

zookeeper 集群搭建
zk集群规划
10个客户端节点: 3个zk节点
10-5-个客户端节点: 5 + 2OB 节点 = 7 zk节点
50-100个客户端节点: 5 + 6OB = 11zk节点
在 ZooKeeper 集群服务运行的过程中,Observer 服务器与 Follow 服务器具有一个相同的功能,那就是负责处理来自客户端的诸如查询数据节点等非事务性的会话请求操作。但与 Follow 服务器不同的是,Observer 不参与 Leader 服务器的选举工作,也不会被选举为 Leader 服务器。
Observer 服务器做的事情几乎和 Follow 服务器一样,那么为什么 ZooKeeper 还要创建一个 Observer 角色服务器呢?
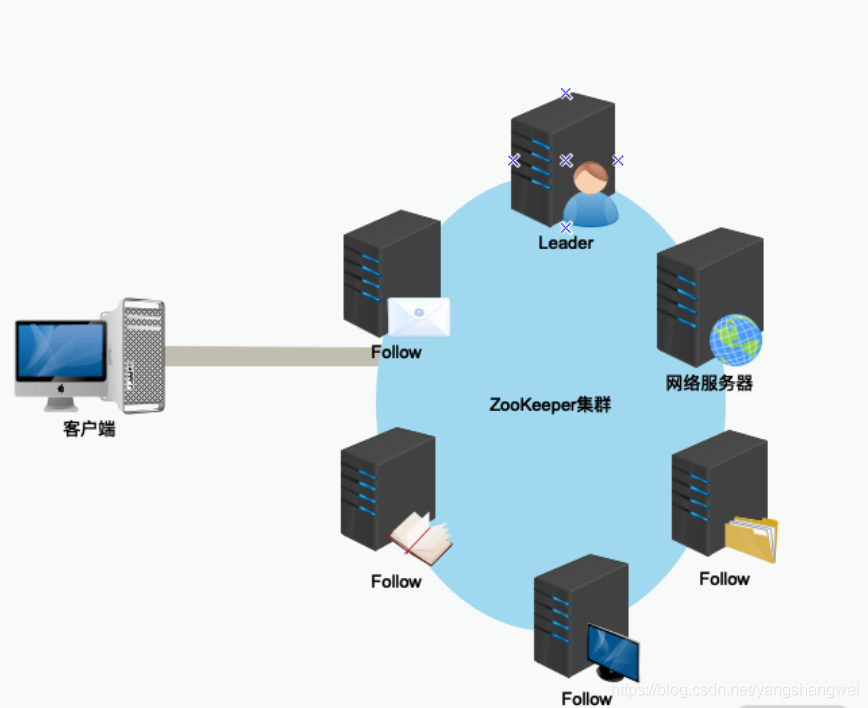
在早期的 ZooKeeper 集群服务运行过程中,只有 Leader 服务器和 Follow 服务器。
不过随着 ZooKeeper 在分布式环境下的广泛应用,早期模式的设计缺点也随之产生,主要带来的问题有如下几点:
随着集群规模的变大,集群处理写入的性能反而下降。
ZooKeeper 集群无法做到跨域部署
其中最主要的问题在于,当 ZooKeeper 集群的规模变大,集群中 Follow 服务器数量逐渐增多的时候,ZooKeeper 处理创建数据节点等事务性请求操作的性能就会逐渐下降。这是因为 ZooKeeper 集群在处理事务性请求操作时,要在 ZooKeeper 集群中对该事务性的请求发起投票,只有超过半数的 Follow 服务器投票一致,才会执行该条写入操作。
正因如此,随着集群中 Follow 服务器的数量越来越多,一次写入等相关操作的投票也就变得越来越复杂,并且 Follow 服务器之间彼此的网络通信也变得越来越耗时,导致随着 Follow 服务器数量的逐步增加,事务性的处理性能反而变得越来越低。
为了解决这一问题, ZooKeeper 集群中创建了一种新的服务器角色,即 Observer——观察者角色服务器。Observer 可以处理 ZooKeeper 集群中的非事务性请求,并且不参与 Leader 节点等投票相关的操作。这样既保证了 ZooKeeper 集群性能的扩展性,又避免了因为过多的服务器参与投票相关的操作而影响 ZooKeeper 集群处理事务性会话请求的能力。
在引入 Observer 角色服务器后,一个 ZooKeeper 集群服务在部署的拓扑结构,如下图所示:
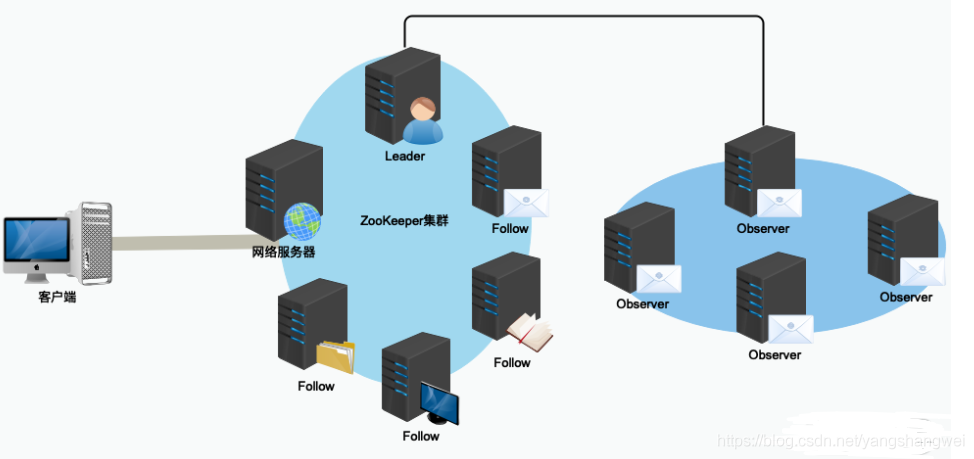
在实际部署的时候,因为 Observer 不参与 Leader 节点等操作,并不会像 Follow 服务器那样频繁的与 Leader 服务器进行通信。因此,可以将 Observer 服务器部署在不同的网络区间中,这样也不会影响整个 ZooKeeper 集群的性能,也就是所谓的跨域部署。
环境准备:
172.16.230.121 namenode1
172.16.230.122 namenode2
172.16.230.123 datanode1 zk
172.16.230.124 datanode2 zk
172.16.230.125 datanode3 zk
下载zookeeper
wget http://archive.apache.org/dist/zookeeper/zookeeper-3.5.5/apache-zookeeper-3.5.5-bin.tar.gz
tar -zxvf apache-zookeeper-3.5.5-bin.tar.gz
mv apache-zookeeper-3.5.5 /data/zookeeper
修改配置文件
mkdir /data/zookeeper/logs mkdir /data/zookeeper/data cd /data/zookeeper/conf mv zoo_sample.cfg zoo.cfg vim /data/zookeeper/conf/zoo.cfg tickTime=2000 initLimit=10 syncLimit=5 clientPort=2181 #将单个客户端(由IP地址标识)可以与ZooKeeper集成中的单个成员建立的并发连接数(在套接字级别)限制为多少 maxClientCnxns=2000 #服务器允许客户端进行协商的最大会话超时(以毫秒为单位)。默认为tickTime的20倍 maxSessionTimeout=60000000 #ZooKeeper自动清除功能会将autopurge.snapRetainCount最新快照和相应的事务日志分别保留在dataDir和dataLogDir中 autopurge.snapRetainCount=10 #触发清除任务的时间间隔(以小时为单位) autopurge.purgeInterval=1 #为了避免查找,ZooKeeper以preAllocSize千字节的块为单位在事务日志文件中分配空间。默认块大小为64M preAllocSize=131072 #使用快照和事务日志(请考虑预写日志)记录其事务 snapCount=3000000 #负责接受客户端连接。默认值为“是” leaderServes=yes dataDir=/data/zookeeper/data dataLogDir=/data/zookeeper/log 4lw.commands.whitelist=* server.1=datanode1:2888:3888 server.2=datanode2:2888:3888 server.3=datanode3:2888:3888
查看 /data/zookeeper/bin/zkENV.sh中 jvm 默认HEAP
#注释掉ZK_SERVER_HEAP,使用自己定义的jvm , 默认jvm 使用1G。
ZK_SERVER_HEAP="${ZK_SERVER_HEAP:-1000}"
export SERVER_JVMFLAGS="$SERVER_JVMFLAGS"
# default heap for zookeeper client
ZK_CLIENT_HEAP="${ZK_CLIENT_HEAP:-256}"
export CLIENT_JVMFLAGS="$CLIENT_JVMFLAGS"
新建 /data/zookeeper/conf/zookeeper-env.sh 启动后会加载。
JAVA_HOME=/data/jdk ZOO_LOG_DIR=/data/zookeeper/logs ZOO_LOG4J_PROP="WARN,ROLLINGFILE" SERVER_JVMFLAGS="-server -Xms1G -Xmx1G -Xmn400m -Xss228k -XX:+UseG1GC -XX:G1ReservePercent=25 -XX:InitiatingHeapOccupancyPercent=30 -XX:+DisableExplicitGC -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/data/logs/hadoop -XX:ErrorFile=/data/logs/hadoop/hs_err_pid%p.log -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintTenuringDistribution -XX:+PrintGCApplicationStoppedTime -Xloggc:/data/logs/hadoop/gc.log -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=32 -XX:GCLogFileSize=64m"
# -Xms1G 初始化内存, -Xmx1G 最大内存1G
# -Xmn400m 新生代, 最大内存的3/8
# -Xss228K 线程占用的堆内存
创建myid文件
172.16.230.121 echo "1" > /data/zookeeper/data/myid 172.16.230.122 echo "2" > /data/zookeeper/data/myid 172.16.230.123 echo "3" > /data/zookeeper/data/myid
加入环境变量
[hadoop@datanode1 bin]$ cat ~/.bash_profile # .bash_profile # Get the aliases and functions if [ -f ~/.bashrc ]; then . ~/.bashrc fi # User specific environment and startup programs PATH=$PATH:$HOME/.local/bin:$HOME/bin:/data/zookeeper/bin export PATH
source ~/.bash_profile
启动:
zkServer.sh start
zkServer.sh status
zookeeper 动态配置, 添加observer
vim /data/zookeeper/conf/zoo.cfg tickTime=2000 initLimit=10 syncLimit=5 dataDir=/tmp/zookeeper clientPort=2181 #将单个客户端(由IP地址标识)可以与ZooKeeper集成中的单个成员建立的并发连接数(在套接字级别)限制为多少 maxClientCnxns=2000 #服务器允许客户端进行协商的最大会话超时(以毫秒为单位)。默认为tickTime的20倍 maxSessionTimeout=60000000 #ZooKeeper自动清除功能会将autopurge.snapRetainCount最新快照和相应的事务日志分别保留在dataDir和dataLogDir中 autopurge.snapRetainCount=10 #触发清除任务的时间间隔(以小时为单位) autopurge.purgeInterval=1 #为了避免查找,ZooKeeper以preAllocSize千字节的块为单位在事务日志文件中分配空间。默认块大小为64M preAllocSize=131072 #使用快照和事务日志(请考虑预写日志)记录其事务 snapCount=3000000 #负责接受客户端连接。默认值为“是” leaderServes=yes dataDir=/data/zookeeper/data dataLogDir=/data/zookeeper/log 4lw.commands.whitelist=* server.1=datanode1:2888:3888 server.2=datanode2:2888:3888 server.3=datanode3:2888:3888
#启动动态配置 reconfigEnabled=true dynamicConfigFile=/data/zookeeper/conf/zoo_replicated1.cfg.dynamic
动态配置文件/data/zookeeper/conf/zoo_replicated1.cfg.dynamic
server.1=datanode1:2888:3888;2181 server.2=datanode2:2888:3888;2181 server.3=datanode3:2888:3888;2181 server.4=datanode4:2888:3888:observer;2181 server.5=datanode5:2888:3888:observer;2181
datanode4 datanode5 创建myid文件
172.16.230.124 echo "4" > /data/zookeeper/data/myid 172.16.230.125 echo "5" > /data/zookeeper/data/myid
datanode6扩容:
动态配置文件/data/zookeeper/conf/zoo_replicated1.cfg.dynamic
server.1=datanode1:2888:3888;2181
server.2=datanode2:2888:3888;2181
server.3=datanode3:2888:3888;2181
# 添加server.6###############
server.6=datanode6:2888:3888;2181
##############################
server.4=datanode4:2888:3888:observer;2181
server.5=datanode5:2888:3888:observer;2181
datanode6 创建myid文件
172.16.230.126
echo "6" > /data/zookeeper/data/myid
登陆121 节点(执行reconfig -add)
zkCli.sh reconfig -add 6=datanode6:2888:3888;2181
删除datanode6(执行reconfig -remove)
reconfig -remove 6
systemctl 自启动
[Unit] Description=ZooKeeper Service After=network.target [Service] Type=forking Environment=JAVA_HOME=/data/jdk ExecStart=/data/zookeeper/bin/zkServer.sh start ExecReload=/data/zookeeper/bin/zkServer.sh restart ExecStop=/data/zookeeper/bin/zkServer.sh stop Restart=always [Install] WantedBy=default.target
https://zookeeper.apache.org/doc/r3.5.9/zookeeperAdmin.html#sc_systemReq
https://zookeeper.apache.org/doc/r3.5.9/zookeeperReconfig.html

