hive 搭建
Hive
hive是简历再hadoop上的数据库仓库基础架构,它提供了一系列的工具,可以用来进行数据提取转化
加载(ETL),这是一种可以存储,查询和分析存储再hadoop种的大规模数据机制,hive定义了简单的类sql
查询语音,称为QL,它允许熟悉sql的用户查询数据,同时, 这个语言也允许熟悉mapreduce开发者的开发
自定义的mapper和 reducer 来处理内建的mapper和reducer无法完成的复杂的分析工作
数据库:关系型数据库 和 非关系型数据库 可以实时进行增删改查操作
数据仓库: 存放大量数据,可以对仓库里数据,进行计算和分析,弱点:不能实时更新,删除
Hive 是sql解析引擎,它将sql语句转译成M/R job,然后再haoop上执行
Hive的表其实你一直HDFS的目录/文件夹,按表名把文件夹分开,如果是分区表,则分区值是子文件夹,
可以直接在M/R job里使用这些数据
Hive的系统架构
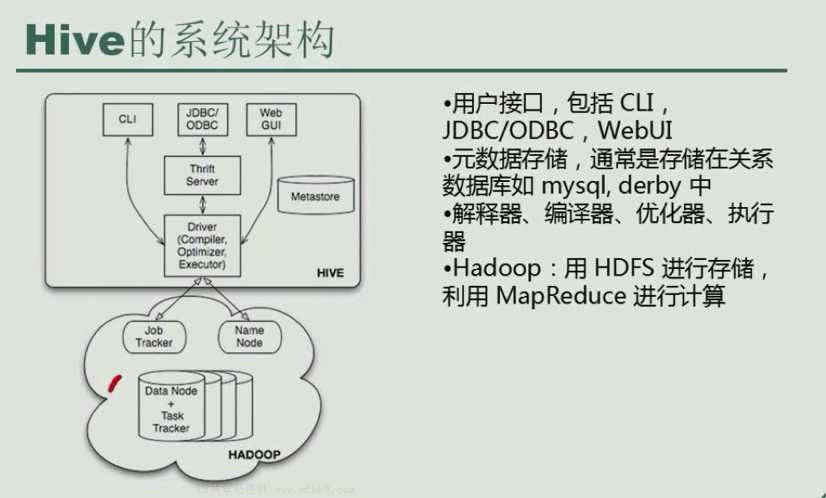
用户接口主要有三个: CLI , ODBC/JDBC . WebUI
1 cli, 即shell 命令行
2. JDBC/ODBC 是Hive的java
3. WEBUI是通过浏览器访问Hive
Hive 将元数据存储再数据库中的 metastore,并没有保存计算的数据,要计算的数据都保存在hdfs中,只保存的表的信息,表的名字,表有几个列,这个表处理的那条数据,表的描述信息, 目前只支持mysql、derby
Hive中的元数据包括表的名字, 表的列和分区及其属性,表的属性,表的数据所在目录等
解释器、编译器、优化器完成HQL查询语句从词法分析、语法分析、 编译、优化以及查询计划的生成,
生成的查询计划存储再HDDS中, 并在随后在mapreduce调用执行。
Hive的数据存储再HDFS中,大部分的查询由mapreduce完成。
Hive 既要依赖 hdfs,也要依赖yarn
derby数据库不支持多个连接
cd /data/hive/bin
./hive
hive>show databases
hive>show tables
hive>create table student(id int,name string)
hive>show create table student
cat /root/1.txt
1 feng
2 su
3 li
空行
#hive从本地加载/root/1.txt,并且导入到sutdent表中
hive>load data local inpath '/root/1.txt' into table student
查询student表数据,显示4行数据,但是都为NULL, 因为列与列之间没有分隔符, 显示2列,是应为,创建表时,有2列。
hive> select * from student;
NULL NULL
NULL NULL
NULL NULL
NULL NULL
统计student 行总数,调用mapreduce。
hive> select count(*) from student;
创建 teacher, 以\t 为分隔符。
hive>create table teacher (id bigint,name string) row format delimited fields terminated by '\t'
hive>show create table teacher
hive>select * from teacher;
hive>seley * from teacher order by id desc;
创建库
hive>create database feng;
hive>use feng;
hive>show tables;
hive>create table user (id int, name string)
metastore 保存的位置,在/data/hive/bin 目录下 derby数据名称 metastore_db,
如果metastore_db 再当前路径下只支持一个连接,
在那个目录下 运行的 hive命令,就在那个目录下 生成metastore_db,不同路径下的metastore_db,显示的库不同。
使用mysql作为 meastore 存储路径
1 删除derby 在hdfs生成的库删除
hdfs dfs rm -rf /user/hive
2. 配置hive
[root@hive1 conf]# vim hive-env.sh
HADOOP_HOME=/data/hadoop
[root@hive1 conf]# cp hive-default.xml.template hive-site.xml
<!--
<property>
<name>hive.metastore.warehouse.dir</name>
<value>hdfs://ns1/hive/warehousedir</value>
</property>
<property>
<name>hive.exec.scratchdir</name>
<value>hdfs://ns1/hive/scratchdir</value>
</property>
<property>
<name>hive.querylog.location</name>
<value>/data/hive/logs</value>
</property>
-->
<!--连接192.168.20.131 mysql数据库,如果hive没有,则创建 -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://192.168.20.131:3306/hive?createDatabaseIfNotExist=true</value>
</property>
<!--mysql odbc驱动 -->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!--mysql 用户名 -->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!--mysql 密码 -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<property>
<name>hive.aux.jars.path</name>
<value>file:///data/hive/lib/hive-hbase-handler-2.1.0.jar ,file:///data/hive/lib/protobuf-java-2.5.0.jar,file:///data/hive/lib/hbase-client-1.1.1.jar,file:///data/hive/lib/hbase-common-1.1.1.jar,file:///data/hive/lib/zookeeper-3.4.6.jar</value>
</property>
<!--
<property>
<name>hive.metastore.uris</name>
<value>thrift://192.168.20.96:9083</value>
</property>
-->
在 Hive 中创建表之前需要使用以下 HDFS 命令创建 /tmp 和 /user/hive/warehouse (hive-site.xml 配置文件中属性项 hive.metastore.warehouse.dir 的默认值) 目录并给它们赋写权限
[root@hive1 ~]# hadoop fs -mkdir -p /hive/scratchdir
[root@hive1 ~]# hadoop fs -mkdir /tmp
[root@hive1 ~]# hadoop fs -ls /hive
[root@hive1 ~]# hadoop fs -chmod -R g+w /hive/
[root@hive1 ~]# hadoop fs -chmod -R g+w /tmp
拷贝 odbc驱动
cp mysql-connector-java-5.1.40-bin.jar /data/hive/lib
从 Hive 2.1 版本开始, 我们需要先运行 schematool 命令来执行初始化操作
[root@hive1 bin]# ./schematool -dbType mysql -initSchema
[root@hive1 bin]# chown -R hadoop.hadoop /data/hive
[root@hive1 data]# su - hadoop
[hadoop@hive1 bin]$ ./hive
启动成功
hive> create table people (id int,name string)
mysql中保存表的信息, hdfs 创建一个people文件夹
192.168.20.131 mysql 保存的元数据信息 mysql中显示结果
root@localhost:hive>select * from columns_v2;
+-------+---------+-------------+-----------+-------------+
| CD_ID | COMMENT | COLUMN_NAME | TYPE_NAME | INTEGER_IDX |
+-------+---------+-------------+-----------+-------------+
| 1 | NULL | id | int | 0 |
| 1 | NULL | name | string | 1 |
+-------+---------+-------------+-----------+-------------+
2 rows in set (0.00 sec)
root@localhost:hive>select * from tbls
-> ;
+--------+-------------+-------+------------------+--------+-----------+-------+----------+---------------+--------------------+--------------------+
| TBL_ID | CREATE_TIME | DB_ID | LAST_ACCESS_TIME | OWNER | RETENTION | SD_ID | TBL_NAME | TBL_TYPE | VIEW_EXPANDED_TEXT | VIEW_ORIGINAL_TEXT |
+--------+-------------+-------+------------------+--------+-----------+-------+----------+---------------+--------------------+--------------------+
| 1 | 1479804678 | 1 | 0 | hadoop | 0 | 1 | name | MANAGED_TABLE | NULL | NULL |
+--------+-------------+-------+------------------+--------+-----------+-------+----------+---------------+--------------------+--------------------+
1 row in set (0.00 sec)
指向了 hdfs 路径
root@localhost:hive>select * from sds
-> ;
+-------+-------+------------------------------------------+---------------+---------------------------+-------------------------------------+-------------+------------------------------------------------------------+----------+
| SD_ID | CD_ID | INPUT_FORMAT | IS_COMPRESSED | IS_STOREDASSUBDIRECTORIES | LOCATION | NUM_BUCKETS | OUTPUT_FORMAT | SERDE_ID |
+-------+-------+------------------------------------------+---------------+---------------------------+-------------------------------------+-------------+------------------------------------------------------------+----------+
| 1 | 1 | org.apache.hadoop.mapred.TextInputFormat | | | hdfs://ns1/user/hive/warehouse/name | -1 | org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat | 1 |
+-------+-------+------------------------------------------+---------------+---------------------------+-------------------------------------+-------------+------------------------------------------------------------+----------+

 浙公网安备 33010602011771号
浙公网安备 33010602011771号