

第一次作业
1、
习题1-1 数据压缩的一个基本问题是“我们要压缩什么”,对此你会死怎样理解的?
答:课本上说到三种压缩对象,分别从物理空间、时间空间和电磁频段举出例子,对此,我的看法是数据压缩就是将较大的数据信息量所占空间通过一定的压缩技术,转换为较小的数据占有空间,并且我们又不希望破坏原有的数据,解压后原有的数据依然存在,但是有的时候也是会有一定的损坏的,依情况而定。而压缩的对象也就是所谓的某信号所占的空域、时域和频域空间!
习题1-2 数据压缩的额另一个基本问题是“为什么进行压缩”,对此你又是怎样理解的?
答:现代几乎都是采用数字技术了,数字技术使数据量大增,占据的空间大,并且文件太大,在传输过程中速度很慢,硬盘中的资料越来越多,也越来越乱,影响人们工作的效率,如果将它们压缩打包后存放,不仅节约了空间还利于查找;在带宽还不能尽如人意的今天,通过网络传输文件(下载、收发邮件等等)当然也是越小越好,能大大提高工作效率,所以进行压缩是非常有必要的。
习题1-6 数据压缩技术是如何分类的?
答: 数据压缩技术根据是否有数据丢失分为可逆压缩(又称无失真编码、无差错编码、无噪声编码,或冗余度压缩、熵编码、数据紧缩、信息保持编码等等)和不可逆压缩(又称有失真编码,信息论中称熵压缩),需要注意的是对于数据外在冗余度得压缩常称为数据紧缩,冗余度压缩式针对数据内部的耳朵与信息进行研究;根据能否同时进行分为即时压缩和非即时压缩;根据压缩数据不同分为数据压缩和文件压缩。
2、
参考书《数据压缩导论(第4版)》Page 8 1.4
(1)用你的计算机上的压缩工具来压缩不同文件。研究原文件的大小和类型对于压缩文件与原文件大小之比的影响。
答:我用自己的计算机上的压缩工具来压缩不同文件时,发现音频文件和视频文件的压缩比比较小;音频和视频之类的文件压缩比比较大;但是不管压缩比是大是小,都是对文件进行了压缩了的,提高了人们的工作效率,节省了资源和空间!
(2)从一本通俗杂志中摘录几段文字,并删除所有不会影响理解的文字,从而实现压缩。例如,在"This is the dog that belongs to my friend” 中,删除 is 、the、that和to之后,仍然能传递相同的意思。用被删除的单词数与原文本的总单词数之比来衡量文本中的冗余度。用一本技术期刊中的文字来重复这一实验。对于摘自不同来源的文字,我们能否就其冗余度做出定量论述?
答:在数据传输中,由于衰减或干扰会使数据代码发生突变,此时就要提高数据代码的抗干扰能力,这必须在原二进制代码长度的基础上增加几位二进制代码的长度,使相应数据具有一定的冗余度,也称做富裕度,简单的讲就是“备用”品,当正常运作的那部分出问题时,就自动启用备用,而这种“备用”时时更新,以确保不会造成脱节,所以叫冗余。如果被删除的单词多,说明冗余度大;如果被删除的单词少,说明冗余度小;并且冗余度越大,压缩潜力也就越大。
3、
参考书《数据压缩导论(第4版)》Page 30
(3)给定符号集A={a1,a2,a3,a4},求以下条件下的一阶熵:
(a)P(a1)=P(a2)=P(a3)=P(a4)=1/4
(b)P(a1)=1/2 , P(a2)=1/4 , P(a3)=P(a4)=1/8
(c)P(a1)=0.505 , P(a2)=1/4 , P(a3)=1/8 , P(a4)=0.12
答:
(a)一阶熵为:-4*1/4*log21/4
=-log21/4
=2(bit)
(b)一阶熵为: -1/2log21/2-1/4*log21/4-2*1/8*log21/8
=1/2+1/2+3/4
=7/4 =1.75(bit)
(c)一阶熵为: -0.505*log20.505-1/4*log21/4-1/4*log21/4-0.12*log20.12
=-0.505*log20.505+1/2+1/2-0.12*log20.12
= 0.5+1-0.12*log20.12
= 1.5+0.3672
=1.8672(bit)
(5)考虑以下序列:
ATGCTTAACGTGCTTAACCTGAAGCTTCCGCTGAAGAACCTG
CTGAACCCGCTTAAGCTTAAGCTGAACCTTCTGAACCTGCTT
根据此序列估计个概率值,并计算这一序列的一阶熵。
答:
由题可知,ATGC的频数分别是:21、23、16、24
则ATGC概率分别为: P(A)=21/84=1/4 ,P(T)=23/84, P(G)=16/84=4/21, P(C)=24/84=2/7
则一阶熵为:-1/4*log2(1/4)-23/84*log2(23/84)-4/21*log2(4/21)-2/7*log2(2/7)
=0.5+0.512+0.457+0.514
=1.983(bit)
(7)做一个实验,看看一个模型能够多么准确地描述一个信源。
编写一段程序,从包括26个字母的符号集{a,b,...,z}中随机选择字母,组成100个四字母单词,这些单词中有多少是有意义的?
答:程序代码如下
#include<iostream>
#include<iomanip>
#include<ctime>
using namespace std;
int main()
{
int k,i,j;
char n[100][100];
srand(time(NULL));
for(i=0;i<100;i++)
{
for(j=0;j<4;j++)
{
k=rand()%26;
n[i][j]=k+'a';
}
n[i][4]='\0';
cout<<" "<<n[i]<<"\t";
}
return 0;
}
调试结果如下:
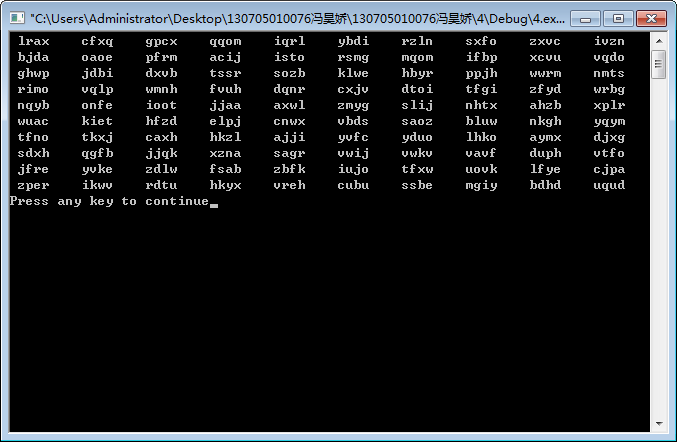
因为有些单词也许有意义,但是我不认识,所以不知道具体有几个有意义的,但是总体来看,是没有几个是有意义的!为数不多,就那么几个而已!
