
2020暑假第7周
这周学习了HDFS的API系列操作。
首先,在Windows系统需要配置hadoop运行环境。
然后
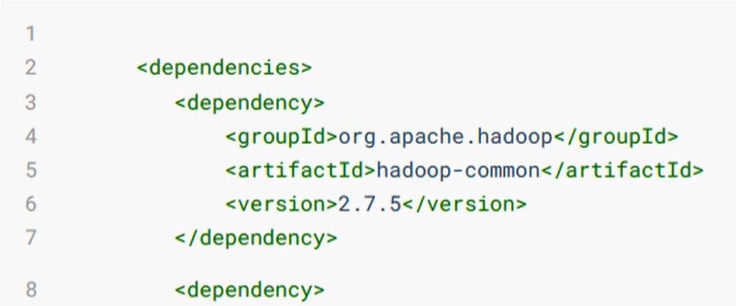
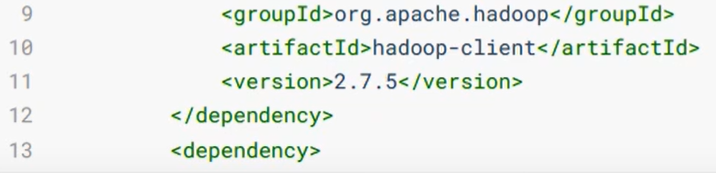
然后,导入maven依赖。
然后,使用url方式访问数据。 
然后,使用文件系统方式访问数据。
在Java中操作HDFS,主要涉及Configuration类和FileSystem类。
用方法:FileSystem fs = FileSystem.get(conf)来获取子类对象。
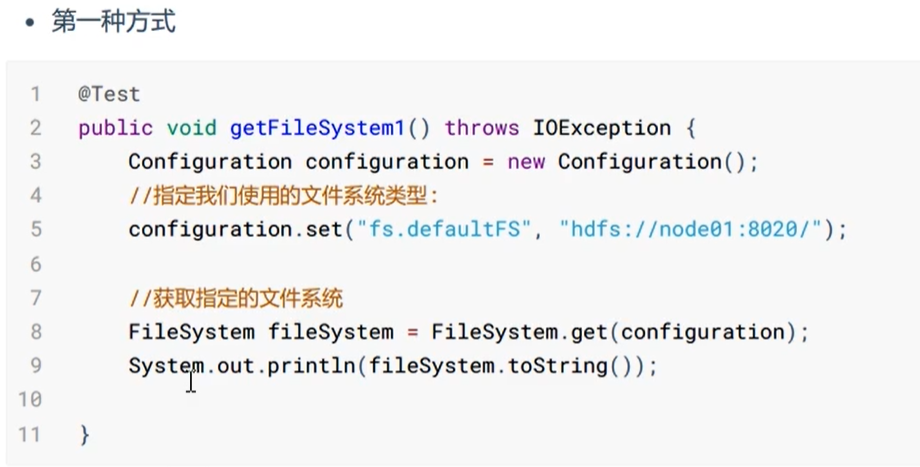
获取FileSystem的几种方式:
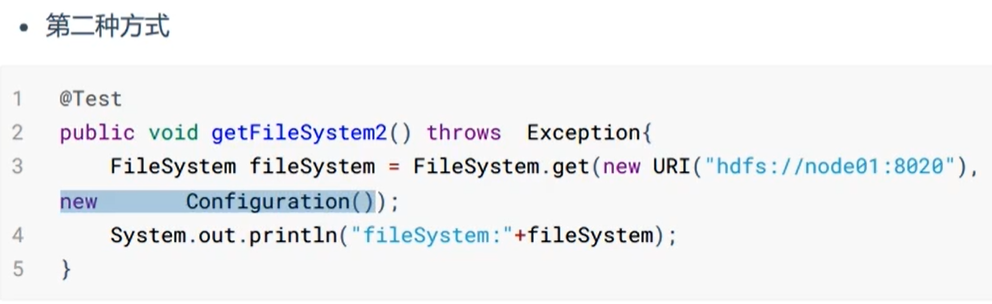
* 第三种方式


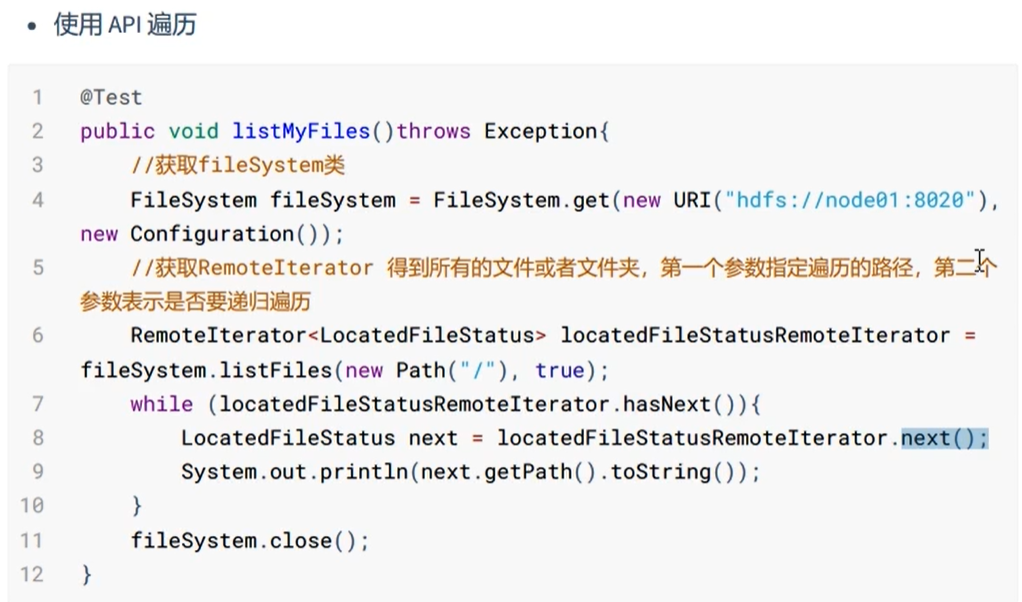
遍历HDFS中所有文件。
HDFS上创建文件夹。

下载文件。

HDFS文件上传。

HDFS的权限访问控制,这一部分没有学太懂。
小文件合并。
由于Hadoop擅长存储大文件,因为大文件的元数据信息比较少,如果Hadoop集群当中有大量小文件,那么每个小文件都需要维护一份元数据信息,会大大增加集群管理元数据的内存压力,所以在HDFS的Shell命令模式下,可以通过命令:cd/export/servers hdfs dfs -getmerge/config/*.xml ./hello.xml 将很多hdfs文件合并成一个大文件下载到本地。
另外,就是学习了HDFS的高可用机制。
在Hadoop中,NameNode所处位置非常重要,整个HDFS文件系统的元数据信息都由NameNode来管理,NameNode的可用性直接决定了Hadoop的可用性,一旦NameNode进程不能工作了,就会影响整个集群的正常使用。
在典型的HA集群中,两台独立的机器被配置为NameNode。在工作集群中,NameNode机器中的一个处于Active状态,另一个处于Standby状态。Active NameNode负责群集中的所有客户端操作,而Stanley充当从服务器。在需要的时候,Stanley机器保持足够的状态以提供快速故障切换。
组件有:ZKFailoverController、HealthMonitor、ActiveStandbyElector、DataNode。
Hadoop的联邦机制。
单个NameNode的架构使得HDFS在集群扩展性和性能上都有潜在问题,NameNode成为了性能的瓶颈。Federation是联邦、联盟的意思,是NameNode的Federation,也就是说会有多个NameNode,也就会有多个namespace,即命名空间。
解决了NameNode的横向扩展问题,但不能解决NameNode的单点故障问题。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律