java为什么要用类型擦除实现泛型?--c++,java,c# 的泛型是如何实现的
所以总结一下c++,java,c#的泛型。c++的泛型在编译时完全展开,类型精度高,共享代码差。java的泛型使用类型擦出,仅在编译时做类型检查,在运行时擦出,共享代码好,但是类型精度不行。c#的泛型使用混合实现方式,在运行时展开,类型精度高,代码共享不错。
很长一段时间我只知道java的泛型使用了被成为“类型擦除”的技术,但是具体的原因和实现细节一直不清楚,最近仔细“研究”了一下,发现了许多有趣的地方。其实有关泛型的知识我已经在组内做过一次分享。但我还是觉得有些地方讲的不够透彻,所以我打算把分享的一部分内容提取出来写成博客,串讲清楚其中的几个知识点,所以就有了这篇:《java为什么要用类型擦除实现泛型? 》
为什么需要泛型?
试想你需要一个简单的容器类,或者说句柄类,比如要存放一个苹果的篮子,那你可以这样简单的实现:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
class Fruit{}
class Apple extends Fruit{}
class Bucket{
private Apple apple;
public void set(Apple apple){
this.apple = apple;
}
public Apple get(){
return this.apple;
}
}
|
这样一个简单的篮子就实现了,但问题是它只能存放苹果,之后又出现了另外的一大堆水果类,那你就不得不为这些水果类分别实现容器:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
class Fruit{}
class Apple extends Fruit{}
class Banana extends Fruit{}
class Orange extends Fruit{}
class BucketApple{
private Apple apple;
public void set(Apple apple){
this.apple = apple;
}
public Apple get(){
return this.apple;
}
}
class BucketBanana{
private Banana banana;
public void set(Banana banana){
this.banana = banana;
}
public Banana get(){
return this.banana;
}
}
class BucketOrange{
private Orange orange;
public void set(Orange orange){
this.orange = orange;
}
public Orange get(){
return this.orange;
}
}
|
然后你发现你其实在做大量的重复劳动。所以你幻想你的语言编译器要是支持某一种功能,能够帮你自动生成这些代码就好了。
不过在祈求让编译器帮你生成这些代码之前,你突然想到了Object能够引用任何类型的对象,所以你只要写一个Object类型的Bucket就可以存放任何类型了。
|
1
2
3
4
5
6
7
8
9
10
11
|
class Bucket{
private Object object;
public void set(Object object){
this.object = object;
}
public Object get(){
return this.object;
}
}
|
但是问题是这种容器的类型丢失了,你不得不在输出的地方加入类型转换:
|
1
2
3
|
Bucket appleBucket = new Bucket();
bucket.set(new Apple());
Apple apple = (Apple)bucket.get();
|
而且你无法保证被放入容器的就是Apple,因为Object可以指向任何引用类型。
这个时候你可能又要祈求编译器来帮你完成这些类型检查了。
说道这里,你应该明白了泛型要保证两件事,第一:我只需要定义一次类,就可以被“任何”类型使用,而不是对每一种类型定义一个类。第二:我的泛型只能保存我指明的类型,而不是放一堆object引用。
实际上很多语言的泛型就是基于以上两点而实现的,下面我就将分别介绍c++,java,c# 的泛型是如何实现的。对比的原因是为了说明为什么它要这么实现,这样实现的优点和缺点是什么。
c++
宏
大部分人在大学都学过c语言,你一定记得c语言中有一种被称为宏的东西,宏能够在预编译期来“替换”代码。因为c++是兼容c的,所以宏在c++中同样可以使用。
比如下面这段代码:
|
1
2
|
#define square(x) x*x
int a = square(5);
|
在预处理期之后,你代码中所有的square(5);,都被替换成了 5*5。
同理,有人把c++中的模板称为高级宏,当我们在c++中定义一个Bucket模板类之后。可以分别去声明不同类型的模板实现。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
#include <iostream>
template<class T> class Bucket{
private:
T stuff;
public:
void set(T t){
this->stuff = t;
}
T get(){
return this->stuff;
}
};
class Fruit{};
class Apple : public Fruit{};
class Banana : public Fruit{};
class Orange : public Fruit{};
int main() {
std::cout << "Hello, World!" << std::endl;
Bucket<Apple> appleBucket;
appleBucket.set(Apple());
Bucket<Banana> bananaBucket;
bananaBucket.set(Banana());
return 0;
}
|
而当你在编译之前,c++的模板会进行展开,变成类似这个样子:
|
1
2
3
4
5
6
7
8
9
10
11
12
|
class Bucket_Apple {
private:
Apple stuff;
public:
void set(Apple t){
this->stuff = t;
}
Apple get(){
return this->stuff;
}
};
|
这样你就明白为什么c++的模板能够实现泛型了吧,因为它帮你生成了不同类型的代码。
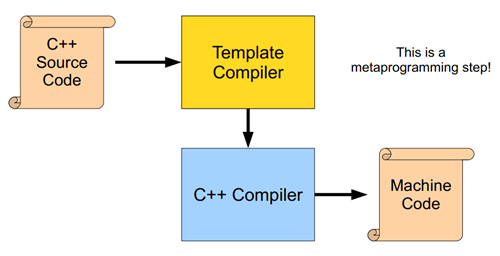
实际上c++的模板又称为:编译时多态技术,功能远比泛型强大。我们常听到的:“c++元编程”,即所谓的用代码来生成代码的技术。就是基于它的模板。
但是你发现这种技术有一个弊端,就是如果我要声明了100个不同类型的水果容器,那它可能会生成100份代码。那大量使用模板的c++代码,编译后的文件将非常大。(猜测某些编译器可能会做优化处理,这部分我并不是很清楚,欢迎指正。)
java
java的泛型在底层实现上使用了Object引用,也就是我们之前所提到的第二种方式,但是为了防止你往一个Apple的Bucket添加一个Banana。编译器会先根据你声明的泛型类型进行静态类型检查,然后再进行类型擦出,擦除为Object。而所谓的类型检查,就是在边界(对象进入和离开的地方)处,检查类型是否符合某种约束,简单的来说包括:
- 赋值语句的左右两边类型必须兼容。
- 函数调用的实参与其形参类型必须兼容。
- return的表达式类型与函数定义的返回值类型必须兼容。
- 还有多态类型检查,既向上转型可以直接通过,但是向下转型必须强制类型转换(前提是有继承关系)
|
1
2
|
Number n = new Integer(1);
Integer b = (Integer)n;
|
但是要注意的一点是,编译器只会检查继承关系是否符合。强转本身如果有问题,在运行时才会发现。所以下面这行代码在运行期才会抛异常。
|
1
2
|
// n is Integer
Double d = (Double)n;
|
所以你不能在一个ArrayList 中插入一个String对象, 但在运行是打印泛型类的类型却是一样的:
|
1
2
3
4
5
6
7
|
ArrayList<Integer> arrayListInt = new ArrayList<Integer>();
ArrayList<String> arrayListString = new ArrayList<String>();
ArrayList arrayList = new ArrayList();
System.out.println(arrayListInt.getClass().getName());
System.out.println(arrayListString.getClass().getName());
System.out.println(arrayList.getClass().getName());
# all print java.util.ArrayList
|
但这种技术也有一个弊端,就是既然擦成object了,那么在运行的时候,你根本不能确定这个对象到底是什么类型,虽然你可以通过编译器帮你插入的checkcast来获得此对象的类型。但是你并不能把T真正的当作一个类型使用:比如这条语句在java中是非法的。
|
1
2
|
// error
T a = new T();
|
同理,因为都被擦成了Object,你就不能根据类型来做某种区分。比如异常继承:
|
1
2
3
4
5
|
// error
try {
} catch (SomeException<Integer> e) {
} catch (SomeException<String> e) {
}
|
比如重载:
|
1
2
3
|
// error
void f(List<T> v);
void f(List<W> v);
|
还有因为基本类型int并不属于oop,所以它不能被擦除为Object,那么java的泛型也不能用于基本类型。
|
1
2
|
// error
List<int> a;
|
类型擦出到底指什么?
首先你要明白一点,一个对象的类型永远不会被擦出的,比如你用一个Object去引用一个Apple对象,你还是可以获得到它的类型的。比如用RTTI。
|
1
2
3
|
Object object = new Apple();
System.out.println(object.getClass().getName());
# will print Apple
|
哪怕它是放到泛型里的。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
class Bucket<T>{
private T t;
public void set(T t){
this.t = t;
}
public T get(){
return this.t;
}
public void showClass(){
System.out.println(t.getClass().getName());
}
}
Bucket<Apple> appleBucket = new Bucket<Apple>();
appleBucket.set(new Apple());
appleBucket.showClass();
# will print Apple too
|
为啥?因为引用就是一个用来访问对象的标签而已,对象一直在堆上放着呢。
所以不要断章取义认为类型擦出就是把容器内对象的类型擦掉了,所谓的类型擦出,是指容器类Bucket<Apple>,对于Apple的类型声明在编译期的类型检查之后被擦掉,变为和Bucket<Object>等同效果,也可以说是Bucket<Apple>和Bucket<Banana>被擦为和Bucket<Object>等价,而不是指里面的对象本身的类型被擦掉!
c#
c#结合了c++的展开和java的代码共享。
首先在编译时,c#会将泛型编译成元数据,即生成.net的IL Assembly代码。并在CLR运行时,通过JIT(即时编译), 将IL代码即时编译成相应类型的特化代码。
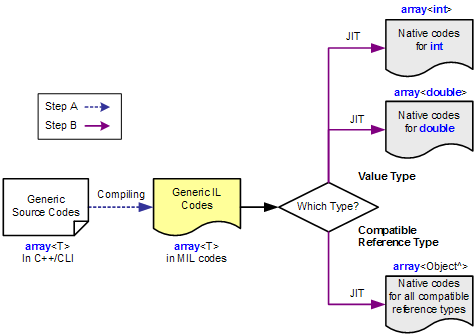
这样的好处是既不会像c++那样生成多份代码,又不会像java那样,丢失了泛型的类型。基本做到了两全其美。
所以总结一下c++,java,c#的泛型。c++的泛型在编译时完全展开,类型精度高,共享代码差。java的泛型使用类型擦出,仅在编译时做类型检查,在运行时擦出,共享代码好,但是类型精度不行。c#的泛型使用混合实现方式,在运行时展开,类型精度高,代码共享不错。
为什么java要用类型擦除?
看到这里你可能会问,为什么java要用类型擦除这样的技术来实现泛型,而不是像c#那样高大上,难道是因为sun的那群人技术水平远比不上微软的那群人么?
原因是为了向后兼容。
你去查查历史就会知道,c#和java在一开始都是不支持泛型的。为了让一个不支持泛型的语言支持泛型,只有两条路可以走,要么以前的非泛型容器保持不变,然后平行的增加一套泛型化的类型。要么直接把已有的非泛型容器扩展为泛型。不添加任何新的泛型版本。
当时c#从1.1升级到了2.0,代码并不是很多,而且都在微软.net的可控范围,所以选择了第一种实现方式,其实你可以发现,c#中有两种写法,非泛型写法和泛型写法:
|
1
2
3
4
|
// 非泛型
ArrayList array = new ArrayList();
// 泛型
List<int> list = new List<int>();
|
而java的非泛型容器,已经从1.4.2占有到5.0,市面上已经有大量的代码,不得已选择了第二种方法。(之所以是从1.4.2开始,是因为java以前连collection都没有,是一种vector的写法。),而且有一个更重要的原因就是之前提到的向后兼容。所谓的向后兼容,是保证1.5的程序在8.0上还可以运行。(当然指的是二进制兼容,而非源码兼容。)所以本质上是为了让非泛型的java程序在后续支持泛型的jvm上还可以运行。
那么为什么使用类型擦除就能保持向后兼容呢?
在《java编程思想》中讲到了这样一个例子,下面两种代码在编译成java虚拟机汇编码是一样的,所以无论是函数的返回类型是T,还是你自己主动写强转,最后都是插入一条checkcast语句而已:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
class SimpleHolder{
private Object obj;
public Object getObj() {
return obj;
}
public void setObj(Object obj) {
this.obj = obj;
}
}
SimpleHolder holder = new SimpleHolder();
holder.setObj("Item");
String s = (String)holder.getObj();
class GenericHolder<T>{
private T obj;
public T getObj() {
return obj;
}
public void setObj(T obj) {
this.obj = obj;
}
}
GenericHolder<String> holder = new GenericHolder<String>();
holder.setObj("Item");
String s = holder.getObj();
|
|
1
2
3
4
5
|
aload_1
invokevirtual // Method get: ()Object
checkcast // class java/lang/String
astore_2
return
|
我形象的理解为,之前非泛型的写法,编译成的虚拟机汇编码块是A,之后的泛型写法,只是在A的前面,后面“插入”了其它的汇编码,而并不会破坏A这个整体。这才算是既把非泛型“扩展为泛型”,又兼容了非泛型。
这下你应该理解“java为什么要用类型擦除实现泛型?”和这样实现的优劣了吧!
http://www.pulpcode.cn/2017/12/30/why-java-generic-use-type-eraser/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号