spark 简介
spark 是基于内存计算的 大数据分布式计算框架,spark基于内存计算,提高了在大数据环境下处理的实时性,同时保证了高容错性和高可伸缩性,允许用户将spark部署在大量廉价的硬件上,形成集群。
1. 分布式计算
2. 内存计算
3. 容错
4. 多计算范式
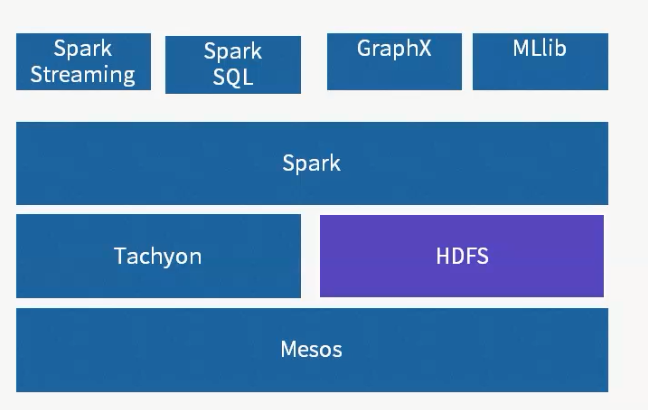
1 Messos 作为资源管理框架。相当于yarn,进行资源管理以及调度。 2 spark生态系统,不提供存储层,可以调用外部存储,例如HDFS 3 Tachyon 是 分布式内存文件系统,能够缓存数据,并提供数据快速读写。 4 spark 是核心计算引擎,能够将任务并行化,在大规模集群中进行数据计算。 5 spark streaming是 流式计算引擎,能够将输入数据切分成小的批次,对每个批次采用spark的计算范式,进行计算。 6 spark sql 是 sql on hadoop 系统,能够提供交互式查询,以及报表查询,并且可以通过jdbc 调用 7 graphx 是 图计算引擎,能够完成大规模图运算。 8 mlib 是 机器学习库,提供聚类,分类,以及推荐的基本学习算法。
spark优势
1 计算范式支持 打造多栈计算范式的高效数据流水线 2 处理速度,轻量级快速处理 3 易用性, 分布式RDD抽象,spark支持多语言
4 兼容性,与HDFS等存储层兼容
spark的架构
1.spark架构组件简介
spark集群中master负责集群整体资源管理和调度,worker负责带个节点的资源管理, mater ---> slave 模型, Driver程序是应用逻辑执行的起点,而多个Executor用来对数据进行并行处理
spark的构成:
ClusterManager: 在standalone模式中即为: master: 主节点,控制整个集群,监控worker.在yarn模式中为资源管理器.
Worker: 从节点,负责控制计算节点,启动Executor或Driver, 在yarn模式中为nodemanager,负责计算节点的控制。
Driver: 运行application的main()函数并且创建sparkcontext
Executor: 执行器,是为某application运行在worker node上的一个进程,启动进程池运行任务上,每个application拥有独立的一组executors.
sparkcontext: 整个应用的上下文,控制应用的生命周期
RDD: spark的基本计算单元, 一组RDD形成执行的有向无环图RDD Graph。
2.spark 架构图
3. spark集群执行机制
spark的工作机制
spark的调度原理
spark 在 yarn集群搭建详细情况
spark 官方提供4种 集群部署方案
Spark Mesos模式:官方推荐模式,通用集群管理,有两种调度模式:粗粒度模式(Coarse-grained Mode)与细粒度模式(Fine-grained Mode);
Spark YARN模式:Hadoop YARN资源管理模式;
Standalone模式: 简单模式或称独立模式,可以单独部署到一个集群中,无依赖任何其他资源管理系统。不使用其他调度工具时会存在单点故障,使用Zookeeper等可以解决;
Local模式:本地模式,可以启动本地一个线程来运行job,可以启动N个线程或者使用系统所有核运行job;
第一 Stanalone模式集群安装,spark standalone模式的集群由master 与worker节点组成,程序通过与master节点交互相互申请资源,worker节点启动executor运行。
spark官方要求 scala版本为2.10 以下, 安装下载安装 [root@spark_master ~]# https://codeload.github.com/scala/scala/tar.gz/v2.12.1 [root@spark_master ~]# tar -zxvf scala-2.12.1.tar.gz
查看主机名
[root@spark_master ~]# cat /etc/hosts
192.168.20.213 spark_salve1
192.168.20.214 spark_salve2
下载spark [root@spark_manager ~]# wget http://d3kbcqa49mib13.cloudfront.net/spark-2.0.2-bin-hadoop2.7.tgz
[root@spark_manager conf]# tar -zxvf spark-2.0.2-bin-hadoop2.7.tgz -C /data/spark
[root@spark_manager conf]#cd /data/spark/conf
[root@spark_manager conf]#
spark2.0.2 standalone 集群模式安装
[root@spark_manager conf]# mv slaves.template slaves
[root@spark_manager conf]# mv spark-env.sh.template spark-env.sh
[root@spark_manager conf]# cat slaves
spark_manager
spark_salve1
spark_salve2
[root@spark_manager conf]#mv spark-env.sh.template spark-env.sh
启动集群:
1.启动manager
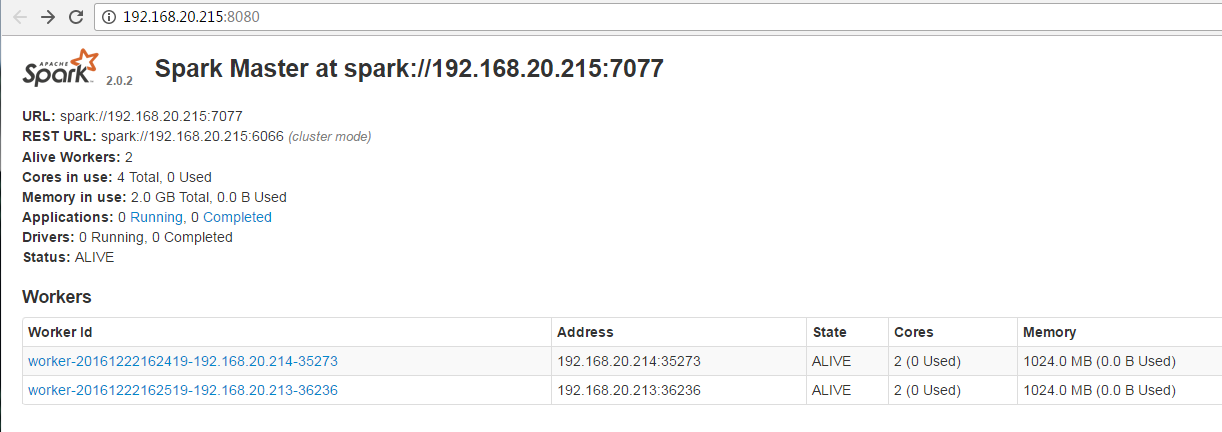
[root@spark_manager sbin]# ./start-master.sh
2. 启动slave(workers)
[root@spark_slave1 sbin]# ./start-slave.sh 192.168.20.215:7077
[root@spark_slave2 sbin]# ./start-slave.sh 192.168.20.215:7077
![]()
#######################################################################################################################################
spark2.0.2 standalone HA 集群模式安装
多个slave的情况下自动具备了worker的HA,因为spark会将失败的任务调度到其他worker上执行。但是,master还是有单点的,如果master故障了,那么用户就无法提交新的作业 了。注意,已经提交到worker的作业不受影响。
spark官方给出了2种解决方法,一个是使用zk做分布式协调,zk选主;另一个是使用基于LOCAL FILE SYSTEM恢复的单节点方案。第二种其实只有1个master实例,当master故障后服务不可用,必须重启master进程,一般在生成系统上是不可接受的,所以我采用的是第一种方式。
一配置 zookeeper:略过
2. 主机名信息:
192.168.20.215 spark_manager
192.168.20.213 spark_salve1
192.168.20.214 spark_salve2
192.168.20.211 standby_master
192.168.20.37 zookeeper1
192.168.20.38 zookeeper2
192.168.20.39 zookeepe3
第一台spark_manager
[root@spark_manager sbin]# ssh-keygen -t rsa
[root@spark_manager sbin]# ssh-copy-id -i /root/.ssh/id_rsa.pub root@192.168.20.211
[root@spark_manager sbin]# ssh-copy-id -i /root/.ssh/id_rsa.pub root@192.168.20.213
[root@spark_manager sbin]# ssh-copy-id -i /root/.ssh/id_rsa.pub root@192.168.20.214
[root@spark_manager sbin]# ssh-copy-id -i /root/.ssh/id_rsa.pub root@192.168.20.215
第二台spark_manager
[root@standby_master ~]# ssh-keygen -t rsa
[root@standby_manager sbin]# ssh-copy-id -i /root/.ssh/id_rsa.pub root@192.168.20.215
[root@standby_manager sbin]# ssh-copy-id -i /root/.ssh/id_rsa.pub root@192.168.20.213
[root@standby_manager sbin]# ssh-copy-id -i /root/.ssh/id_rsa.pub root@192.168.20.214
[root@standby_manager sbin]# ssh-copy-id -i /root/.ssh/id_rsa.pub root@192.168.20.211
[root@spark_manager conf]# mv slaves.template slaves
[root@spark_manager conf]# mv spark-env.sh.template spark-env.sh
[root@spark_manager conf]# cat slaves
spark_salve1
spark_salve2
[root@spark_manager conf]# mv spark-env.sh.template spark-env.sh
[root@spark_manager conf]# cat spark-env.sh
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=zookeeper1:2181,zookeeper2:2181,zookeeper3:2181 -Dspark.deploy.zookeeper.dir=/spark"
[root@spark_manager conf]# scp -r /data/spark 192.168.20.211:/data/
[root@spark_manager conf]# scp -r /data/spark 192.168.20.213:/data/
[root@spark_manager conf]# scp -r /data/spark 192.168.20.214:/data/
[root@spark_manager sbin]# ./start-all.sh
slave 出现

spark_manager不能识别,但是host已经指向了,修改了下面shell 启动脚本主机名更改成IP。
[root@spark_manager data]# vim /data/spark/sbin/start-slaves.sh

[root@spark_manager sbin]# jps
6867 Worker
6934 Jps
6282 Master
[root@spark_salve1 data]# jps
4019 Jps
3941 Worker
[root@spark_slave2 ~]# jps
2565 Worker
2618 Jps
启动standby_manager 进程
[root@spark_manager data]# vim /data/spark/sbin/start-slaves.sh

[root@standby_master sbin]# ./start-master.sh
[root@standby_master sbin]# jps
2655 Master
2735 Jps
HA 切换
kill 掉 spark_manager 上的 manager 进程,
查看spark_salve 日志,表示已经切换。

standby_manager 日志。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号