df_clean.apply(pd.to_numeric, errors='ignore')
在复习之前学习的pandas代码时发现这句话 df_clean.apply(pd.to_numeric, errors='ignore') 感到十分疑惑,apply()是什么函数,pd.to_numeric又是啥,errors=""有啥作用。
接下来一一解答:
一、map(), apply()和applymap()
1.map():
map() 是一个Series的函数,DataFrame结构中没有map()。map()将一个自定义函数应用于Series结构中的每个元素(elements)。
下面举一个例子 将w列都加1
test1=pd.DataFrame(np.arange(12).reshape(3, 4), index=list("abc"), columns=list("WXYZ"))#先构造一个随机的测试数据 print(test1) test1["W"]=test1["W"].map(lambda x:x+1)#将w列的数都加1 # #lambda在这里其实是在定义一个简单的函数,一个没有函数名的函数 print(test1)

2.apply():
apply()将一个函数作用于DataFrame中的每个行或者列
下面我们将w,x列相加
按列相加
test1['total'] = test1[['W', 'X']].apply(lambda x: x.sum(), axis=1)#按列相加 print(test1)
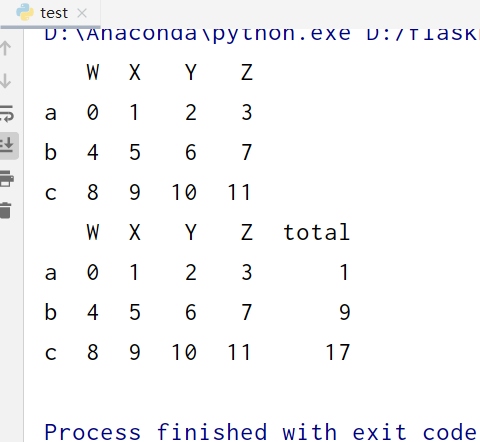
按行相加
test1.loc['total'] = test1[['W', 'X']].apply(lambda x: x.sum(), axis=0)#按行相加 print(test1)

3.applymap():
将函数做用于DataFrame中的所有元素(elements)
将所有元素都加5
def addFive(X): return X+5
test1=test1.applymap(addFive) print(test1)

二、pd.to_numeric
将参数转换为数字类型。
errors中参数的解释:
'raise'参数:无效的解析将引发异常
'corece'参数:将无效解析设置为NaN
'ignore'参数:无效的解析将返回输入
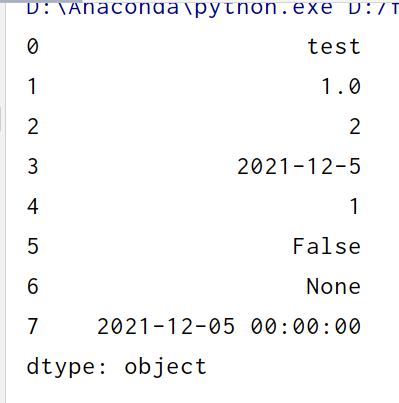
先构造数据
s = pd.Series(['test', '1.0', '2', '2021-12-5', 1, False, None, pd.Timestamp('2021-12-05')]) print(s)
执行raise会报错,因为该数据里面有非数字
pd.to_numeric(s,errors="raise")

执行ignore只对数字字符串转型,其他不转换
pd.to_numeric(s,errors="ignore")

执行coerce会将时间,bool,数字字符串转换为数字,其他为NaN
pd.to_numeric(s,errors="coerce")



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· 分享 3 个 .NET 开源的文件压缩处理库,助力快速实现文件压缩解压功能!
· Ollama——大语言模型本地部署的极速利器
· 使用C#创建一个MCP客户端
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· Windows编程----内核对象竟然如此简单?