TensorFlow上实践基于自编码的One Class Learning
--One Class Learning的自白
一、单分类简介
如果将分类算法进行划分,根据类别个数的不同可以分为单分类、二分类、多分类,常见的分类算法主要解决二分类和多分类问题,预测一封邮件是否是垃圾邮件是一个典型的二分类问题,手写体识别是一个典型的多分类问题,这些算法并不能很好的应用在单分类上,但单分类问题在工业界广泛存在,由于每个企业刻画用户的数据都是有限的,很多二分类问题很难找到负样本,比如通过用户的搜索记录预测一个用户是否有小孩,可以通过规则筛选出正样本,如经常搜索“宝宝、早教”之类的词,但很难筛选出合适的负样本,一个用户没有搜索并不代表没有小孩,即便用一些排除法筛选出负样本,负样本也会不纯,不能保证负样本中没有正样本,这样用分类模型跑出的结果存在解释性的困难,预测概率高可以认为是有很有可能有小孩,但概率低是有小孩的的可能小还是无法判断?在只能定义正样本不能定义负样本的场景中,使用单分类算法(One-Class Learning)更适合,单分类算法只关注与样本的相似或匹配程度,对于未知的部分不妄下结论。很多人会说“我不知道什么是爱,但我知道什么是不爱”,他们相亲时会立马排查掉不爱的对象,他们就是一个聪明的One-Class学习器。
当然分类算法根据记录所属类别个数的不同还可以分为单标签分类和多标签分类,预测一个用户喜欢的球类就是一个多标签多分类问题,这里不多加讨论,本文重点讨论单分类问题。

二、单分类算法介绍
One Class Learning比较经典的算法是One-Class-SVM[参考文献1],这个算法的思路非常简单,就是寻求一个超平面将样本中的正例圈起来,预测是就用这个超平面做决策,在圈内的样本就认为是正样本。由于核函数计算比较耗时,在海量数据的场景用得并不多;
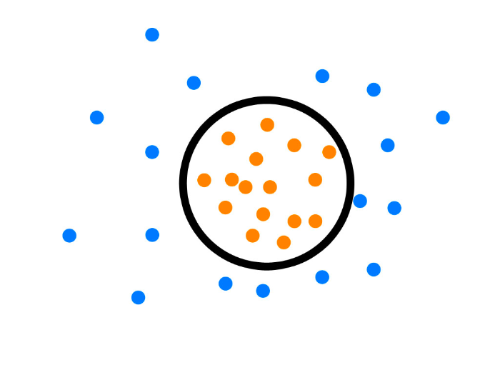
one class svm示例图(图片引用自[参考文献2])
另外一个算法是基于神经网络的算法,在深度学习中广泛使用的自编码算法可以应用在单分类的问题上[参考文献3],自编码器是一个BP神经网络,网络输入层和输出层是一样,中间层数可以有多层,中间层的节点个数比输出入层少,最简单的情况就是中间只有一个隐藏层,如下图所示,由于中间层的节点数较少,这样中间层相当于是对数据进行了压缩和抽象,实现无监督的方式学习数据的抽象特征。
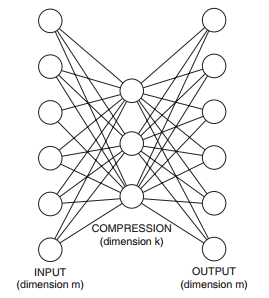
如果我们只有正样本数据,没有负样本数据,或者说只关注学习正样本的规律,那么利用正样本训练一个自编码器,编码器就相当于单分类的模型,对全量数据进行预测时,通过比较输入层和输出层的相似度就可以判断记录是否属于正样本。由于自编器采用神经网络实现,可以用GPU来进行加速计算,因此比较适合海量数据的场景。
三、单分类算法实践
这里使用TensorFlow实践了一下基于自编码的One-Class-Learning,代码引用自[参考文献4],使用MNIST数据进行自编码,首先用0-9这10个类别的数据进行训练,输入层和输出层节点数为784,中间层有两层,节点数分别为256、128,下图中第一排是原始图片,第二排是自编码后解码的图片,可以认为第二排图片是128个单元节点的压缩表示。

假设现在是一个单分类问题,我们只有部分数字7的标注数据,现在需要预测一张图片是不是数据7,那么可以用这部分标注数据来训练一个编码器,让编码器来发现数字7的内在规律,预测时通过编码器进行计算,比较输入层与输出层的相似度,如果相似度较高就可以认为是数字7,编码和解码后的图片示例如下:

实现代码如下:
1 import tensorflow as tf 2 import numpy as np 3 import matplotlib.pyplot as plt 4 5 # Import MNIST data 6 from tensorflow.examples.tutorials.mnist import input_data 7 8 # Parameters 9 learning_rate = 0.008 10 training_epochs = 130 11 batch_size = 2560 12 13 # Building the encoder 14 def encoder(x,weights,biases): 15 # Encoder Hidden layer with sigmoid activation #1 16 layer_1 = tf.nn.sigmoid(tf.add(tf.matmul(x, weights['encoder_h1']), 17 biases['encoder_b1'])) 18 # Decoder Hidden layer with sigmoid activation #2 19 layer_2 = tf.nn.sigmoid(tf.add(tf.matmul(layer_1, weights['encoder_h2']), 20 biases['encoder_b2'])) 21 return layer_2 22 23 24 # Building the decoder 25 def decoder(x,weights,biases): 26 # Encoder Hidden layer with sigmoid activation #1 27 layer_1 = tf.nn.sigmoid(tf.add(tf.matmul(x, weights['decoder_h1']), 28 biases['decoder_b1'])) 29 # Decoder Hidden layer with sigmoid activation #2 30 layer_2 = tf.nn.sigmoid(tf.add(tf.matmul(layer_1, weights['decoder_h2']), 31 biases['decoder_b2'])) 32 return layer_2 33 34 def one_class_learning(dataset,testset,n_input,one_class_label,filename): 35 # Network Parameters 36 n_hidden_1 = int(n_input/2) 37 n_hidden_2 = int(n_input/4) 38 # tf Graph input (only pictures) 39 X = tf.placeholder("float", [None, n_input]) 40 41 weights = { 42 'encoder_h1': tf.Variable(tf.random_normal([n_input, n_hidden_1])), 43 'encoder_h2': tf.Variable(tf.random_normal([n_hidden_1, n_hidden_2])), 44 'decoder_h1': tf.Variable(tf.random_normal([n_hidden_2, n_hidden_1])), 45 'decoder_h2': tf.Variable(tf.random_normal([n_hidden_1, n_input])), 46 } 47 biases = { 48 'encoder_b1': tf.Variable(tf.random_normal([n_hidden_1])), 49 'encoder_b2': tf.Variable(tf.random_normal([n_hidden_2])), 50 'decoder_b1': tf.Variable(tf.random_normal([n_hidden_1])), 51 'decoder_b2': tf.Variable(tf.random_normal([n_input])), 52 } 53 # Construct model 54 encoder_op = encoder(X,weights,biases) 55 decoder_op = decoder(encoder_op,weights,biases) 56 # Prediction 57 y_pred = decoder_op 58 # Targets (Labels) are the input data. 59 y_true = X 60 # Define loss and optimizer, minimize the squared error 61 cost = tf.reduce_mean(tf.pow(y_true - y_pred, 2)) 62 optimizer = tf.train.RMSPropOptimizer(learning_rate).minimize(cost) 63 64 # Initializing the variables 65 init = tf.global_variables_initializer() 66 67 # Launch the graph 68 with tf.Session() as sess: 69 sess.run(init) 70 total_batch = int(len(dataset['data'])/batch_size) 71 # Training cycle 72 for epoch in range(training_epochs): 73 # Loop over all batches 74 for i in range(total_batch): 75 batch_xs = dataset['data'][i*batch_size:(i+1)*batch_size] 76 batch_ys = dataset['label'][i*batch_size:(i+1)*batch_size] 77 batch_xs = [batch_xs[j] for j in range(len(batch_xs)) if batch_ys[j] == one_class_label] 78 79 # Run optimization op (backprop) and cost op (to get loss value) 80 _, c = sess.run([optimizer, cost], feed_dict={X: batch_xs}) 81 # Display logs per epoch step 82 print("Epoch:", '%04d' % (epoch+1),"cost=", "{:.9f}".format(c)) 83 84 encode_decode = sess.run(y_pred, feed_dict={X: testset['data']}) 85 86 #examples_to_show = 14 87 #f, a = plt.subplots(2, examples_to_show, figsize=(examples_to_show, 2)) 88 #for i in range(examples_to_show): 89 # print(testset['label'][i],sess.run(tf.reduce_mean(tf.pow(testset['data'][i] - encode_decode[i], 2)))) 90 # a[0][i].imshow(np.reshape(testset['data'][i], (28, 28))) 91 # a[1][i].imshow(np.reshape(encode_decode[i], (28, 28))) 92 #f.show() 93 #plt.draw() 94 #plt.waitforbuttonpress() 95 wf = open(filename,'a+') 96 for i in range(len(encode_decode)): 97 wf.write(str(one_class_label)+','+str(testset['label'][i])+','+str(sess.run(tf.reduce_mean(tf.pow(testset['data'][i] - encode_decode[i], 2))))+'\n') 98 if i % 500 == 0: 99 print(i) 100 wf.close() 101 102 103 104 def decode_one_hot(label): 105 return max([i for i in range(len(label)) if label[i] == 1]) 106 107 def mnist_test(): 108 mnist = input_data.read_data_sets("MNIST_data", one_hot=True) 109 trainset = {'data':mnist.train.images,'label':[decode_one_hot(label) for label in mnist.train.labels]} 110 testset = {'data':mnist.test.images,'label':[decode_one_hot(label) for label in mnist.test.labels]} 111 one_class_learning(trainset,testset,784,7,'label_7.csv') 112 113 mnist_test()
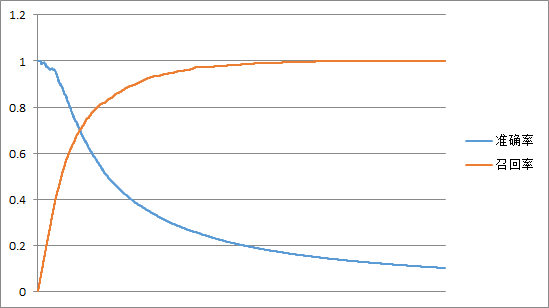
根据相似度进行排序,还可以计算准确率、召回率、ROC等,这里统计了一下准确率和召回率。
四、参考文献
[1].Manevitz L M, Yousef M. One-class svms for document classification[J]. Journal of Machine Learning Research, 2002, 2(1):139-154.
[2]: http://www.louisdorard.com/blog/when-machine-learning-fails
[3].Manevitz L, Yousef M. One-class document classification via Neural Networks[M]. Elsevier Science Publishers B. V. 2007.
[4].https://github.com/aymericdamien/TensorFlow-Examples/blob/master/examples/3_NeuralNetworks/autoencoder.py
全文完,转载请注明出处:http://www.cnblogs.com/fengfenggirl/p/One-Class-Learning.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号