

kafka学习
1. 为何需要消息服务
2. 消息中间件的发展历史
3. 业界对比
4. 基本概念介绍
5. 操作实战
基于消息中间件构建消息服务,解决云分布式场景的消息通信问题,提供高可靠,高性能(高并发,高吞吐),高扩展的消息管道
优点:
1.系统解耦, 基于发布订阅模型,分布式应用异步解构,可以增加应用的水平扩展性,增加前端应用快速反应能力
2.削峰填谷, 大促等流量突然来袭时,消息服务可以缓冲突发流向,避免整个系统崩溃。
3. 数据交换, 解决跨DC传输,通道安全可靠,服务可用的问题
4.异步通知, 海量终端接入,高吞吐,低延迟
5.日志通道, 作为重要日志监控通信管道,将应用日志监控对系统性能影响降到最低。

消息中间件,是指支持与保证分布式应用程序之间同步/异步接受消息的中间价,通过消息中间价,应用程序或组件之间可以进行可靠的异步通讯来降低系统之间的耦合度,从而提高整个系统的可宽展行和可用性。
业界分布式mq横向对比分析
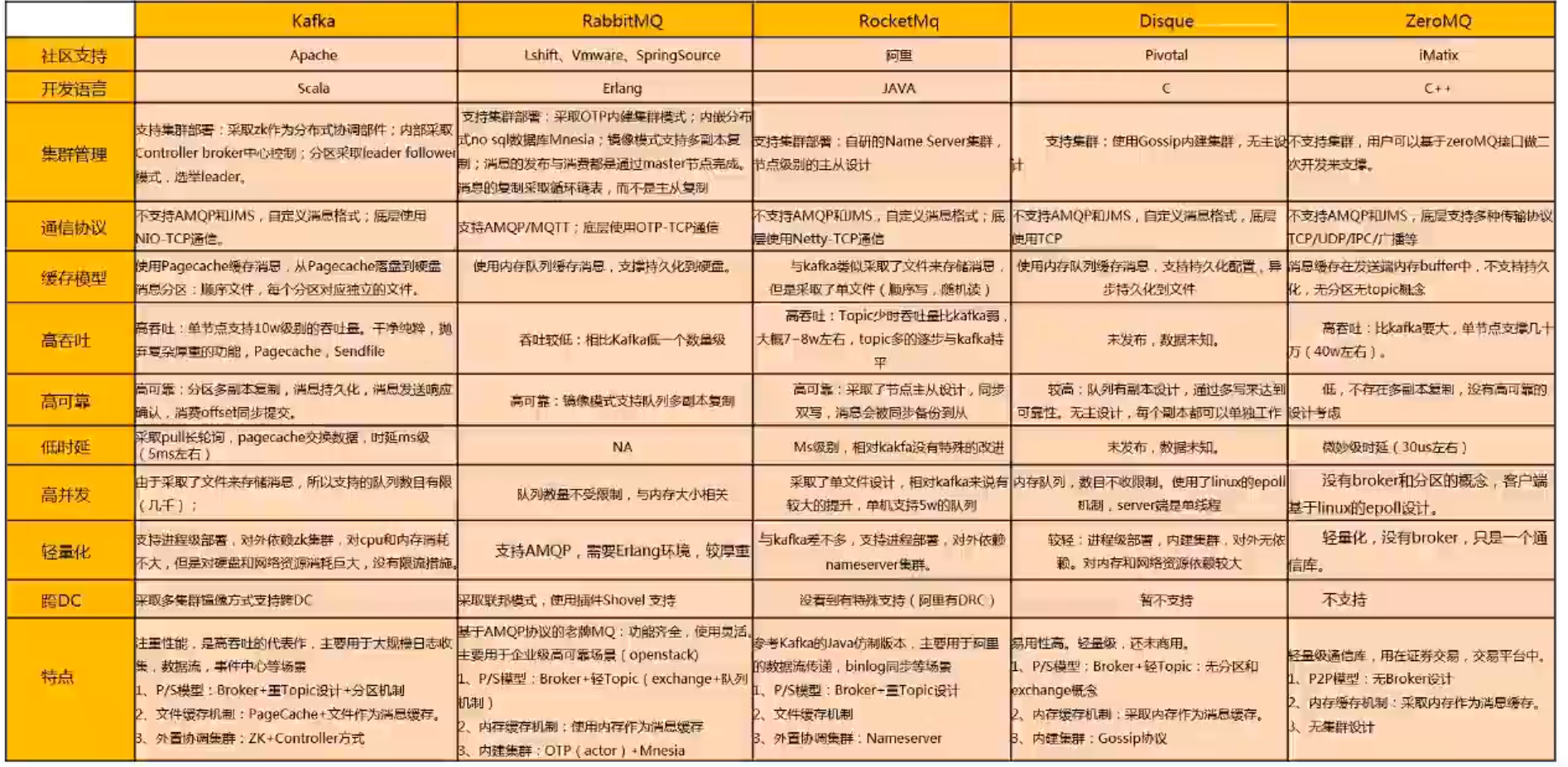
kafka: 是一种分布式、基于发布/订阅的消息中间价
1. 高性能、高吞吐: 消息是追加写盘,顺序写盘、充分利用磁盘IO、消息可以在client端压缩,发送到server端,提升了性能。
2. 在线扩容 : 分区机制,在线扩容, 副本在线扩容, 节点broker在线扩容。
3. 高可靠 集群部署、多副本机制: 多副本机制,支持在线扩容,支持分区在线迁移。
kafka基本概念:
1. broker: kafka集群包含一个或者多个服务实例,之中服务实例被称作broker。
2. topic: 每条发布到kafka集群的消息都有一个类别,这个类别被称作topic
3. partition: 分区是物理上的概念,每个topic包含一个或者多个分区。
4.producer: 负责发布消息到kafka broker。
5. consumer: 消息消费者,向kafka broker 读取消息的客户端。
6. consumer group: 每个consumer 属于一个特定的consumer group(可为每个consumer指定group name,否则属于默认的group)
4.1 kafka批量生产机制,并且是异步的
1. 当一条消息在发送的时候,首先会在本地进行缓存,会根据这条消息属于那个分区,放入到不同的Batch,放到不同的包里。
2. 异步线程会从缓冲区里取消息,把发往同一个broker的batch打包,然后放到同一个请求里,再发送到broker。
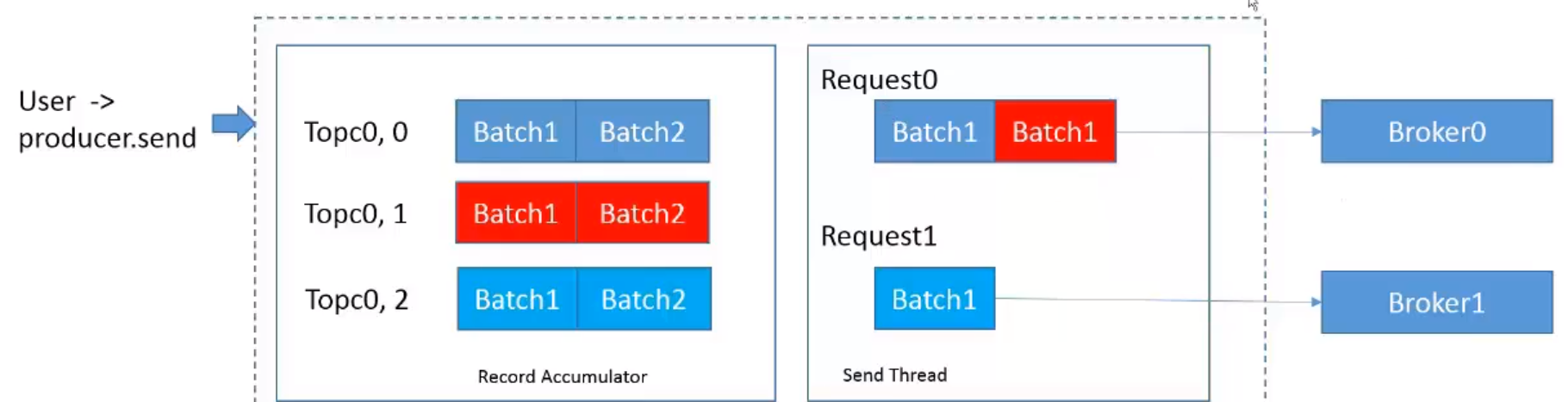
4.2 kafka 分区副本
1. kafka通过副本方式达到高可用的目标,每个分区可以有一个或者多个副本,分别分配在不同的节点上。
2. 多个副本之间只有一个leader,其他副本通过pull模式同步leader消息,处于同步状态的副本集合称为ISR
3. 生产者和消费者都只能从leader写入或者读取数据,leader故障后,会有线从ISR集群中选择副本作为leader
4. ISR同步副本的集合。
4.3 kafka partition & offset
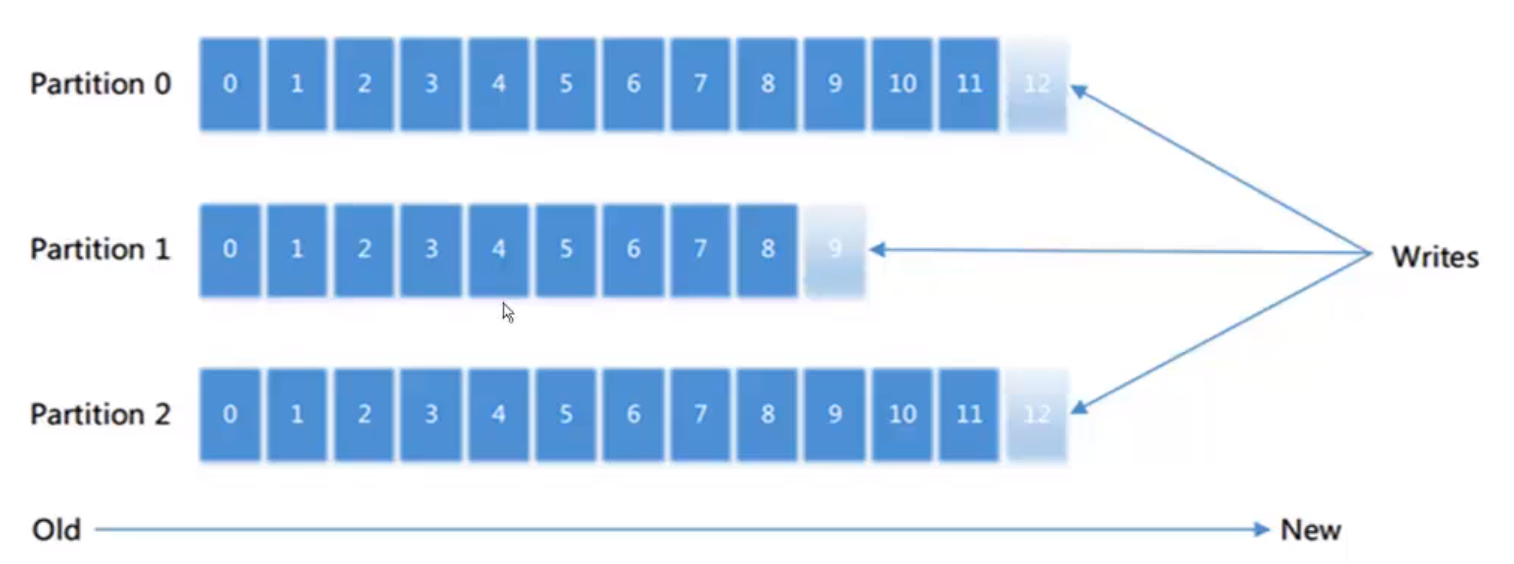
1. 每个分区消息只能通过追加消息的方式增加消息,消息都有一个偏移量(offset),顺序写入保证性能高效
2. 消费者通过分区中offset 定位消费和记录消费的位置。
4.4 kafka消费者组合分区。
1. 每个消费者都属于一个消费组,通过消费组概念可以实现topic消息的广播(发送所有消费组)或者单播(组内消息均衡分担)
2. 消费者采用pull模式进行消费,方便消费进度记录在客户端,服务端无状态。
3. 组内的消费者以topic 分区个数进行衡量分配,所有组内消费者最多只能有分区个数的消费者。
4.7 kafka 高可用机制
分布式系统下,单点故障不可避免,kafka如何管理节点故障。
1. 从kafka的broker 中选择一个节点作为分区管理与副本状态变更的控制,称为controller
2. 统一监听zk元数据变化,通知各节点状态信息。
3. 管理broker节点的故障恢复, 对故障节点所在分区进行重新leader选举,帮助业务故障切换到新的broker
如果controller节点本身故障
各个broker节点通过watch zk的/controller节点,如果controller故障,会出发节点进行争夺创建/controller节点,创建上的节点称为新的controller.
kafka生产机制:
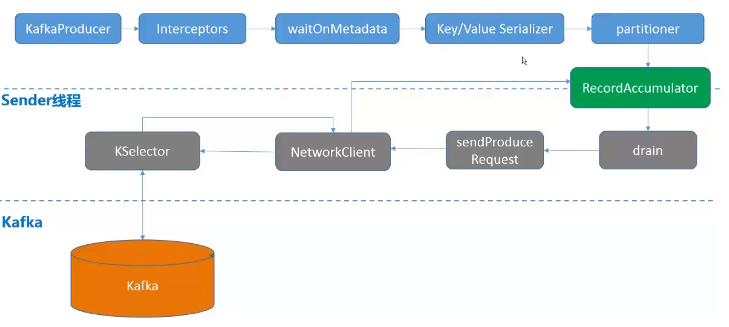
生产模型: Batch

* batch size
默认16384(16K), 消息batch大小, 当batch达到batch.size大小时, 唤醒sender线程发送消息,批量发送消息,减少request数量,提高发送效率,减轻服务端压力
* ling.ms
默认为0, sender线程检查batch是否ready,满足batch size和ling.ms 其中一个,即发送消息
* buffer.memory
默认33554432(32M), producer可以用来缓存数据的内存大小, 如果数据产生速度大于想broker发送的速度, producer会阻塞或者抛出异常,通过参数“block.on.buffer.full”控制。
2.1 参数调优
参数 默认值 推荐值 说明
buffer.memory 33554432 536870912 producer可以采用缓存数据的内存大小,如果数据产生速度大于向broker发送的速度,producer会阻塞或者抛出异常,这项这是将和producer能够使用的内存相关,但并不是一个硬性的限制,因为不是producer 使用的所有内存都是用于缓存,一些额外的内存会使用压缩
linger.ms 0 0 producer组将会汇总任何在请求和发送之间到达的消息记录一个单独批量的请求,通常来说,只要在记录产生速度大于发送速度的时候才能发生,然而,在某些条件下,客户端将希望降低请求的数量,甚至降低到中等负载以下,
receive.buffer.byte 32768 默认值 TCP receive 缓存大小, 当读取数据是使用。
send.buffer.bytes 131072 默认值 TCP send缓存大小,当发送数据时使用。
acks 1 1 producer 需要server接收到数据之后发生的确认接收的信号,此项配置就是指producer需要多少个这样的确认信号,acks=0 表示producer不需要等待任何接收的信息,acks=1 表示等待leader已经成功将数据写入到本地log,但是并没有等待所有follower是否成功写入。这种情况下,如果follower没有成功备份到数据,此时leader挂掉,则消息会丢失。acks=all,表示leader 需要等待所有备份都成功写入到日志。
batch.size 16384 262144 producer 将试图处理消息记录,以减轻请求次数,这将改善client与server之间的性能,这项配置控制默认的批量处理消息字节数。
kafka 高吞吐生产配置:
1. Topic配置: 3分区 、 2副本 2. 配置发送确认配置: acks=0 or 1 #允许丢消息
kafka 相对可靠配置
1. Topic配置: 3分区 、3副本 min.insync.replicas = 2 #最小同步副本数为2
2. 配置发送确认配置: acks = -1 # IRS副本消息都同步后,再响应。
kafka 高可靠配置,性能影响较大
1. Topic配置: 3分区 、3副本 min.insync.replicas = 2 #最小同步副本数为2 flush.messages = 1 #接收的消息,全部落盘 2. 配置发送确认配置: acks = -1 # IRS副本消息都同步后,再响应。
kafka消费机制
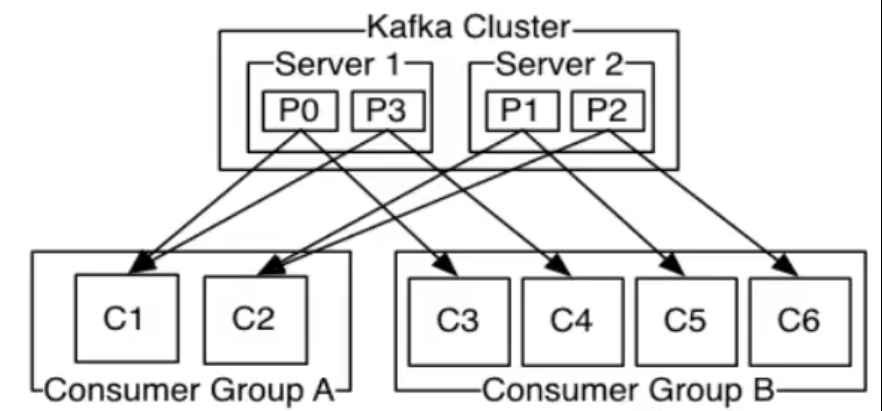
1. comsumer: kafka消费者负责pull消息和确认消息,分new consumer(消费进度_consumer_offsets) 和 old consumer(不适用了,消息进度保存在zk里。)
2. group: 每个消费者都属于一个消费组内, 通过消费组可以实现topic消息的广播和单播
3.relalance: 组内的消费者以topic分区个数进行负载均衡,所以组内消费者最多只有分区个数的消费者。
4.assign: 收费消费分区。
5. subscribe 模式: 自动分配消费分区。
1.2 基本概念:消费模型
消费模型: 消费者采用pull 模式进行消费,方便消费进度记录在客户端,服务端是无状态的。

首先是一个fetch请求,拉去多少请求,是consumer决定的(fetch_size 拉去多少消息), 从broker里面指定的patition 去fetch这个消息,fetch消息后,还需要提交消费进度,也是又consumer 把消费进度提交到broker,把消费进度写在_consumer_offsets中。
1.3 基本概念: 消费进度管理机制
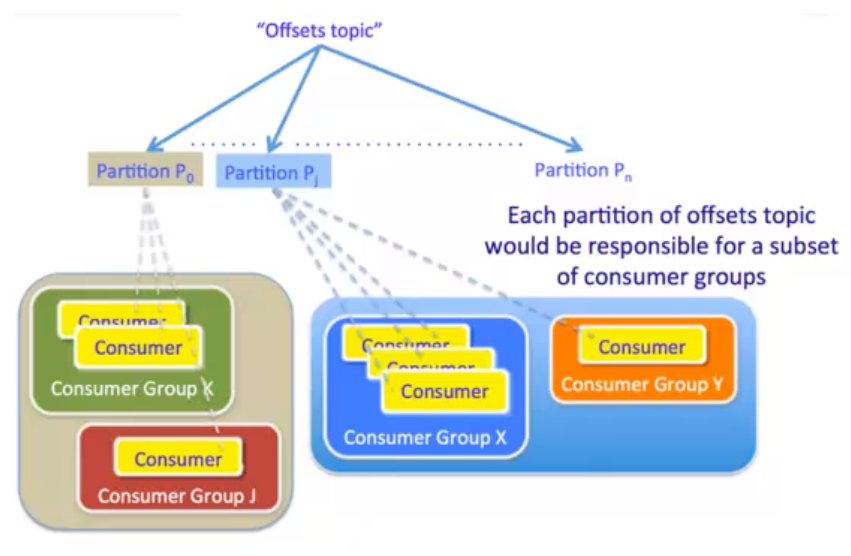
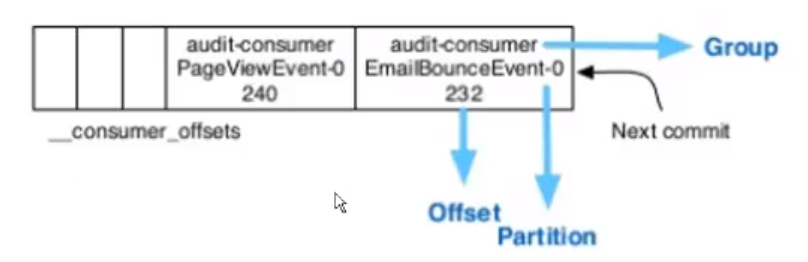
消费进度其实就是一条一条的消息,消息已经保存在_consumer_offset中,消息保存的内容包括 group(消费组的信息) partition(emailbounceevent-0分区0) offset(232),消费过程中也是要指定分区的。
消费机制
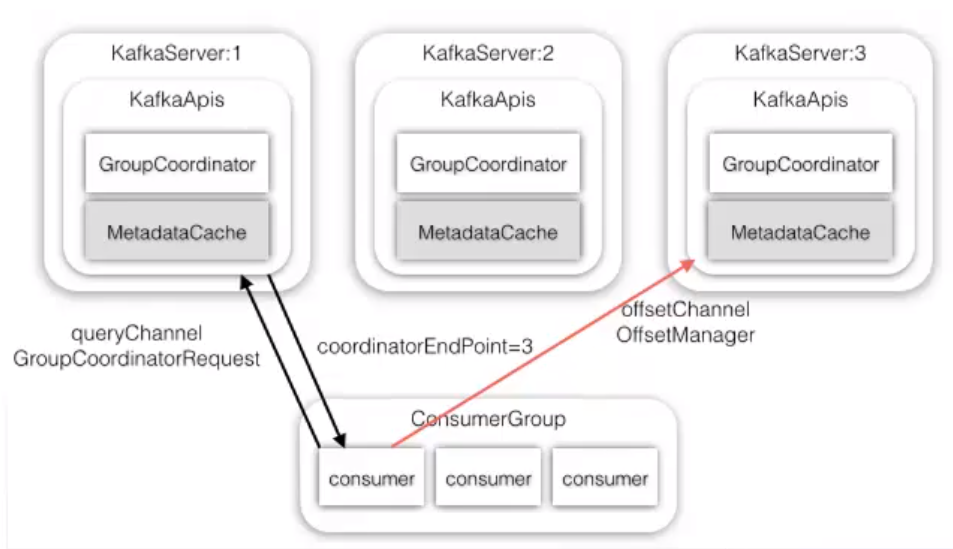
1. 每个消费组里面的消费者都需要先查找一个协调者(groupcoordinator)
2. 消费者加入到这个组内,主要目的是为了对分区进行分配
3. 分配分区完毕后,再查找各自分区的leader,进行消费。
GroupCoordinator: 职责
处理 JoinGroupRequest、 SyncGroupRequest 完成 Partition 分配
维护 _consumer_offset, 关系消费进度
通过心跳检查消费者状态。
4.1 Group Rebalance: 触发条件
* 新的consumer 加入到group
* 有consumer 退出: 主动leave 宕机 网络故障
* Topic 分区数变化
* Consumer 调用 unsubscrible
参数配置
参数 默认值 推荐值 说明 max.partition.fetch.bytes 1048576 默认值 每次fetch请求中,针对每次fetch消息的最大字节数,这些字节将会督导用于每个partition的内存中,因此,次设置将会控制consumer所使用的memory大小,这个fetch请求尺寸必须至少和server允许的最大消息尺寸相等,否则,producer可能发送的消息尺寸大于consumer所能消耗的尺寸。 fetch.min.bytes 1 默认值 每次fetch请求时,server应该返回的最小字节数,如果没有足够的数据返回,请求会等待,知道足够的数据才会返回。 fetch.wait.max.ms 500 默认值 如果没有足够的数据能够满足fetch.min.bytes,则此项配置是指在答应fetch请求之前,server会阻塞的最大时间。
使用规范:
1. consumer owner 线程需要确保不会异常退出,避免客户端没有发起消费请求,阻塞消费。
2. 确保处理完消息后再做消息commit,避免业务消息处理失败,无法重新拉去处理失败的消息。
3. consumer 不能频繁加入和退出group, 会导致consumer频繁做rebalance,阻塞消费。
4. consumer 数量不能超过topic分区数,否则会有consumer 拉取不到消息。
5. consumer 需周期poll, 维持和server的心跳,必须心跳超时,导致consumer 频繁加入和退出,阻塞消费。
6. consumer 拉取的消息本地缓存应有大小限制,避免OOM
7.kafka不能保证消费重复的消息,
8.消费线程退出要调用consumer 的close方法,避免同一个组的其他消费者阻塞session.timeout.ms的时间。

