Python爬虫-scrapyd框架部署
爬虫项目部署
1 脚本文件部署
linux内置的cron进程能帮我们实现这些需求,cron搭配shell脚本,非常复杂的指令也没有问题。
1.1 crontab的使用
crontab [-u username] //省略用户表表示操作当前用户的crontab
-e (编辑工作表)
-l (列出工作表里的命令)
-r (删除工作)
我们用crontab -e进入当前用户的工作表编辑,是常见的vim界面。每行是一条命令。
crontab的命令构成为 时间+动作,其时间有分、时、日、月、周五种,操作符有
- ***** 取值范围内的所有数字
- / 每过多少个数字
- - 从X到Z
- ,散列数字
| 代表意义 | 分钟 | 小时 | 日期 | 月份 | 周 | 命令 |
|---|---|---|---|---|---|---|
| 数字范围 | 0~59 | 0~23 | 1~31 | 1~12 | 0~6 | 就命令 |
1.2 为当前用户创建cron服务
- 可以键入
crontab -e编辑crontab服务文件
举例:
* * * * * #每分钟都执行
实例1:每5分钟执行一次文档写入
*/1 * * * * echo 'hello world' >> /home/poppies/Documents/xialuo/ps/demo.txt
实例2:每小时的第3和第15分钟执行
3,15 * * * * echo 'hello world' >> /home/xxoo/demo/demo.log
实例:在上午8点的20分钟执行
20 8 * * * myCommand
1.3 单个脚本使用定时任务部署
1.3.1 上传本地文件到服务器
scp /path/filename username@servername:/path
scp env_ps.py poppies@192.168.65.232:/home/poppies/Documents/xialuo/ps
1.3.2 定时采集任务
1、使用定时任务启动 每5分钟采集一次数据
*/5 * * * * python /home/poppies/Documents/xialuo/ps/env_ps.py spider >> /home/poppies/Documents/xialuo/demo/demo.log
2 使用scrapyd部署
2.1 环境安装
pip install scrapyd
pip install scrapyd-client
官网:https://scrapyd.readthedocs.io/en/stable/overview.html
由于window兼容性问题,所以scrapyd-deploy无法支持
D:\software\inters\python3\Scripts
修改 scrapyd-deploy.bat格式
@echo off
"D:\software\inters\python3\Scripts\python.exe" "D:\software\inters\python3\Scripts\scrapyd-deploy" % *
执行 scrapyd-deploy -l 看到以下

2.2 查询状态
这个接口负责查看 Scrapyd 当前服务和任务的状态,我们可以用 curl 命令来请求这个接口,命令如下:
curl http://127.0.0.1:6800/daemonstatus.json
2.3 爬虫部署
1、把原先注释掉的url那一行取消注释,这个就是我们要部署到目标服务器的地址,
2、 把[deploy]这里改为[deploy:xl],这里是命名为xl,命名可以任意怎么都可以,只要能标识出来项目就可以。
下边的project 就是我们的工程名,到此配置文件更改完成。
2.3.1 发布项目
# 这里target 为你的服务器命令,prject是你工程的名字,发布工程之前我们的scrapyd.cfg必须修改
# scrapyd-deploy 部署名 -p 工程名称
scrapyd-deploy ps -p xialuo
2.3.2 启动爬虫
# PROJECT_NAME填入你爬虫工程的名字,SPIDER_NAME填入你爬虫的名字
curl http://localhost:6800/schedule.json -d project=xialuo -d spider=ps
2.3.3 停止爬虫
curl http://localhost:6800/cancel.json -d project=huya -d job=86a3dd29d51811eca18f000ec6599497
2.3.4 查看当前项目
curl http://127.0.0.1:6800/listprojects.json
2.3.4 查看详情
curl http://localhost:6800/listjobs.json?project=xialuo
2.3.5 交互调试
import requests
data = {}
data['project'] = 'huya'
data['spider'] = 'hh'
url = 'http://127.0.0.1:6800/schedule.json'
res = requests.post(url,data)
res.json() # 获取数据 返回jobid
print(res.json())
# 1b51dd0ac37e11ea8543000c29c350ab
# 停止
datas = {}
datas['project'] = 'xialuo'
datas['job'] = res.json()['jobid']
res = requests.post('http://127.0.0.1:6800/cancel.json',data)
print(res.text)
print(requests.get('http://localhost:6800/listjobs.json?project=huya').text)
3 Gerapy爬虫部署
是一个基于Scrapyd,Scrapyd API,Django,Vue.js搭建的分布式爬虫管理框架。简单点说,就是用上述的Scrapyd工具是在命令行进行操作,而Gerapy将命令行和图形界面进行了对接,我们只需要点击按钮就可完成部署,启动,停止,删除的操作。
3.1 环境安装
pip install gerapy
一、创建新项目
gerapy init
二、对数据库初始化
gerapy migrate # gerapy ==> python manage.py
三、启动gerapy服务
gerapy runserver
四、创建用户名密码
gerapy createsuperuser
3.2 项目部署
3.2.1 界面展示
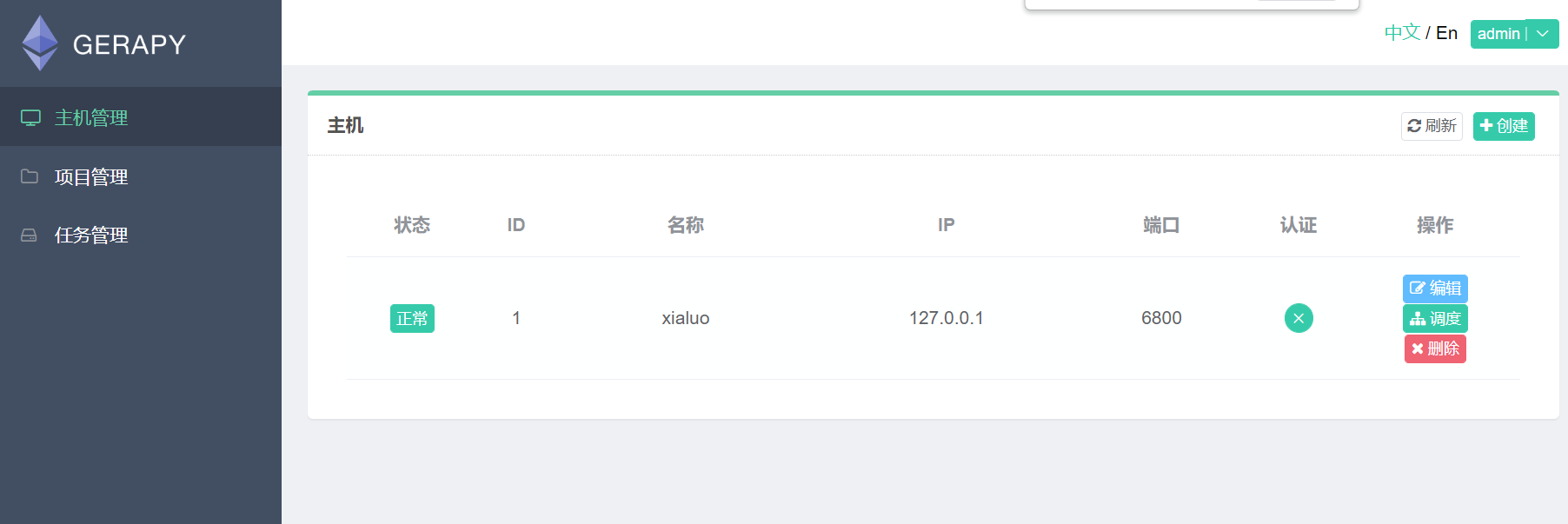
3.2.2 爬虫部署
1、打包上传
2、复制代码到包即可
4 docker容器
4.1 docker简介
打包:docker打包就是把软件运行需要的依赖、第三方库、软件打包放到一起,变成一个安装包
分发:可以把打包的安装包上传到仓库、其他人可以下载使用
部署:就是把安装包使用命令运行起来你的应用,自动模拟环境。
Docker是开发人员和系统管理员使用容器开发、部署和运行应用程序的平台。使用Linux容器来部署应用程序称为集装箱化。使用docker轻松部署应用程序
集装箱化的优点:
- 灵活:即使是复杂的应用程序也可封装。
- 轻量级:容器利用并共享主机内核。
- 便携式:您可以在本地构建,部署到云上并在任何地方运行。
- 可扩展性:您可以增加和自动分发容器副本。
- 可堆叠:您可以垂直堆叠服务并及时并及时堆叠服务。
4.2 虚拟机virtual machine
虚拟机(virtual machine)就是带环境安装的一种解决方案。它可以在一种操作系统里面运行另一种操作系统,比如在Windows系统里面运行Linux系统。应用程序对此毫无感知,因为虚拟机看上去跟真丝系统一模一样,而对于底层系统来说,虚拟机就是一个普通文件,不需要了就删掉,对其它部分毫无影响。
虚拟机的缺点:
- 资源占用多:虚拟机会独占一部分内存和硬盘空间。它运行的时候,其他程序就不能使用这些资源了。哪怕虚拟机里面的应用程序,真正使用的内存只有1M,虚拟机依然需要几百MB的内容才能运行。
- 冗余步骤多:虚拟机是完整的操作系统,一些系统级别的操作步骤,往往无法跳过,比如用户登录。
- 启动慢:启动操作系统需要多久,启动虚拟机就需要多久。可能要等几分钟,应用陈故乡才能真正运行。
4.3 容器和虚拟机比较
一个容器中运行原生Linux和共享主机与其它容器的内核,它运行一个独立的进程,不占用任何其它可执行文件的内存,使其轻量化。
相比之下,虚拟机(VM)运行一个完整的“客户”操作系统,通过虚拟机管理程序虚拟访问主机资源。一般来说,虚拟机提供的环境比大多数应用程序需要的资源多。

-
dockerfile 就是源代码
-
image 镜像 可执行的程序 ubuntu mysql redis nginx elesticsearch 网站打包成镜像
-
container 运行的进程
学习地址:https://www.runoob.com/docker/docker-tutorial.html
4.4 docker安装
下载地址:
卸载旧版本
yum remove docker docker-common docker-selinux docker-engine
安装
yum install -y yum-utils device-mapper-persistent-data lvm2 && python2 /usr/bin/yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo && yum install docker-ce -y
启动
systemctl start docker
4.5 镜像使用
4.5.1 镜像查找
镜像下载
docker pull ubuntu
4.5.2 镜像列举
docker images 来列出本地主机上的镜像。

各个选项说明:
- REPOSITORY:表示镜像的仓库源
- TAG:镜像的标签
- IMAGE ID:镜像ID
- CREATED:镜像创建时间
- SIZE:镜像大小
4.5.3 获取一个新的镜像
当我们在本地主机上使用一个不存在的镜像时 Docker 就会自动下载这个镜像。如果我们想预先下载这个镜像,我们可以使用 docker pull 命令来下载它。
docker pull ubuntu
4.5.4 查找镜像
docker search ubuntu
4.5.5 删除镜像
docker rmi ubuntu
4.6 容器使用
4.6.1 容器操作
以下命令使用 ubuntu 镜像启动一个容器,参数为以命令行模式进入该容器:
docker run -it ubuntu /bin/bash
参数说明:
- -i: 交互式操作。
- -t: 终端。
- ubuntu: ubuntu 镜像。
- /bin/bash:放在镜像名后的是命令,这里我们希望有个交互式 Shell,因此用的是 /bin/bash。
查看所有的容器命令如下:
docker ps -a
使用 docker start 启动一个已停止的容器:
docker start <容器 ID>
使用 docker stop 停止一个容器:
docker stop <容器 ID>
exec 命令
docker exec -it <容器 ID> /bin/bash
删除容器
docker rm -f <容器 ID>
运行一个 web 应用
- 我们将在docker容器中运行一个 Python Flask 应用来运行一个web应用
sudo docker pull training/webapp
sudo docker run -d -P training/webapp python app.py
参数说明:
- -d:让容器在后台运行。
- -P:将容器内部使用的网络端口随机映射到我们使用的主机上。

注:Docker 开放了 5000 端口(默认 Python Flask 端口)映射到主机端口 49153上。
这时我们可以通过浏览器访问http://192.168.65.232:49153/
我们也可以通过 -p 参数来设置不一样的端口:
sudo docker run -d -p 5000:5000 training/webapp python app.py
注:容器内部的 5000 端口映射到我们本地主机的 5000 端口上。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号