
Scrapy练习——爬取京东商城商品信息
刚刚接触爬虫,花了一段时间研究了一下如何使用scrapy,写了一个比较简单的小程序,主要用于爬取京东商城有关进口牛奶页面的商品信息,包括商品的名称,价格,店铺名称,链接,以及评价的一些信息等。简单记录一下我的心得和体会,刚刚入门,可能理解的不够深入不够抽象,很多东西也只是知其然不知其所以然,理解的还是比较浅显,希望有看见的大佬能一起交流。
先上我主要参考的几篇博客,我的爬虫基本上是在这两篇博客的基础上完成的,感谢大佬的无私分享:
小白进阶之Scrapy第一篇
scrapy爬取京东商城某一类商品的信息和评论(一)
首先说明一下我的程序是基于以上二篇博客的基础上进行修改的,主要的改动是针对3.6版本的python,修改了一些已经删除的函数,修改了一些已经更新的页面的网址,还有有些商品是京东全球购,商品页面的信息和京东自营的不一样,对此进行了判定和处理等,并将信息输出到Mysql中。
整个爬虫我已上传至Github,欢迎大家讨论交流。
scrapy爬虫主要可以分为几部分,如下图所示:
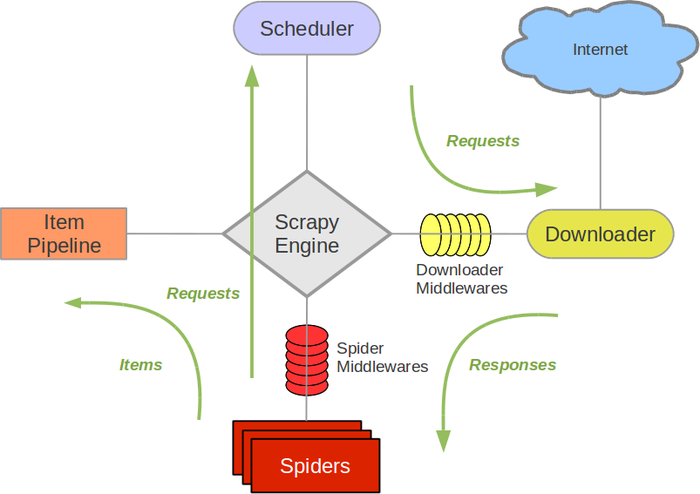
有关Scrapy的基本结构在第一篇博客里也有所简单说明,在此不再赘述,如果需要了解更多还是需要看官方文档。在这里我简单说一下我认为比较重要的几个部分。
Spider:这个部分可以认为是爬虫的本体了,他的主要作用就是从下载好的内容中爬到你需要的东西,所以你在写爬虫的时候基本都是对Spider进行修改。
Item Pipeline:这个模块简单的说就是将你爬到的信息进行处理,输出到Mysql等。因此在这里需要完成python到Mysql的输出。
在上面两篇博客的基础上对代码进行了一定的修改,我的编程环境是Python 3.6,开发环境是win10下的Pycharm。需要注意的一点是,在IDE中进行爬虫的运行和调试需要添加一些内容,如果是在IDE下进行运行的话,需要在项目的根目录下添加一个名为entrypoint的py文件,其中的代码如下:
from scrapy.cmdline import execute execute(['scrapy','crawl','JDSpider']) #用于在IDE里运行
其中JDSpider即是你自定义的Spider的name属性,注意一定要与Spider的名字匹配。
如果要在IDE下进行调试的话,则需要在与setting.py的目录下添加一个名为run.py的文件,文件的代码如下:
# -*- coding: utf-8 -*- from scrapy import cmdline name = 'JDSpider' cmd = 'scrapy crawl {0}'.format(name) cmdline.execute(cmd.split()) #用于在IDE里进行Debug
需要运行爬虫的时候,直接运行entrypoiot.py即可,同理,进行调试的时候debug entrypoint.py。
下面开始进行爬虫的编写了。第一步,先确定你需要进行爬取的信息都有那些,那么我们先来编写items.py。代码如下:
import scrapy class JDSpiderItem(scrapy.Item): # define the fields for your item here like: ID = scrapy.Field() # 商品ID name = scrapy.Field() # 商品名字 comment = scrapy.Field() # 评论人数 shop_name = scrapy.Field() # 店家名字 price = scrapy.Field() # 价钱 link = scrapy.Field() comment_num = scrapy.Field() score1count = scrapy.Field() # 评分为1星的人数 score2count = scrapy.Field() # 评分为2星的人数 score3count = scrapy.Field() # 评分为3星的人数 score4count = scrapy.Field() # 评分为4星的人数 score5count = scrapy.Field()
这一部分比较简单,只要将你想要爬取的信息提供一个Scrapy.Field()方法即可。
第二部分的内容是编写爬虫的设置,修改settings.py中的代码。
MYSQL_HOSTS = "127.0.0.1" MYSQL_USER = "root" MYSQL_PASSWORD = "7911upup" MYSQL_PORT = 3306 MYSQL_DB = "JD_test" # HTTPCACHE_ENABLED = True # HTTPCACHE_EXPIRATION_SECS = 0 # HTTPCACHE_DIR = 'httpcache' # HTTPCACHE_IGNORE_HTTP_CODES = [] # HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage' # DOWNLOAD_DELAY = 7 # 下载延迟
其中第一部分的内容是有关Mysql的接口,127.0.0.1是本机的保留地址,root是Mysql数据库的账户名称,第三行是密码,第四行是端口,默认为3306,第五行是mysql建立的database名称。
第二部分是本地缓存,如果取消注释的话是建立本地缓存,这样能够减少网站压力,也方便进行调试,我一开始在调试的过程中是保留本地缓存的,但是在进行调试的过程中发现经过一段时间的调试之后发生了数据丢失的现象,不知道是不是跟我的程序编写有关系,所以我个人建议如果是刚开始进行调试的时候尽可能的减少爬取的数据量,并不使用本地的缓存,这样能够防止数据出现错误,便与调试。
既然刚才提到了Mysql,这里也简单说一下mysql的操作吧,由于我对这一块不太了解,在这里也不献丑了,直接上代码,看代码还是比较好理解的,就是首先建立一个database,然后在其中建立一个table,然后再设置一些变量的名称和类型。
#create database JD_test character set gbk; use JD_test; DROP TABLE IF EXISTS `JD_name`; CREATE TABLE `JD_name` ( `id` int(11) NOT NULL AUTO_INCREMENT, `good_id` varchar(255) DEFAULT NULL, `name` varchar(255) DEFAULT NULL, `price` varchar(255) DEFAULT NULL, `comment` varchar(255) DEFAULT NULL, `shop_name` varchar(255) DEFAULT NULL, `link` varchar(255) DEFAULT NULL, `score1count` varchar(255) DEFAULT NULL, `score2count` varchar(255) DEFAULT NULL, `score3count` varchar(255) DEFAULT NULL, `score4count` varchar(255) DEFAULT NULL, `score5count` varchar(255) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=38 DEFAULT CHARSET=utf8mb4; truncate JD_name;
至于python这一部分,在3.6中是用到了pymysql这个库完成二者的连接的。这一部分的代码如下。
import pymysql.connections import pymysql.cursors MYSQL_HOSTS = "127.0.0.1" MYSQL_USER = "root" MYSQL_PASSWORD = "7911upup" MYSQL_PORT = 3306 MYSQL_DB = "JD_test" connect = pymysql.Connect( host = MYSQL_HOSTS, port = MYSQL_PORT, user = MYSQL_USER, passwd = MYSQL_PASSWORD, database = MYSQL_DB, charset="utf8" ) cursor = connect.cursor() # # 插入数据 class Sql: @classmethod def insert_JD_name(cls,id, name, shop_name, price, link, comment_num ,score1count, score2count, score3count, score4count, score5count): sql = "INSERT INTO jd_name (good_id, name, comment, shop_name, price, link ,score1count, score2count," \ " score3count, score4count, score5count) VALUES ( %(id)s, %(name)s, %(comment_num)s, %(shop_name)s, %(price)s" \ ", %(link)s, %(score1count)s, %(score2count)s, %(score3count)s, %(score4count)s, %(score5count)s )" value = { 'id' : id, 'name' : name, 'comment' : comment_num, 'shop_name' : shop_name, 'price' : price, 'link' : link, 'comment_num' : comment_num, 'score1count' : score1count, 'score2count' : score2count, 'score3count' : score3count, 'score4count' : score4count, 'score5count' : score5count, } cursor.execute(sql, value) connect.commit()
接下来就是Spider的编写了,在Spider类中有几个比较重要的变量和函数,一个是start_url,这个是爬虫开始爬取的网站地址,由于在JD首页进行搜索显示的页面是30条动态加载的,所以爬取不是特别方便,所以选取在首页左侧中的进口牛奶分类的页面,该页面能够直接显示60条商品数据。网址为https://list.jd.com/list.html?cat=1320,5019,12215&page=N&sort=sort_totalsales15_desc&trans=1&JL=6_0_0#J_main。这里N即为具体的页码,通过如下代码将start_url设置成为一个list。
start_urls = [] for i in range(1, 10+1): # 这里需要自己设置页数 url = 'https://list.jd.com/list.html?cat=1320,5019,12215&page='+ str(i)+'&sort=sort_totalsales15_desc&trans=1&JL=6_0_0#J_main' start_urls.append(url)
第二个比较重要的函数是parse,在这里我们素质四连,一共有parse,parse_detail,parse_getCommentnum,parse_price四个方法,parse用来爬取商品的ID,链接,还有商品的名称;parse_detail用来爬取商品的店铺名,后面两个方法则是用来爬取评论数和不同评价的人数以及商品的价格。
解析数据的话,可以用Xpath直接解析,也可以用导入的BS4等库来做,在这里我用Xpath+正则表达式的一套combo来完成,不懂的老哥可以先看一下这个有关正则表达式的介绍。相比于我参考的代码,在网站解析这一部分很多解析的代码已经失效了,年久失修只能我自己动手来修改,刚开始上手确实有点麻烦,毕竟没有JS基础,看网页源代码有些吃力,后来操作了一番以后也就有点熟悉了,简单介绍一下如何查找你需要的元素。
我采用的是猎豹浏览器,是基于Chrome内核的,调试起来应该跟Chrome没什么区别,首先在对应的页面单击F12,出现如下页面:
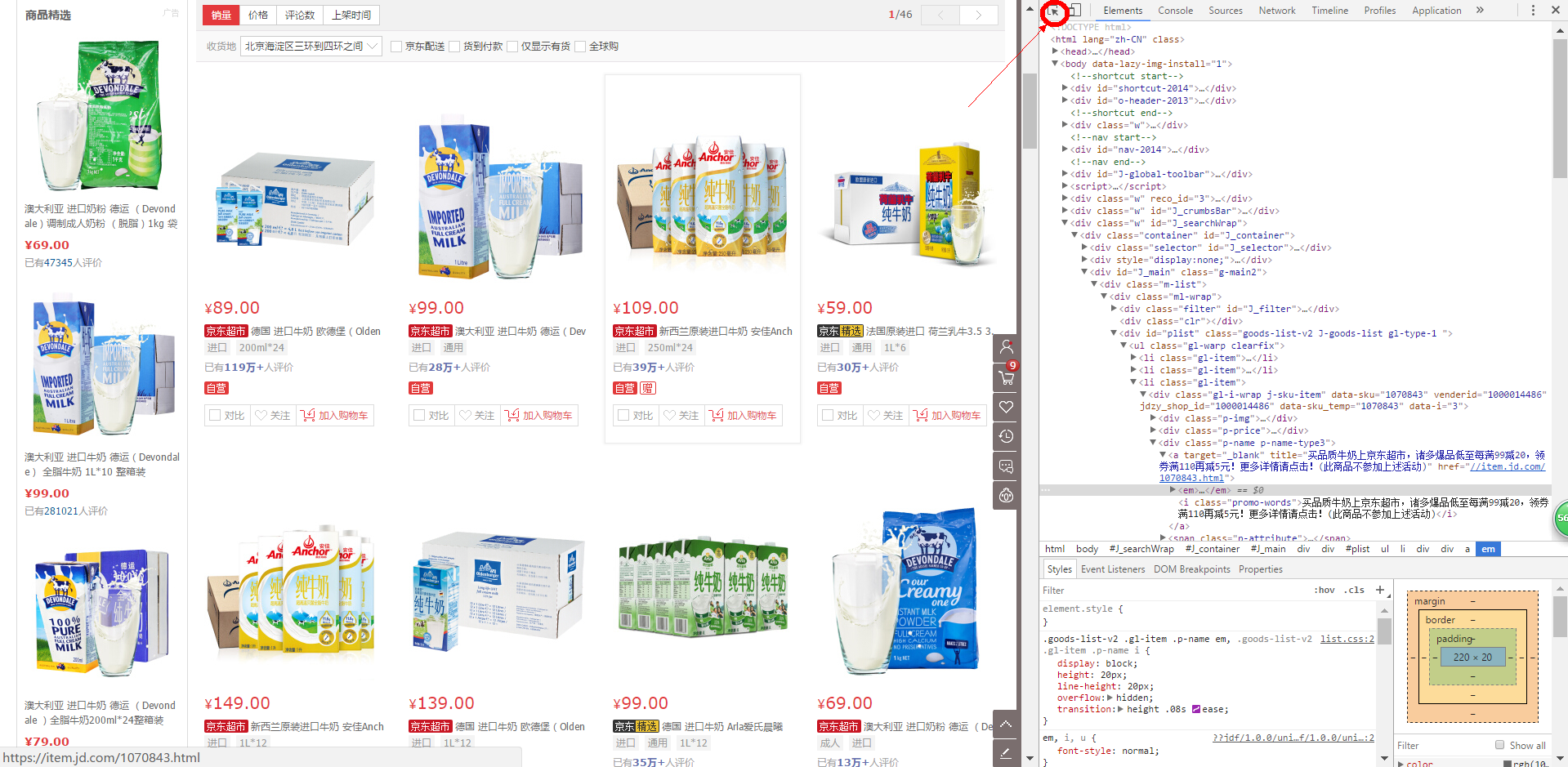
首先进行观察,可以看出所有的商品都有一个class=‘gl-item’的标签,再单击所示图标,将光标移动到你需要的信息上点右键,例如某一个商品的名称哪里,即可在右边显示出对应的信息,从图中可以知道这个商品名称的信息是在 li//div/div[@class="p-name"]/a/em/ 的text中,同时也可以看出其中的文本还包括一些空格等等,所以需要使用正则表达式对其进行筛选。这里的代码如下:
def parse(self, response): # 解析搜索页 # print(response.text) sel = Selector(response) # Xpath选择器 goods = sel.xpath('//li[@class="gl-item"]') for good in goods: item1 = JDSpiderItem() temp1 = str(good.xpath('./div/div[@class="p-name"]/a/em/text()').extract()) pattern = re.compile("[\u4e00-\u9fa5]+.+\w") #从第一个汉字起 匹配商品名称 good_name = re.search(pattern,temp1) item1['name'] = good_name.group() item1['link'] = "http:" + str(good.xpath('./div/div[@class="p-img"]/a/@href').extract())[2:-2] item1['ID'] = good.xpath('./div/@data-sku').extract() if good.xpath('./div/div[@class="p-name"]/a/em/span/text()').extract() == ['全球购']: item1['link'] = 'https://item.jd.hk/' + item1['ID'][0] +'.html' url = item1['link'] + "#comments-list" yield scrapy.Request(url, meta={'item': item1}, callback=self.parse_detail)
简单的说一下几个需要注意的地方,一个是正则表达式中,[\u4e00-\u9fa5]+从第一个汉字开始匹配,这里其实是有一点小BUG的,因为有的商品名称是以字符和数字或者标点符号开头的,由于我爬取的商品信息第一页里没有这种情况,所以我也没有修改,后面应该进行适当的调整,修改一下这个正则表达式。第二个是注意re模块中search和match的区别,match是从第一个字符开始进行匹配,而search是在整个字符串中进行匹配,建议使用search。第三个需要注意的地方是对于牛奶这种商品,分为两个类型,一个是JD自营的或者第三方的一些店铺,这些网址是类似的,而还有一种是京东全球购,这种商品的网址跟之前的是不一样的,网址开头是items.jd.hk。因此在爬的过程中要将全球购的这个标签给选取出来,针对不同的商品类型,对link的值进行修改,这样传递给request才是有效的url。
parse_detail这个函数是用于爬取商品的店铺名的,这里进入了商品的详情页面,url是通过parse函数抓取的ID生成的,全球购和国内商品的url不同,在这里对于店铺的抓取也是不同的,其中的标签是不一样的,需要注意的就是有的商品是京东自营的,没有具体的店铺名,在这里需要进行判别。
def parse_detail(self, response): # pass item1 = response.meta['item'] sel = Selector(response) # Xpath选择器 if response.url[:18] == 'https://item.jd.hk': #判断是否为全球购 goods = sel.xpath('//div[@class="shopName"]') temp = str(goods.xpath('./strong/span/a/text()').extract())[2:-2] if temp == '': item1['shop_name'] = '全球购:'+ 'JD全球购' #判断是否JD自营 else: item1['shop_name'] = '全球购:' + temp # print('全球购:'+ item1['shop_name']) else: goods = sel.xpath('//div[@class="J-hove-wrap EDropdown fr"]') item1['shop_name'] = str(goods.xpath('./div/div[@class="name"]/a/text()').extract())[2:-2] if item1['shop_name'] == '': #是否JD自营 item1['shop_name'] = '京东自营' # print(item1['shop_name'])
下面的两个parse函数没有太多的改动,与第二篇博客中的相差无几,只是把其中解析的网址做了替换,之前的不能用了。在此也不多说了,烦请各位移步那篇博客。我就只上个代码了。
def parse_price(self, response): item1 = response.meta['item'] temp1 = str(response.body).split('jQuery712392([') s = temp1[1][:-6] # 获取到需要的json内容 js = json.loads(str(s)) # js是一个list item1['price'] = js['p'] return item1 def parse_getCommentnum(self, response): item1 = response.meta['item'] js = json.loads(str(response.body)[2:-1]) item1['score1count'] = js['CommentsCount'][0]['Score1Count'] item1['score2count'] = js['CommentsCount'][0]['Score2Count'] item1['score3count'] = js['CommentsCount'][0]['Score3Count'] item1['score4count'] = js['CommentsCount'][0]['Score4Count'] item1['score5count'] = js['CommentsCount'][0]['Score5Count'] item1['comment_num'] = js['CommentsCount'][0]['CommentCount'] num = item1['ID'] # 获得商品ID s1 = re.findall("\d+",str(num))[0] url = "http://p.3.cn/prices/mgets?callback=jQuery712392&type=1&area=1_2800_2849_0.138365810&pdtk=&pduid=15083882680322055841740&pdpin=jd_4fbc182f7d0c0&pin=jd_4fbc182f7d0c0&pdbp=0&skuIds=J_" + s1 yield scrapy.Request(url, meta={'item': item1}, callback=self.parse_price)
最后的部分就是pipeline,这里完成对爬取的数据的输出,输出到mysql中。
class JdspiderPipeline(object): def process_item(self, item, spider): if isinstance(item, JDSpiderItem): good_id = item['ID'] good_name = item['name'] shop_name = item['shop_name'] price = item['price'] link = item['link'] comment_num = item['comment_num'] score1count = item['score1count'] score2count = item['score2count'] score3count = item['score3count'] score4count = item['score4count'] score5count = item['score5count'] Sql.insert_JD_name(good_id, good_name, shop_name, price, link, comment_num ,score1count, score2count, score3count, score4count, score5count) # print('存储一条信息完毕了哦') return item
在Mysql输出到csv中时会出现一个问题,即输出的中文会出现乱码,在这里提供一个解决方案,将输出的csv文件以记事本的形式打开,另存为csv的时候可以选择以utf-8进行存储,然后再打开即可。
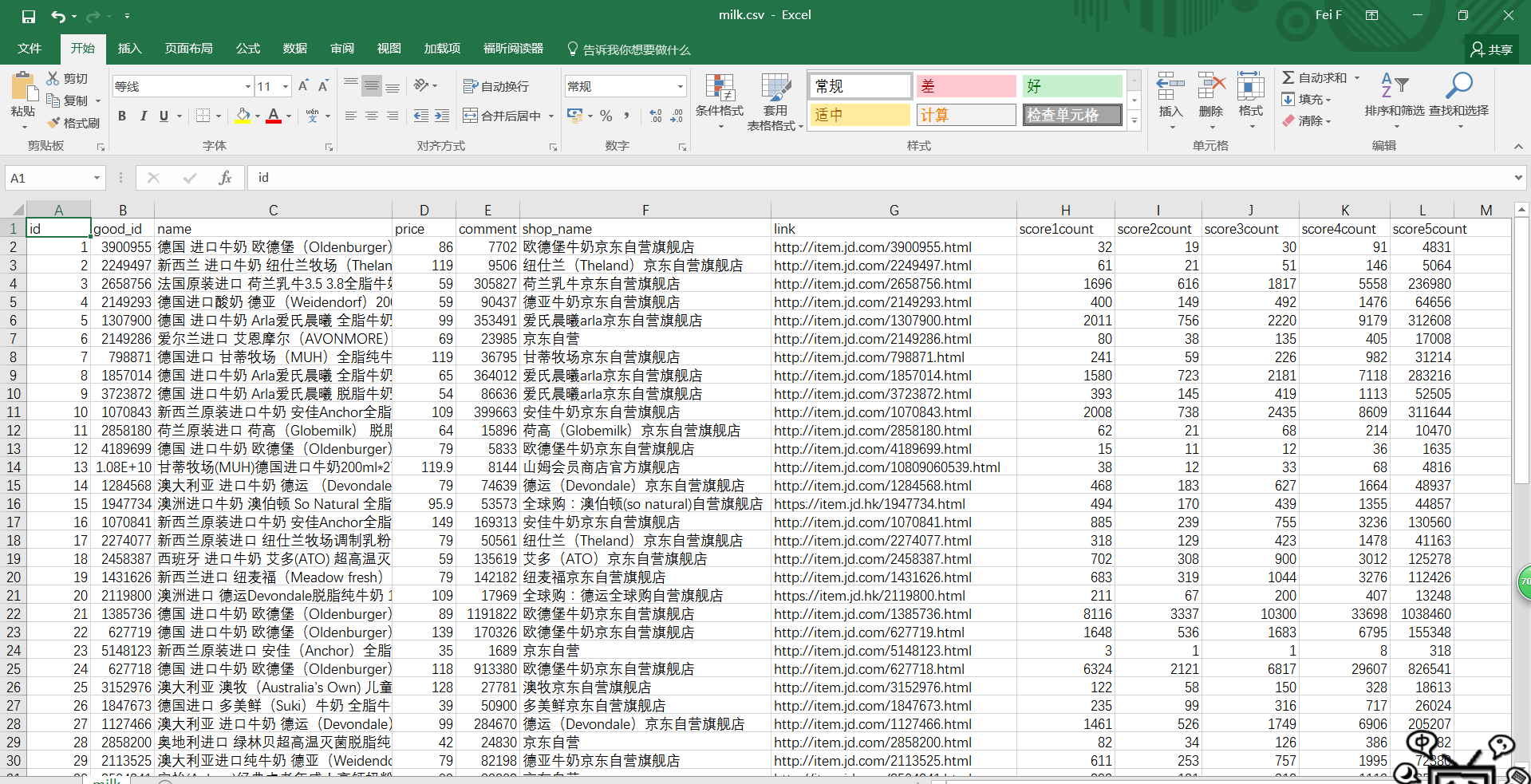
成品图如下:
以上就是我关于Scrapy模块编写爬虫时的一些心得了, 仓促完成的一篇博客,多有疏漏,自己理解不深的地方还有很多,继续加油。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号