

redis集群
1、概述
通过上一篇文章的内容,Redis主从复制的基本功能和进行Redis高可用集群监控的Sentinel基本功能基本呈现给了读者。从这篇文章开始我们一起来讨论Redis中两种高性能集群方案,并且在讨论过程中将上一篇文章介绍的高可用集群方案结合进去。这两种高性能集群方案是:Twemproxy和Redis自带的Cluster方案。
2、Redis高性能集群:Twemproxy
2-1、Twemproxy概要
Twemproxy是一个Twitter开源的一个Redis/Memcache代理服务器,最早也是Twitter在使用。在Twitter决定开发Twemproxy时,互联网领域使用最广泛的缓存技术还是Memcache,那个时候Redis并没有提供原生的Cluster功能,甚至没有Bate版本。而Twemproxy(也称为nutcraker)恰恰是为了解决将多个独立的Redis节点组成集群,同时提供缓存服务的问题。
您可以在GitHub上下载Twemproxy(https://github.com/twitter/twemproxy)。这个地址也可以算作Twemproxy的官网了,其上对Twemproxy的特性进行了简要描述,包括:轻量级的快速访问代理、减少客户端对Redis服务的直连、支持多个Redis节点同时工作、支持数据分片、支持多种Hash算法、故障检查和故障节点自动排除、支持多种操作系统Linux, BSD, OS X 以及 Solaris…… 。
但是官网上并没有明确介绍Twemproxy的缺点,而且细心的朋友可以观察到官网上的源代码已经有相当时间没有更新了,这能说明什么问题呢?本文后续内容将进行说明。下图说明了Twemproxy的功能定位:
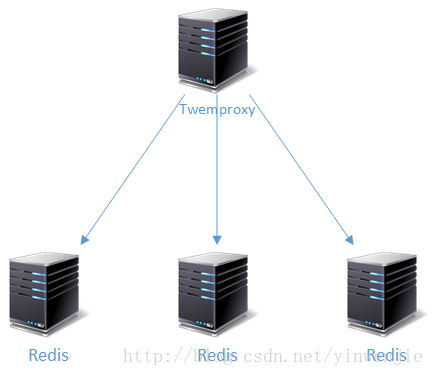
2-2、Twemproxy基本配置
Twemproxy的基本配置非常简单,直接解压安装后就可以运行。它的主要配置文件在conf目录下的“nutcracker.yml”文件。由于Twemproxy的安装太简单了,本文就不再进行描述了,这里给出安装命令就可以了(CentOS 6.X / 7.X):
-
// 先安装automake、libtool等第三方支持组件
-
# yum install -y automake libtool
-
// 然后解压下载的Twemproxy压缩包
-
// 进入解压的目录后运行(生成configure )
-
# autoreconf -fvi
-
// 正式开始安装
-
# ./configure --prefix=您的安装目录
-
# make && make install安装后打开“nutcracker.yml”文件,这个文件实际上已经有内容了,相当于一个各种运行场景下的配置示例。各位读者可以将这些配置信息注释掉或者直接删除。这里我们给出配置文件中一些关键的配置属性,大家只需要知道这些配置属性的意义,就可以进行灵活操作了:
-
listen:这个参数用于设置Twemproxy监控的IP和端口信息,如果要监控本机的所有IP设备,则设置为0.0.0.0,例如0.0.0.0:22122。
-
hash:这个参数非常重要所以多说几句。Twemproxy可以使用一致性Hash算法,通过计算Key的Hash值定位这个Key对应的数据存储在下层Redis节点的哪个位置。注意不是计算Key的数据结构,而是Key对应数据的存储位置。Twemproxy支持多种Hash算法,包括:md5、crc16、fnv1_64、fnv1a_64、fnv1_32、fnv1a_32、hsieh、murmur、jenkins等。之前我们介绍过,考虑采用哪种Hash算法有两个重要指标:Hash算法的速度和Hash算法的碰撞率。例如之前号称破解了MD5算法的王小云教授就是依靠Hash碰撞完成的,但实际上这种方式算不算完全破解呢?行业内就有很多种观点了,这里笔者经验有限就不展开讨论了。但MD5算法的两个事实依然是存在的:MD5任然是不可逆的,同时现成的破解站点也是存在的:http://www.ttmd5.com/。另外两个事实是MD5算法的碰撞率确实是各种Hash算法中碰撞率非常低的,但它确实不是所有Hash算法中速度最快的。显然,这里我们更看重的Hash值的计算速度而不是碰撞率,产生Hash碰撞的两个Key其后果无非是被分配到同一个Redis节点进行存储而已。所以这里我们推荐设置两种Hash算法,murmur和fnv1a_64。
-
hash_tag:为了避免在业务级别有关联的数据因为Key的Hash值不同而被散落在不用的Redis服务上(原因是当存储部分相关联数据的Redis下线,这个完整的业务数据就会受到影响),Redis提供了一个设置参数hash_tag来框定一个Key的部分字符串,并对它进行Hash计算。这样就可以保证有关联的业务数据在进行Hash计算时得到同一个计算结果,从而被分配到一个Redis节点进行存储。hash_tag由两个字符组成,举个例子,设置hash_tag为”[]”,这时客户端通过Twemproxy存储两个Key:“user[yinwenjie]”、“sex[yinwenjie]”,那么当Twemproxy计算这两个Key的Hash值时,就只会采用“[]”中的字符串“yinwenjie”进行,所以计算出来的Hash值都是一样的。最终这两个Key都会落到同一个Redis节点上进行存储。
-
distribution:依据Key的数据分配模式。Twemproxy本身并不存储数据,它的一个重要功能就是依据客户端传来的Key,对存储数据的真实Redis节点进行定位。定位方式包括三种:ketama,一致性Hash算法,关于一致性Hash算法的介绍可以参考这篇文章:http://blog.csdn.net/yinwenjie/article/details/46620711#t1。modula,这种数据分配模式,是根据Key的Hash值取模,模的数量就是下层可工作的Redis节点数量。random,完全随机分配Key对应的真实Redis节点。
-
timeout:这是一个超时时间,用来指定等待和Redis建立连接的超时时间,以及从Redis收到响应的超时时间。
-
backlog:“The TCP backlog argument. Defaults to 512.”这是官网上的解释,很简单不是吗?实际上我们介绍Redis时也出现过类似的参数,这个参数允许当前同时进行连接的有效TCP连接数量,但是请配合Linux系统下的somaxconn的设置进行使用,否则它会失效。
-
preconnect:这个参数的默认值为false,主要指代当Twemproxy服务启动时,是否需要预连接到下层的Redis服务上。
-
redis、redis_auth和redis_db: Twemproxy可以作为Redis和Memcache两种缓存服务的代理,当redis参数设置为false时代表它将作为Memcache的代理。另外如果下层的Redis设置了权限验证信息,则Twemproxy还要通过redis_auth配置项进行相应的设置。最后,由于Redis支持多个数据库,那么Twemproxy默认情况下将提供编号为“0”的数据库的代理,如果要改变请通过redis_db参数进行设置。
-
server_connections:这个参数设置Twemproxy可以在每一个下层Redis/Memcache服务上同时使用的连接数量,默认的值为1。
-
auto_eject_hosts、server_failure_limit和server_retry_timeout:Twemproxy支持自动下线(不再代理)失败的Redis服务,如果要打开这个功能,请设置auto_eject_hosts参数为true。这时,Twemproxy会在重试server_failure_limit次数后将还没有连接测试成功的Redis服务从自身代理列表上去掉。而server_retry_timeout设置了每一次测试连接的等待超时时间。
-
servers:这个参数是一个列表,列出了Twemproxy代理的Redis的IP地址、访问端口和权重。
以下展示了一个完整的可以使用的Twemproxy代理的配置文件:
-
beta:
-
listen: 0.0.0.0:22122
-
hash: fnv1a_64
-
hash_tag: "{}"
-
distribution: ketama
-
auto_eject_hosts: false
-
timeout: 400
-
redis: true
-
servers:
-
- 192.168.61.140:6379:1 server1
-
- 192.168.61.145:6379:1 server2
-
-
#原有配置文件中的其它配置信息如果不使用则可以注释掉
以上配置信息中的各个属性已经在前文详细介绍,这里就不再赘述了。以下是Twemproxy的启动指令,记得要首先设置Linux下的环境变量:
-
-
// 您还可以通过以下命令测试配置文件的正确性
-
-
// 还有更多参数可选
-
Usage: nutcracker [-?hVdDt] [-v verbosity level] [-o output file]
-
[
-
[
-
-
// 关于这些参数更详细的使用说明,可以参考官方文档中的说明
2-3、LVS + Twemproxy + Keepalived + Redis + Redis Sentinel + Sentinel Agent
在生产环境下搭建Redis高性能集群,如果其中只使用一个Twemproxy节点,那肯定是不合理的。因为那样做会存在Twemproxy单节点故障问题,所以至少应该使用两个Twemproxy节点。又因为Twemproxy服务的工作相对独立,为了增加访问性能可以使用两个甚至多个Twemproxy节点同时提供服务,其上统一使用LVS服务进行负载分发。根据这样的描述,我们可以构建一种在生产环境下使用的Redis高性能集群方案:
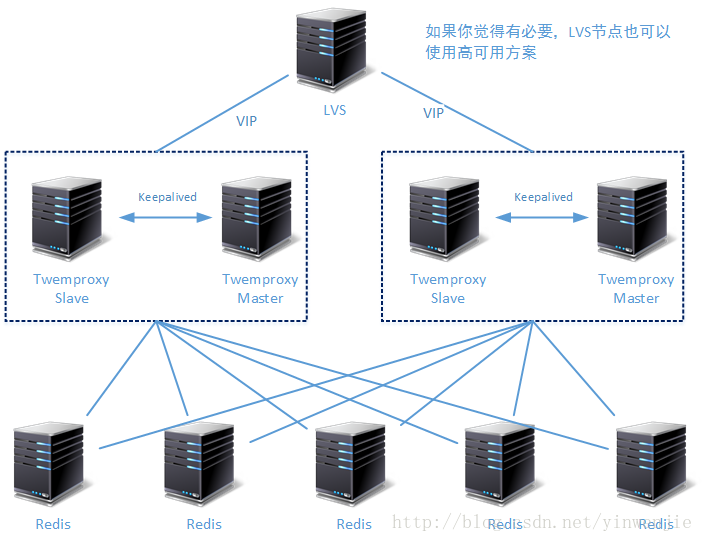
上图中我们使用了两组Twemproxy节点,每一组都有两个Twemproxy节点在同一时间分别处于Active状态和Standby状态,在使用Keepalived组件进行状态监控和浮动IP切换。这四个Twemproxy节点的配合信息完全一样,保证了无论数据读写请求通过LVS到达哪一个Twemproxy节点,最终计算出来的目标Redis节点都是一样的。
但是以上方案还是有问题,就是单个Redis节点的高可用性无法保证。虽然在这样的Redis集群中,每一个活动的Redis节点在宕机后都可以被Twemproxy自动下线,造成的数据丢失情况也因为使用了一致性Hash算法而被限制到了一个可控制的范围。但是毕竟会丢失一部分数据,而且丢失的数据规模会和集群中Redis节点数量成反比关系。所以我们还需要在上一个集群方案的设计上再进行调整,加入我们在上一篇文章中介绍的Redis主从同步方案和Sentinel监控功能,形成第二种方案。
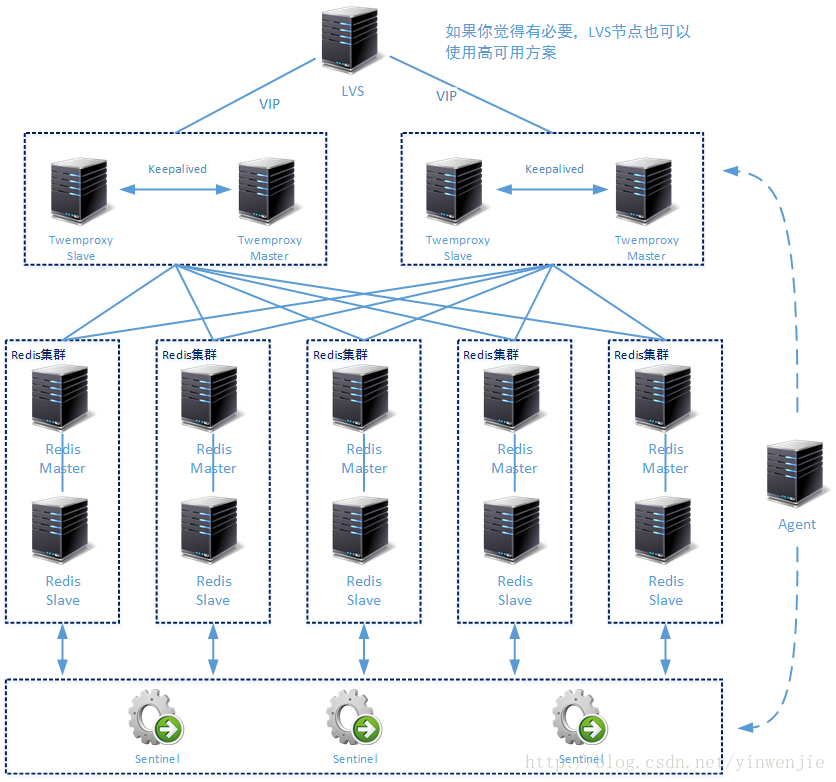
Twemproxy提供了一个配合使用的扩展组件:Redis_Twemproxy_Agent,它的作用是监控Sentinel中Master节点的情况,并且将最新的Master节点情况通知Twemproxy。这样一来当下层某组Redis高可用集群发生Master—Slave状态切换时,Twemproxy就会适时对其下层代理配置情况作出调整。
另外,上图中给出的第二种生产环境下的Redis集群方案,一共有5组独立运行的Redis高可用集群组,每组Redis高可用集群都有一个Master节点和至少一个Slave节点,它们之间使用Redis原生提供的数据复制功能保持数据同步。最后这些Redis高可用集群组通过一组Sentinel进行状态监控,而这组Sentinel也是同时拥有一个Master节点和两个Slave节点的高可用集群。
3、Redis高性能集群:Redis Cluster
3-1、Twemproxy的生产环境问题
-
可维护性上的问题:
LVS + Twemproxy + Keepalived + Redis + Sentinel + Sentinel Agent 的架构方案应该是笔者迄今为止介绍的层次最多,且每层组件最多的单一系统架构。Keepalived在LVS和Twemproxy都有使用,所以在不将Keepalived单独算作一层的情况下就是4层结构(这里说的层次都限于指本公司/机构的运维团队需要进行维护的系统组件)。而我们介绍过的Nginx集群方案是两层架构(LVS+Nginx),由于智能DNS路由一般是购买所以不参与计算;介绍过的ActiveMQ生产集群可以是三层架构(Zookeeper + ActiveMQ + LevelDB),也可以是两层架构(ActiveMQ + KahaBD/关系型数据库);介绍过的MySQL分库分表集群是三层架构(LVS + MyCAT + MySQL节点)。架构层次越多、每一层使用的组件越多,给运维团队带来的维护压力就越大,给生产环境带来的不稳定因素也越大。很显然从运维角度出发,为了解决单一功能而使用四层架构的情况是不太多见的——除非业务功能不能改变且系统架构层面又没有替代方案。
-
执行性能和设计思路问题:
Twemproxy并不是目前执行速度最快的Redis Proxy产品,例如豌豆荚在2014年开源的一款产品Codis就可以当做Twemproxy的替代方案。Codis对下层Redis节点的组织方式个人认为要优于Twemproxy,例如它将下层的Redis节点明确分为多个组,每个组中有一个Master和至少一个Slave节点,并且采用了类似随后要介绍的Redis Cluster那样的预分片方式(Slot),另外它还采用了ZK对各节点的工作状态进行协调。要知道Twemproxy虽然支持健康检查,也支持宕机节点的自动删除,但是Twemproxy并不支持数据转移。也就是说当某个Redis节点下线后,其上的数据也不会转移到其它节点上,而且Twemproxy中使用一致性Hash算法的基点或者取模运算所使用的基数也会发生变化。而如果引入的组的概念后,就可以减轻这个问题产生的风险,因为在一个组中的Master节点一旦出现问题,就会有Slave节点来接替它,而不会出现数据丢失问题。最后,根据豌豆荚自己的测试和广大网友自行测试的结果看,Codis对下层Redis节点的代理性能也要优于Twemproxy。
-
其它问题:
Redis的数据结构中,我们可以使用Set结构进行交并补运算。但是Twemproxy代理不支持这样的运算。另外Twemproxy也不对事务功能提供支持。
3-2、Redis原生的Cluster支持
可以说Twemproxy是早期Redis原生的Cluster没有成熟时的替代方案,而后Redis官方推荐的高性能集群方案还是基于其原生的Redis Cluster功能。Redis Cluster从Redis 3.0开始引入,实际上那个时候还是一个Bate版本,光放也不建议在生产环境下使用。但是到了目前最新的Version 3.2版本,Redis Cluster已经非常稳定了。

(上图来源于网络)
3-3、Redis Cluster基本配置示例
这里我们给出一个Redis Cluster的安装示例,首先介绍一下这个Redis Cluster的配置示例要达到的部署效果,这样才便于各位读者继续阅读。在这个示例场景中我们有两台物理机,每台物理机上启动了三个Redis节点,一共六个节点,并让它们按照Cluster模式工作起来。如下表所示:
| IP和端口 | 配置文件名 |
|---|---|
| 192.168.61.140:6379 | redis.conf.140_6379 |
| 192.168.61.140:6380 | redis.conf.140_6380 |
| 192.168.61.140:6381 | redis.conf.140_6381 |
| 192.168.61.145:6379 | redis.conf.145_6379 |
| 192.168.61.145:6380 | redis.conf.145_6380 |
| 192.168.61.145:6381 | redis.conf.145_6381 |
请注意,在生产环境中笔者并不建议在一台物理机上/虚拟机上部署多个Redis节点,因为这样大大增加了多个Redis节点同时不可用的风险,但这是示例场景所以无所谓啦。
3-3-1、Redis安装和配置文件部署
由于有六个节点参与到集群中,所以我们需要准备六份不同的配置文件。读者可以将这6个文件存放到不同的文件夹下:
-
========== 192.168.61.145:6379 ==========
-
######### NETWORK #########
-
bind 192.168.61.145
-
port 6379
-
######### GENERAL #########
-
pidfile "/var/run/redis_6379.pid"
-
######### REDIS CLUSTER #########
-
cluster-enabled yes
-
cluster-config-file nodes.145_6379
-
cluster-node-timeout 15000
-
######### APPEND ONLY MODE #########
-
appendonly yes
-
-
========== 192.168.61.145:6380 ==========
-
######### NETWORK #########
-
bind 192.168.61.145
-
port 6380
-
######### GENERAL #########
-
pidfile "/var/run/redis_6380.pid"
-
######### REDIS CLUSTER #########
-
cluster-enabled yes
-
cluster-config-file nodes.145_6380
-
cluster-node-timeout 15000
-
######### APPEND ONLY MODE #########
-
appendonly yes
-
-
========== 192.168.61.145:6381 ==========
-
######### NETWORK #########
-
bind 192.168.61.145
-
port 6381
-
######### GENERAL #########
-
pidfile "/var/run/redis_6381.pid"
-
######### REDIS CLUSTER #########
-
cluster-enabled yes
-
cluster-config-file nodes.145_6381
-
cluster-node-timeout 15000
-
######### APPEND ONLY MODE #########
-
appendonly yes
-
-
========== 192.168.61.140:6379 ==========
-
######### NETWORK #########
-
bind 192.168.61.140
-
port 6379
-
######### GENERAL #########
-
pidfile "/var/run/redis_6379.pid"
-
######### REDIS CLUSTER #########
-
cluster-enabled yes
-
cluster-config-file nodes.140_6379
-
cluster-node-timeout 15000
-
######### APPEND ONLY MODE #########
-
appendonly yes
-
-
========== 192.168.61.140:6380 ==========
-
######### NETWORK #########
-
bind 192.168.61.140
-
port 6380
-
######### GENERAL #########
-
pidfile "/var/run/redis_6380.pid"
-
######### REDIS CLUSTER #########
-
cluster-enabled yes
-
cluster-config-file nodes.140_6380
-
cluster-node-timeout 15000
-
######### APPEND ONLY MODE #########
-
appendonly yes
-
-
========== 192.168.61.140:6381 ==========
-
######### NETWORK #########
-
bind 192.168.61.140
-
port 6381
-
######### GENERAL #########
-
pidfile "/var/run/redis_6381.pid"
-
######### REDIS CLUSTER #########
-
cluster-enabled yes
-
cluster-config-file nodes.140_6381
-
cluster-node-timeout 15000
-
######### APPEND ONLY MODE #########
-
appendonly yes
以上只是列举了要参与Redis Cluster的六个节点中和本节内容相关的重点配置项,包括网络配置、一般性配置和集群部分的配置。其它的配置项可以根据读者所处技术环境的自行决定,例如是否开启主动SNAPSHOTTING的策略问题,因为Cluster中的Master都会有一个或者多个Slave节点,所以基本上一组高可用集群的数据不会同时丢失,而Master和Slave间的数据同步还是依靠Redis原生的主从同步方案完成的,所以Redis Master节点还是会做被动作SNAPSHOTTING动作。以下是六个节点的启动命令:
-
// 启动145上的三个redis节点
-
# redis-server ./redis.conf.145_6379 &
-
# redis-server ./redis.conf.145_6380 &
-
# redis-server ./redis.conf.145_6381 &
-
// 启动140上的三个redis节点
-
# redis-server ./redis.conf.140_6379 &
-
# redis-server ./redis.conf.140_6380 &
-
# redis-server ./redis.conf.140_6381 &
以上启动命令和您放置配置文件具体位置有关、和您是否设定了环境变量有关,还和您准备如何查看命令执行日志有关。所以具体执行参数肯定是有差异的。请注意,在第一次单独启动某个Redis节点时,您可能会看到类似以下的提示:
-
//============= redis.conf.145_6380节点
-
......
-
18449:M 29 Dec 18:32:52.036 # I have keys for unassigned slot 95. Taking responsibility for it.
-
18449:M 29 Dec 18:32:52.036 # I have keys for unassigned slot 219. Taking responsibility for it.
-
18449:M 29 Dec 18:32:52.038 # I have keys for unassigned slot 641. Taking responsibility for it.
-
......
-
-
//============= redis.conf.145_6381节点
-
......
-
9582:M 29 Dec 18:43:49.048 # I have keys for unassigned slot 95. Taking responsibility for it.
-
9582:M 29 Dec 18:43:49.048 # I have keys for unassigned slot 219. Taking responsibility for it.
-
9582:M 29 Dec 18:43:49.048 # I have keys for unassigned slot 641. Taking responsibility for it.
-
......
这是因为Redis启动时,会自动创建技术人员在cluster-config-file配置项设定的集群配置文件,例如nodes.140_6380、nodes.140_6381这些文件,并且会默认托管一些slots。但细心的读者可以发现,这六个节点独立启动时默认托管的slots信息都是一样的。这是因为这些节点还没有建立通讯机制,并不能协调slot的管理信息。而且这些cluster-config-file中都会默认自身节点是一个Master节点。
经过以上过程我们启动了六个节点,但是到目前为止这六个节点还是独立工作的并没有形成集群。这是因为各个cluster-config-file中并没有明确协调哪些节点将成为Master节点,哪些节点将成为Slave节点并且他们的主从映射关系,也没有协调任何和节点发现有关的信息,同样也没有协调各个节点的ID信息或者节点所映射的Master的ID信息,更没有协调各个节点分别负责的slot信息。那么以上这些协调动作都是通过下一个操作步骤。

(上图说明了各个Redis节点单独启动后的Redis Cluster状态)
3-3-2、Ruby安装和集群命令运行
Redis Cluster通过运行一个Ruby脚本进行初始化和启动,如果您的操作系统还没有安装Ruby,请进行安装(以下示例的安装命令适用于CentOS):
-
# yum install -y ruby rubygems
-
......
-
# gem install redis
-
Successfully installed redis-3.3.2
-
1 gem installed
-
Installing ri documentation for redis-3.3.2...
-
Installing RDoc documentation for redis-3.3.2...
-
......
在Redis的源文件目录的src目录中,有一个Ruby脚本文件“redis-trib.rb”,通过运行这个脚本文件可以完成Redis Cluster的初始化和启动操作。如果各位读者希望以后都能方便的运行这个脚本文件,可以先将这个脚本文件Copy到Redis的执行目录下:
-
# cp 你的源码路径/redis-trib.rb /usr/local/bin/redis-trib.rb
-
//或者
-
# cp 你的源码路径/redis-trib.rb /usr/redis/bin/redis-trib.rb
-
......
接下来就可以运行这个脚本了:
-
# redis-trib.rb create --replicas 1 192.168.61.140:6379 192.168.61.140:6380 192.168.61.140:6381 192.168.61.145:6379 192.168.61.145:6380 192.168.61.145:6381
-
>>> Creating cluster
-
>>> Performing hash slots allocation on 6 nodes...
-
Using 3 masters:
-
192.168.61.145:6379
-
192.168.61.140:6379
-
192.168.61.145:6380
-
Adding replica 192.168.61.140:6380 to 192.168.61.145:6379
-
Adding replica 192.168.61.145:6381 to 192.168.61.140:6379
-
Adding replica 192.168.61.140:6381 to 192.168.61.145:6380
-
M: 1cf10fb6d7c0ad4d936b1c061a99d370bda07757 192.168.61.140:6379
-
slots:5461-10922 (5462 slots) master
-
S: 8749db7b6a5860be63f592e94388239a7467cbb1 192.168.61.140:6380
-
replicates 3ee2a9f173ccbee3a5a79b082af2910be7d22e57
-
S: 33f9ee49963a32220984122278105cdda7761517 192.168.61.140:6381
-
replicates 120bc340ed1b24ba8e07368cf18d433094644e6e
-
M: 3ee2a9f173ccbee3a5a79b082af2910be7d22e57 192.168.61.145:6379
-
slots:0-5460 (5461 slots) master
-
M: 120bc340ed1b24ba8e07368cf18d433094644e6e 192.168.61.145:6380
-
slots:10923-16383 (5461 slots) master
-
S: 0b107150f7c075fe7ba701b64a9f7bf9f7896ead 192.168.61.145:6381
-
replicates 1cf10fb6d7c0ad4d936b1c061a99d370bda07757
-
Can I set the above configuration? (type 'yes' to accept): yes
以上命令中,create参数代表创建一个新的新的Redis Cluster,然后我们后给出了一个replicas参数,这个参数代表集群中的每一个Master节点对应多少个Slave节点,这里给出的数值是1,就代表每一个Master节点会对应一个Slave节点。需要注意,这里并不需要明确指定哪些节点将成为Master节点,哪些节点将成为Slave节点,而redis-trib会参考replicas参数的值自行计算得出。在命令的最后我们还给出了参与这个新的Redis Cluster的所有Redis节点的信息。
redis-trib会根据以上这些参数预计一个可能的配置信息,特别是初始化的Master和Slave节点的预计情况、每个节点的ID编号以及每个Master节点负责的Slot。接着redis-trib会将这份报告呈现给技术人员,由后者最终确定是否执行初始化。输入“yes”,redis-trib就将按照这份计划执行Redis Cluster的创建工作了:
-
......
-
>>> Performing Cluster Check (using node 192.168.61.140:6379)
-
M: 1cf10fb6d7c0ad4d936b1c061a99d370bda07757 192.168.61.140:6379
-
slots:5461-10922 (5462 slots) master
-
1 additional replica(s)
-
S: 33f9ee49963a32220984122278105cdda7761517 192.168.61.140:6381
-
slots: (0 slots) slave
-
replicates 120bc340ed1b24ba8e07368cf18d433094644e6e
-
S: 0b107150f7c075fe7ba701b64a9f7bf9f7896ead 192.168.61.145:6381
-
slots: (0 slots) slave
-
replicates 1cf10fb6d7c0ad4d936b1c061a99d370bda07757
-
M: 3ee2a9f173ccbee3a5a79b082af2910be7d22e57 192.168.61.145:6379
-
slots:0-5460 (5461 slots) master
-
1 additional replica(s)
-
S: 8749db7b6a5860be63f592e94388239a7467cbb1 192.168.61.140:6380
-
slots: (0 slots) slave
-
replicates 3ee2a9f173ccbee3a5a79b082af2910be7d22e57
-
M: 120bc340ed1b24ba8e07368cf18d433094644e6e 192.168.61.145:6380
-
slots:10923-16383 (5461 slots) master
-
1 additional replica(s)
-
[OK] All nodes agree about slots configuration.
-
>>> Check for open slots...
-
>>> Check slots coverage...
-
[OK] All 16384 slots covered.
到此为止6个节点的Redis Cluster就创建完成了,除了初始化创建Redis Cluster外,您还可以参考官方网站上的介绍完成Redis Cluster中的节点新增、删除或者其它操作:https://redis.io/topics/cluster-tutorial。
3-3-3、使用客户端进行连接
客户端进行集群环境的连接,就是一个更简单的工作了。实际上Redis的客户端并不需要连接到Redis Cluster中的所有节点,就可以完整操作Redis Cluster中的数据。这是因为每个Redis Cluster中的节点都清楚整个集群的全局情况,特别是Slot存在的位置。以下示例代码展示了如何通过Java代码连接到Redis Cluster:
-
......
-
JedisPoolConfig config = new JedisPoolConfig();
-
config.setMaxTotal(10);
-
config.setMaxIdle(2);
-
-
// 这里添加集群节点。可以添加多个节点,但并不是需要添加Cluster的所有节点
-
HostAndPort node0 = new HostAndPort("192.168.61.140", 6379);
-
HostAndPort node1 = new HostAndPort("192.168.61.145", 6379);
-
Set<HostAndPort> nodes = new HashSet<HostAndPort>();
-
nodes.add(node0);
-
nodes.add(node1);
-
-
// 创建和连接到集群
-
JedisCluster jedisCluster = new JedisCluster(nodes, 5000, 10, config);
-
-
//==============================
-
// 做你要做的Redis操作吧,少年
-
//==============================
-
-
jedisCluster.close();

 浙公网安备 33010602011771号
浙公网安备 33010602011771号