HTTP协议篇(一):多路复用、数据流
管道机制、多路复用
管道机制(Pipelining)
HTTP 1.1 引入了管道机制(Pipelining),即客户端可通过同一个TCP连接同时发送多个请求。如果客户端需要请求两个资源,以前的做法是在同一个TCP连接里面,先发送A请求,然后等待服务器做出回应,收到后再发出B请求;而管道机制则允许浏览器同时发出A请求和B请求,但是服务器还是按照顺序,先回应A请求,完成后再回应B请求。
多路复用(Multiplexing)
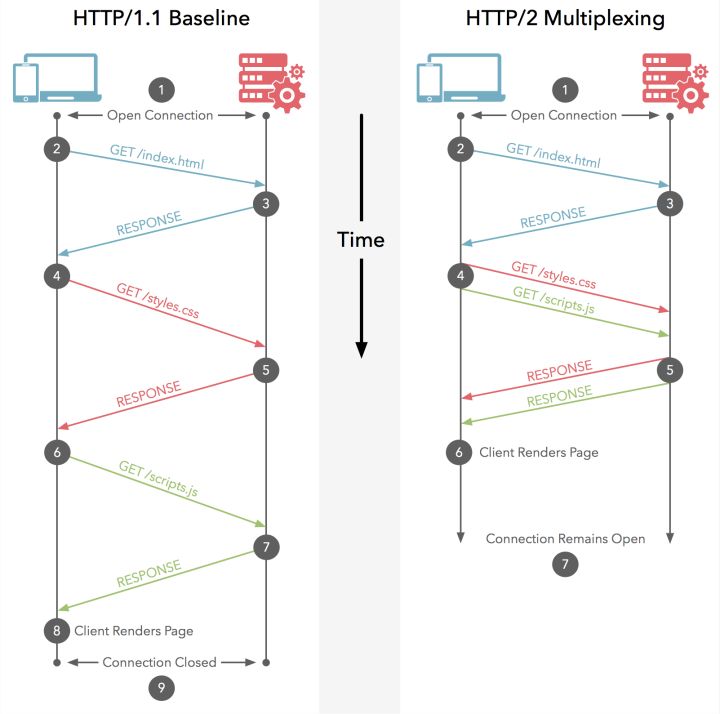
虽然 HTTP 1.1 默认启用长TCP连接,但所有的请求-响应都是按序进行的(这里的长连接可理解成半双工协议。即便是HTTP 1.1引入了管道机制,也是如此)。复用同一个TCP连接期间,即便是通过管道同时发送了多个请求,服务端也是按请求的顺序依次给出响应的;而客户端在未收到之前所发出所有请求的响应之前,将会阻塞后面的请求(排队等待),这称为"队头堵塞"(Head-of-line blocking)。
HTTP/2复用TCP连接则不同,虽然依然遵循请求-响应模式,但客户端发送多个请求和服务端给出多个响应的顺序不受限制,这样既避免了"队头堵塞",又能更快获取响应。在复用同一个TCP连接时,服务器同时(或先后)收到了A、B两个请求,先回应A请求,但由于处理过程非常耗时,于是就发送A请求已经处理好的部分, 接着回应B请求,完成后,再发送A请求剩下的部分。HTTP/2长连接可以理解成全双工的协议。
Content-Length
Content-length 声明本次响应的数据长度。keep-alive 连接可以先后传送多个响应,因此用Content-length来区分数据包是属于哪一个响应。在HTTP 1.0 中,Content-Length字段不是必需的,因为浏览器与服务器通信使用的是短连接,服务端发送完数据关闭TCP连接,就表明收到的数据包已经全了。
分块传输(Chunked)、数据流
分块传输(Chunked)
使用Content-Length字段的前提条件是,服务器发送响应之前,必须知道响应的数据长度。 对于一些很耗时的动态操作来说,这意味着,服务器要等到所有操作完成,才能发送数据,显然这样的效率不高。更好的处理方法是,产生一块数据,就发送一块,采用"流模式"(Stream)取代"缓存模式"(Buffer)。因此,HTTP 1.1 规定可以不使用Content-Length字段,而使用"分块传输编码"(Chunked Transfer Encoding)。只要请求或响应的头信息有Transfer-Encoding: chunked字段,就表明body将可能由数量未定的多个数据块组成。
每个数据块之前会有一行包含一个16进制数值,表示这个块的长度;最后一个大小为0的块,就表示本次响应的数据发送完了。

HTTP/1.1 200 OK Content-Type: text/plain Transfer-Encoding: chunked 25 This is the data in the first chunk 1C and this is the second one 3 con 8 sequence 0
数据流
HTTP/2 长连接中的数据包是不按请求-响应顺序发送的,一个完整的请求或响应(称一个数据流stream,每个数据流都有一个独一无二的编号)可能会分成非连续多次发送。数据包发送的时候,都必须标记所属的数据流ID,用来区分它属于哪个数据流。另外还规定,客户端发出的数据流,ID一律为奇数,服务器发出的,ID为偶数。数据流发送到一半的时候,客户端和服务器都可以发送信号(RST_STREAM帧)取消这个数据流。HTTP 1.1 取消数据流的唯一方法,就是关闭TCP连接;HTTP/2 取消某一次请求,同时保证TCP连接还打开着,可以被其他请求使用。客户端还可以指定数据流的优先级,优先级越高,服务器就会越早响应。
https://www.cnblogs.com/XiongMaoMengNan/p/8425724.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号