在茫茫人海中发现相似的你——局部敏感哈希(LSH)
一、引入
在做微博文本挖掘的时候,会发现很多微博是高度相似的,因为大量的微博都是转发其他人的微博,并且没有添加评论,导致很多数据是重复或者高度相似的。这给我们进行数据处理带来很大的困扰,我们得想办法把找出这些相似的微博,再对其进行去重处理。
如果只是要找到重复的微博,我们可以用两两比较所有的微博,对相同的微博值保留一条即可;但这只能在数据量很小的情况下才有可能,当我们有1000万条微博时,需要两两比较的微博有10^6亿(n*(n-1)/2)对,这个计算量是惊人的,即便你用map-reduce,拥有强大的集群,那也顶不住数据再增加一两个数量级。一种稍微好一点的办法是对所以微博进行一次hash,再对桶内的微博进行比较,利用hash可以过滤了绝大多数不相同的微博,避免了无谓的比较,时间复杂度O(n),显著提高效率。Hash的一个基本特性就是随机性,它将一个字符串随机的hash到一个桶中,对于相同的两个字符串,hash值总是相同的,但两个hash值只要相差一点,hash值就就可能大相径庭,可谓差之毫厘谬以千里:
>>> s1 = "我是一个字符串" >>> s2 = "我是一个字符串" >>> hash(s1) 2006838971 >>> hash(s2) 2006838971 >>> s3 = "我就是一个字符串" >>> hash(s3) -1823451294
如果能有一种hash算法,能将相似的字符串hash得到相似的hash值,那就能在接近线性的时间解决海量微博中的去重问题。幸好,这样的hash已经有大牛发明了,它叫局部敏感哈希(Locality Sensitive Hashing,简称LSH)。接下来我们通过海量微博文本相似项发现的例子来探讨这个神奇的hash。
二、文档相似度计算
按照文本处理的术语,我们认为一条微博是一篇文档,度量两篇文档相似度有多种方法,有欧式距离、编辑距离、余弦距离、Jaccard距离,我们这里使用Jaccard距离。这里注意一下,距离和相似度是不同的概念,距离越近相似度应该越高,距离越远相似度应该越低,因此similar = 1-distace。
集合S和T的Jaccard相识度$$SIM(S,T)=\frac{|S交T|}{|S并T|}$$ 当我们不考虑微博中重复出现的词时,一条微博就可以看成一个集合,集合的元素是一个个的词:
s1 = '''从 决心 减肥 的 这 一刻 起 请 做 如下 小 改变 你 做 得 到 么''' s2 = '''从 决心 减肥 的 这 一刻 起 请 做 如下 小 改变'''
sim(s1,s2)=11/16=0.69.
三 文档的Shingling
为了字面上相似的文档,将文档表示成集合最有效的方法是构建文档中的短字符串集合,一个常用的方法时Shingling(不知道翻译成什么,囧),看定义很简单的:文档的k-shingle定义为其中长度为k的子串。对于上面的字符串s2,选择k=2,这s2中的所有2-single组成的集合为:
{"从 决心","决心 减肥","减肥 的","的 这","这 一刻","一刻 起","起 请","请 做","做 如下","如下 小","小 改变"}
k值的选取具有一定的技巧,k越大越能找到真正相似的文档,而k越小就能召回更多的文档,但他们可能相似度不高,比如k=1,就变成了基本词的比较了。我这里词作为shingle的基本单位,在英文处理中,是以字母为基本单位,原因在于汉字有上万个,而英文字母只有27个,以汉字为单位将造成shingle集合巨大。
遍历所用文档,就得到了shingle全集。
四、保持相似度矩阵表示
1、集合的矩阵表示
假设我们有这样4篇文档(分词后):
s1 = "我 减肥" s2= "要" s3 = "他 减肥 成功" s4 = "我 要 减肥"
为方便叙述,我们取k=1,这时shingle全集为{我,他,要,减肥,成功},将文档表示成特征矩阵,行代表shingle元素,列代表文档,只有文档j出现元素i时,矩阵M[i][j]=1,否则M[i][j] = 0.
|
元素 |
S1 |
S2 |
S3 |
S4 |
|
我 |
1 |
0 |
0 |
1 |
|
他 |
0 |
0 |
1 |
0 |
|
要 |
0 |
1 |
0 |
1 |
|
减肥 |
1 |
0 |
1 |
1 |
|
成功 |
0 |
0 |
1 |
0 |
实际上,真正计算的过程中矩阵不是这样表示的,因为数据很稀疏。得到矩阵表示后,我们来看最小hash的定义。
五、最小哈希(min-hashing)
最小hash定义为:特征矩阵按行进行一个随机的排列后,第一个列值为1的行的行号。举例说明如下,假设之前的特征矩阵按行进行的一个随机排列如下:
|
元素 |
S1 |
S2 |
S3 |
S4 |
|
他 |
0 |
0 |
1 |
0 |
|
成功 |
0 |
0 |
1 |
0 |
|
我 |
1 |
0 |
0 |
1 |
|
减肥 |
1 |
0 |
1 |
1 |
|
要 |
0 |
1 |
0 |
1 |
最小哈希值:h(S1)=3,h(S2)=5,h(S3)=1,h(S4)=2.
为什么定义最小hash?事实上,两列的最小hash值就是这两列的Jaccard相似度的一个估计,换句话说,两列最小hash值同等的概率与其相似度相等,即P(h(Si)=h(Sj)) = sim(Si,Sj)。为什么会相等?我们考虑Si和Sj这两列,它们所在的行的所有可能结果可以分成如下三类:
(1)A类:两列的值都为1;
(2)B类:其中一列的值为0,另一列的值为1;
(3)C类:两列的值都为0.
特征矩阵相当稀疏,导致大部分的行都属于C类,但只有A、B类行的决定sim(Si,Sj),假定A类行有a个,B类行有b个,那么sim(si,sj)=a/(a+b)。现在我们只需要证明对矩阵行进行随机排列,两个的最小hash值相等的概率P(h(Si)=h(Sj))=a/(a+b),如果我们把C类行都删掉,那么第一行不是A类行就是B类行,如果第一行是A类行那么h(Si)=h(Sj),因此P(h(Si)=h(Sj))=P(删掉C类行后,第一行为A类)=A类行的数目/所有行的数目=a/(a+b),这就是最小hash的神奇之处。
六、最小hash签名
有了最小hash还不够,一次最小hash只是一次独立的随即事件,中心极限定理告诉我们,只有多次重复随机事件才能造就必然。选择n个随机排列作用于特征矩阵,得到n个最小hash值,h1,h2,...,hn,这n个最小hash值组成一个n维向量,即为最小签名,两列的最小签名的相似度即为两列的Jaccard相似度的估计。
现在就看如何计算最小签名了。对一个很大的矩阵按行进行随机排列,首先需要得到一个随机排列,然后按这个随机排列去排序,这将耗费很长的时间。我们需要一种方法来模拟随机排列的过程。又有一个神奇的办法是:找一个哈希函数h,将第r行放在排列转换后的第h(r)的位置上。我们不再是选择n个随机排列,而是选择n个hash,h1,h2,...,hn作用于行,这样我们就可以得到签名矩阵。令SIG(i,c)为第i个哈希函数在第c列上的元素。一开始对所有的SIG(i,c)初始化为无穷大,然后从上往下对列c进行处理:
if 特征矩阵中的c列r行值为1:
for i in xrange(n):#对每个hash函数
SIG(i,c)=min(SIG(i,C),hi(r))
else:
continue
按上面的方法处理每一列,即得到最小签名矩阵。
七、基于最小hash的局部敏感hash
前面我们辛辛苦苦的工作貌似只是将一个文档的集合转换为一个最小签名,虽然这个签名大大压缩了集合的空间,但要计算两列的相似度还是需要两两比较签名矩阵两列的相似度,如果有n篇文档,两个比较的次数是n*(n-1)/2。接下来就看局部敏感hash怎么个敏感法。
我们对签名矩阵按行进行分组,将矩阵分成b组,每组由r行组成,下面的实列将一个签名矩阵分成6组,每组由3行组成。
|
组1 |
... |
1 0 0 0 2 3 2 1 2 2 0 1 3 1 1 |
... |
|
组2 |
|
||
|
组3 |
|
||
|
组4 |
|
||
|
组5 |
|
||
|
组6 |
|
分组之后,我们对最小签名向量的每一组进行hash,各个组设置不同的桶空间。只要两列有一组的最小签名部分相同,那么这两列就会hash到同一个桶而成为候选相似项。签名的分析我们知道,对于某个具体的行,两个签名相同的概率p =两列的相似度= sim(S1,S2),然后:
(1)在某个组中所有行的两个签名值都相等概率是$p^r$;
(2)在某个组中至少有一对签名不相等的概率是$1-p^r$;
(3)在每一组中至少有一对签名不相等的概率是$(1-p^r)^b$;
(4)至少有一个组的所有对的签名相等的概率是$1-(1-p^r)^b$;
于是两列成为候选相似对的概率是$1-(1-p^r)^b$,它采样值以及曲线如下:
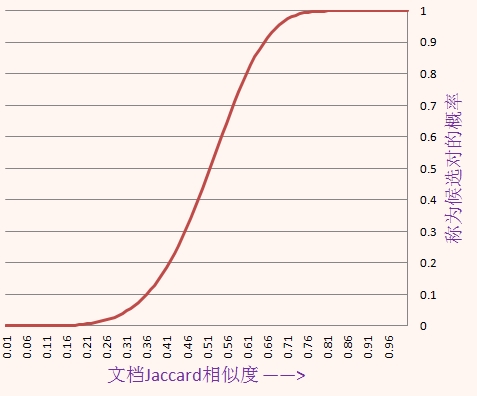
| p | 1-(1-p^5)^20 |
| 0.1 | 0.0002 |
| 0.2 | 0.0064 |
| 0.3 | 0.0475 |
| 0.4 | 0.1860 |
| 0.5 | 0.4701 |
| 0.6 | 0.8019 |
| 0.7 | 0.9748 |
| 0.8 | 0.9996 |
| 0.9 | 1.0000 |
当两篇文档的相似度为0.8时,它们hash到同一个桶而成为候选对的概率是0.9996,而当它们的相似度只有0.3时,它们成为候选对的概率只有0.0475,因此局部敏感hash解决了让相似的对以较高的概率hash到同一个桶,而不相似的项hash到不同的桶的问题。
对于每个桶内的文档,会有一部分是不相似的,因为hash有冲突,需要进行桶内检验。基于最小签名的LSH很容易转化为Map-reduce来计算。
下面是我对微博进行局部敏感hash的一个结果(分词并删掉标点):
1 "外表 活泼 内心 孤僻 的 人 会 做 的 事 1 手机 不 离 身 2 对待 不同 的 人 有 不同 的 性格 3 从 小 懂得 很多 道理 4 有 时候 很 神经 有时候 很 镇静 5 会 因为 别人 一 句 话 伤心 但 不 会 被 发现 6 安慰 很多 人 但 自己 却 没 人 安慰 7 会 怀念 从前 讨厌 现在 8 有时候 会 笑 的 没 心 没 肺 有 时 却 很 沉默"
2 "外表 活泼 内心 孤僻 的 人 会 做 的 事 1. 手机 不 离 身 2. 对待 不同 的 人 有 不同 的 性格 3. 从小 懂得 很多 道理 4. 有时候 很 神经 有时候 很 镇静 5. 会 因为 别人 一 句 话 伤心 但 不 会 被 发现 6. 安慰 很多 人 但 自己 却 没 人 安慰 7. 会 怀念 从前 讨厌 现在 8. 有时候 会 笑 的 没 心 没 肺 有时 却 很 沉默"
3 "射手 座 的 特征 1 手机 不 离 身 2 对待 不同 的 人 有 不同 的 性格 3 从 小 懂得 很多 道理 4 有 时候 很 神经 有时候 很 镇静 5 会 因为 别人 一 句 话 伤心 但 不 会 被 发现 6 安慰 很多 人 但 自己 却 没 人 安慰"
4 "外表 活泼 内心 孤僻 的 人 会 做 的 事 1 手机 不 离 身 2 对待 不同 的 人 有 不同 的 性格 3 从 小 懂得 很多 道理 4 有 时候 很 神经 有时候 很 镇静 5 会 因为 别人 一 句 话 伤心 但 不 会 被 发现 6 安慰 很多 人 但 自己 却 没 人 安慰 7 会 怀念 从前 讨厌 现在 8 有时候 会 笑 的 没 心 没 肺 有 时 却 很 沉默 你 是 这样 吗"
5 "金牛座 特征 1 手机 不 离 身 2 对待 不同 的 人 有 不同 的 性格 3 从 小 懂得 很多 道理 4 有 时候 很 神经 有时候 很 镇静 5 会 因为 别人 一 句 话 伤心 但 不 会 被 发现 6 安慰 很多 人 但 自己 却 没 人 安慰 7 会 怀念 从前 讨厌 现在 8 有时候 会 笑 的 没 心 没 肺 有时 却 很 沉默"
6 "外表 活泼 内心 孤僻 的 人 会 做 的 事 1 手机 不 离 身 2 对待 不同 的 人 有 不同 的 性格 3 从 小 懂得 很多 道理 4 有 时候 很 神经 有时候 很 镇静 5 会 因为 别人 一 句 话 伤心 但 不 会 被 发现 6 安慰 很多 人 但 自己 却 没 人 安慰 7 会 怀念 从前 讨厌 现在 8 有时候 会 笑 的 没 心 没 肺 有 时 却 很 沉默 你 是 这样 吗"
7 "天蝎座 特征 1 手机 不 离 身 2 对待 不同 的 人 有 不同 的 性格 3 从 小 懂得 很多 道理 4 有 时候 很 神经 有时候 很 镇静 5 会 因为 别人 一 句 话 伤心 但 不 会 被 发现 6 安慰 很多 人 但 自己 却 没 人 安慰 7 会 怀念 从前 讨厌 现在 8 有时候 会 笑 的 没 心 没 肺 有时 却 很 沉默" 8 "双子座 的 你 是 这样 的 吗 1 手机 不 离 身 睡觉 不 关机 2 对待 不同 的 人 有 不同 的 性格 3 从 小 懂得 很多 道理 但 知 行 往往 难以 合 一 4 有 时候 很 神经 有时候 很 镇静 5 会 因为 别人 一 句 话 伤心 但 不 会 被 发现 6 很 会 安慰 别人 却 不 会 安慰 自己 7 会 经常 怀念 从 前"
9 "外表 活泼 内心 孤僻 的 人 会 做 的 事 1 手机 不 离 身 2 对待 不同 的 人 有 不同 的 性格 3 从 小 懂得 很多 道理 4 有 时候 很 神经 有时候 很 镇静 5 会 因为 别人 一 句 话 伤心 但 不 会 被 发现 6 安慰 很多 人 但 自己 却 没 人 安慰 7 会 怀念 从前 讨厌 现在 8 有时候 会 笑 的 没 心 没 肺 有时 却 很 沉默 你 是 这样 吗"
10 "外表 活泼 内心 孤僻 的 人 会 做 的 事 1 手机 不 离 身 2 对待 不同 的 人 有 不同 的 性格 3 从 小 懂得 很多 道理 4 有 时候 很 神经 有时候 很 镇静 5 会 因为 别人 一 句 话 伤心 但 不 会 被 发现 6 安慰 很多 人 但 自己 却 没 人 安慰 7 会 怀念 从前 讨厌 现在 8 有时候 会 笑 的 没 心 没 肺 有 时 却 很 沉默 你 是 这样 吗 转"
11 "外表 活泼 内心 孤僻 的 人 会 做 的 事 1. 手机 不 离 身 2. 对待 不同 的 人 有 不同 的 性格 3. 从小 懂得 很多 道理 4. 有时候 很 神经 有时候 很 镇静 5. 会 因为 别人 一 句 话 伤心 但 不 会 被 发现 6. 安慰 很多 人 但 自己 却 没 人 安慰 7. 会 怀念 从前 讨厌 现在 8. 有时候 会 笑 的 没 心 没 肺 有时 却 很 沉默"
看了这个,你还相信星座吗?
八、局部敏感hash的一般定义
局部敏感hash实质上是满足一定条件的函数簇,上面介绍只是一个基于Jaccard的例子,实际上还有面向其他距离的LSH。
令d1<d2是定义在距离测定d下得两个距离值,如果一个函数族的每一个函数f满足:
(1)如果d(x,y)<=d1,则f(x)=f(y)的概率至少为p1,即P(f(x)=f(y)) >= p1;
(2)如果d(x,y)>=d2,则f(x)=f(y)的概率至多为p2,即p(f(x)=f(y)) <= p2.
那么称F为(d1,d2,p1,p2)-敏感的函数族。实际上我们之前的最小hash函数族是(d1,d2,1-d1,1-d2)-敏感的。
局部敏感hash族还可以进行放大处理,已获得更高的准确率和召回率,当然也有面向其他距离的LSH。本文的东西全部源自参考文献的课本,有兴趣可以好好读一下这本书。
参考文献:
《互联网大规模数据挖掘与分布式处理》
感谢阅读,欢迎评论交流!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号