Spark课堂测试
1、 数据采集(要求至少爬取三千条记录,时间跨度超过一星期):(10分)
(1) 源程序代码:
# -*- coding: utf-8 -*-
import urllib.request
import json
import time
import random
def crawlProductComment(url):
#读取原始数据(注意选择gbk编码方式)
html = urllib.request.urlopen(url).read().decode('gbk')
#从原始数据中提取出JSON格式数据(分别以'{'和'}'作为开始和结束标志)
jsondata = html[27:-2]
#print(jsondata)
data = json.loads(jsondata)
#print(data['comments'])
#print(data['comments'][0]['content'])
#遍历商品评论列表
comments = data['comments']
print(comments)
return comments
data = []
for i in range(0,10):
#iphone8评论链接,通过更改page参数的值来循环读取多页评论信息
url = 'https://sclub.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98vv89597&productId=5001175&score=0&sortType=5&page=' + str(i) +'&pageSize=10&isShadowSku=0&fold=1'
comments = crawlProductComment(url)
data.extend(comments)
#设置休眠时间
time.sleep(random.randint(0,1))
print('-------',i)
with open('xiaomi_note_3.json','w') as f:
json.dump(data,f)
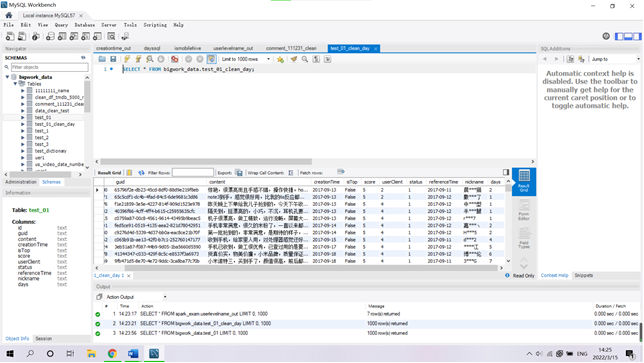
(2) 数据采集到本地文件内容截图(显示统计条数超过3000条和时间跨度)

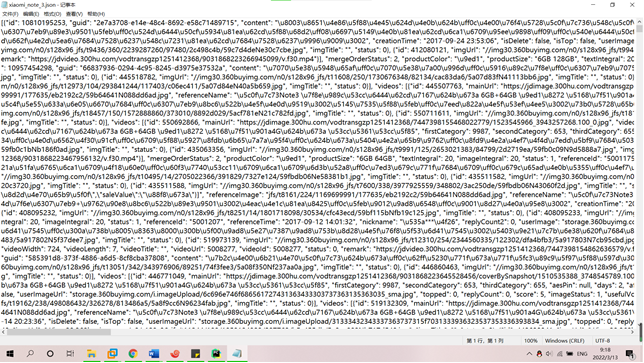
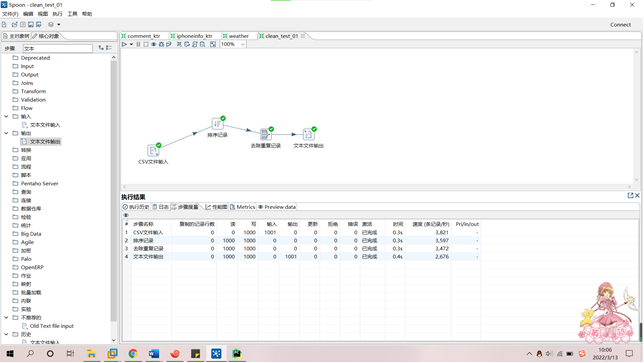
2、数据预处理:要求使用MapReduce或者kettle实现源数据的预处理,对大量的Json文件,进行清洗,以得到结构化的文本文件。(10分)
(1)去除用户评论表的重复记录结果截图;
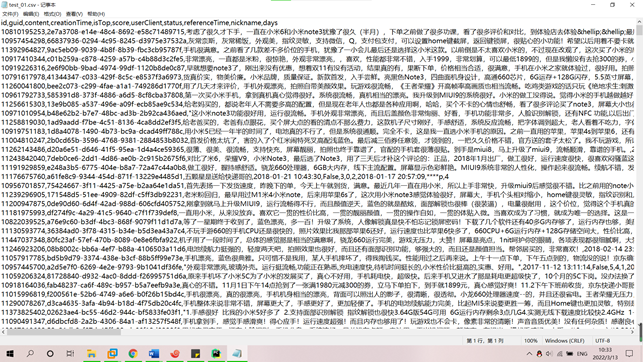
(3) 按照清洗后的数据格式要求提取相应的数据字段文件截图。
3、 数据统计:生成Hive用户评论数据:(15分)
(1)在Hive创建一张表,用于存放清洗后的数据,表名为pinglun,(创建数据表SQL语句),创建成功导入数据截图:
drop table if exists pinglun;
create table pinglun(
id string,
guid string,
content string,
creationTime string,
isTop string,
score string,
userClient string,
status string,
referenceTime string,
nickname string,
days string
)
row format delimited fields terminated by ',';
load data local inpath '/opt/module/data/ScalaExam/test_01.csv' into table pinglun;
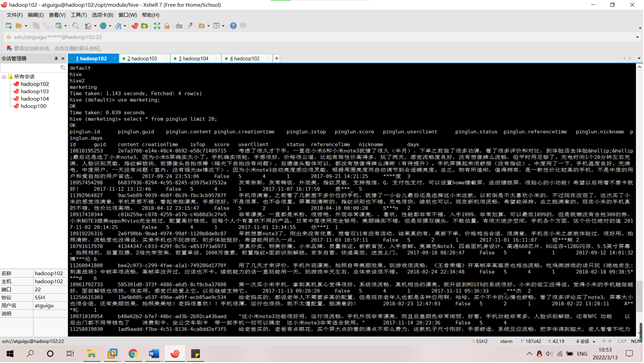
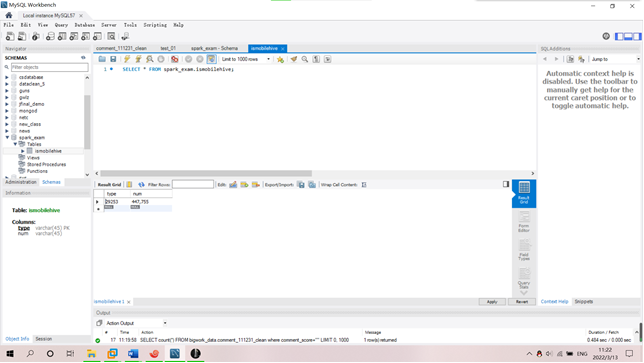
需求1:分析用户使用移动端购买还是PC端购买,及移动端和PC端的用户比例,生成ismobilehive表,存储统计结果;创建数据表SQL语句,创建成功导入数据截图
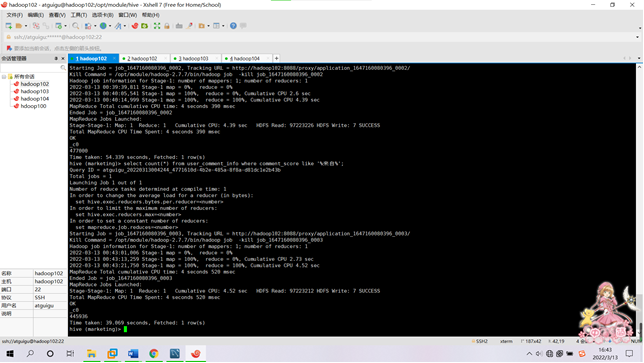

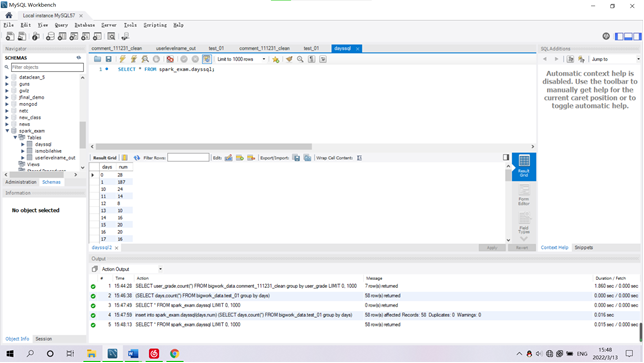
需求2:分析用户评论周期(收到货后,一般多久进行评论),生成dayssql表,存储统计结果;创建数据表SQL语句,创建成功导入数据截图
SELECT days,count(*) FROM bigwork_data.test_01 group by days;
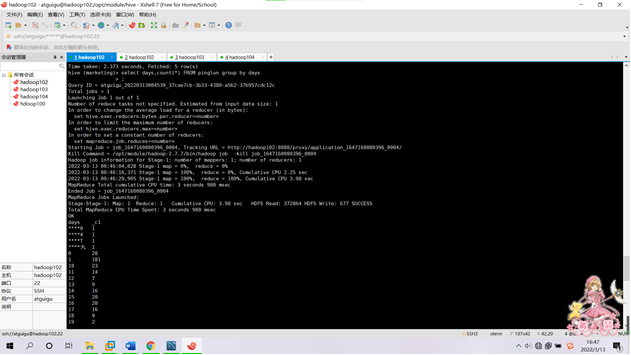
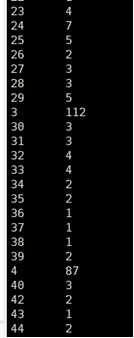
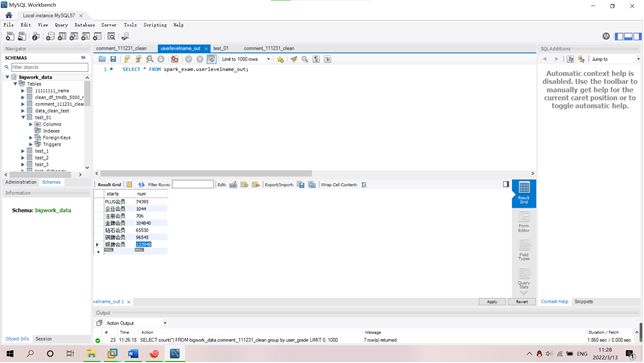
需求3:分析会员级别(判断购买此商品的用户级别),生成userlevelname_out表,存储统计结果;创建数据表SQL语句,创建成功导入数据截图
SELECT user_grade,count(*) FROM bigwork_data.comment_111231_clean group by user_grade;
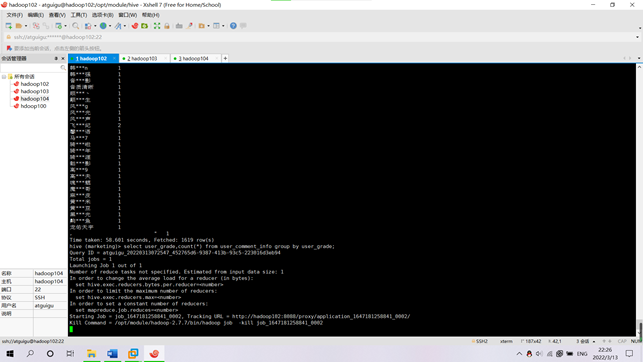
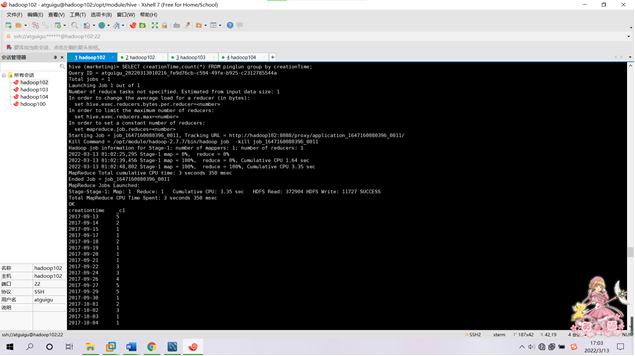
需求4:分析每天评论量,生成creationtime_out表,存储统计结果;创建数据表SQL语句,创建成功导入数据截图
SELECT creationTime,count(*) FROM bigwork_data.test_01_clean_day group by creationTime;
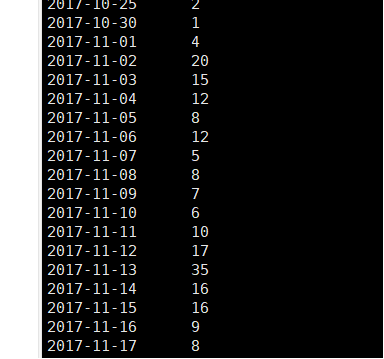
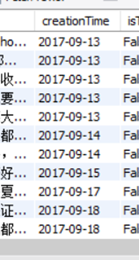
需求5:日期格式标准化后数据表前后对照截图
利用kattle格式化日期

使用剪切字符串

清洗前后对比


4、 利用Sqoop进行数据迁移至Mysql数据库:(5分)
五个表导入mysql数据库中五个表截图。
导入语句(只展示一个的,其他的类似):
bin/sqoop export --connect "jdbc:mysql://hadoop102:3306/test?useUnicode=true&characterEncoding=utf-8" --username root --password 123456 --table area_data --num-mappers 1 --export-dir /user/hive/warehouse/area_data --input-fields-terminated-by ","
Ismobilehive表
Dayssql表
Userlevelname_out表
Creationtime_out表

Pinglun表