



Spark译文(一)
Spark Overview(Spark概述)
·Apache Spark是一种快速通用的集群计算系统。
·它提供Java,Scala,Python和R中的高级API,以及支持通用执行图的优化引擎。
·它还支持丰富的高级工具集,包括用于SQL和结构化数据处理的Spark SQL,用于机器学习的MLlib,用于图形处理的GraphX和Spark Streaming
Security(安全性)
·Spark中的安全性默认为OFF。
·这可能意味着您很容易受到默认攻击。
·在下载和运行Spark之前,请参阅Spark Security
Downloading
·从项目网站的下载页面获取Spark。
·本文档适用于Spark版本2.4.2。
·Spark使用Hadoop的客户端库来实现HDFS和YARN。
·下载是针对少数流行的Hadoop版本预先打包的。
·用户还可以通过增加Spark的类路径下载“Hadoop免费”二进制文件并使用任何Hadoop版本运行Spark。
·Scala和Java用户可以使用Maven坐标在他们的项目中包含Spark,并且将来Python用户也可以从PyPI安装Spark。
·如果您想从源代码构建Spark,请访问Building Spark。
·Spark在Windows和类UNIX系统(例如Linux,Mac OS)上运行。
·在一台机器上本地运行很容易 - 您只需要在系统PATH上安装Java,或者指向Java安装的JAVA_HOME环境变量。
·Spark运行在Java 8 +,Python 2.7 + / 3.4 +和R 3.1+上。
·对于Scala API,Spark 2.4.2使用Scala 2.12。
·您需要使用兼容的Scala版本(2.12.x)。
·请注意,自Spark 2.2.0起,对2.6.5之前的Java 7,Python 2.6和旧Hadoop版本的支持已被删除。
·自2.3.0起,对Scala 2.10的支持被删除。
·自Spark 2.4.1起,对Scala 2.11的支持已被弃用,将在Spark 3.0中删除。
Running the Examples and Shell(运行示例和Shell)
·Spark附带了几个示例程序。
·Scala,Java,Python和R示例位于examples / src / main目录中。
·要运行其中一个Java或Scala示例程序,请在顶级Spark目录中使用bin / run-example [params]。
·(在幕后,这将调用更常用的spark-submit脚本来启动应用程序)。
·例如
./bin/run-example SparkPi 10·您还可以通过Scala shell的修改版本以交互方式运行Spark。
·这是学习框架的好方法。
./bin/spark-shell --master local[2]·--master选项指定分布式集群的主URL,或本地在一个线程上本地运行,或本地[N]在本地运行N个线程。
·您应该首先使用local进行测试。
·有关选项的完整列表,请使用--help选项运行Spark shell。
·Spark还提供了一个Python API。
·要在Python解释器中以交互方式运行Spark,请使用bin / pyspark:
./bin/pyspark --master local[2]·Python中也提供了示例应用程序。
·例如:
./bin/spark-submit examples/src/main/python/pi.py 10
Quick Start(快速开始)
·本教程简要介绍了如何使用Spark。
·我们将首先通过Spark的交互式shell(在Python或Scala中)介绍API,然后展示如何使用Java,Scala和Python编写应用程序。
·要继续本指南,首先,从Spark网站下载Spark的打包版本。
·由于我们不会使用HDFS,您可以下载任何版本的Hadoop的软件包。
·请注意,在Spark 2.0之前,Spark的主要编程接口是Resilient Distributed Dataset(RDD)。
·在Spark 2.0之后,RDD被数据集取代,数据集像RDD一样强类型,但在底层有更丰富的优化。
·仍然支持RDD接口,您可以在RDD编程指南中获得更详细的参考。
·但是,我们强烈建议您切换到使用数据集,它具有比RDD更好的性能。
·请参阅SQL编程指南以获取有关数据集的更多信息
Interactive Analysis with the Spark Shell(使用Spark Shell进行交互式分析)
Basics(基本)
·Spark的shell提供了一种学习API的简单方法,以及一种以交互方式分析数据的强大工具。
·它可以在Scala(在Java VM上运行,因此是使用现有Java库的好方法)或Python中使用。
·通过在Spark目录中运行以下命令来启动它:
./bin/pyspark
或者如果在当前环境中使用pip安装了PySpark:
pyspark·Spark的主要抽象是一个名为Dataset的分布式项目集合。
·可以从Hadoop InputFormats(例如HDFS文件)或通过转换其他数据集来创建数据集。
·由于Python的动态特性,我们不需要在Python中强类型数据集。
·因此,Python中的所有数据集都是Dataset [Row],我们称之为DataFrame与Pandas和R中的数据框概念一致。让我们从Spark源目录中的README文件的文本中创建一个新的DataFrame:
>>> textFile = spark.read.text("README.md")·您可以通过调用某些操作直接从DataFrame获取值,也可以转换DataFrame以获取新值。
·有关更多详细信息,请阅读API文档。
>>> textFile.count() # Number of rows in this DataFrame
126
>>> textFile.first() # First row in this DataFrame
Row(value=u'# Apache Spark')
·现在让我们将这个DataFrame转换为一个新的DataFrame。
·我们调用filter来返回一个新的DataFrame,其中包含文件中的一行子集。
>>> linesWithSpark = textFile.filter(textFile.value.contains("Spark"))我们可以将转换和行动联系在一起:
>>> textFile.filter(textFile.value.contains("Spark")).count() # How many lines contain "Spark"?
15More on Dataset Operations(有关数据集操作的更多信息)
·数据集操作和转换可用于更复杂的计算。
·假设我们想要找到含有最多单词的行:
>>> from pyspark.sql.functions import *
>>> textFile.select(size(split(textFile.value, "\s+")).name("numWords")).agg(max(col("numWords"))).collect()
[Row(max(numWords)=15)]·这首先将一行映射为整数值,并将其别名为“numWords”,从而创建一个新的DataFrame。
·在该DataFrame上调用agg以查找最大字数。
·select和agg的参数都是Column,我们可以使用df.colName从DataFrame中获取一列。
·我们还可以导入pyspark.sql.functions,它提供了许多方便的功能来从旧的列构建一个新的列。
·一个常见的数据流模式是MapReduce,由Hadoop推广。
·Spark可以轻松实现MapReduce流程:
>>> wordCounts = textFile.select(explode(split(textFile.value, "\s+")).alias("word")).groupBy("word").count()·在这里,我们使用select中的explode函数,将行数据集转换为单词数据集,然后将groupBy和count结合起来计算文件中的每个单词计数,作为2列的DataFrame:“word”和“
·计数”。
·要在我们的shell中收集单词count,我们可以调用collect:
>>> wordCounts.collect()
[Row(word=u'online', count=1), Row(word=u'graphs', count=1), ...]Caching(高速缓存)
·Spark还支持将数据集提取到群集范围的内存缓存中。
·这在重复访问数据时非常有用,例如查询小的“热”数据集或运行像PageRank这样的迭代算法时。
·举个简单的例子,让我们标记要缓存的linesWithSpark数据集:
>>> linesWithSpark.cache()
>>> linesWithSpark.count()
15
>>> linesWithSpark.count()
15·使用Spark来探索和缓存100行文本文件似乎很愚蠢。
·有趣的是,这些相同的功能可用于非常大的数据集,即使它们跨越数十个或数百个节点进行条带化。
·您也可以通过将bin / pyspark连接到群集来交互式地执行此操作,如RDD编程指南中所述。
Self-Contained Applications(自包含的应用程序)
·假设我们希望使用Spark API编写一个自包含的应用程序。
·我们将在Scala(使用sbt),Java(使用Maven)和Python(pip)中使用简单的应用程序。
·现在我们将展示如何使用Python API(PySpark)编写应用程序。
·如果要构建打包的PySpark应用程序或库,可以将其添加到setup.py文件中:
install_requires=[
'pyspark=={site.SPARK_VERSION}'
]
作为示例,我们将创建一个简单的Spark应用程序SimpleApp.py:
"""SimpleApp.py"""
from pyspark.sql import SparkSession
logFile = "YOUR_SPARK_HOME/README.md" # Should be some file on your system
spark = SparkSession.builder.appName("SimpleApp").getOrCreate()
logData = spark.read.text(logFile).cache()
numAs = logData.filter(logData.value.contains('a')).count()
numBs = logData.filter(logData.value.contains('b')).count()
print("Lines with a: %i, lines with b: %i" % (numAs, numBs))
spark.stop()
·该程序只计算包含'a'的行数和包含文本文件中'b'的数字。
·请注意,您需要将YOUR_SPARK_HOME替换为安装Spark的位置。
·与Scala和Java示例一样,我们使用SparkSession来创建数据集。
·对于使用自定义类或第三方库的应用程序,我们还可以通过将它们打包到.zip文件中来添加代码依赖关系以通过其--py-files参数进行spark-submit(有关详细信息,请参阅spark-submit --help)。
·SimpleApp非常简单,我们不需要指定任何代码依赖项。
我们可以使用bin / spark-submit脚本运行此应用程序:
# Use spark-submit to run your application $ YOUR_SPARK_HOME/bin/spark-submit \ --master local[4] \ SimpleApp.py ... Lines with a: 46, Lines with b: 23
如果您的环境中安装了PySpark pip(例如,pip install pyspark),您可以使用常规Python解释器运行您的应用程序,或者根据您的喜好使用提供的“spark-submit”。
# Use the Python interpreter to run your application
$ python SimpleApp.py
...
Lines with a: 46, Lines with b: 23RDD Programming Guide(RDD编程指南)
Overview(概观)
·在较高的层次上,每个Spark应用程序都包含一个驱动程序,该程序运行用户的主要功能并在群集上执行各种并行操作。
·Spark提供的主要抽象是弹性分布式数据集(RDD),它是跨群集节点分区的元素的集合,可以并行操作。
·RDD是通过从Hadoop文件系统(或任何其他Hadoop支持的文件系统)中的文件或驱动程序中的现有Scala集合开始并对其进行转换而创建的。
·用户还可以要求Spark在内存中保留RDD,允许它在并行操作中有效地重用。
·最后,RDD会自动从节点故障中恢复。
·Spark中的第二个抽象是可以在并行操作中使用的共享变量。
·默认情况下,当Spark并行运行一个函数作为不同节点上的一组任务时,它会将函数中使用的每个变量的副本发送给每个任务。
·有时,变量需要跨任务共享,或者在任务和驱动程序之间共享。
·Spark支持两种类型的共享变量:广播变量,可用于缓存所有节点的内存中的值;累加器,它们是仅“添加”到的变量,例如计数器和总和。
·本指南以Spark支持的每种语言显示了这些功能。
·如果你启动Spark的交互式shell,最简单的方法就是 - 用于Scala shell的bin / spark-shell或用于Python的bin / pyspark。
Linking with Spark(与Spark链接)
·Spark 2.4.2适用于Python 2.7+或Python 3.4+。
·它可以使用标准的CPython解释器,因此可以使用像NumPy这样的C库。
·它也适用于PyPy 2.3+。
·Spark 2.2.0中删除了Python 2.6支持。
·Python中的Spark应用程序可以使用bin / spark-submit脚本运行,该脚本在运行时包含Spark,也可以将其包含在setup.py中:
install_requires=[
'pyspark=={site.SPARK_VERSION}'
]
·要在不使用pip安装PySpark的情况下在Python中运行Spark应用程序,请使用位于Spark目录中的bin / spark-submit脚本。
·此脚本将加载Spark的Java / Scala库,并允许您将应用程序提交到群集。
·您还可以使用bin / pyspark来启动交互式Python shell。
·如果您希望访问HDFS数据,则需要使用PySpark构建链接到您的HDFS版本。
·Spark主页上还提供了预构建的软件包,可用于常见的HDFS版本。
·最后,您需要将一些Spark类导入到您的程序中。
·添加以下行:
from pyspark import SparkContext, SparkConf·PySpark在驱动程序和工作程序中都需要相同的次要版本的Python。
·它使用PATH中的默认python版本,您可以指定PYSPARK_PYTHON要使用的Python版本,例如:
$ PYSPARK_PYTHON=python3.4 bin/pyspark
$ PYSPARK_PYTHON=/opt/pypy-2.5/bin/pypy bin/spark-submit examples/src/main/python/pi.pyInitializing Spark(初始化Spark)
·Spark程序必须做的第一件事是创建一个SparkContext对象,它告诉Spark如何访问集群。
·要创建SparkContext,首先需要构建一个包含有关应用程序信息的SparkConf对象。
conf = SparkConf().setAppName(appName).setMaster(master)
sc = SparkContext(conf=conf)·appName参数是应用程序在集群UI上显示的名称。
·master是Spark,Mesos或YARN群集URL,或者是以本地模式运行的特殊“本地”字符串。
·实际上,在群集上运行时,您不希望在程序中对master进行硬编码,而是使用spark-submit启动应用程序并在那里接收它。
·但是,对于本地测试和单元测试,您可以传递“local”以在进程中运行Spark。
Using the Shell(使用Shell)
·在PySpark shell中,已经为你创建了一个特殊的解释器感知SparkContext,名为sc。
·制作自己的SparkContext将无法正常工作。
·您可以使用--master参数设置上下文连接到的主服务器,并且可以通过将逗号分隔的列表传递给--py-files将Python .zip,.egg或.py文件添加到运行时路径。
·您还可以通过向--packages参数提供以逗号分隔的Maven坐标列表,将依赖项(例如Spark包)添加到shell会话中。
·任何可能存在依赖关系的其他存储库(例如Sonatype)都可以传递给--repositories参数。
·必要时,必须使用pip手动安装Spark软件包具有的任何Python依赖项(在该软件包的requirements.txt中列出)。
·例如,要在四个核心上运行bin / pyspark,请使用:
$ ./bin/pyspark --master local[4]
或者,要将code.py添加到搜索路径(以便以后能够导入代码),请使用:
$ ./bin/pyspark --master local[4] --py-files code.py·有关选项的完整列表,请运行pyspark --help。
·在幕后,pyspark调用更一般的spark-submit脚本。
·也可以在增强的Python解释器IPython中启动PySpark shell。
·PySpark适用于IPython 1.0.0及更高版本。
·要使用IPython,请在运行bin / pyspark时将PYSPARK_DRIVER_PYTHON变量设置为ipython:
$ PYSPARK_DRIVER_PYTHON=ipython ./bin/pyspark
要使用Jupyter notebook(以前称为IPython notebook)
$ PYSPARK_DRIVER_PYTHON=jupyter PYSPARK_DRIVER_PYTHON_OPTS=notebook ./bin/pyspark·您可以通过设置PYSPARK_DRIVER_PYTHON_OPTS来自定义ipython或jupyter命令。
·启动Jupyter Notebook服务器后,您可以从“文件”选项卡创建一个新的“Python 2”笔记本。
·在笔记本内部,您可以在开始尝试使用Jupyter notebook中的Spark之前输入命令%pylab inline作为笔记本的一部分。
Resilient Distributed Datasets (弹性分布式数据集)(RDDs)
·Spark围绕弹性分布式数据集(RDD)的概念展开,RDD是一个可以并行操作的容错的容错集合。
·创建RDD有两种方法:并行化驱动程序中的现有集合,或引用外部存储系统中的数据集,例如共享文件系统,HDFS,HBase或提供Hadoop InputFormat的任何数据源。
Parallelized Collections(并行化集合)
·通过在驱动程序中的现有可迭代或集合上调用SparkContext的parallelize方法来创建并行化集合。
·复制集合的元素以形成可以并行操作的分布式数据集。
·例如,以下是如何创建包含数字1到5的并行化集合:
data = [1, 2, 3, 4, 5]
distData = sc.parallelize(data)·一旦创建,分布式数据集(distData)可以并行操作。
·例如,我们可以调用distData.reduce(lambda a,b:a + b)来添加列表的元素。
·我们稍后将描述对分布式数据集的操作。
·并行集合的一个重要参数是将数据集切割为的分区数。
·Spark将为群集的每个分区运行一个任务。
·通常,您希望群集中的每个CPU有2-4个分区。
·通常,Spark会尝试根据您的群集自动设置分区数。
·但是,您也可以通过将其作为第二个参数传递给并行化来手动设置它(例如sc.parallelize(data,10))。
·注意:代码中的某些位置使用术语切片(分区的同义词)来保持向后兼容性。
External Datasets(外部数据集)
·PySpark可以从Hadoop支持的任何存储源创建分布式数据集,包括本地文件系统,HDFS,Cassandra,HBase,Amazon S3等.Spark支持文本文件,SequenceFiles和任何其他Hadoop InputFormat。
·可以使用SparkContext的textFile方法创建文本文件RDD。
·此方法获取文件的URI(计算机上的本地路径,或hdfs://,s3a://等URI)并将其作为行集合读取。
·这是一个示例调用:
>>> distFile = sc.textFile("data.txt")·创建后,distFile可以由数据集操作执行。
·例如,我们可以使用map添加所有行的大小,并按如下方式减少操作:distFile.map(lambda s:len(s))。reduce(lambda a,b:a + b)。
·有关使用Spark读取文件的一些注意事项
·如果在本地文件系统上使用路径,则还必须可以在工作节点上的相同路径上访问该文件。
·将文件复制到所有工作者或使用网络安装的共享文件系统。
·Spark的所有基于文件的输入方法(包括textFile)都支持在目录,压缩文件和通配符上运行。
·例如,您可以使用textFile(“/ my / directory”),textFile(“/ my / directory / * .txt”)和textFile(“/ my / directory / * .gz”)。
·textFile方法还采用可选的第二个参数来控制文件的分区数。
·默认情况下,Spark为文件的每个块创建一个分区(HDFS中默认为128MB),但您也可以通过传递更大的值来请求更多的分区。
·请注意,您不能拥有比块少的分区。
·除文本文件外,Spark的Python API还支持其他几种数据格式:
·SparkContext.wholeTextFiles允许您读取包含多个小文本文件的目录,并将它们作为(文件名,内容)对返回。
·这与textFile形成对比,textFile将在每个文件中每行返回一条记录。
·RDD.saveAsPickleFile和SparkContext.pickleFile支持以包含pickle Python对象的简单格式保存RDD。
·批处理用于pickle序列化,默认批处理大小为10。
·SequenceFile和Hadoop输入/输出格式
·请注意,此功能目前标记为“实验”,适用于高级用户。
·将来可能会使用基于Spark SQL的读/写支持替换它,在这种情况下,Spark SQL是首选方法。
·可写支持
·PySpark SequenceFile支持在Java中加载键值对的RDD,将Writable转换为基本Java类型,并使用Pyrolite挖掘生成的Java对象。
·将键值对的RDD保存到SequenceFile时,PySpark会反过来。
·它将Python对象解开为Java对象,然后将它们转换为Writable。
·以下Writable会自动转换:
| Writable Type(可写类型) | Python Type |
|---|---|
| Text | unicode str |
| IntWritable | int |
| FloatWritable | float |
| DoubleWritable | float |
| BooleanWritable | bool |
| BytesWritable | bytearray |
| NullWritable | None |
| MapWritable | dict |
·数组不是开箱即用的。
·用户在读取或写入时需要指定自定义ArrayWritable子类型。
·编写时,用户还需要指定将数组转换为自定义ArrayWritable子类型的自定义转换器。
·在读取时,默认转换器将自定义ArrayWritable子类型转换为Java Object [],然后将其pickle到Python元组。
·要为原始类型的数组获取Python array.array,用户需要指定自定义转换器。
Saving and Loading SequenceFiles(保存和加载SequenceFiles)
·与文本文件类似,可以通过指定路径来保存和加载SequenceFiles。
·可以指定键和值类,但对于标准Writable,这不是必需的。
$ ./bin/pyspark --jars /path/to/elasticsearch-hadoop.jar
>>> conf = {"es.resource" : "index/type"} # assume Elasticsearch is running on localhost defaults
>>> rdd = sc.newAPIHadoopRDD("org.elasticsearch.hadoop.mr.EsInputFormat",
"org.apache.hadoop.io.NullWritable",
"org.elasticsearch.hadoop.mr.LinkedMapWritable",
conf=conf)
>>> rdd.first() # the result is a MapWritable that is converted to a Python dict
(u'Elasticsearch ID',
{u'field1': True,
u'field2': u'Some Text',
u'field3': 12345})·请注意,如果InputFormat仅依赖于Hadoop配置和/或输入路径,并且可以根据上表轻松转换键和值类,则此方法应适用于此类情况。
·如果您有自定义序列化二进制数据(例如从Cassandra / HBase加载数据),那么您首先需要将Scala / Java端的数据转换为可由Pyrolite的pickler处理的数据。
·为此提供了转换器特性。
·只需扩展此特征并在convert方法中实现转换代码。
·请记住确保将此类以及访问InputFormat所需的任何依赖项打包到Spark作业jar中并包含在PySpark类路径中。
·有关使用Cassandra / HBase InputFormat和OutputFormat以及自定义转换器的示例,请参阅Python示例和Converter示例。
RDD Operations(RDD操作)
·RDD支持两种类型的操作:转换(从现有数据集创建新数据集)和操作(在数据集上运行计算后将值返回到驱动程序)。
·例如,map是一个转换,它通过一个函数传递每个数据集元素,并返回一个表示结果的新RDD。
·另一方面,reduce是一个使用某个函数聚合RDD的所有元素的操作,并将最终结果返回给驱动程序(尽管还有一个返回分布式数据集的并行reduceByKey)。
·Spark中的所有转换都是惰性的,因为它们不会立即计算结果。
·相反,他们只记得应用于某些基础数据集(例如文件)的转换。
·仅当操作需要将结果返回到驱动程序时才会计算转换。
·这种设计使Spark能够更有效地运行。
·例如,我们可以意识到通过map创建的数据集将用于reduce,并且仅将reduce的结果返回给驱动程序,而不是更大的映射数据集。
·默认情况下,每次对其执行操作时,都可以重新计算每个转换后的RDD。
·但是,您也可以使用持久化(或缓存)方法在内存中保留RDD,在这种情况下,Spark会在群集上保留元素,以便在下次查询时更快地访问。
·还支持在磁盘上保留RDD或在多个节点上复制。
Basics(基本)
为了说明RDD基础知识,请考虑以下简单程序:
lines = sc.textFile("data.txt")
lineLengths = lines.map(lambda s: len(s))
totalLength = lineLengths.reduce(lambda a, b: a + b)·第一行定义来自外部文件的基本RDD。
·此数据集未加载到内存中或以其他方式执行:行仅仅是指向文件的指针。
·第二行将lineLengths定义为地图转换的结果。
·同样,由于懒惰,lineLengths不会立即计算。
·最后,我们运行reduce,这是一个动作。
·此时,Spark将计算分解为在不同机器上运行的任务,并且每台机器都运行其部分映射和本地缩减,仅返回其对驱动程序的答案。
·如果我们以后想再次使用lineLengths,我们可以添加:
lineLengths.persist()
在reduce之前,这将导致lineLengths在第一次计算之后保存在内存中。
Passing Functions to Spark(将函数传递给Spark)
·Spark的API在很大程度上依赖于在驱动程序中传递函数以在集群上运行。
·有三种建议的方法可以做到这一点:
·Lambda表达式,用于可以作为表达式编写的简单函数。
·(Lambdas不支持多语句函数或不返回值的语句。)
·调用Spark的函数内部的本地defs,用于更长的代码。
·模块中的顶级函数。
·例如,要传递比使用lambda支持的更长的函数,请考虑以下代码:
"""MyScript.py"""
if __name__ == "__main__":
def myFunc(s):
words = s.split(" ")
return len(words)
sc = SparkContext(...)
sc.textFile("file.txt").map(myFunc)·请注意,虽然也可以将引用传递给类实例中的方法(而不是单例对象),但这需要发送包含该类的对象以及方法。
·例如,考虑:
class MyClass(object):
def func(self, s):
return s
def doStuff(self, rdd):
return rdd.map(self.func)·在这里,如果我们创建一个新的MyClass并在其上调用doStuff,那里的map会引用该MyClass实例的func方法,因此需要将整个对象发送到集群。
·以类似的方式,访问外部对象的字段将引用整个对象:
class MyClass(object):
def __init__(self):
self.field = "Hello"
def doStuff(self, rdd):
return rdd.map(lambda s: self.field + s)要避免此问题,最简单的方法是将字段复制到局部变量中,而不是从外部访问它:
def doStuff(self, rdd):
field = self.field
return rdd.map(lambda s: field + s)Understanding closures(理解闭包)
·Spark的一个难点是在跨集群执行代码时理解变量和方法的范围和生命周期。
·修改其范围之外的变量的RDD操作可能经常引起混淆。
·在下面的示例中,我们将查看使用foreach()递增计数器的代码,但同样的问题也可能发生在其他操作中。
Example
·考虑下面的天真RDD元素总和,根据执行是否在同一JVM中发生,它可能表现不同。
·一个常见的例子是在本地模式下运行Spark(--master = local [n])而不是将Spark应用程序部署到集群(例如通过spark-submit to YARN):
counter = 0
rdd = sc.parallelize(data)
# Wrong: Don't do this!!
def increment_counter(x):
global counter
counter += x
rdd.foreach(increment_counter)
print("Counter value: ", counter)Local vs. cluster modes(本地与群集模式)
·上述代码的行为未定义,可能无法按预期工作。
·为了执行作业,Spark将RDD操作的处理分解为任务,每个任务都由执行程序执行。
·在执行之前,Spark计算任务的闭包。
·闭包是那些变量和方法,它们必须是可见的,以便执行程序在RDD上执行其计算(在本例中为foreach())。
·该闭包被序列化并发送给每个执行者。
·发送给每个执行程序的闭包内的变量现在是副本,因此,当在foreach函数中引用计数器时,它不再是驱动程序节点上的计数器。
·驱动程序节点的内存中仍然有一个计数器,但执行程序不再可见!
·执行程序只能看到序列化闭包中的副本。
·因此,计数器的最终值仍然为零,因为计数器上的所有操作都引用了序列化闭包内的值。
·在本地模式下,在某些情况下,foreach函数实际上将在与驱动程序相同的JVM中执行,并将引用相同的原始计数器,并且可能实际更新它。
·为了确保在这些场景中定义良好的行为,应该使用累加器。
·Spark中的累加器专门用于提供一种机制,用于在跨集群中的工作节点拆分执行时安全地更新变量。
·本指南的“累加器”部分更详细地讨论了这些内容。
·通常,闭包 - 类似循环或本地定义的方法的构造不应该用于改变某些全局状态。
·Spark没有定义或保证从闭包外部引用的对象的突变行为。
·执行此操作的某些代码可能在本地模式下工作,但这只是偶然的,并且此类代码在分布式模式下不会按预期运行。
·如果需要某些全局聚合,请使用累加器。
Printing elements of an RDD(打印RDD的元素)
·另一个常见的习惯用法是尝试使用rdd.foreach(println)或rdd.map(println)打印出RDD的元素。
·在一台机器上,这将生成预期的输出并打印所有RDD的元素。
·但是,在集群模式下,执行程序调用的stdout输出现在写入执行程序的stdout,而不是驱动程序上的那个,因此驱动程序上的stdout不会显示这些!
·要打印驱动程序上的所有元素,可以使用collect()方法首先将RDD带到驱动程序节点:rdd.collect()。foreach(println)。
·但是,这会导致驱动程序内存不足,因为collect()会将整个RDD提取到一台机器上;
·如果你只需要打印RDD的一些元素,更安全的方法是使用take():rdd.take(100).foreach(println)。
Working with Key-Value Pairs(使用键值对)
·虽然大多数Spark操作都适用于包含任何类型对象的RDD,但一些特殊操作仅适用于键值对的RDD。
·最常见的是分布式“随机”操作,例如通过密钥对元素进行分组或聚合。
·在Python中,这些操作适用于包含内置Python元组的RDD,如(1,2)。
·只需创建这样的元组,然后调用您想要的操作。
·例如,以下代码对键值对使用reduceByKey操作来计算文件中每行文本出现的次数:
lines = sc.textFile("data.txt") pairs = lines.map(lambda s: (s, 1)) counts = pairs.reduceByKey(lambda a, b: a + b)
例如,我们也可以使用counts.sortByKey()来按字母顺序对这些对进行排序,最后使用counts.collect()将它们作为对象列表返回到驱动程序。
Transformations(转换)
·下表列出了Spark支持的一些常见转换。
·有关详细信息,请参阅RDD API文档(Scala,Java,Python,R)并配对RDD函数doc(Scala,Java)。
·转型意义
·map(func)返回通过函数func传递源的每个元素形成的新分布式数据集。
·filter(func)返回通过选择func返回true的源元素形成的新数据集。
·flatMap(func)与map类似,但每个输入项可以映射到0个或更多输出项(因此func应返回Seq而不是单个项)。
·mapPartitions(func)与map类似,但在RDD的每个分区(块)上单独运行,因此当在类型T的RDD上运行时,func必须是Iterator => Iterator 类型。
·mapPartitionsWithIndex(func)与mapPartitions类似,但也为func提供了一个表示分区索引的整数值,因此当在RDD类型上运行时,func必须是类型(Int,Iterator )=> Iterator
·T.
·sample(withReplacement,fraction,seed)使用给定的随机数生成器种子,使用或不使用替换对数据的一小部分进行采样。
·union(otherDataset)返回一个新数据集,其中包含源数据集和参数中元素的并集。
·intersection(otherDataset)返回包含源数据集和参数中元素交集的新RDD。
·distinct([numPartitions]))返回包含源数据集的不同元素的新数据集。
·groupByKey([numPartitions])在(K,V)对的数据集上调用时,返回(K,Iterable )对的数据集。
·注意:如果要对每个键执行聚合(例如总和或平均值)进行分组,则使用reduceByKey或aggregateByKey将产生更好的性能。
·注意:默认情况下,输出中的并行级别取决于父RDD的分区数。
·您可以传递可选的numPartitions参数来设置不同数量的任务。
·reduceByKey(func,[numPartitions])当在(K,V)对的数据集上调用时,返回(K,V)对的数据集,其中使用给定的reduce函数func聚合每个键的值,该函数必须是
·type(V,V)=> V.与groupByKey类似,reduce任务的数量可通过可选的第二个参数进行配置。
·aggregateByKey(zeroValue)(seqOp,combOp,[numPartitions])在(K,V)对的数据集上调用时,返回(K,U)对的数据集,其中使用给定的组合函数聚合每个键的值,
·中性的“零”值。
·允许与输入值类型不同的聚合值类型,同时避免不必要的分配。
·与groupByKey类似,reduce任务的数量可通过可选的第二个参数进行配置。
·sortByKey([ascending],[numPartitions])在K实现Ordered的(K,V)对的数据集上调用时,返回按键按升序或降序排序的(K,V)对数据集,如
·布尔升序参数。
·join(otherDataset,[numPartitions])当调用类型为(K,V)和(K,W)的数据集时,返回(K,(V,W))对的数据集以及每个键的所有元素对。
·通过leftOuterJoin,rightOuterJoin和fullOuterJoin支持外连接。
·cogroup(otherDataset,[numPartitions])当调用类型为(K,V)和(K,W)的数据集时,返回(K,(Iterable ,Iterable ))元组的数据集。
·此操作也称为groupWith。
·cartesian(otherDataset)当调用类型为T和U的数据集时,返回(T,U)对的数据集(所有元素对)。
·pipe(command,[envVars])通过shell命令管道RDD的每个分区,例如:
·一个Perl或bash脚本。
·RDD元素被写入进程的stdin,并且输出到其stdout的行将作为字符串的RDD返回。
·coalesce(numPartitions)将RDD中的分区数减少为numPartitions。
·过滤大型数据集后,可以更有效地运行操作。
·repartition(numPartitions)随机重新调整RDD中的数据以创建更多或更少的分区并在它们之间进行平衡。
·这总是随机播放网络上的所有数据。
·repartitionAndSortWithinPartitions(partitioner)根据给定的分区程序重新分区RDD,并在每个生成的分区中按键对记录进行排序。
·这比调用重新分区然后在每个分区内排序更有效,因为它可以将排序推送到shuffle机器中。
Actions(动作)
·下表列出了Spark支持的一些常见操作。
·请参阅RDD API文档(Scala,Java,Python,R)
·并配对RDD函数doc(Scala,Java)以获取详细信息。
·行动意义
·reduce(func)使用函数func(它接受两个参数并返回一个)来聚合数据集的元素。
·该函数应该是可交换的和关联的,以便可以并行正确计算。
·collect()在驱动程序中将数据集的所有元素作为数组返回。
·在过滤器或其他返回足够小的数据子集的操作之后,这通常很有用。
·count()返回数据集中的元素数。
·first()返回数据集的第一个元素(类似于take(1))。
·take(n)返回包含数据集的前n个元素的数组。
·takeSample(withReplacement,num,[seed])返回一个数组,其中包含数据集的num个元素的随机样本,有或没有替换,可选地预先指定随机数生成器种子。
·takeOrdered(n,[ordering])使用自然顺序或自定义比较器返回RDD的前n个元素。
·saveAsTextFile(path)将数据集的元素写为本地文件系统,HDFS或任何其他Hadoop支持的文件系统中给定目录中的文本文件(或文本文件集)。
·Spark将在每个元素上调用toString,将其转换为文件中的一行文本。
·saveAsSequenceFile(路径)
·(Java和Scala)将数据集的元素作为Hadoop SequenceFile写入本地文件系统,HDFS或任何其他Hadoop支持的文件系统中的给定路径中。
·这可以在实现Hadoop的Writable接口的键值对的RDD上使用。
·在Scala中,它也可以在可隐式转换为Writable的类型上使用(Spark包括基本类型的转换,如Int,Double,String等)。
·saveAsObjectFile(路径)
·(Java和Scala)使用Java序列化以简单格式编写数据集的元素,然后可以使用SparkContext.objectFile()加载它。
·countByKey()仅适用于类型为(K,V)的RDD。
·返回(K,Int)对的散列映射,其中包含每个键的计数。
·foreach(func)对数据集的每个元素运行函数func。
·这通常用于副作用,例如更新累加器或与外部存储系统交互。
·注意:在foreach()之外修改除累加器之外的变量可能会导致未定义的行为。
·有关详细信息,请参阅了解闭包。
·Spark RDD API还公开了某些操作的异步版本,例如foreach的foreachAsync,它会立即将一个FutureAction返回给调用者,而不是在完成操作时阻塞。
·这可用于管理或等待操作的异步执行。
Shuffle operations(随机操作)
·Spark中的某些操作会触发称为shuffle的事件。
·随机播放是Spark的重新分配数据的机制,因此它可以跨分区进行不同的分组。
·这通常涉及跨执行程序和机器复制数据,使得混洗成为复杂且昂贵的操作。
Background(背景)
·为了理解在shuffle期间发生的事情,我们可以考虑reduceByKey操作的示例。
·reduceByKey操作生成一个新的RDD,其中单个键的所有值都组合成一个元组 - 键和对与该键关联的所有值执行reduce函数的结果。
·挑战在于,并非单个密钥的所有值都必须位于同一个分区,甚至是同一个机器上,但它们必须位于同一位置才能计算结果。
·在Spark中,数据通常不跨分区分布,以便在特定操作的必要位置。
·在计算过程中,单个任务将在单个分区上运行 - 因此,要组织单个reduceByKey reduce任务执行的所有数据,Spark需要执行全部操作。
·它必须从所有分区读取以查找所有键的所有值,然后将分区中的值汇总在一起以计算每个键的最终结果 - 这称为shuffle。
·尽管新洗牌数据的每个分区中的元素集将是确定性的,并且分区本身的排序也是如此,但这些元素的排序不是。
·如果在随机播放后需要可预测的有序数据,则可以使用:
·mapPartitions使用例如.sorted对每个分区进行排序
·repartitionAndSortWithinPartitions在同时重新分区的同时有效地对分区进行排序
·sortBy来创建一个全局排序的RDD
·可以导致混洗的操作包括重新分区操作,如重新分区和合并,“ByKey操作(计数除外),如groupByKey和reduceByKey,以及联合操作,如cogroup和join。
Performance Impact(绩效影响)
·Shuffle是一项昂贵的操作,因为它涉及磁盘I / O,数据序列化和网络I / O.
·为了组织shuffle的数据,Spark生成了一系列任务 - 映射任务以组织数据,以及一组reduce任务来聚合它。
·这个术语来自MapReduce,并不直接与Spark的地图和减少操作相关。
·在内部,各个地图任务的结果会保留在内存中,直到它们无法适应。
·然后,这些基于目标分区进行排序并写入单个文件。
·在reduce方面,任务读取相关的排序块。
·某些shuffle操作会消耗大量的堆内存,因为它们使用内存中的数据结构来在传输记录之前或之后组织记录。
·具体来说,reduceByKey和aggregateByKey在地图侧创建这些结构,并且'ByKey操作在reduce侧生成这些结构。
·当数据不适合内存时,Spark会将这些表溢出到磁盘,从而导致磁盘I / O的额外开销和垃圾收集增加。
·Shuffle还会在磁盘上生成大量中间文件。
·从Spark 1.3开始,这些文件将被保留,直到不再使用相应的RDD并进行垃圾回收。
·这样做是为了在重新计算谱系时不需要重新创建shuffle文件。
·如果应用程序保留对这些RDD的引用或GC不经常启动,则垃圾收集可能仅在很长一段时间后才会发生。
·这意味着长时间运行的Spark作业可能会占用大量磁盘空间。
·配置Spark上下文时,spark.local.dir配置参数指定临时存储目录。
·可以通过调整各种配置参数来调整随机行为。
·请参阅“Spark配置指南”中的“随机行为”部分。
RDD Persistence(RDD持久性)
·Spark中最重要的功能之一是跨操作在内存中持久化(或缓存)数据集。
·当您持久保存RDD时,每个节点都会存储它在内存中计算的任何分区,并在该数据集(或从中派生的数据集)的其他操作中重用它们。
·这使得未来的行动更快(通常超过10倍)。
·缓存是迭代算法和快速交互式使用的关键工具。
·您可以使用persist()或cache()方法标记要保留的RDD。
·第一次在动作中计算它,它将保留在节点的内存中。
·Spark的缓存是容错的 - 如果丢失了RDD的任何分区,它将使用最初创建它的转换自动重新计算。
·此外,每个持久化RDD可以使用不同的存储级别进行存储,例如,允许您将数据集保留在磁盘上,将其保留在内存中,但作为序列化Java对象(以节省空间),跨节点复制它。
·通过将StorageLevel对象(Scala,Java,Python)传递给persist()来设置这些级别。
·cache()方法是使用默认存储级别的简写,即StorageLevel.MEMORY_ONLY(在内存中存储反序列化的对象)。
·完整的存储级别是:
·存储级别含义
·MEMORY_ONLY将RDD存储为JVM中的反序列化Java对象。
·如果RDD不适合内存,则某些分区将不会被缓存,并且每次需要时都会重新计算。
·这是默认级别。
·MEMORY_AND_DISK将RDD存储为JVM中的反序列化Java对象。
·如果RDD不适合内存,请存储不适合磁盘的分区,并在需要时从那里读取它们。
·MEMORY_ONLY_SER
·(Java和Scala)将RDD存储为序列化Java对象(每个分区一个字节数组)。
·这通常比反序列化对象更节省空间,特别是在使用快速序列化器时,但读取CPU密集程度更高。
·MEMORY_AND_DISK_SER
·(Java和Scala)与MEMORY_ONLY_SER类似,但是将不适合内存的分区溢出到磁盘,而不是每次需要时动态重新计算它们。
·DISK_ONLY仅将RDD分区存储在磁盘上。
·MEMORY_ONLY_2,MEMORY_AND_DISK_2等。与上面的级别相同,但复制两个群集节点上的每个分区。
·OFF_HEAP(实验)与MEMORY_ONLY_SER类似,但将数据存储在堆外内存中。
·这需要启用堆外内存。
·注意:在Python中,存储的对象将始终使用Pickle库进行序列化,因此您是否选择序列化级别并不重要。
·Python中的可用存储级别包括MEMORY_ONLY,MEMORY_ONLY_2,MEMORY_AND_DISK,MEMORY_AND_DISK_2,DISK_ONLY和DISK_ONLY_2。
·即使没有用户调用持久性,Spark也会在随机操作(例如reduceByKey)中自动保留一些中间数据。
·这样做是为了避免在shuffle期间节点发生故障时重新计算整个输入。
·我们仍然建议用户在生成的RDD上调用persist,如果他们计划重用它。
Which Storage Level to Choose?(选择哪种存储级别?)
·Spark的存储级别旨在提供内存使用和CPU效率之间的不同折衷。
·我们建议您通过以下流程选择一个:
·如果您的RDD与默认存储级别(MEMORY_ONLY)很舒适,请保持这种状态。
·这是CPU效率最高的选项,允许RDD上的操作尽可能快地运行。
·如果没有,请尝试使用MEMORY_ONLY_SER并选择快速序列化库,以使对象更节省空间,但仍然可以快速访问。
·(Java和Scala)
·除非计算数据集的函数很昂贵,否则它们不会溢出到磁盘,或者它们会过滤大量数据。
·否则,重新计算分区可能与从磁盘读取分区一样快。
·如果要快速故障恢复,请使用复制的存储级别(例如,如果使用Spark来处理来自Web应用程序的请求)。
·所有存储级别通过重新计算丢失的数据提供完全容错,但复制的存储级别允许您继续在RDD上运行任务,而无需等待重新计算丢失的分区。
Removing Data(删除数据)
·Spark会自动监视每个节点上的缓存使用情况,并以最近最少使用(LRU)的方式删除旧数据分区。
·如果您想手动删除RDD而不是等待它退出缓存,请使用RDD.unpersist()方法。
Shared Variables(共享变量)
·通常,当在远程集群节点上执行传递给Spark操作(例如map或reduce)的函数时,它将在函数中使用的所有变量的单独副本上工作。
·这些变量将复制到每台计算机,并且远程计算机上的变量的更新不会传播回驱动程序。
·支持跨任务的通用,读写共享变量效率低下。
·但是,Spark确实为两种常见的使用模式提供了两种有限类型的共享变量:广播变量和累加器。
Broadcast Variables(广播变量)
·广播变量允许程序员在每台机器上保留一个只读变量,而不是随副本一起发送它的副本。
·例如,它们可用于以有效的方式为每个节点提供大输入数据集的副本。
·Spark还尝试使用有效的广播算法来分发广播变量,以降低通信成本。
·Spark动作通过一组阶段执行,由分布式“shuffle”操作分隔。
·Spark自动广播每个阶段中任务所需的公共数据。
·以这种方式广播的数据以序列化形式缓存并在运行每个任务之前反序列化。
·这意味着显式创建广播变量仅在跨多个阶段的任务需要相同数据或以反序列化形式缓存数据很重要时才有用。
·通过调用SparkContext.broadcast(v)从变量v创建广播变量。
·广播变量是v的包装器,可以通过调用value方法访问其值。
·下面的代码显示了这个:
>>> broadcastVar = sc.broadcast([1, 2, 3])
<pyspark.broadcast.Broadcast object at 0x102789f10>
>>> broadcastVar.value
[1, 2, 3]·创建广播变量后,应该在群集上运行的任何函数中使用它而不是值v,这样v不会多次传送到节点。
·另外,在广播之后不应修改对象v,以便确保所有节点获得广播变量的相同值(例如,如果稍后将变量发送到新节点)。
Accumulators(累加器)
·累加器是仅通过关联和交换操作“添加”的变量,因此可以并行有效地支持。
·它们可用于实现计数器(如MapReduce)或总和。
·Spark本身支持数值类型的累加器,程序员可以添加对新类型的支持。
·作为用户,您可以创建命名或未命名的累加器。
·如下图所示,命名累加器(在此实例计数器中)将显示在Web UI中,用于修改该累加器的阶段。
·Spark显示“任务”表中任务修改的每个累加器的值。
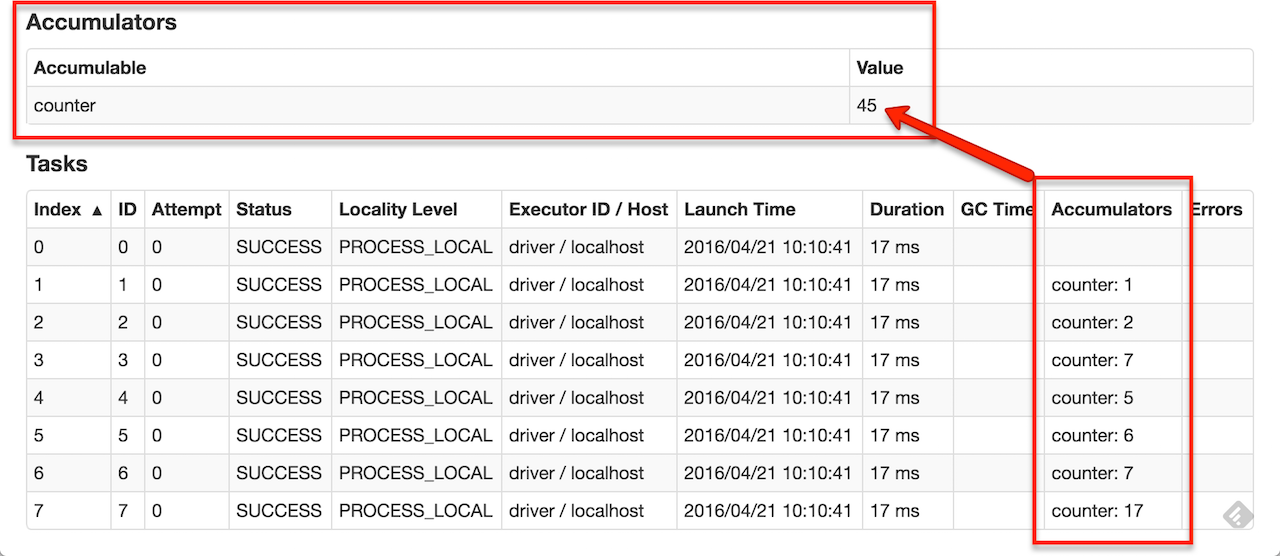
跟踪UI中的累加器对于理解运行阶段的进度非常有用(注意:Python中尚不支持)。
·通过调用SparkContext.accumulator(v)从初始值v创建累加器。
·然后,可以使用add方法或+ =运算符将在群集上运行的任务添加到其中。
·但是,他们无法读懂它的价值。
·只有驱动程序可以使用其value方法读取累加器的值。
·下面的代码显示了一个累加器用于添加数组的元素:
>>> accum = sc.accumulator(0)
>>> accum
Accumulator<id=0, value=0>
>>> sc.parallelize([1, 2, 3, 4]).foreach(lambda x: accum.add(x))
...
10/09/29 18:41:08 INFO SparkContext: Tasks finished in 0.317106 s
>>> accum.value
10·虽然此代码使用Int类型的累加器的内置支持,但程序员也可以通过继承AccumulatorParam来创建自己的类型。
·AccumulatorParam接口有两种方法:零用于为数据类型提供“零值”,addInPlace用于将两个值一起添加。
·例如,假设我们有一个表示数学向量的Vector类,我们可以写:
class VectorAccumulatorParam(AccumulatorParam):
def zero(self, initialValue):
return Vector.zeros(initialValue.size)
def addInPlace(self, v1, v2):
v1 += v2
return v1
# Then, create an Accumulator of this type:
vecAccum = sc.accumulator(Vector(...), VectorAccumulatorParam())·对于仅在操作内执行的累加器更新,Spark保证每个任务对累加器的更新仅应用一次,即重新启动的任务不会更新该值。
·在转换中,用户应该知道,如果重新执行任务或作业阶段,则可以多次应用每个任务的更新。
·累加器不会改变Spark的惰性评估模型。
·如果在RDD上的操作中更新它们,则只有在RDD作为操作的一部分计算时才更新它们的值。
·因此,在像map()这样的惰性转换中进行累积器更新时,不能保证执行累加器更新。
·以下代码片段演示了此属性:
accum = sc.accumulator(0)
def g(x):
accum.add(x)
return f(x)
data.map(g)
# Here, accum is still 0 because no actions have caused the `map` to be computed.Deploying to a Cluster(部署到群集)
·应用程序提交指南介绍了如何将应用程序提交到群集。
·简而言之,一旦将应用程序打包到JAR(用于Java / Scala)或一组.py或.zip文件(用于Python),bin / spark-submit脚本允许您将其提交给任何支持的集群管理器。
Launching Spark jobs from Java / Scala(从Java / Scala启动Spark作业)
org.apache.spark.launcher包提供了使用简单Java API将Spark作业作为子进程启动的类。
Unit Testing(单元测试)
·Spark对任何流行的单元测试框架进行单元测试都很友好。
·只需在测试中创建一个SparkContext,主URL设置为local,运行您的操作,然后调用SparkContext.stop()将其拆除。
·确保在finally块或测试框架的tearDown方法中停止上下文,因为Spark不支持在同一程序中同时运行的两个上下文。
Where to Go from Here(从这往哪儿走)
You can see some example Spark programs on the Spark website. In addition, Spark includes several samples in the examples directory (Scala,Java, Python, R). You can run Java and Scala examples by passing the class name to Spark’s bin/run-example script; for instance:
./bin/run-example SparkPi
对于Python示例,请使用spark-submit代替:
./bin/spark-submit examples/src/main/python/pi.py
Spark SQL, DataFrames and Datasets Guide
·Spark SQL是用于结构化数据处理的Spark模块。
·与基本的Spark RDD API不同,Spark SQL提供的接口为Spark提供了有关数据结构和正在执行的计算的更多信息。
·在内部,Spark SQL使用此额外信息来执行额外的优化。
·有几种与Spark SQL交互的方法,包括SQL和Dataset API。
·在计算结果时,使用相同的执行引擎,与您用于表达计算的API /语言无关。
·这种统一意味着开发人员可以轻松地在不同的API之间来回切换,从而提供表达给定转换的最自然的方式。
·此页面上的所有示例都使用Spark分发中包含的示例数据,并且可以在spark-shell,pyspark shell或sparkR shell中运行。
SQL
·Spark SQL的一个用途是执行SQL查询。
·Spark SQL还可用于从现有Hive安装中读取数据。
·有关如何配置此功能的更多信息,请参阅Hive Tables部分。
·从其他编程语言中运行SQL时,结果将作为数据集/数据框返回。
·您还可以使用命令行或JDBC / ODBC与SQL接口进行交互。
Datasets and DataFrames
·数据集是分布式数据集合。
·数据集是Spark 1.6中添加的一个新接口,它提供了RDD的优势(强类型,使用强大的lambda函数的能力)和Spark SQL优化执行引擎的优点。
·数据集可以从JVM对象构造,然后使用功能转换(map,flatMap,filter等)进行操作。
·数据集API在Scala和Java中可用。
·Python没有对Dataset API的支持。
·但由于Python的动态特性,数据集API的许多好处已经可用(即您可以通过名称自然地访问行的字段row.columnName)。
·R的情况类似。
·DataFrame是一个组织成命名列的数据集。
·它在概念上等同于关系数据库中的表或R / Python中的数据框,但在底层具有更丰富的优化。
·DataFrame可以从多种来源构建,例如:结构化数据文件,Hive中的表,外部数据库或现有RDD。
·DataFrame API在Scala,Java,Python和R中可用。在Scala和Java中,DataFrame由行数据集表示。
·在Scala API中,DataFrame只是Dataset [Row]的类型别名。
·而在Java API中,用户需要使用Dataset 来表示DataFrame。
·在本文档中,我们经常将行的Scala / Java数据集称为DataFrame。
Getting Started(入门)
Starting Point: SparkSession(起点:SparkSession)
·Spark中所有功能的入口点是SparkSession类。
·要创建基本的SparkSession,只需使用SparkSession.builder:
from pyspark.sql import SparkSession
spark = SparkSession \
.builder \
.appName("Python Spark SQL basic example") \
.config("spark.some.config.option", "some-value") \
.getOrCreate()
·在Spark repo中的“examples / src / main / python / sql / basic.py”中找到完整的示例代码。
·Spark 2.0中的SparkSession为Hive功能提供内置支持,包括使用HiveQL编写查询,访问Hive UDF以及从Hive表读取数据的功能。
·要使用这些功能,您无需拥有现有的Hive设置。
Creating DataFrames(创建DataFrame)
·使用SparkSession,应用程序可以从现有RDD,Hive表或Spark数据源创建DataFrame。
·作为示例,以下内容基于JSON文件的内容创建DataFrame:
# spark is an existing SparkSession
df = spark.read.json("examples/src/main/resources/people.json")
# Displays the content of the DataFrame to stdout
df.show()
# +----+-------+
# | age| name|
# +----+-------+
# |null|Michael|
# | 30| Andy|
# | 19| Justin|
# +----+-------+
Find full example code at "examples/src/main/python/sql/basic.py" in the Spark repo.
Untyped Dataset Operations (aka DataFrame Operations)无类型数据集操作(又名DataFrame操作)
·DataFrames为Scala,Java,Python和R中的结构化数据操作提供特定于域的语言。
·如上所述,在Spark 2.0中,DataFrames只是Scala和Java API中Rows的数据集。
·与“类型转换”相比,这些操作也称为“无类型转换”,带有强类型Scala / Java数据集。
·这里我们包括使用数据集进行结构化数据处理的一些基本示例:
·在Python中,可以通过属性(df.age)或索引(df ['age'])访问DataFrame的列。
·虽然前者便于交互式数据探索,但强烈建议用户使用后一种形式,这是未来的证明,不会破坏也是DataFrame类属性的列名。
# spark, df are from the previous example
# Print the schema in a tree format
df.printSchema()
# root
# |-- age: long (nullable = true)
# |-- name: string (nullable = true)
# Select only the "name" column
df.select("name").show()
# +-------+
# | name|
# +-------+
# |Michael|
# | Andy|
# | Justin|
# +-------+
# Select everybody, but increment the age by 1
df.select(df['name'], df['age'] + 1).show()
# +-------+---------+
# | name|(age + 1)|
# +-------+---------+
# |Michael| null|
# | Andy| 31|
# | Justin| 20|
# +-------+---------+
# Select people older than 21
df.filter(df['age'] > 21).show()
# +---+----+
# |age|name|
# +---+----+
# | 30|Andy|
# +---+----+
# Count people by age
df.groupBy("age").count().show()
# +----+-----+
# | age|count|
# +----+-----+
# | 19| 1|
# |null| 1|
# | 30| 1|
# +----+-----+
·在Spark repo中的“examples / src / main / python / sql / basic.py”中找到完整的示例代码。
·有关可在DataFrame上执行的操作类型的完整列表,请参阅API文档。
·除了简单的列引用和表达式之外,DataFrame还具有丰富的函数库,包括字符串操作,日期算术,常见的数学运算等。
·完整列表可在DataFrame函数参考中找到。
Running SQL Queries Programmatically(以编程方式运行SQL查询)
SparkSession上的sql函数使应用程序能够以编程方式运行SQL查询并将结果作为DataFrame返回。
# Register the DataFrame as a SQL temporary view
df.createOrReplaceTempView("people")
sqlDF = spark.sql("SELECT * FROM people")
sqlDF.show()
# +----+-------+
# | age| name|
# +----+-------+
# |null|Michael|
# | 30| Andy|
# | 19| Justin|
# +----+-------+
Find full example code at "examples/src/main/python/sql/basic.py" in the Spark repo.
Global Temporary View(全球临时观点)
·Spark SQL中的临时视图是会话范围的,如果创建它的会话终止,它将消失。
·如果您希望拥有一个在所有会话之间共享的临时视图并保持活动状态,直到Spark应用程序终止,您可以创建一个全局临时视图。
·全局临时视图与系统保留的数据库global_temp绑定,我们必须使用限定名称来引用它,例如
·SELECT * FROM global_temp.view1。
# Register the DataFrame as a global temporary view
df.createGlobalTempView("people")
# Global temporary view is tied to a system preserved database `global_temp`
spark.sql("SELECT * FROM global_temp.people").show()
# +----+-------+
# | age| name|
# +----+-------+
# |null|Michael|
# | 30| Andy|
# | 19| Justin|
# +----+-------+
# Global temporary view is cross-session
spark.newSession().sql("SELECT * FROM global_temp.people").show()
# +----+-------+
# | age| name|
# +----+-------+
# |null|Michael|
# | 30| Andy|
# | 19| Justin|
# +----+-------+
Find full example code at "examples/src/main/python/sql/basic.py" in the Spark repo.
Creating Datasets(创建数据集)
·数据集与RDD类似,但是,它们不使用Java序列化或Kryo,而是使用专用的编码器来序列化对象以便通过网络进行处理或传输。
·虽然编码器和标准序列化都负责将对象转换为字节,但编码器是动态生成的代码,并使用一种格式,允许Spark执行许多操作,如过滤,排序和散列,而无需将字节反序列化为对象。
case class Person(name: String, age: Long)
// Encoders are created for case classes
val caseClassDS = Seq(Person("Andy", 32)).toDS()
caseClassDS.show()
// +----+---+
// |name|age|
// +----+---+
// |Andy| 32|
// +----+---+
// Encoders for most common types are automatically provided by importing spark.implicits._
val primitiveDS = Seq(1, 2, 3).toDS()
primitiveDS.map(_ + 1).collect() // Returns: Array(2, 3, 4)
// DataFrames can be converted to a Dataset by providing a class. Mapping will be done by name
val path = "examples/src/main/resources/people.json"
val peopleDS = spark.read.json(path).as[Person]
peopleDS.show()
// +----+-------+
// | age| name|
// +----+-------+
// |null|Michael|
// | 30| Andy|
// | 19| Justin|
// +----+-------+
Find full example code at "examples/src/main/scala/org/apache/spark/examples/sql/SparkSQLExample.scala" in the Spark repo.
Interoperating with RDDs(与RDD互操作)
·Spark SQL支持两种不同的方法将现有RDD转换为数据集。
·第一种方法使用反射来推断包含特定类型对象的RDD的模式。
·这种基于反射的方法可以提供更简洁的代码,并且在您编写Spark应用程序时已经了解模式时可以很好地工作。
·创建数据集的第二种方法是通过编程接口,允许您构建模式,然后将其应用于现有RDD。
·虽然此方法更详细,但它允许您在直到运行时才知道列及其类型时构造数据集。
Inferring the Schema Using Reflection(使用反射推断模式)
·Spark SQL可以将Row对象的RDD转换为DataFrame,从而推断出数据类型。
·通过将键/值对列表作为kwargs传递给Row类来构造行。
·此列表的键定义表的列名称,并通过对整个数据集进行采样来推断类型,类似于对JSON文件执行的推断
from pyspark.sql import Row
sc = spark.sparkContext
# Load a text file and convert each line to a Row.
lines = sc.textFile("examples/src/main/resources/people.txt")
parts = lines.map(lambda l: l.split(","))
people = parts.map(lambda p: Row(name=p[0], age=int(p[1])))
# Infer the schema, and register the DataFrame as a table.
schemaPeople = spark.createDataFrame(people)
schemaPeople.createOrReplaceTempView("people")
# SQL can be run over DataFrames that have been registered as a table.
teenagers = spark.sql("SELECT name FROM people WHERE age >= 13 AND age <= 19")
# The results of SQL queries are Dataframe objects.
# rdd returns the content as an :class:`pyspark.RDD` of :class:`Row`.
teenNames = teenagers.rdd.map(lambda p: "Name: " + p.name).collect()
for name in teenNames:
print(name)
# Name: Justin
Find full example code at "examples/src/main/python/sql/basic.py" in the Spark repo.
Programmatically Specifying the Schema(以编程方式指定架构)
·当无法提前定义kwargs字典时(例如,记录结构以字符串形式编码,或者文本数据集将被解析,字段将以不同方式为不同用户进行投影),可以使用编程方式创建DataFrame
·三个步骤。
·从原始RDD创建元组或列表的RDD;
·创建由StructType表示的模式,该模式与步骤1中创建的RDD中的元组或列表的结构相匹配。
·通过SparkSession提供的createDataFrame方法将模式应用于RDD。
例如:
# Import data types
from pyspark.sql.types import *
sc = spark.sparkContext
# Load a text file and convert each line to a Row.
lines = sc.textFile("examples/src/main/resources/people.txt")
parts = lines.map(lambda l: l.split(","))
# Each line is converted to a tuple.
people = parts.map(lambda p: (p[0], p[1].strip()))
# The schema is encoded in a string.
schemaString = "name age"
fields = [StructField(field_name, StringType(), True) for field_name in schemaString.split()]
schema = StructType(fields)
# Apply the schema to the RDD.
schemaPeople = spark.createDataFrame(people, schema)
# Creates a temporary view using the DataFrame
schemaPeople.createOrReplaceTempView("people")
# SQL can be run over DataFrames that have been registered as a table.
results = spark.sql("SELECT name FROM people")
results.show()
# +-------+
# | name|
# +-------+
# |Michael|
# | Andy|
# | Justin|
# +-------+
Find full example code at "examples/src/main/python/sql/basic.py" in the Spark repo.
Aggregations(聚合)
·内置的DataFrames函数提供常见的聚合,如count(),countDistinct(),avg(),max(),min()等。虽然这些函数是为DataFrames设计的,但Spark SQL也有类型安全的版本
·其中一些在Scala和Java中使用强类型数据集。
·此外,用户不限于预定义的聚合函数,并且可以创建自己的聚合函数。
Untyped User-Defined Aggregate Functions(无用户定义的聚合函数)
·用户必须扩展UserDefinedAggregateFunction抽象类以实现自定义无类型聚合函数。
·例如,用户定义的平均值可能如下所示:
import org.apache.spark.sql.{Row, SparkSession}
import org.apache.spark.sql.expressions.MutableAggregationBuffer
import org.apache.spark.sql.expressions.UserDefinedAggregateFunction
import org.apache.spark.sql.types._
object MyAverage extends UserDefinedAggregateFunction {
// Data types of input arguments of this aggregate function
def inputSchema: StructType = StructType(StructField("inputColumn", LongType) :: Nil)
// Data types of values in the aggregation buffer
def bufferSchema: StructType = {
StructType(StructField("sum", LongType) :: StructField("count", LongType) :: Nil)
}
// The data type of the returned value
def dataType: DataType = DoubleType
// Whether this function always returns the same output on the identical input
def deterministic: Boolean = true
// Initializes the given aggregation buffer. The buffer itself is a `Row` that in addition to
// standard methods like retrieving a value at an index (e.g., get(), getBoolean()), provides
// the opportunity to update its values. Note that arrays and maps inside the buffer are still
// immutable.
def initialize(buffer: MutableAggregationBuffer): Unit = {
buffer(0) = 0L
buffer(1) = 0L
}
// Updates the given aggregation buffer `buffer` with new input data from `input`
def update(buffer: MutableAggregationBuffer, input: Row): Unit = {
if (!input.isNullAt(0)) {
buffer(0) = buffer.getLong(0) + input.getLong(0)
buffer(1) = buffer.getLong(1) + 1
}
}
// Merges two aggregation buffers and stores the updated buffer values back to `buffer1`
def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = {
buffer1(0) = buffer1.getLong(0) + buffer2.getLong(0)
buffer1(1) = buffer1.getLong(1) + buffer2.getLong(1)
}
// Calculates the final result
def evaluate(buffer: Row):