
如何利用混沌工程应对未知故障
在实际生产环境中,各种无法预知的事件难以避免,风险隐患无处不在。分布式系统架构的复杂性、海量数据的计算与存储、跨团队协同等,这些都在向系统的稳定性发起挑战。系统不确定性风险的加剧,最终将会波及到我们业务的连续性。
你是否想过:如果整个区域或数据中心出现故障、服务出现访问延迟、系统时钟不同步等这些问题发生,将会带来怎样的后果?其中有些结果我们可以预知,但更多可能在意料之外。这时候,你可以阅读这篇文章了解——“混沌工程”。
— 1 —
初识混沌工程
混沌工程(Chaos Engineering)是通过主动向系统中引入软件或硬件的异常状态(扰动),制造故障场景,并根据系统在各种压力下的行为表现,确定优化策略的一种系统性稳定性保障手段。
Netflix 前云架构师 Adrian Cockcroft,在 2018 年关于混沌工程的演讲中,提出了关于混沌工程的更精确的定义:“混沌工程是一种确保减轻故障影响的实验”。也有人将混沌工程比作疫苗,通过 “接种疫苗” 的方式,让系统具备抵挡 “重大疾病” 的能力。
2010 年底,Netflix 向全世界推出 Chaos Monkey ,其主要功能是随机终止在生产环境中运行的虚拟机实例和容器,模拟系统基础设施遭到破坏的场景,使得工程师能够观察服务是否健壮、有弹性,能否容忍计划外的故障。这就是混沌工程的早期雏形。
混沌工程可以为我们做什么?
| 应用场景 | 价值 |
|---|---|
| 容灾能力测试 | 通过注入故障,验证个别组件发生故障时不会影响整个系统,以及限流降级、熔断、主备切换、故障迁移等容灾手段的有效性。 |
| 微服务强弱依赖治理 | 非核心服务不能拖垮主服务。在给被调服务注入和去除故障过程中,观察主调服务的指标表现,可以直观便捷地获得依赖强弱关系,对不符合预期的依赖关系做进一步优化。 |
| 验证容器编排配置 | 通过模拟删除服务Pod和节点、增加Pod资源负载,观察系统服务可用配置性,验证副本配置、资源限制配置等是否合理。 |
| 监控警告 | 验证监控指标是否准确、监控维度是否完美、告警阈值是否合理、告警是否快速、告警接收人是否正确、通知渠道是否可用等。 |
| 应急演练 | 通过红蓝对抗等真是故障场景下的演练,考验相关人员的问题应急能力、应急效率,以战养战,丰富团队经验,增强团队信心。 |
混沌工程,与故障注入、故障测试等测试方法,有本质上的区别。混沌工程是一种生成新信息的实践,而故障注入是测试已知属性的方法。
在传统测试里,我们可以写一个断言,给定特定的条件,产生一个特定的输出,如果不满足断言条件,就说明测试出错,它不能产出一些让我们始料未及的 “惊喜”。
而混沌工程是探索更多未知场景的实验,实验会有怎样的新信息生成,我们是不确定的。
— 2 —
混沌工程原则
以下原则描述了应用混沌工程的理想方式:
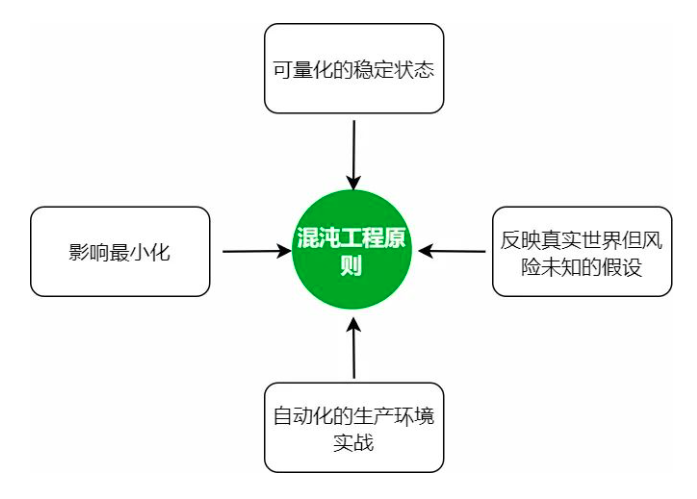
可量化的稳定状态
实施混沌工程,首先要了解系统在正常状态下的行为。因为,在人为注入故障后,不仅要评估故障注入对系统造成的影响,还要确保系统能够恢复到这个稳定状态。
因此,需要收集一些可测量的指标,来实现系统稳定状态的可观测性。而业务指标相比系统指标(如 CPU 负载、内存使用率等),更能反映系统的健康状态以及用户满意度。
反映真实世界但风险未知的假设
在真实业务场景中,遇到的任何故障都是混沌实验的潜在变量。目前业界已经有了按照 IaaS 层、PaaS 层、SaaS 层划分的故障画像(如下图)。除了对这些已出现的问题进行分类、优先级排序外,也要对未来可能会出现的新问题保持关注。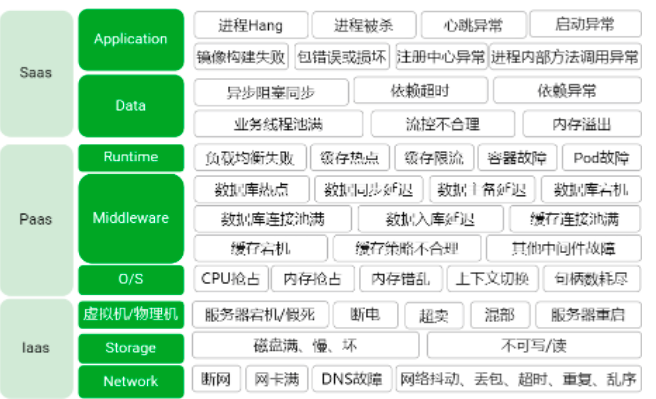
同时,践行混沌工程要以接受不确定性为思想前提,即把重点放在发现未知的风险并进行改进,而非做出对实验输入和输出有明确预期的假设。
但是,在决定引入哪些事件时,也需要估算事件发生的概率和最终影响范围,推算造成的成本和复杂度等。
自动化的生产环境实战
同军队演练一样,将每次演习都看作是一次实战。生产环境的服务状态和流量模式等问题也会影响到系统的行为。
因此,最好直接在生产环境中进行混沌实验。混沌工程实验还应该实现自动化且可持续运行,能够全自动的设计、执行和终止实验。
影响最小化
面对未知实验,想要完全避免不出问题是不可能的。在生产环境中进行实验必然是有风险的,但冒这个风险的代价总会比将来大规模业务中断所带来的打击要小。
而我们所要做的就是,使用技术手段最小化故障对客户的影响,即 “最小爆炸半径”,如采取小范围的故障注入、流量路由、数据隔离等手段。
— 3 —
如何实施混沌工程
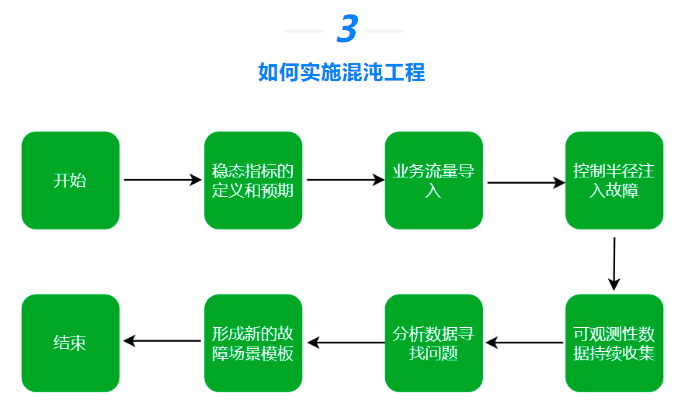
设计实验
-
确定稳态指标:确定一个与用户相关的关键性能指标,如订单量或每秒的流量等。
-
创建假设:假设系统会出现哪些问题,注入了相应故障后会发生什么,这个结果可能会对客户造成什么影响。
执行实验
-
确定实验范围——控制半径
-
故障注入
故障观察
如果观测到稳态指标受到影响,则可以停止实验。接下来首先评估故障本身,根据指标变化情况来验证(或反驳)预先的假设。然后,检查仪表板和警报,看看是否有其他意外变动。
事后分析——发现新故障
实验结束后,需要深入分析总结故障的种类、影响、发生的原因以及防止未来发生类似故障的方法。
通过混沌实验,你有可能在系统瘫痪之前,发现了新故障并及时进行了修复,你也有可能会发现,系统对注入的故障具有恢复弹性,因而增强了对系统的信心。
— 4 —
开源项目
Chaos Monkey
https://github.com/netflix/chaosmonkey%0a
Chaos Mesh
Chaos Mesh 是一个云原生混沌工程平台,提供了在 Kubernetes 平台上进行混沌测试的能力。
https://github.com/chaos-mesh/chaos-mesh%0a
Litmus
Litmus 是一种开源的云原生混沌工程工具集,帮助 Kubernetes SRE 和开发人员发现 Kubernetes 平台和应用的韧性问题。
https://github.com/litmuschaos/litmus%0a
Chaosblade
ChaosBlade 是阿里巴巴在其自身故障测试和演练实践基础上,结合自身业务场景而开发的面向多集群、多环境、多语言的混沌工程平台。
https://github.com/chaosblade-io/chaosblade%0a
本文源自公众号道客船长,分布式实验室已获完整授权。

