Python 爬虫-feapder 框架简介
feapder 框架
学习目标
-
掌握便捷式框架操作流程
-
掌握请求钩子结构使用
-
掌握框架项目搭建流程
-
掌握数据入库与去重
1 简介
国内文档:https://boris-code.gitee.io/feapder
feapder 是一款上手简单,功能强大的Python爬虫框架,使用方式类似scrapy,方便由scrapy框架切换过来,框架内置3种爬虫:
1.1 支持的场景
AirSpider爬虫比较轻量,学习成本低。面对一些数据量较少,无需断点续爬,无需分布式采集的需求,可采用此爬虫。Spider是一款基于redis的分布式爬虫,适用于海量数据采集,支持断点续爬、爬虫报警、数据自动入库等功能BatchSpider是一款分布式批次爬虫,对于需要周期性采集的数据,优先考虑使用本爬虫。
1.2 架构说明
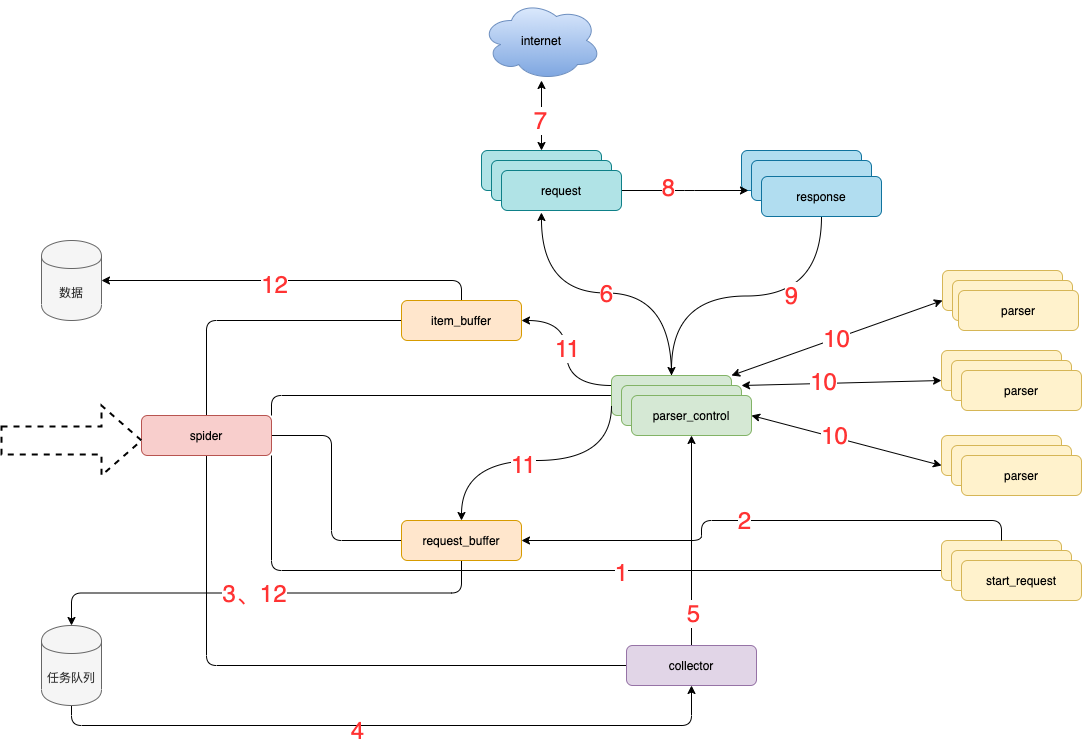
1.2.1模块说明
- spider 框架调度核心
- parser_control 模版控制器,负责调度parser
- collector 任务收集器,负责从任务队里中批量取任务到内存,以减少爬虫对任务队列数据库的访问频率及并发量
- parser 数据解析器
- start_request 初始任务下发函数
- item_buffer 数据缓冲队列,批量将数据存储到数据库中
- request_buffer 请求任务缓冲队列,批量将请求任务存储到任务队列中
- request 数据下载器,封装了requests,用于从互联网上下载数据
- response 请求响应,封装了response, 支持xpath、css、re等解析方式,自动处理中文乱码
1.2.2 流程说明
- spider调度start_request生产任务
- start_request下发任务到request_buffer中
- spider调度request_buffer批量将任务存储到任务队列数据库中
- spider调度collector从任务队列中批量获取任务到内存队列
- spider调度parser_control从collector的内存队列中获取任务
- parser_control调度request请求数据
- request请求与下载数据
- request将下载后的数据给response,进一步封装
- 将封装好的response返回给parser_control(图示为多个parser_control,表示多线程)
- parser_control调度对应的parser,解析返回的response(图示多组parser表示不同的网站解析器)
- parser_control将parser解析到的数据item及新产生的request分发到item_buffer与request_buffer
- spider调度item_buffer与request_buffer将数据批量入库
2 使用
2.1 环境安装
pip install feapder
2.2 创建普通爬虫
feapder create -s xxxx
2.3 爬虫小案例
- 下发任务:下发任务
def start_requests(self):
yield feapder.Request("https://www.icswb.com/channel-list-channel-161.html")
- 解析标题及详情页链接
def parse(self, request, response):
# 提取网站title
print(response.xpath("//title/text()").extract_first())
# 提取网站描述
article_list = response.xpath('//ul[@id="NewsListContainer"]/li')
for i in article_list[:-1]:
title = i.xpath('./h3/a/text()').extract_first()
url = i.xpath('./h3/a/@href').extract_first()
print(url)
yield feapder.Request('https://www.icswb.com'+url, callback=self.parser_detail, title=title)
- 抓详情需要将列表采集到的url作为新任务,然后请求,解析。写法很简单,代码如下:
def parser_detail(self, request, response):
title = request.title
content = response.xpath('//article[@class="am-article"]').extract_first()
print(content)
- 启动代码
if __name__ == "__main__":
# 开启多线程方式
SpiderTest(thread_count=5).start()
2.3.1 数据入库
feapder给我们提供了方法
from feapder.db.mysqldb import MysqlDB
db = MysqlDB(
ip="localhost", port=3306, db="feapder", user_name="feapder", user_pass="feapder123"
)
tt = '胖双'
cc = '胖娜'
sql = "insert ignore into xxx (title,content) values ('%s', '%s')" % (tt,cc)
db.add(sql)
1、创建配置文件
feapder create --setting
-
激活配置
# # MYSQL MYSQL_IP = "localhost" MYSQL_PORT = 3306 MYSQL_DB = "test8" MYSQL_USER_NAME = "root" MYSQL_USER_PASS = ""
2、创建item文件
feapder create -i xxx # xxx=表名
3、项目引入
from xxx_item import XxxItem
....
item = XxxItem()
item.title = titles
item.content = contents
yield item
注:数据是一次入库,降低对数据库的操作
2.4 自定义中间件
- 请求前会经过这个函数
import feapder
class Demo1s(feapder.AirSpider):
def start_requests(self):
for i in range(1, 3):
yield feapder.Request("http://httpbin.org/get",download_midware=self.xxx)
def xxx(self, request):
"""
我是自定义的下载中间件
:param request:
:return:
"""
request.headers = {'User-Agent': "lalala"}
return request
def parse(self, request, response):
print(response.text)
# print(title, url)
2.5 自定义下载器
自定义下载器即在下载中间件里下载,然后返回response即可,如使用httpx库下载以便支持http2
import feapder, httpx
class Demo1s(feapder.AirSpider):
def start_requests(self):
yield feapder.Request("https://www.smartbackgroundchecks.com/")
def download_midware(self, request):
with httpx.Client(http2=True) as client:
response = client.get(request.url)
response.status_code = 200
return request, response
def parse(self, request, response):
print(response.text)
def validate(self, request, response):
if response.status_code != 200:
raise Exception("response code not 200") # 重试
if __name__ == "__main__":
Demo1s(thread_count=1).start()
2.6 对接自动化
采集动态页面时(Ajax渲染的页面),常用的有两种方案。一种是找接口拼参数,这种方式比较复杂但效率高,需要一定的爬虫功底;另外一种是采用浏览器渲染的方式,直接获取源码,简单方便
内置浏览器渲染支持 CHROME 、PHANTOMJS、FIREFOX
def start_requests(self):
yield feapder.Request("https://news.qq.com/", render=True)
在返回的Request中传递render=True即可
注意:框架用的是老版本,需要降低现有版本
-
pip install selenium==3.141.0
2.6.1 配置
- 在setting里面改配置
- 在项目里面重写配置
__custom_setting__ = dict(
WEBDRIVER=dict(
pool_size=1, # 浏览器的数量
load_images=True, # 是否加载图片
user_agent=None, # 字符串 或 无参函数,返回值为user_agent
proxy=None, # xxx.xxx.xxx.xxx:xxxx 或 无参函数,返回值为代理地址
headless=False, # 是否为无头浏览器
driver_type="CHROME", # CHROME、PHANTOMJS、FIREFOX
timeout=30, # 请求超时时间
window_size=(1024, 800), # 窗口大小
executable_path='D:\software\inters\python3\chromedriver.exe', # 浏览器路径,默认为默认路径
render_time=0, # 渲染时长,即打开网页等待指定时间后再获取源码
custom_argument=["--ignore-certificate-errors"], # 自定义浏览器渲染参数
)
)
自动适配浏览器驱动
WEBDRIVER = dict(
...
auto_install_driver=True
)
即浏览器渲染相关配置 auto_install_driver 设置True,让其自动对比驱动版本,版本不符或驱动不存在时自动下载
2.6.2 操作浏览器对象
- 通过
response.browser获取浏览器对象
import time
import feapder
from feapder.utils.webdriver import WebDriver
class TestRender(feapder.AirSpider):
def start_requests(self):
yield feapder.Request("http://www.baidu.com", render=True)
def parse(self, request, response):
browser: WebDriver = response.browser
browser.find_element_by_id("kw").send_keys("feapder")
browser.find_element_by_id("su").click()
time.sleep(5)
print(browser.page_source)
# response也是可以正常使用的
# response.xpath("//title")
# 若有滚动,可通过如下方式更新response,使其加载滚动后的内容
# response.text = browser.page_source
if __name__ == "__main__":
TestRender().start()
2.6.3 拦截XHR 数据
WEBDRIVER = dict(
...
xhr_url_regexes=[
"接口1正则",
"接口2正则",
]
)
数据获取
browser: WebDriver = response.browser
# 提取文本
text = browser.xhr_text("接口1正则")
# 提取json
data = browser.xhr_json("接口1正则")
获取对象
browser: WebDriver = response.browser
xhr_response = browser.xhr_response("接口1正则")
print("请求接口", xhr_response.request.url)
print("请求头", xhr_response.request.headers)
print("请求体", xhr_response.request.data)
print("返回头", xhr_response.headers)
print("返回地址", xhr_response.url)
print("返回内容", xhr_response.content)
2.6.4 示例代码
# -*- coding: utf-8 -*-
"""
Created on 2022-09-13 21:39:47
---------
@summary:
---------
@author: XL
"""
import time
import feapder
from feapder.utils.webdriver import WebDriver
from feapder.network.downloader import SeleniumDownloader
class Test(feapder.AirSpider):
__custom_setting__ = dict(
WEBDRIVER=dict(
pool_size=1, # 浏览器的数量
load_images=True, # 是否加载图片
user_agent=None, # 字符串 或 无参函数,返回值为user_agent
proxy=None, # xxx.xxx.xxx.xxx:xxxx 或 无参函数,返回值为代理地址
headless=False, # 是否为无头浏览器
driver_type="CHROME", # CHROME、PHANTOMJS、FIREFOX
timeout=30, # 请求超时时间
window_size=(1024, 800), # 窗口大小
executable_path='D:\software\inters\python3\chromedriver.exe', # 浏览器路径,默认为默认路径
render_time=0, # 渲染时长,即打开网页等待指定时间后再获取源码
custom_argument=["--ignore-certificate-errors"], # 自定义浏览器渲染参数
xhr_url_regexes=[
"/api/post/Query",
], # 拦截 https://careers.tencent.com/tencentcareer/api/post/Query 接口
)
)
def start_requests(self):
yield feapder.Request("https://careers.tencent.com/search.html?keyword=python",render=True)
def parse(self, request, response):
# print(response.text)
# 可以使用自动化提取
# 数据提取第一种 使用xpath提取
# title = response.xpath('//h4[@class="recruit-title"]/text()')
# print(title)
# 数据提取第2种 继续使用自动化
# browser: WebDriver = response.browser
# time.sleep(3)
# title = browser.find_element_by_class_name('recruit-title').text
# print(title)
# 数据提取第3种,使用API接口拦截
browser: WebDriver = response.browser
time.sleep(1.5)
# 获取接口数据 文本类型
# data = browser.xhr_text("/api/post/Query")
# print(data)
# data = browser.xhr_json("/api/post/Query")
# print(data)
# 自定义提取数据
xhr_response = browser.xhr_response("/api/post/Query")
print("请求头", xhr_response.request.headers)
print("请求体", xhr_response.request.data)
print("返回内容", xhr_response.content)
# 关闭浏览器
response.close_browser(request)
if __name__ == "__main__":
Test().start()
3 项目搭建
3.1 创建项目
feapder create -p <project_name>
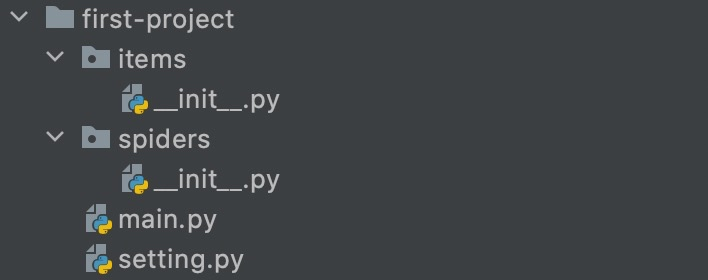
- items: 文件夹存放与数据库表映射的item
- spiders: 文件夹存放爬虫脚本
- main.py: 运行入口
- setting.py: 爬虫配置文件
3.2 创建普通爬虫
- 需要先切换到spiders文件夹下
feapder create -s first_spider
3.3 配置自动化
WEBDRIVER = dict(
pool_size=1, # 浏览器的数量
load_images=True, # 是否加载图片
user_agent=None, # 字符串 或 无参函数,返回值为user_agent
proxy=None, # xxx.xxx.xxx.xxx:xxxx 或 无参函数,返回值为代理地址
headless=False, # 是否为无头浏览器
driver_type="CHROME", # CHROME、PHANTOMJS、FIREFOX
timeout=30, # 请求超时时间
window_size=(1024, 800), # 窗口大小
executable_path='D:\software\inters\python3\chromedriver.exe', # 浏览器路径,默认为默认路径
render_time=0, # 渲染时长,即打开网页等待指定时间后再获取源码
custom_argument=[
"--ignore-certificate-errors",
"--disable-blink-features=AutomationControlled",
], # 自定义浏览器渲染参数
xhr_url_regexes=[
"/hbsearch/HotelSearch",
],
auto_install_driver=False, # 自动下载浏览器驱动 支持chrome 和 firefox
use_stealth_js=True, # 使用stealth.min.js隐藏浏览器特征
)
3.4 业务逻辑分析
3.5.1 翻页
def next_page(self,browser):
# 11568
for x in range(1, 11):
time.sleep(0.3)
js = "window.scrollTo(0, {})".format(x*1000) # 1000 2000 3000 4000 5000
browser.execute_script(js)
time.sleep(2)
3.5.2 点击
def get_next_page(self,browser):
try:
next_btn = browser.find_element_by_xpath('.//a[@class="pn-next"]') # 下一页地址
if 'next-disabled' in next_btn.get_attribute('class'):
print('没有下一页,抓取完成')
else:
next_btn.click()
except Exception as e:
print(e)
3.5 数据解析
browser: WebDriver = response.browser
time.sleep(1.5)
self.next_page(browser)
res = browser.page_source
html = etree.HTML(res)
page = ''.join(html.xpath('//span[@class="p-num"]/a[@class="curr"]/text()')) # 提取当前页面
print(f'正在采集第{page}个页面')
goods_ids = html.xpath(
'.//ul[@class="gl-warp clearfix"]/li[@class="gl-item"]/@data-sku') # 获取商品id号 作为页面的id号
goods_names_tag = html.xpath('.//div[@class="p-name p-name-type-2"]/a/em') # 提取商品标题
goods_prices = html.xpath('.//div[@class="p-price"]//i') # 提取商品价格
goods_stores_tag = html.xpath('.//div[@class="p-shop"]') # 提取店铺
goods_commits = html.xpath('.//div[@class="p-commit"]//a') # 提取评价
goods_names = []
for goods_name in goods_names_tag:
goods_names.append(goods_name.xpath('string(.)').strip())
goods_stores = []
for goods_store in goods_stores_tag:
goods_stores.append(goods_store.xpath('string(.)').strip())
goods_price = []
for price in goods_prices:
goods_price.append(price.xpath('string(.)').strip())
goods_commit = []
for commit in goods_commits:
goods_commit.append(commit.xpath('string(.)').strip())
3.6 数据入库
更改配置文件
- 放开mongo注释
- 放开管道mongo注释
from feapder import Item
...
item = Item() # 声明一个item
item.table_name = "test_mongo" # 指定存储的表名
item.ID = goods_ids[i]
item.标题 = goods_names[i]
item.价格 =goods_price[i]
item.店铺 = goods_stores[i]
yield item
如果您觉得本篇文章还不错,欢迎点赞,转发分享(转发请注明出处),感谢~~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号