RPC 框架
RPC框架分层描述(RPC模型)
应用层 远程调用与远程调用的对应函数的实现功能
表示层 将调用名和参量打包
平台层(会话层) 建立对等实体的上下文映射、消息的发送接收机制、信息的处理机制
通信层 根据主机、端口或其他的一些信息建立通信联系。
整套rpc是一个pipeline的过程话的处理流程。
https://www.zhihu.com/question/25536695
关于RPC
你的题目是RPC框架,首先了解什么叫RPC,为什么要RPC,RPC是指远程过程调用,也就是说两台服务器A,B,一个应用部署在A服务器上,想要调用B服务器上应用提供的函数/方法,由于不在一个内存空间,不能直接调用,需要通过网络来表达调用的语义和传达调用的数据。
比如说,一个方法可能是这样定义的:
Employee getEmployeeByName(String fullName)
那么:
首先,要解决通讯的问题,主要是通过在客户端和服务器之间建立TCP连接,远程过程调用的所有交换的数据都在这个连接里传输。连接可以是按需连接,调用结束后就断掉,也可以是长连接,多个远程过程调用共享同一个连接。
第二,要解决寻址的问题,也就是说,A服务器上的应用怎么告诉底层的RPC框架,如何连接到B服务器(如主机或IP地址)以及特定的端口,方法的名称名称是什么,这样才能完成调用。比如基于Web服务协议栈的RPC,就要提供一个endpoint URI,或者是从UDDI服务上查找。如果是RMI调用的话,还需要一个RMI Registry来注册服务的地址。
第三,当A服务器上的应用发起远程过程调用时,方法的参数需要通过底层的网络协议如TCP传递到B服务器,由于网络协议是基于二进制的,内存中的参数的值要序列化成二进制的形式,也就是序列化(Serialize)或编组(marshal),通过寻址和传输将序列化的二进制发送给B服务器。
第四,B服务器收到请求后,需要对参数进行反序列化(序列化的逆操作),恢复为内存中的表达方式,然后找到对应的方法(寻址的一部分)进行本地调用,然后得到返回值。
第五,返回值还要发送回服务器A上的应用,也要经过序列化的方式发送,服务器A接到后,再反序列化,恢复为内存中的表达方式,交给A服务器上的应用
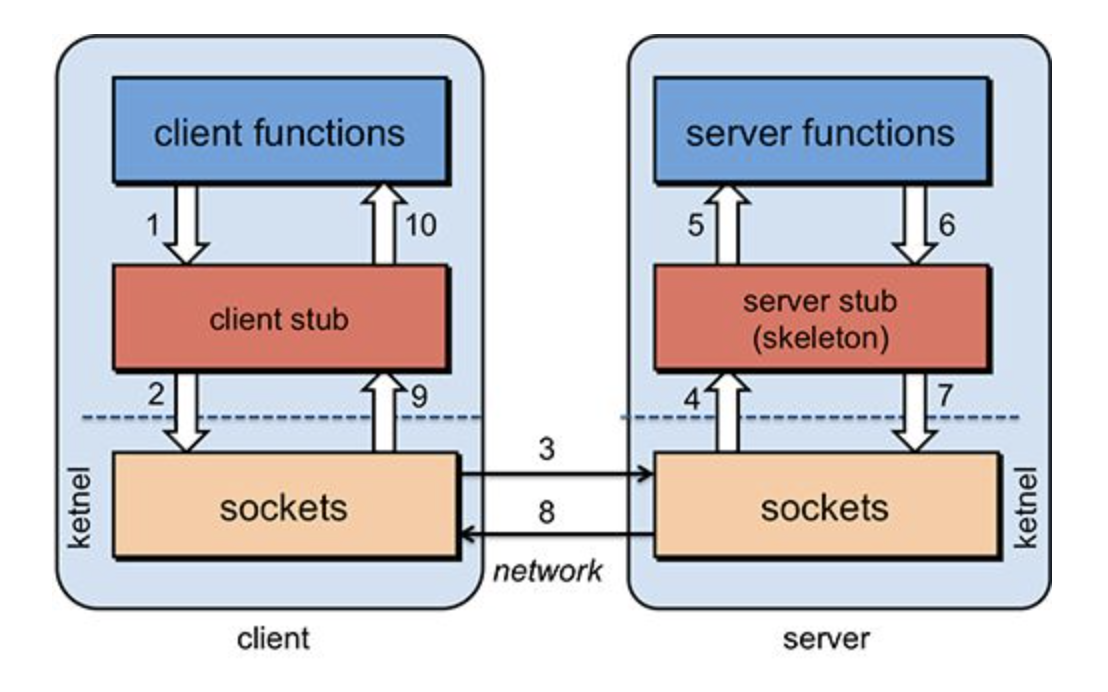
(图片来源:https://www.cs.rutgers.edu/~pxk/417/notes/03-rpc.html)
为什么RPC呢?就是无法在一个进程内,甚至一个计算机内通过本地调用的方式完成的需求,比如比如不同的系统间的通讯,甚至不同的组织间的通讯。由于计算能力需要横向扩展,需要在多台机器组成的集群上部署应用,
链接:https://www.zhihu.com/question/25536695/answer/221638079
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
在远程调用时,我们需要执行的函数体是在远程的机器上的,也就是说,Multiply是在另一个进程中执行的。这就带来了几个新问题:
- Call ID映射。我们怎么告诉远程机器我们要调用Multiply,而不是Add或者FooBar呢?在本地调用中,函数体是直接通过函数指针来指定的,我们调用Multiply,编译器就自动帮我们调用它相应的函数指针。但是在远程调用中,函数指针是不行的,因为两个进程的地址空间是完全不一样的。所以,在RPC中,所有的函数都必须有自己的一个ID。这个ID在所有进程中都是唯一确定的。客户端在做远程过程调用时,必须附上这个ID。然后我们还需要在客户端和服务端分别维护一个 {函数 <--> Call ID} 的对应表。两者的表不一定需要完全相同,但相同的函数对应的Call ID必须相同。当客户端需要进行远程调用时,它就查一下这个表,找出相应的Call ID,然后把它传给服务端,服务端也通过查表,来确定客户端需要调用的函数,然后执行相应函数的代码。
- 序列化和反序列化。客户端怎么把参数值传给远程的函数呢?在本地调用中,我们只需要把参数压到栈里,然后让函数自己去栈里读就行。但是在远程过程调用时,客户端跟服务端是不同的进程,不能通过内存来传递参数。甚至有时候客户端和服务端使用的都不是同一种语言(比如服务端用C++,客户端用Java或者Python)。这时候就需要客户端把参数先转成一个字节流,传给服务端后,再把字节流转成自己能读取的格式。这个过程叫序列化和反序列化。同理,从服务端返回的值也需要序列化反序列化的过程。
- 网络传输。远程调用往往用在网络上,客户端和服务端是通过网络连接的。所有的数据都需要通过网络传输,因此就需要有一个网络传输层。网络传输层需要把Call ID和序列化后的参数字节流传给服务端,然后再把序列化后的调用结果传回客户端。只要能完成这两者的,都可以作为传输层使用。因此,它所使用的协议其实是不限的,能完成传输就行。尽管大部分RPC框架都使用TCP协议,但其实UDP也可以,而gRPC干脆就用了HTTP2。Java的Netty也属于这层的东西。
有了这三个机制,就能实现RPC了,具体过程如下:
// Client端
// int l_times_r = Call(ServerAddr, Multiply, lvalue, rvalue)
1. 将这个调用映射为Call ID。这里假设用最简单的字符串当Call ID的方法
2. 将Call ID,lvalue和rvalue序列化。可以直接将它们的值以二进制形式打包
3. 把2中得到的数据包发送给ServerAddr,这需要使用网络传输层
4. 等待服务器返回结果
5. 如果服务器调用成功,那么就将结果反序列化,并赋给l_times_r
// Server端
1. 在本地维护一个Call ID到函数指针的映射call_id_map,可以用std::map<std::string, std::function<>>
2. 等待请求
3. 得到一个请求后,将其数据包反序列化,得到Call ID
4. 通过在call_id_map中查找,得到相应的函数指针
5. 将lvalue和rvalue反序列化后,在本地调用Multiply函数,得到结果
6. 将结果序列化后通过网络返回给Client
所以要实现一个RPC框架,其实只需要按以上流程实现就基本完成了。
其中:
- Call ID映射可以直接使用函数字符串,也可以使用整数ID。映射表一般就是一个哈希表。
- 序列化反序列化可以自己写,也可以使用Protobuf或者FlatBuffers之类的。
- 网络传输库可以自己写socket,或者用asio,ZeroMQ,Netty之类。
当然,这里面还有一些细节可以填充,比如如何处理网络错误,如何防止攻击,如何做流量控制,等等。但有了以上的架构,这些都可以持续加进去。
最后,有兴趣的可以看我们自己写的一个小而精的RPC库 tinyrpc(hjk41/tinyrpc),对于理解RPC如何工作很有好处。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号