大三寒假学习 spark学习 RDD的依赖关系和运行过程
窄依赖与宽依赖的区别:
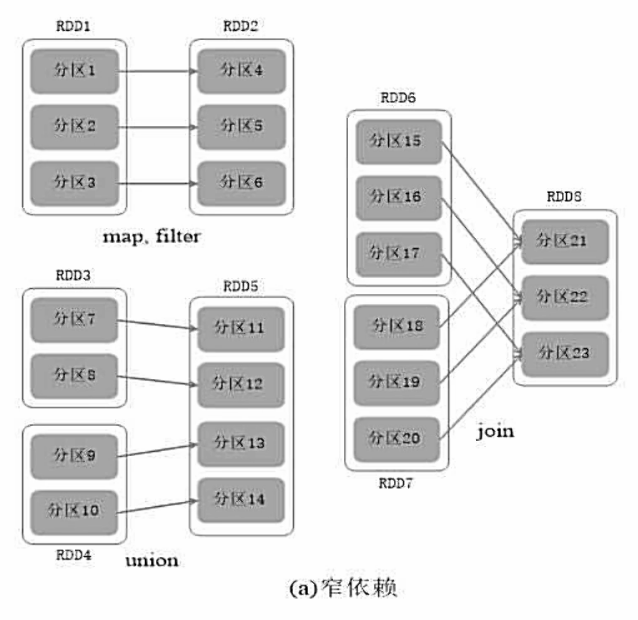
窄依赖:表现为一个父RDD的分区对应于一个子RDD的分区或多个父RDD的分区对应于一个子RDD的分区
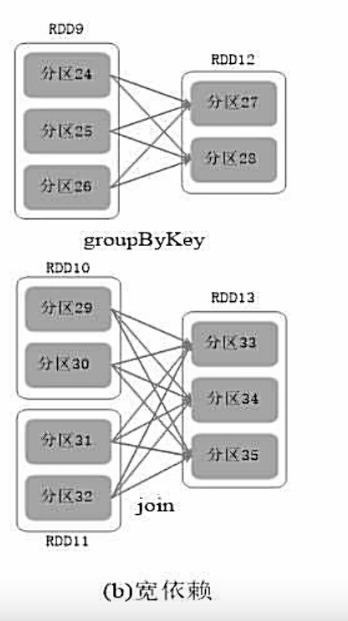
宽依赖:表现为存在一个父RDD的一个分区对应一个子RDD的多个分区
Stage的划分:
Spark通过分析各个RDD的依赖关系生成了DAG再通过分析各个RDD中的分区之间的依赖关系来决定如何划分Stage
根据RDD分区的依赖关系划分Stage:
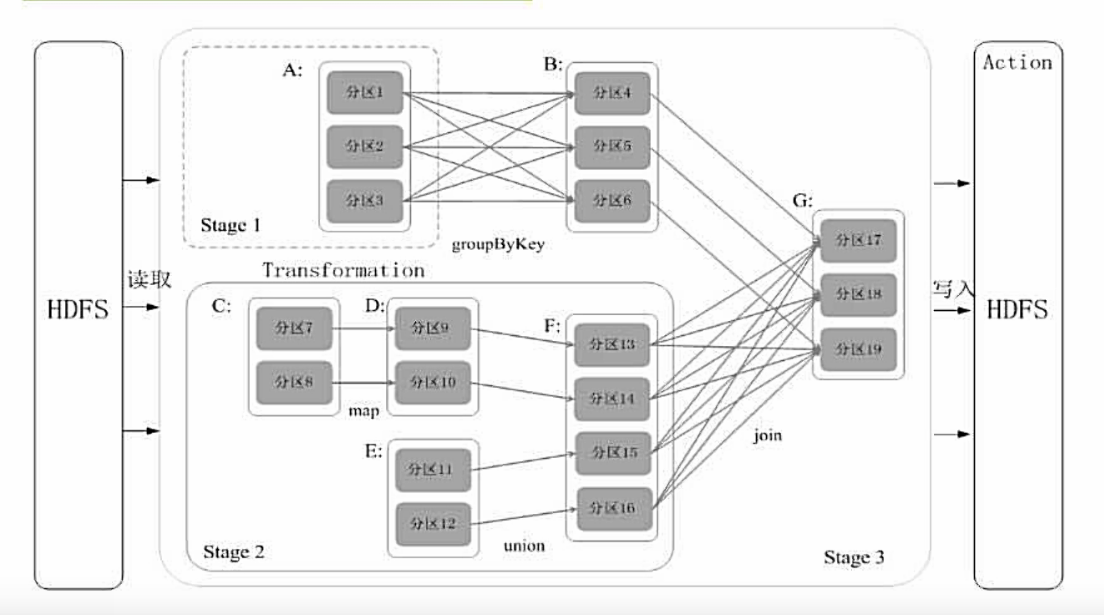
Stage的划分:
- 在DAG中进行反向解析,遇到宽依赖就断开
- 遇到窄依赖就把当前的RDD加入到Stage中
- 将窄依赖尽量划分在同一个Stage中,可以实现流水线计算
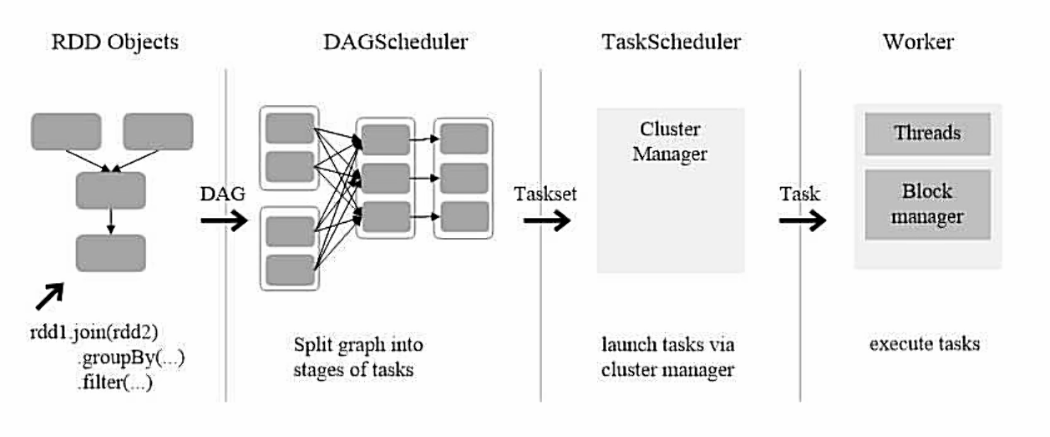
RDD运行过程:
- 创建RDD对象
- SparkContext负责计算RDD之间的依赖关系,构建DAG
- DAGScheduler负责把DAG图分解成多个Stage每个Stage中包含了多个Task每个Task会被TaskScheduler分发给各个WorkerNode上的Executor去执行
RDD在Spark中的运行过程:
分类:
大三寒假


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Ollama——大语言模型本地部署的极速利器
· 使用C#创建一个MCP客户端
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· Windows编程----内核对象竟然如此简单?
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
2021-01-20 大二寒假作业之《构建之法》读后感1