机器学习理论提升方法AdaBoost算法第一卷
AdaBoost算法内容来自《统计学习与方法》李航,《机器学习》周志华,以及《机器学习实战》Peter HarringTon,相互学习,不足之处请大家多多指教!
提升算法是将弱学习算法提升为强学习算法的统计学习方法,在分类学习中,提升方法通过反复修改训练数据的权值分布,构建一系列基本的基本分类器,并将这些基本的分类器线性组合,构成一个强分类器.代表的方法是AdaBoost算法.
本卷大纲为:
1 提升方法AdaBoost算法
2 AdaBoost算法解释
3 提升树
4 总结
1 提升方法AdaBoost算法
1.1 提升方法的基本思想
提升方法基于三个臭皮匠赛过诸葛亮的思想.对于一个复杂的任务来说,将多个专家系统的判断进行适当的综合分析,要比其中任何一个专家单独判断要好.
强可学习的:一个概念,如果存在一个多项式学习算法能够学习它,并且正确率很高,那么就称为这个概念是强可学习的.
弱可学习的:一个概念,如果存在一个多项式的学习算法能够学习它,但是学习的正确率仅仅只能比随机猜测的略好,那么就称这个概念是弱可学习的.
一个任务可以变成,在学习中,如果已经发现了弱学习方法,那么能够将其提升boost为强学习方法.关于提升的研究有很多,有很多算法被提出来,最具代表性的是AdaBoost算法.
对于分类问题而言,给定一个训练样本,求比较粗糙的分类规则要求比求比较精确的分类规则容易得多,提升方法就是从弱学习算法出发,反复学习得到一系列弱分类器,然后组合这些弱分类器,构成一个强大的分类器.大多数的提升算法都是改变训练数据的概率分布(训练数据的权值分布),针对不同的训练数据分布调用弱学习算法学习一系列弱分类器.
1.2提升方法解决的方法
提升方法需要解决的两个问题
[1]在每一轮如何改变训练数据的权重和概率分布
关于第一个问题,AdaBoost的做法是,提高那些被前一轮弱分类器错误分类样本的权重,而降低那些被正确分类样本的权值.这样一来,有正确分类的数据,由于其权值加大而受到后一轮弱分类器更大的关注.于是分类问题被一系列弱分类器分而治之.
[2]如何将弱分类器组合成一个强的分类器
关于第二个问题,弱分类器的组合,AdaBoost采用加权多数表决的方法,具体的,加大分类误差较小的弱分类器的权值,使得其在表决中较大的作用,减小分类误差率大的分类器的权值,使得其在表决中起较小的作用.
1.3 AdaBoost算法的具体实现
输入:训练数据集T={(x1,y1),(x2,y2),(x3,y3)..........(xn,yn)},弱学习算法
输出:最终的分类器G(x)
训练步骤:
(1)初始化训练数据的权值分布
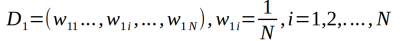
(2)对于m=1,2,...,M
(a)使用具有权值分布Dm的训练数据集学习,得到基本分类器:
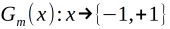
(b)计算Gm(x)在训练数据集上的分类误差率:
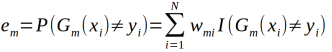
(c)计算Gm(x)的系数:
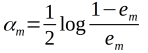
(d)更新训练数据的权值分布:
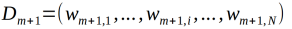
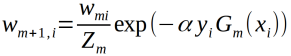
这里的Zm是规范化因子,使得Dm+1是一个概率分布
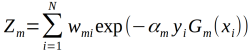
(3)构建基本分类器的线性组合
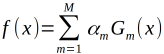
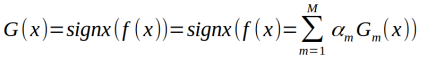
1.4算法具体说明:
步骤(1)假设训练数据集具有均匀的权值分布,即每个训练样本在基本分类器的学习中作用相同,这个假设保证第1步在原始数据上学得类器G1(x)
步骤(2)AdaBoost反复学习基本分类器,在每一轮m=1,2,3,.....,M顺序执行下列操作.
(a)使用当前分布Dm加权的训练数据集,学习基本分类器Gm(x)
(b)计算基本分类器Gm(x)在训练数据集上的基本误差em
(c)计算基本分类器Gm(x)的系数ɑm,ɑm表示Gm(x)在最终分类器中的重要性,分类误差小的分类器在最终的分类器中的作用越大
(c)更新训练数据的权值,为下一轮作准备
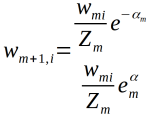
被基本分类器Gm(x)误分类的样本的权值得以扩大,被正确分类样本的权值得以缩小,两者一比较,误分类的样本权值被放大
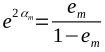
因此,误分类样本在下一轮学习中起更大的作用,不改变训练数据,不断改变训练数据的权值分布,使得训练数据在基本分类器中起不同作用,这是AdaBoost算法的特点
步骤(3),线性组合f(x)实现M个基本分类器的加权表决,系数ɑm 表示基本分类器的重要性,这里ɑm的和并不为1,f(x)的符号决定实类.f(x)的绝对值表示分类的可信度,利用基本分类器线性组合构建最终分类器是AdaBoost的另一个特点.
2 AdaBoost算法解释
AdaBoost算法的另外一个解释,可以认为AdaBoost算法是模型为加法模型,损失函数为指数函数,学习方法为前向分步算法时的二分类学习方法.
2.1前向分步算法
考虑加法模型
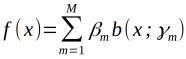
其中 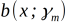 为基函数,
为基函数,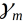 为基函数的参数,
为基函数的参数,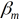 为基函数的系数,在给定训练数据和损失函数L(y,f(x))的条件下,学习加法模型f(x)成为经验风险极小化,即损失函数极小化问题:
为基函数的系数,在给定训练数据和损失函数L(y,f(x))的条件下,学习加法模型f(x)成为经验风险极小化,即损失函数极小化问题:
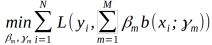
前向分步算法求解这个优化问题的想法是:因为学习的是加法模型,如果能够从前向后,每一步只学习一个基函数及其系数,逐步逼近最优化目标函数式,就可以简化优化的复杂度,具体的,每步只需要优化如下
损失函数:
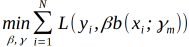
2.2学习加法模型f(x)的前向分步算法如下:
输入:训练数据集T={(x1,y1),(x2,y2),....,(xN,yN)};损失函数L(y,f(x));基函数{b(x;r)}
输出:加法模型f(x)
(1)初始化f_0(x) = 0
(2)对m=1,2,3.....,M
(a)极小化损失函数
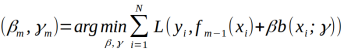
得到参数 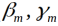
(b)更新
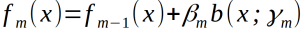
(3)得到加法模型
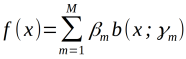
3 提升树
提升树是以分类树或者回归树为基本的分类器的提升方法,提升树被认为是统计学习中性能最好的学习方法之一.
3.1提升树模型
提升方法实际采用加法模型(基函数的线性组合)与前向分步算法,以决策树为基函数的提升方法称为提升树,对分类问题决策树是二叉分类树,对回归问题决策树是二叉回归树.
提升树算法采用前向分步算法,首先确定初始提升树f0(x)=0,第m步的模型是
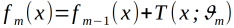
其中为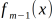 当前模型,通过经验风险极小化确定下一棵决策树的参数
当前模型,通过经验风险极小化确定下一棵决策树的参数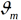
![]()
由于树的线性组合可以很好的拟合训练数据,即使数据中的输入和输出之间的关系很复杂也是如此,所以提升树是高级的学习方法.
不同问题的提升树的学习方法主要区别在于使用的损失函数不同,包括使用平方误差损失函数的回归问题,用指数损失函数的分类问题,以及一般损失函数的决策问题.
3.2回归问题的提升树算法
输入:训练数据集T={(x1,y1),(x2,y2),(x3,y3),...,(xn,yn)},xi属于Rn,yi属于R
输出:提升树fm(x)
具体过程:
(1)初始化
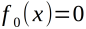
(2)对m=1,2,3....,M
(a)按式子计算残差
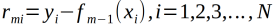
(b)拟合残差学习一个回归树,得到
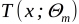
(c)更新
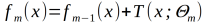
(3)得到回归提升树
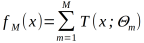
3.3梯度提升
提升树利用加法模型和前向分步算法实现学习优化过程,当损失函数是平方损失和指数损失时,每一步的优化都是比较简单,但是对于一般的损失函数,往往每一步优化都不是很容易,为此,Frediman提出梯度
提升算法,利用损失函数的负梯度在当前模型的值作为回归问题提升算法中残差的近似值,拟合一个回归树.
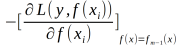
梯度提升算法具体实现步骤:
输入:训练数据集T={(x1,y1),(x2,y2),(x3,y3),...,(xN,yN)},xi属于Rn,yi属于R,损失函数L(y,f(X))
输出:回归树f(x)
(1)初始化
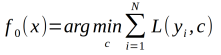
(2)对m=1,2,3,....,M
(a)对i=1,2,3,...,N计算残差
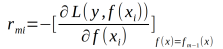
(b)对拟合一个回归树,得到第m颗树的叶节点区域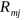 ,j=1,2,3....,J
,j=1,2,3....,J
(c)对于J=1,2,3,...J,计算系数C
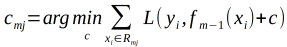
(d)更新
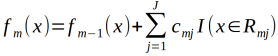
(3)得到回归树
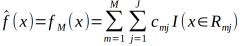
算法解释:
第一步初始化,估计使损失函数极小化的常数值,它是只有一个根节点的树
第二步a计算损失函数的负梯度在当前模型的值,将它作为残差的估计,对于平方损失函数,他就是通常所说的残差,对于一般的损失函数,他就是残差的近似值
第二步b估计回归树节点区域,以拟合残差的近似值
第二步c利用线性搜索估计叶节点区域的值,使损失函数极小化
第二步d更新回归树
第三步输出最终模型f(x)
4 总结
[1] AdaBoost算法特点是通过迭代每次学习的一个基本分类器,每次迭代中,提高那些被前一轮分类器错误分类数据的权值,降低那些被正确分类的数据的权值,最后AdaBoost将基本分类器线性组合为强分类器,其中给分类误差率小基本分类器较大的权值,给分类误差大的基本分类器以小的权值
[2] AdaBoost算法的一个解释是该算法实际是一个前向分步算法的一个实现,在这个方法里,模型是加法模型,损失函数是指数模型,算法是前向分步算法
每一步极小化损失函数,得到参数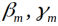
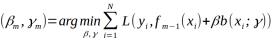
[3 ]提升树是以分类树和回归树为基本分类器的提升方法,提升树被认为是统计学习中比较有效的学习方法
前一篇文章地址:机器学习理论决策树算法第二卷http://www.cnblogs.com/fengdashen/p/7642647.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号