结对第二次作业——顶会热词统计的实现
结对第二次作业——顶会热词统计的实现
| 课程链接 | 2021春软件工程实践S班(福州大学) |
|---|---|
| 作业要求 | 结对第二次作业——顶会热词统计的实现 |
| 结队学号 | 221801338 & 221801335 |
| 作业目标 | 培养分工协作能力,git实体操作能力,完成热词搜索平台 |
| 项目地址 | 论析平台 |
一 作业内容
1. 基础功能功能1:
对已爬取的论文列表进行操作可对论文列表进行删除;可对论文列表进行查询详细信息(支持模糊查询,查询结果的展示、排序等功能可自行设计);功能2:分析已爬取到的论文信息,提取top10个热门领域或热门研究方向形成如关键词图谱之类直观的查看方式,点击某个关键词可展现相关的论文;可对多年间、不同顶会的热词呈现热度走势对比,以动图的形式呈现(这里将范畴限定在计算机视觉的三大顶会CVPR、ICCV、ECCV内)
2. 附加功能功能3:
获取待爬取论文列表及论文信息爬取支持用户输入单个论文题目,也支持批量导入论文列表;通过论文列表,爬取论文的摘要、关键词、原文链接;
数据来源网站:CVPR、ICCV、ECCV至少爬取三年、三大顶会各300篇论文可编写爬虫代码实现,也可使用爬虫工具(如八爪鱼)爬取此功能为附加功能,实现此功能将获得附加分(详情见评分细则),如果技术上存在难度,可使用助教提供的数据来完成功能1和功能2
3.部署服务器:
本次项目需要部署到云服务器上,并且在博客中给出链接
二 GitHub
1.仓库链接:
2.代码规范链接:
三 PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 60 | 90 |
| •Estimate | •估计这个任务需要多少时间 | 1600 | 1400 |
| Development | 开发 | 280 | 320 |
| •Analysis | •需求分析 (包括学习新技术) | 240 | 300 |
| •Design Spec | •生成设计文档 | 20 | 40 |
| •Design Review | •设计复审 | 60 | 60 |
| •Coding Standard | •代码规范(为目前的开发制定合适的规范) | 40 | 60 |
| •Design | •具体设计 | 60 | 90 |
| •Coding | •具体编码 | 300 | 420 |
| •Code Review | •代码复审 | 60 | 120 |
| •Test | •测试(自我测试,修改代码,提交修改) | 60 | 40 |
| Reporting | 报告 | 120 | 160 |
| •Test Repor | •测试报告 | 40 | 60 |
| •Size Measurement | •计算工作量 | 20 | 20 |
| •Postmortem & Process Improvement Plan | •事后总结, 并提出过程改进计划 | 60 | 120 |
| 合计 | 3020 | 3300 |
四 成品展示
讨论过程
由于结对作业为两个完成,因此分工为冯浩制作前端,洪鸿林制作后端。
第一次结对作业有做过相关模型,但是我们对python以及前端制作只有有简单的了解,在实现的过程中需要有一个学习的阶段,后来发现,我们之前做的功能貌似有点多,在实现过程的时候可能来不及制作,因此就只好按照作业要求进行制作。
在功能讨论及前后端交互的过程中,由于我俩是舍友,因此在线上并没有太多的交流。
线下交流图:


线上交流图:
功能结构图:
功能展示:
项目地址:论析平台
主页:
十大热词:
点击右上角“十大热词“可进入热词查看界面
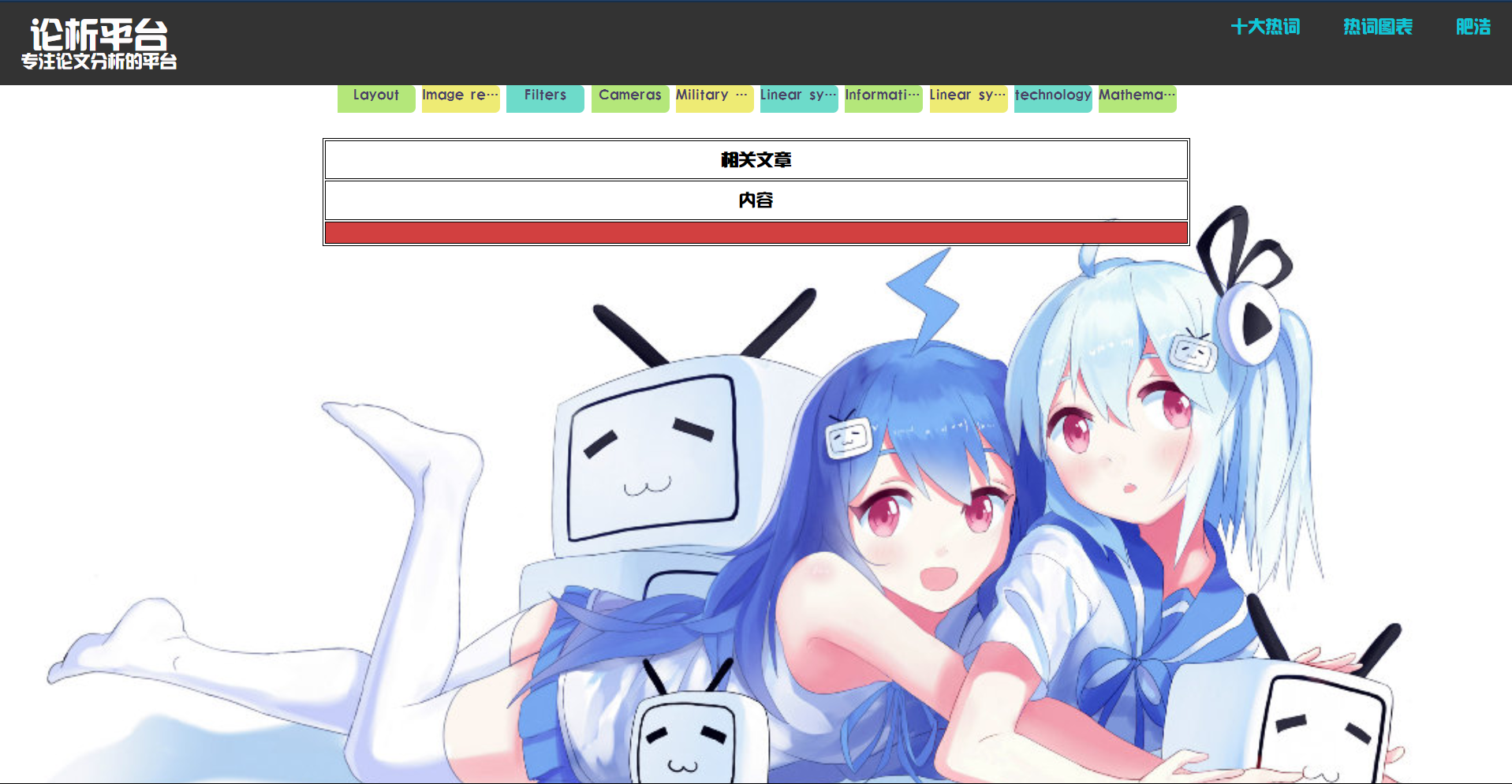
热词图表:
点击右上角”热词图表“可进入动态图表
查询论文:
点击左上角”论析平台“可回到主页
回到主页后在第一个绿色框中输入需要查找的内容即可进行搜索
搜索结果界面如下:
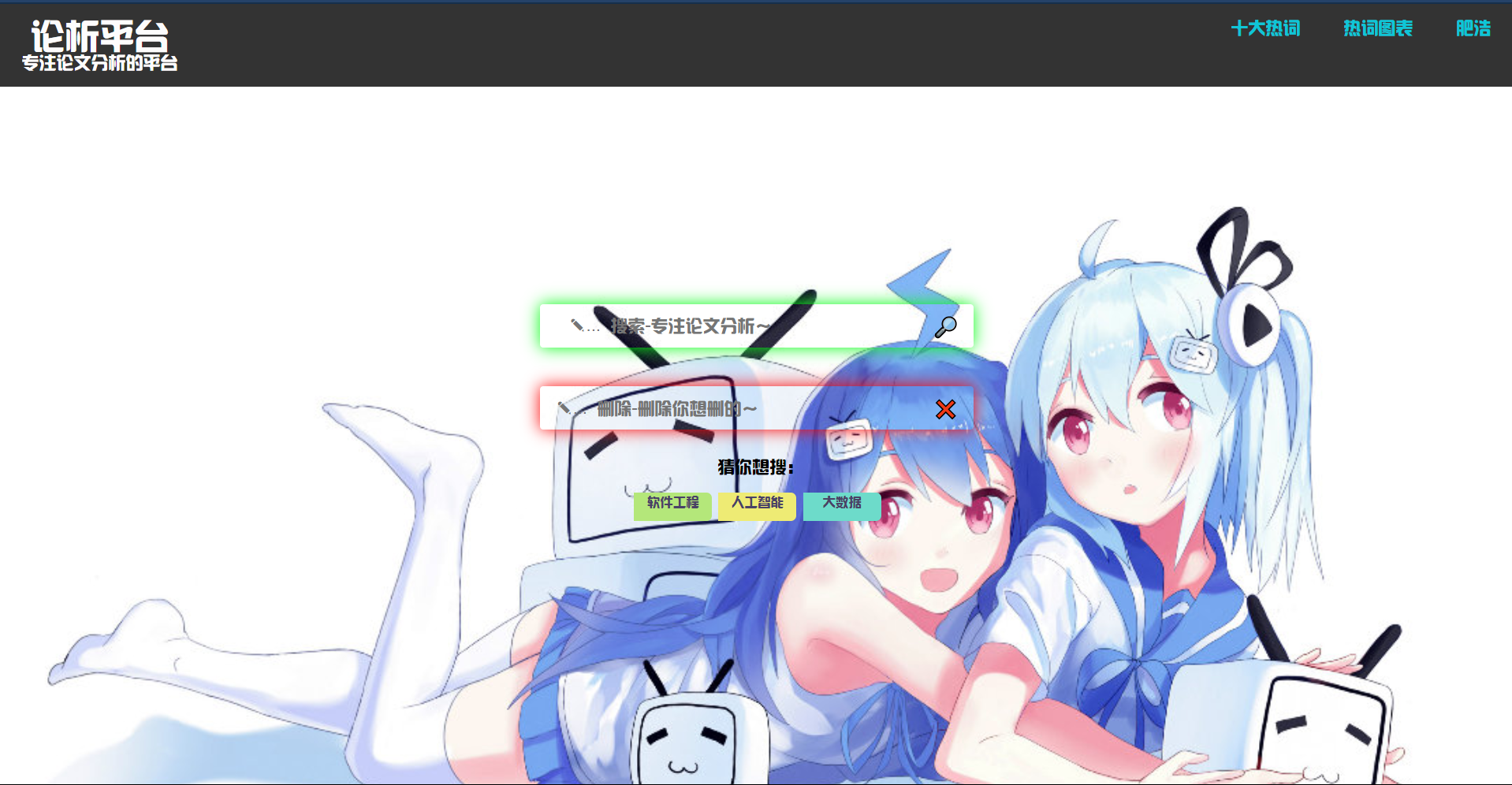

删除论文
在主页红色框内输入论文即可进行删除。

论文列表

代码说明:
index.js
由于没有使用前端框架,因此只能自己写一些小框架,此处为每个界面的导航栏。因为每个界面都要写重复的代码,比较复杂,所以就用JS进行文件调用,需要用的时候直接调用js地址就好啦。
document.writeln("<div>");
document.writeln(" <ul class=\'daohang\'>");
document.writeln(" <li class=\'daohangli1\'>" + "<a class=\'active\' href='home.html'<div style='font-size:32px'>论析平台</div>专注论文分析的平台</a>" + "</li>");
document.writeln(" <li class=\'daohangli2\'><a class=\'name\' href=\'#home\'>肥浩</a></li>");
document.writeln(" <li class=\'daohangli2\'><a class=\'name\' href='chart.html'>热词图表</a></li>");
document.writeln(" <li class=\'daohangli2\'><a class=\'name\' href='hot.html'>十大热词</a></li>");
document.writeln("");
document.writeln(" </ul>");
document.writeln("</div>");
list.html
此处为论文搜索后的展示界面,后台通过{% for result in results %}进行传输,之后使用表格进行排版,用{{ result[0] }}、{{ result[1] }}、{{ result[2] }}接收相应数据。
<table border="1" class="center">
<tr>
<th>
文件名
</th>
<th>
关键词
</th>
<th>
地址
</th>
<th>
摘要
</th>
</tr>
{% for result in results %}
<tr>
<td>
{{ result[0] }}
</td>
<td>
{{ result[1] }}
</td>
<td>
{{ result[2] }}
</td>
<td>
{{ result[3] }}
</td>
</tr>
{% endfor %}
</table>
后端关键代码:
AdapterClass()选择文件进行爬取
class AdapterClass:
def __init__(self,filepath="D:/论文数据"):
self.__fileoperate=FileOperate(filepath)
self.__dict={}
self.__list=[]
def get_key_dic(self)->dict:
if self.__dict:
return self.__dict
_alljson=self.__fileoperate.get_all_json()
dic={}
for json in _alljson:
JsonHelper.jsonfile=json
lis=JsonHelper.get(field="keywords.kwd")
for l in lis:
tmp={json.split("/")[len(json.split("/"))-1],
JsonHelper.get("doiLink"),
JsonHelper.get("abstract")}
if dic.keys().__contains__(l):
dic[l].append(tmp)
else:
dic[l]=[tmp]
self.__dict=dic
return dic
得到所有的关键字
def get_keys(self):
if not self.__dict:
self.get_key_dic()
return self.__dict.keys()
得到对应关键字的文章列表
def get_key_list(self,key):
if not self.__dict:
self.get_key_dic()
return self.__dict.get(key)
得到所有文章需要的信息
def get_json_messages(self,name):
if self.__list:
return self.__list
files=self.__fileoperate.file_search(name)
lis=[]
for file in files:
JsonHelper.jsonfile=file
keys=JsonHelper.get("keywords.kwd")
links=JsonHelper.get("doiLink")
abstract=JsonHelper.get("abstract")
tmplis=[]
tmplis.append(file.split("/")[len(file.split("/"))-1])
tmplis.append(keys)
tmplis.append(links)
tmplis.append(abstract)
lis.append(tmplis)
self.__list=lis
return lis
删除对应文件(全名)
def file_delete(self,filename):
return self.__fileoperate.file_delete(filename)
找到文件(模糊)
def file_search(self,filename):
return self.__fileoperate.file_search(filename)
对文件排序 返回true或false
def file_sort(self):
return self.__fileoperate.file_sort()
得到一个dict{大会一=>{年份=>数量,年份=>数量}}
def get_dict_meet_year_num(self):
return self.__fileoperate.get_dict_meet_year_num()
总结
遇到的困难
困难一: 理想与现实
本次作业需要使用编程将之前做的模型进行实现,但是由于之前是站在产品角度和用户角度。这让我们之前做的模型功能非常全面。但是在编程阶段,由于我们对后端编程不是很熟悉,倒是学习时间很长,最后编程阶段的时间不是很多,无法完成模型中的所有功能。只好将部分重要功能进行实现。
困难二: 前后端对接
我们在前后端对接的时候,由于我们对python与前端的数据交互只会使用
困难三: 时间问题
由于周六有一个团队实践,以及最近编译原理实践、软件质量测试实践时间都堆到了一起,再加上我还有中国大学生服务外创新创业大赛,最近刚好是结果总结的关键时间。还有就是目前是“金三银四”阶段两人最近都在进行实习面试。导致时间非常赶。
心路历程与收获
在结对开发的过程中,我们虽然是前后端分离的模式进行开发,但是双方都在“驾驶员”和“领航员”不断互换角色,在前端开发的过程中冯浩负责编程,洪鸿林负责复审及需求提出。在后端编程中,洪鸿林负责编码,冯浩负责代码复审,测试功能,查看数据能否正常传入前端。
在结对编程过的程中,我们懂得了结对编程并不是一上来两人就能很好的配合,这是一个不断磨合不断相互学习的过程。刚开始,洪鸿林对前端不是很了解,冯浩对python不是很了解,两人无法进行很好的配合,导致进度非常慢。但是在度过学习期之后,我们的开发时间、效果确实好了很多。
在结对编程的过程中,我们学会了编程前一定要统一规范;学会了在结对编程中一定不能自己干自己的,要多沟通交流;学会了如何提需求;并且在这个过程中,我们的默契程度有了很大的提高。
最后,虽然两人最近的时间都非常赶,但是最终我们都通过自己的努力完成了相应的功能,这让我们有了更大的底气去面对更大的挑战!
队友评价
对洪鸿林的评价:
在结对过程中学习非常积极,特别是在搭建服务器的过程中,几乎是从零开始。愿意使用大量时间去学习,并不断实践,这一点非常值得我学习。在后端编程的过程中,由于时间有点赶,甚至晚上熬夜赶项目。虽然完成的功能不是很完善,但我们都从中学到了很多!配合过程很默契!希望能够再次一同学习进步!
对冯浩的评价
能够熟练使用前端技术,但缺乏一定的框架知识,导致后期对接起来比较困难,但是能够尽力把前端做充分,虽然最后没能将项目全部完成,但是从中互相学习到了许多知识。希望之后也能共同进步一起加油。

