutable command that is used in the ordering microservice in eShopOnContainers.
// DDD and CQRS patterns comment: Note that it is recommended to implement immutable Commands // In this case, its immutability is achieved by having all the setters as private // plus only being able to update the data just once, when creating the object through its constructor. // References on Immutable Commands: // http://cqrs.nu/Faq // https://docs.spine3.org/motivation/immutability.html // http://blog.gauffin.org/2012/06/griffin-container-introducing-command-support/ // https://learn.microsoft.com/dotnet/csharp/programming-guide/classes-and-structs/how-to-implement-a-lightweight-class-with-auto-implemented-properties [DataContract] public class CreateOrderCommand : IRequest<bool> { [DataMember] private readonly List<OrderItemDTO> _orderItems; [DataMember] public string UserId { get; private set; } [DataMember] public string UserName { get; private set; } [DataMember] public string City { get; private set; } [DataMember] public string Street { get; private set; } [DataMember] public string State { get; private set; } [DataMember] public string Country { get; private set; } [DataMember] public string ZipCode { get; private set; } [DataMember] public string CardNumber { get; private set; } [DataMember] public string CardHolderName { get; private set; } [DataMember] public DateTime CardExpiration { get; private set; } [DataMember] public string CardSecurityNumber { get; private set; } [DataMember] public int CardTypeId { get; private set; } [DataMember] public IEnumerable<OrderItemDTO> OrderItems => _orderItems; public CreateOrderCommand() { _orderItems = new List<OrderItemDTO>(); } public CreateOrderCommand(List<BasketItem> basketItems, string userId, string userName, string city, string street, string state, string country, string zipcode, string cardNumber, string cardHolderName, DateTime cardExpiration, string cardSecurityNumber, int cardTypeId) : this() { _orderItems = basketItems.ToOrderItemsDTO().ToList(); UserId = userId; UserName = userName; City = city; Street = street; State = state; Country = country; ZipCode = zipcode; CardNumber = cardNumber; CardHolderName = cardHolderName; CardExpiration = cardExpiration; CardSecurityNumber = cardSecurityNumber; CardTypeId = cardTypeId; CardExpiration = cardExpiration; } public class OrderItemDTO { public int ProductId { get; set; } public string ProductName { get; set; } public decimal UnitPrice { get; set; } public decimal Discount { get; set; } public int Units { get; set; } public string PictureUrl { get; set; } } }
Basically, the command class contains all the data you need for performing a business transaction by using the domain model objects. Thus, commands are simply data structures that contain read-only data, and no behavior. The command's name indicates its purpose. In many languages like C#, commands are represented as classes, but they are not true classes in the real object-oriented sense.
As an additional characteristic, commands are immutable, because the expected usage is that they are processed directly by the domain model. They do not need to change during their projected lifetime. In a C# class, immutability can be achieved by not having any setters or other methods that change the internal state.
Keep in mind that if you intend or expect commands to go through a serializing/deserializing process, the properties must have a private setter, and the [DataMember] (or [JsonProperty]) attribute. Otherwise, the deserializer won't be able to reconstruct the object at the destination with the required values. You can also use truly read-only properties if the class has a constructor with parameters for all properties, with the usual camelCase naming convention, and annotate the constructor as [JsonConstructor]. However, this option requires more code.
For example, the command class for creating an order is probably similar in terms of data to the order you want to create, but you probably do not need the same attributes. For instance, CreateOrderCommand does not have an order ID, because the order has not been created yet.
Many command classes can be simple, requiring only a few fields about some state that needs to be changed. That would be the case if you are just changing the status of an order from "in process" to "paid" or "shipped" by using a command similar to the following:
[DataContract] public class UpdateOrderStatusCommand :IRequest<bool> { [DataMember] public string Status { get; private set; } [DataMember] public string OrderId { get; private set; } [DataMember] public string BuyerIdentityGuid { get; private set; } }
Some developers make their UI request objects separate from their command DTOs, but that is just a matter of preference. It is a tedious separation with not much additional value, and the objects are almost exactly the same shape. For instance, in eShopOnContainers, some commands come directly from the client-side.
The Command handler class
You should implement a specific command handler class for each command. That is how the pattern works, and it's where you'll use the command object, the domain objects, and the infrastructure repository objects. The command handler is in fact the heart of the application layer in terms of CQRS and DDD. However, all the domain logic should be contained in the domain classes—within the aggregate roots (root entities), child entities, or domain services, but not within the command handler, which is a class from the application layer.
The command handler class offers a strong stepping stone in the way to achieve the Single Responsibility Principle (SRP) mentioned in a previous section.
A command handler receives a command and obtains a result from the aggregate that is used. The result should be either successful execution of the command, or an exception. In the case of an exception, the system state should be unchanged.
Typically, a command handler deals with a single aggregate driven by its aggregate root (root entity). If multiple aggregates should be impacted by the reception of a single command, you could use domain events to propagate states or actions across multiple aggregates.
The important point here is that when a command is being processed, all the domain logic should be inside the domain model (the aggregates), fully encapsulated and ready for unit testing. The command handler just acts as a way to get the domain model from the database, and as the final step, to tell the infrastructure layer (repositories) to persist the changes when the model is changed. The advantage of this approach is that you can refactor the domain logic in an isolated, fully encapsulated, rich, behavioral domain model without changing code in the application or infrastructure layers, which are the plumbing level (command handlers, Web API, repositories, etc.).
When command handlers get complex, with too much logic, that can be a code smell. Review them, and if you find domain logic, refactor the code to move that domain behavior to the methods of the domain objects (the aggregate root and child entity).
As an example of a command handler class, the following code shows the same CreateOrderCommandHandler class that you saw at the beginning of this chapter. In this case, it also highlights the Handle method and the operations with the domain model objects/aggregates.
public class CreateOrderCommandHandler : IRequestHandler<CreateOrderCommand, bool> { private readonly IOrderRepository _orderRepository; private readonly IIdentityService _identityService; private readonly IMediator _mediator; private readonly IOrderingIntegrationEventService _orderingIntegrationEventService; private readonly ILogger<CreateOrderCommandHandler> _logger; // Using DI to inject infrastructure persistence Repositories public CreateOrderCommandHandler(IMediator mediator, IOrderingIntegrationEventService orderingIntegrationEventService, IOrderRepository orderRepository, IIdentityService identityService, ILogger<CreateOrderCommandHandler> logger) { _orderRepository = orderRepository ?? throw new ArgumentNullException(nameof(orderRepository)); _identityService = identityService ?? throw new ArgumentNullException(nameof(identityService)); _mediator = mediator ?? throw new ArgumentNullException(nameof(mediator)); _orderingIntegrationEventService = orderingIntegrationEventService ?? throw new ArgumentNullException(nameof(orderingIntegrationEventService)); _logger = logger ?? throw new ArgumentNullException(nameof(logger)); } public async Task<bool> Handle(CreateOrderCommand message, CancellationToken cancellationToken) { // Add Integration event to clean the basket var orderStartedIntegrationEvent = new OrderStartedIntegrationEvent(message.UserId); await _orderingIntegrationEventService.AddAndSaveEventAsync(orderStartedIntegrationEvent); // Add/Update the Buyer AggregateRoot // DDD patterns comment: Add child entities and value-objects through the Order Aggregate-Root // methods and constructor so validations, invariants and business logic // make sure that consistency is preserved across the whole aggregate var address = new Address(message.Street, message.City, message.State, message.Country, message.ZipCode); var order = new Order(message.UserId, message.UserName, address, message.CardTypeId, message.CardNumber, message.CardSecurityNumber, message.CardHolderName, message.CardExpiration); foreach (var item in message.OrderItems) { order.AddOrderItem(item.ProductId, item.ProductName, item.UnitPrice, item.Discount, item.PictureUrl, item.Units); } _logger.LogInformation("----- Creating Order - Order: {@Order}", order); _orderRepository.Add(order); return await _orderRepository.UnitOfWork .SaveEntitiesAsync(cancellationToken); } }
These are additional steps a command handler should take:
- Use the command's data to operate with the aggregate root's methods and behavior.
- Internally within the domain objects, raise domain events while the transaction is executed, but that is transparent from a command handler point of view.
- If the aggregate's operation result is successful and after the transaction is finished, raise integration events.(These might also be raised by infrastructure classes like repositories.)
The Command process pipeline: how to trigger a command handler
The next question is how to invoke a command handler. You could manually call it from each related ASP.NET Core controller. However, that approach would be too coupled and is not ideal.
The other two main options, which are the recommended options, are:
- Through an in-memory Mediator pattern artifact.
- With an asynchronous message queue, in between controllers and handlers.
Use the Mediator pattern (in-memory) in the command pipeline
As shown in Figure 7-25, in a CQRS approach you use an intelligent mediator, similar to an in-memory bus, which is smart enough to redirect to the right command handler based on the type of the command or DTO being received. The single black arrows between components represent the dependencies between objects (in many cases, injected through DI) with their related interactions.

Figure 7-25. Using the Mediator pattern in process in a single CQRS microservice
The above diagram shows a zoom-in from image 7-24: the ASP.NET Core controller sends the command to MediatR's command pipeline, so they get to the appropriate handler.
The reason that using the Mediator pattern makes sense is that in enterprise applications, the processing requests can get complicated. You want to be able to add an open number of cross-cutting concerns like logging, validations, audit, and security. In these cases, you can rely on a mediator pipeline (see Mediator pattern) to provide a means for these extra behaviors or cross-cutting concerns.
A mediator is an object that encapsulates the "how" of this process: it coordinates execution based on state, the way a command handler is invoked, or the payload you provide to the handler. With a mediator component, you can apply cross-cutting concerns in a centralized and transparent way by applying decorators (or pipeline behaviors since MediatR 3). For more information, see the Decorator pattern.
Decorators and behaviors are similar to Aspect Oriented Programming (AOP), only applied to a specific process pipeline managed by the mediator component. Aspects in AOP that implement cross-cutting concerns are applied based on aspect weavers injected at compilation time or based on object call interception. Both typical AOP approaches are sometimes said to work "like magic," because it is not easy to see how AOP does its work. When dealing with serious issues or bugs, AOP can be difficult to debug. On the other hand, these decorators/behaviors are explicit and applied only in the context of the mediator, so debugging is much more predictable and easy.
For example, in the eShopOnContainers ordering microservice, has an implementation of two sample behaviors, a LogBehavior class and a ValidatorBehavior class. The implementation of the behaviors is explained in the next section by showing how eShopOnContainers uses MediatR behaviors.
Implement the commad process pipeline with a mediator pattern (MediatR)
As a sample implementation, this guide proposes using the in-process pipeline based on the Mediator pattern to drive command ingestion and route commands, in memory, to the right command handlers. The guide also proposes applying behaviors in order to separate cross-cutting concerns.
For implementation in .NET, there are multiple open-source libraries available that implement the Mediator pattern. The library used in this guide is the MediatR open-source library (created by Jimmy Bogard), but you could use another approach. MediatR is a small and simple library that allows you to process in-memory messages like a command, while applying decorators or behaviors.
Using the Mediator pattern helps you to reduce coupling and to isolate the concerns of the requested work, while automatically connecting to the handler that performs that work—in this case, to command handlers.
Another good reason to use the Mediator pattern was explained by Jimmy Bogard when reviewing this guide:
I think it might be worth mentioning testing here - it provides a nice consistent window into the behavior of your system. Request-in, response-out. We've found that aspect quite valuable in building consistently behaving test.
First, let's look at a sample WebAPI controller where you actually would use the mediator object. If you weren't using the mediator object, you'd need to inject all the dependencies for that controller, things like a logger object and others. Therefore, the constructor would be complicated. On the other hand, if you use the mediator object, the constructor of your controller can be a lot simpler, with just a few dependencies instead of many dependencies if you had one per cross-cutting operation, as in the following example:
public class MyMicroserviceController : Controller { public MyMicroserviceController(IMediator mediator, IMyMicroserviceQueries microserviceQueries) { // ... } }
You can see that the mediator provides a clean and lean Web API controller constructor. In addition, within the controller methods, the code to send a command to the mediator object is almost one line:
[Route("new")] [HttpPost] public async Task<IActionResult> ExecuteBusinessOperation([FromBody]RunOpCommand runOperationCommand) { var commandResult = await _mediator.SendAsync(runOperationCommand); return commandResult ? (IActionResult)Ok() : (IActionResult)BadRequest(); }
Implement idempotent Commands
In eShopOnContainers, a more advanced example than the above is submitting a CreateOrderCommand object from the Ordering microservice. But since the Ordering business process is a bit more complex and, in our case, it actually starts in the Basket microservice, this action of submitting the CreateOrderCommand object is performed from an integration-event handler named UserCheckoutAcceptedIntegrationEventHandler instead of a simple WebAPI controller called from the client App as in the previous simpler example.
Nevertheless, the action of submitting the Command to MediatR is pretty similar, as shown in the following code.
var createOrderCommand = new CreateOrderCommand(eventMsg.Basket.Items, eventMsg.UserId, eventMsg.City, eventMsg.Street, eventMsg.State, eventMsg.Country, eventMsg.ZipCode, eventMsg.CardNumber, eventMsg.CardHolderName, eventMsg.CardExpiration, eventMsg.CardSecurityNumber, eventMsg.CardTypeId); var requestCreateOrder = new IdentifiedCommand<CreateOrderCommand,bool>(createOrderCommand, eventMsg.RequestId); result = await _mediator.Send(requestCreateOrder);
However, this case is also slightly more advanced because we're also implementing idempotent commands. The CreateOrderCommand process should be idempotent, so if the same message comes duplicated through the network, because of any reason, like retries, the same business order will be processed just once.
This is implemented by wrapping the business command (in this case CreateOrderCommand) and embedding it into a generic IdentifiedCommand, which is tracked by an ID of every message coming through the network that has to be idempotent.
In the code below, you can see that the IdentifiedCommand is nothing more than a DTO with and ID plus the wrapped business command object.
public class IdentifiedCommand<T, R> : IRequest<R> where T : IRequest<R> { public T Command { get; } public Guid Id { get; } public IdentifiedCommand(T command, Guid id) { Command = command; Id = id; } }
Then the CommandHandler for the IdentifiedCommand named IdentifiedCommandHandler.cs will basically check if the ID coming as part of the message already exists in a table. If it already exists, that command won't be processed again, so it behaves as an idempotent command. That infrastructure code is performed by the _requestManager.ExistAsync method call below.
// IdentifiedCommandHandler.cs public class IdentifiedCommandHandler<T, R> : IRequestHandler<IdentifiedCommand<T, R>, R> where T : IRequest<R> { private readonly IMediator _mediator; private readonly IRequestManager _requestManager; private readonly ILogger<IdentifiedCommandHandler<T, R>> _logger; public IdentifiedCommandHandler( IMediator mediator, IRequestManager requestManager, ILogger<IdentifiedCommandHandler<T, R>> logger) { _mediator = mediator; _requestManager = requestManager; _logger = logger ?? throw new System.ArgumentNullException(nameof(logger)); } /// <summary> /// Creates the result value to return if a previous request was found /// </summary> /// <returns></returns> protected virtual R CreateResultForDuplicateRequest() { return default(R); } /// <summary> /// This method handles the command. It just ensures that no other request exists with the same ID, and if this is the case /// just enqueues the original inner command. /// </summary> /// <param name="message">IdentifiedCommand which contains both original command & request ID</param> /// <returns>Return value of inner command or default value if request same ID was found</returns> public async Task<R> Handle(IdentifiedCommand<T, R> message, CancellationToken cancellationToken) { var alreadyExists = await _requestManager.ExistAsync(message.Id); if (alreadyExists) { return CreateResultForDuplicateRequest(); } else { await _requestManager.CreateRequestForCommandAsync<T>(message.Id); try { var command = message.Command; var commandName = command.GetGenericTypeName(); var idProperty = string.Empty; var commandId = string.Empty; switch (command) { case CreateOrderCommand createOrderCommand: idProperty = nameof(createOrderCommand.UserId); commandId = createOrderCommand.UserId; break; case CancelOrderCommand cancelOrderCommand: idProperty = nameof(cancelOrderCommand.OrderNumber); commandId = $"{cancelOrderCommand.OrderNumber}"; break; case ShipOrderCommand shipOrderCommand: idProperty = nameof(shipOrderCommand.OrderNumber); commandId = $"{shipOrderCommand.OrderNumber}"; break; default: idProperty = "Id?"; commandId = "n/a"; break; } _logger.LogInformation( "----- Sending command: {CommandName} - {IdProperty}: {CommandId} ({@Command})", commandName, idProperty, commandId, command); // Send the embedded business command to mediator so it runs its related CommandHandler var result = await _mediator.Send(command, cancellationToken); _logger.LogInformation( "----- Command result: {@Result} - {CommandName} - {IdProperty}: {CommandId} ({@Command})", result, commandName, idProperty, commandId, command); return result; } catch { return default(R); } } } }
Since the IdentifiedCommand acts like a business command's envelope, when the business command needs to be processed because it is not a repeated ID, then it takes that inner business command and resubmits it to Mediator, as in the last part of the code shown above when running _mediator.Send(message.Command), from the IdentifiedCommandHandler.cs.
When doing that, it will link and run the business command handler, in this case, the CreateOrderCommandHandler, which is running transactions against the Ordering database, as shown in the following code.
// CreateOrderCommandHandler.cs public class CreateOrderCommandHandler : IRequestHandler<CreateOrderCommand, bool> { private readonly IOrderRepository _orderRepository; private readonly IIdentityService _identityService; private readonly IMediator _mediator; private readonly IOrderingIntegrationEventService _orderingIntegrationEventService; private readonly ILogger<CreateOrderCommandHandler> _logger; // Using DI to inject infrastructure persistence Repositories public CreateOrderCommandHandler(IMediator mediator, IOrderingIntegrationEventService orderingIntegrationEventService, IOrderRepository orderRepository, IIdentityService identityService, ILogger<CreateOrderCommandHandler> logger) { _orderRepository = orderRepository ?? throw new ArgumentNullException(nameof(orderRepository)); _identityService = identityService ?? throw new ArgumentNullException(nameof(identityService)); _mediator = mediator ?? throw new ArgumentNullException(nameof(mediator)); _orderingIntegrationEventService = orderingIntegrationEventService ?? throw new ArgumentNullException(nameof(orderingIntegrationEventService)); _logger = logger ?? throw new ArgumentNullException(nameof(logger)); } public async Task<bool> Handle(CreateOrderCommand message, CancellationToken cancellationToken) { // Add Integration event to clean the basket var orderStartedIntegrationEvent = new OrderStartedIntegrationEvent(message.UserId); await _orderingIntegrationEventService.AddAndSaveEventAsync(orderStartedIntegrationEvent); // Add/Update the Buyer AggregateRoot // DDD patterns comment: Add child entities and value-objects through the Order Aggregate-Root // methods and constructor so validations, invariants and business logic // make sure that consistency is preserved across the whole aggregate var address = new Address(message.Street, message.City, message.State, message.Country, message.ZipCode); var order = new Order(message.UserId, message.UserName, address, message.CardTypeId, message.CardNumber, message.CardSecurityNumber, message.CardHolderName, message.CardExpiration); foreach (var item in message.OrderItems) { order.AddOrderItem(item.ProductId, item.ProductName, item.UnitPrice, item.Discount, item.PictureUrl, item.Units); } _logger.LogInformation("----- Creating Order - Order: {@Order}", order); _orderRepository.Add(order); return await _orderRepository.UnitOfWork .SaveEntitiesAsync(cancellationToken); } }
Register the types used by MediatR
In order for MediatR to be aware of your command handler classes, you need to register the mediator classes and the command handler classes in your IoC container. By default, MediatR uses Autofac as the IoC container, but you can also use the built-in ASP.NET Core IoC container or any other container supported by MediatR.
The following code shows how to register Mediator's types and commands when using Autofac modules.
public class MediatorModule : Autofac.Module { protected override void Load(ContainerBuilder builder) { builder.RegisterAssemblyTypes(typeof(IMediator).GetTypeInfo().Assembly) .AsImplementedInterfaces(); // Register all the Command classes (they implement IRequestHandler) // in assembly holding the Commands builder.RegisterAssemblyTypes(typeof(CreateOrderCommand).GetTypeInfo().Assembly) .AsClosedTypesOf(typeof(IRequestHandler<,>)); // Other types registration //... } }
This is where "the magic happens" with MediatR.
As each command handler implements the generic IRequestHandler<T> interface, when you register the assemblies using RegisteredAssemblyTypes method all the types marked as IRequestHandler also gets registered with their Commands. For example:
public class CreateOrderCommandHandler : IRequestHandler<CreateOrderCommand, bool> {
That is the code that correlates commands with command handlers. The handler is just a simple class, but it inherits from RequestHandler<T>, where T is the command type, and MediatR makes sure it is invoked with the correct payload (the command).
Apply cross-cutting concerns when processing commands with the Behaviors in MediatR
There is one more thing: being able to apply cross-cutting concerns to the mediator pipeline. You can also see at the end of the Autofac registration module code how it registers a behavior type, specifically, a custom LoggingBehavior class and a ValidatorBehavior class. But you could add other custom behaviors, too.
public class MediatorModule : Autofac.Module { protected override void Load(ContainerBuilder builder) { builder.RegisterAssemblyTypes(typeof(IMediator).GetTypeInfo().Assembly) .AsImplementedInterfaces(); // Register all the Command classes (they implement IRequestHandler) // in assembly holding the Commands builder.RegisterAssemblyTypes( typeof(CreateOrderCommand).GetTypeInfo().Assembly). AsClosedTypesOf(typeof(IRequestHandler<,>)); // Other types registration //... builder.RegisterGeneric(typeof(LoggingBehavior<,>)). As(typeof(IPipelineBehavior<,>)); builder.RegisterGeneric(typeof(ValidatorBehavior<,>)). As(typeof(IPipelineBehavior<,>)); } }
That LoggingBehavior class can be implemented as the following code, which logs information about the command handler being executed and whether it was successful or not.
public class LoggingBehavior<TRequest, TResponse> : IPipelineBehavior<TRequest, TResponse> { private readonly ILogger<LoggingBehavior<TRequest, TResponse>> _logger; public LoggingBehavior(ILogger<LoggingBehavior<TRequest, TResponse>> logger) => _logger = logger; public async Task<TResponse> Handle(TRequest request, RequestHandlerDelegate<TResponse> next) { _logger.LogInformation($"Handling {typeof(TRequest).Name}"); var response = await next(); _logger.LogInformation($"Handled {typeof(TResponse).Name}"); return response; } }
Just by implementing this behavior class and by registering it in the pipeline (in the MediatorModule above), all the commands processed through MediatR will be logging information about the execution.
The eShopOnContainers ordering microservice also applies a second behavior for basic validations, the ValidatorBehavior class that relies on the FluentValidation library, as shown in the following code:
public class ValidatorBehavior<TRequest, TResponse> : IPipelineBehavior<TRequest, TResponse> { private readonly IValidator<TRequest>[] _validators; public ValidatorBehavior(IValidator<TRequest>[] validators) => _validators = validators; public async Task<TResponse> Handle(TRequest request, RequestHandlerDelegate<TResponse> next) { var failures = _validators .Select(v => v.Validate(request)) .SelectMany(result => result.Errors) .Where(error => error != null) .ToList(); if (failures.Any()) { throw new OrderingDomainException( $"Command Validation Errors for type {typeof(TRequest).Name}", new ValidationException("Validation exception", failures)); } var response = await next(); return response; } }
Here the behavior is raising an exception if validation fails, but you could also return a result object, containing the command result if it succeeded or the validation messages in case it didn't. This would probably make it easier to display validation results to the user.
Then, based on the FluentValidation library, you would create validation for the data passed with CreateOrderCommand, as in the following code:
public class CreateOrderCommandValidator : AbstractValidator<CreateOrderCommand> { public CreateOrderCommandValidator() { RuleFor(command => command.City).NotEmpty(); RuleFor(command => command.Street).NotEmpty(); RuleFor(command => command.State).NotEmpty(); RuleFor(command => command.Country).NotEmpty(); RuleFor(command => command.ZipCode).NotEmpty(); RuleFor(command => command.CardNumber).NotEmpty().Length(12, 19); RuleFor(command => command.CardHolderName).NotEmpty(); RuleFor(command => command.CardExpiration).NotEmpty().Must(BeValidExpirationDate).WithMessage("Please specify a valid card expiration date"); RuleFor(command => command.CardSecurityNumber).NotEmpty().Length(3); RuleFor(command => command.CardTypeId).NotEmpty(); RuleFor(command => command.OrderItems).Must(ContainOrderItems).WithMessage("No order items found"); } private bool BeValidExpirationDate(DateTime dateTime) { return dateTime >= DateTime.UtcNow; } private bool ContainOrderItems(IEnumerable<OrderItemDTO> orderItems) { return orderItems.Any(); } }
You could create additional validations. This is a very clean and elegant way to implement your command validations.
In a similar way, you could implement other behaviors for additional aspects or cross-cutting concerns that you want to apply to commands when handling them.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号