爬虫技术-Scrapy框架介绍
Scrapy采集框架
1 学习目标
1、框架流程和结构设计原理
2、框架爬虫程序编写
3、框架日志模块使用
4、框架请求发送流程
2 scrapy简介
Scrapy是用纯Python实现一个为了爬取网站数据、提取结构性数据而编写的应用框架,用途非常广泛,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便。
2.0 单个爬虫编写
class Spider(object):
def __init__(self):
# 负责全局配置
pass
def url_list(self):
# 负责任务池维护
pass
def request(self):
# 负责网络请求模块
pass
def parse(self):
# 负责解析数据模块
pass
def save(self):
# 负责数据存储
pass
def run(self):
# 负责模块调度
pass
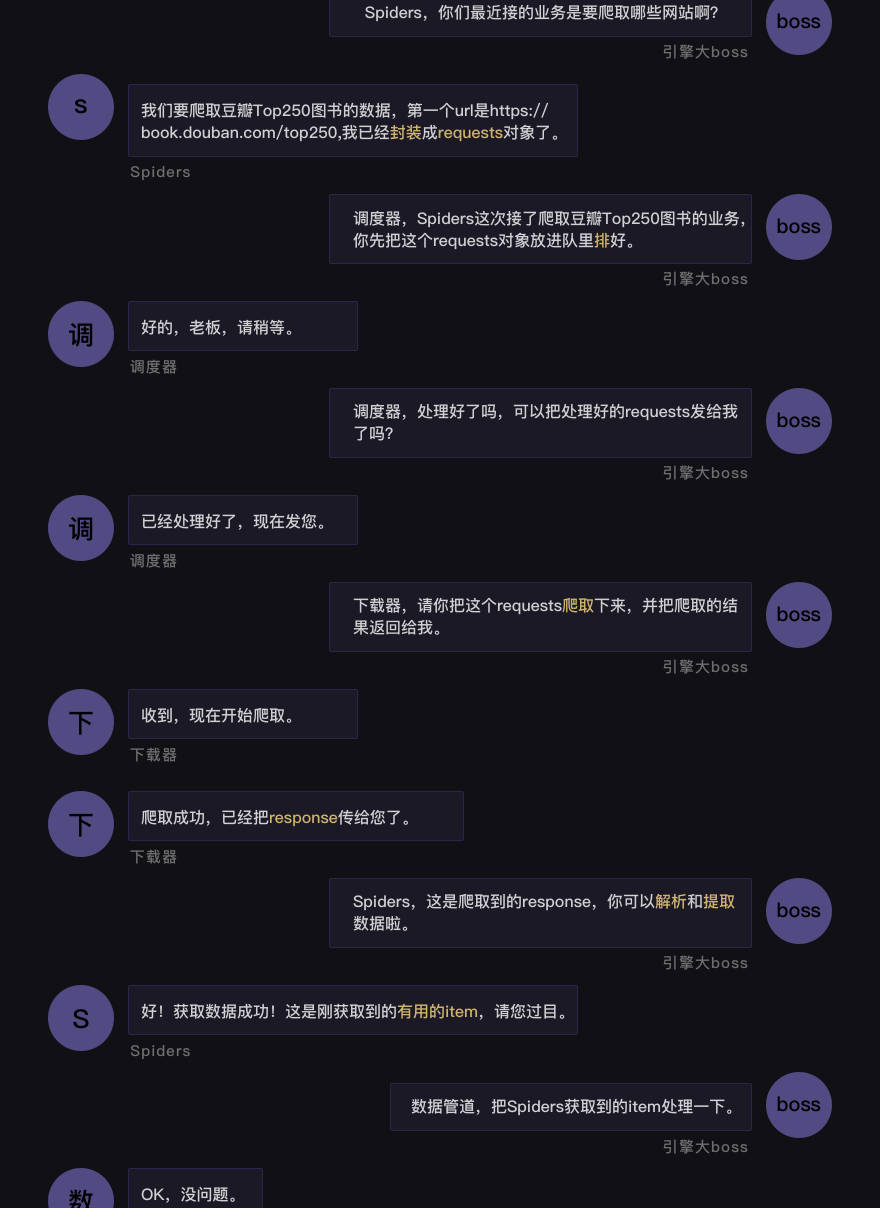
2.1 架构介绍
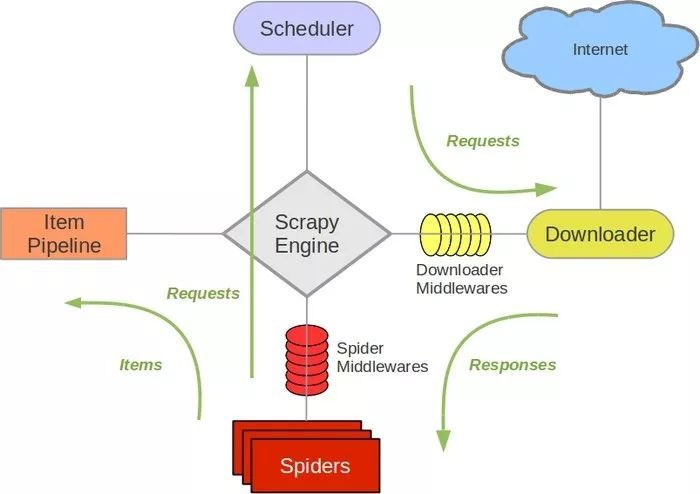
2.2.1 名词解析

2.2.2 运行逻辑图
3 框架使用
3.1 项目搭建
3.1.1 框架安装
查找历史版本:https://pypi.org/project/Scrapy/#history
pip install scrapy==2.3.0
3.1.2 项目创建
scrapy startproject xxxx
文件介绍
- scrapy.cfg:它是 Scrapy 项目的配置文件,其内定义了项目的配置文件路径、部署相关信息等内容。
- items.py:它定义 Item 数据结构,所有的 Item 的定义都可以放这里。
- pipelines.py:它定义 Item Pipeline 的实现,所有的 Item Pipeline 的实现都可以放这里。
- settings.py:它定义项目的全局配置。
- middlewares.py:它定义 Spider Middlewares 和 Downloader Middlewares 的实现。
- spiders:其内包含一个个 Spider 的实现,每个 Spider 都有一个文件。
3.1.3 创建爬虫
Spider 是自己定义的类,Scrapy 用它来从网页里抓取内容,并解析抓取的结果。不过这个类必须继承 Scrapy 提供的 Spider 类 scrapy.Spider,还要定义 Spider 的名称和起始请求,以及怎样处理爬取后的结果的方法
cd 项目路径
scrapy genspider 爬虫名称 目标地址
配置文件简介
# Scrapy settings for ScrapyDemo project
# 自动生成的配置,无需关注,不用修改
BOT_NAME = 'ScrapyDemo'
SPIDER_MODULES = ['ScrapyDemo.spiders']
NEWSPIDER_MODULE = 'ScrapyDemo.spiders'
# 设置UA,但不常用,一般都是在MiddleWare中添加
USER_AGENT = 'ScrapyDemo (+http://www.yourdomain.com)'
# 遵循robots.txt中的爬虫规则,很多人喜欢False,当然我也喜欢....
ROBOTSTXT_OBEY = True
# 对网站并发请求总数,默认16
CONCURRENT_REQUESTS = 32
# 相同网站两个请求之间的间隔时间,默认是0s。相当于time.sleep()
DOWNLOAD_DELAY = 3
# 下面两个配置二选一,但其值不能大于CONCURRENT_REQUESTS,默认启用PER_DOMAIN
# 对网站每个域名的最大并发请求,默认8
CONCURRENT_REQUESTS_PER_DOMAIN = 16
# 默认0,对网站每个IP的最大并发请求,会覆盖上面PER_DOMAIN配置,
# 同时DOWNLOAD_DELAY也成了相同IP两个请求间的间隔了
CONCURRENT_REQUESTS_PER_IP = 16
# 禁用cookie,默认是True,启用
COOKIES_ENABLED = False
# 请求头设置,这里基本上不用
DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
}
# 配置启用Spider MiddleWares,Key是class,Value是优先级
SPIDER_MIDDLEWARES = {
'ScrapyDemo.middlewares.ScrapydemoSpiderMiddleware': 543,
}
# 配置启用Downloader MiddleWares
DOWNLOADER_MIDDLEWARES = {
'ScrapyDemo.middlewares.ScrapydemoDownloaderMiddleware': 543,
}
# 配置并启用扩展,主要是一些状态监控
EXTENSIONS = {
'scrapy.extensions.telnet.TelnetConsole': None,
}
# 配置启用Pipeline用来持久化数据
ITEM_PIPELINES = {
'ScrapyDemo.pipelines.ScrapydemoPipeline': 300,
}
3.2 执行爬虫
3.2.1 终端运行爬虫
- 需要去到项目跟路径执行指令
scrapy crawl xxxx
3.2.2 脚本运行
- 在
Scrapy中有一个可以控制终端命令的模块cmdline。导入了这个模块,我们就能操控终端 execute方法能执行终端的命令行
from scrapy import cmdline
cmdline.execute("scrapy crawl xxxx".split())
cmdline.execute(["scrapy","crawl","xxxx"])
运行报错
ImportError: cannot import name 'HTTPClientFactory' from 'twisted.web.client' (unknown location)
解决:
# 降低Twisted版本
pip install Twisted==20.3.0
3.3 scrapy shell调试
基本使用
scrapy shell https://dig.chouti.com/
数据提取
datas =res.xpath('//div[@class="link-con"]/div')
for i in datas:
print(i.xpath('.//a[@class="link-title link-statistics"]/text()').extract_first())
4 实战演示
4.1 spider结构
import scrapy
from scrapy import cmdline
import bs4
class TopSpider(scrapy.Spider):
name = 'top'
# allowed_domains = ['top.com']
start_urls = ['https://book.douban.com/top250?start=0']
def parse(self, response):
#print(response.text)
bs = bs4.BeautifulSoup(response.text, 'html.parser')
datas = bs.find_all('tr', class_="item")
for data in datas:
item = {}
item['title'] = data.find_all('a')[1]['title']
item['publish'] = data.find('p', class_='pl').text
item['score'] = data.find('span', class_='rating_nums').text
print(item)
if __name__ == '__main__':
cmdline.execute('scrapy crawl top'.split())
4.2 定义数据
在scrapy中,我们会专门定义一个用于记录数据的类
import scrapy
class DoubanItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
#定义书名的数据属性
publish = scrapy.Field()
#定义出版信息的数据属性
score = scrapy.Field()
scrapy.Field()这行代码实现的是,让数据能以类似字典的形式记录。但记录的方式却不是字典,是是我们定义的DoubanItem,属于“自定义的Python字典”。
4.3 定义管道存储
4.3.1 配置管道
放开配置文件
ITEM_PIPELINES = {
'douban.pipelines.DoubanPipeline': 300,
}
4.3.2 存储文件编写
import json
class DoubanPipeline:
def process_item(self, item, spider):
with open('da.json', 'a+', encoding='utf-8') as f:
f.write(json.dumps(dict(item), ensure_ascii=False))
f.write('\r\n')
4.3.3 配置日志
配置日志来做记录
LOG_LEVEL = 'WARNING'
LOG_FILE = './log.log'
配置日志为警告级别,如果有数据是警告级别那么将记录到文件
5 scrapy表单处理
5.1 目标地址
- 首页:http://www.cninfo.com.cn/new/commonUrl?url=disclosure/list/notice#regulator
- 接口:http://www.cninfo.com.cn/new/disclosure
5.2 程序编写
import scrapy
class PostTestSpider(scrapy.Spider):
name = 'post_test'
allowed_domains = ['cninfo.com']
# start_urls = ['http://www.cninfo.com.cn/new/disclosure']
def start_requests(self):
url = 'http://www.cninfo.com.cn/new/disclosure'
for i in range(1,5):
form_data = {
"column": "szse_gem_latest",
"pageNum": str(i),
"pageSize": "30",
"sortName": "",
"sortType": "",
"clusterFlag": "true"
}
yield scrapy.FormRequest(url=url,formdata=form_data,meta={'page':form_data['pageNum']})
def parse(self, response):
print(f'正在采集第{response.meta.get("page")}页')
6 框架扩展
6.1 框架去重设计
dont_filter实现了框架去重的功能
import scrapy
import json
from scrapy import cmdline
class HuyaSpider(scrapy.Spider):
name = 'huya'
# allowed_domains = ['hy.com']
def start_requests(self):
url = ['https://www.huya.com/cache.php?m=LiveList&do=getLiveListByPage&gameId=1663&tagAll=0&page=2',
'https://www.huya.com/cache.php?m=LiveList&do=getLiveListByPage&gameId=1663&tagAll=0&page=2']
for i in url:
# 框架默认对地址进行了去重
yield scrapy.Request(url=i,dont_filter=False)
def parse(self, response):
items = json.loads(response.text)
data = items.get('data').get('datas')
print(len(data))
if __name__ == '__main__':
cmdline.execute('scrapy crawl huya'.split())
7 各目录文件详解
(1)爬虫文件
spiders 下的 jingding.py 是 scrapy 自动为我们生成的爬虫文件。
class scrapy.Spider 是最基本的类,所有编写的爬虫必须继承这个类。 常用属性和方法如下:
-
name:定义spider名字的字符串。
-
allowed_domains:包含了spider允许爬取的域名(domain)的列表,可选。
-
start_urls:初始URL元组/列表。当没有制定特定的URL时,spider将从该列表中开始进行爬取。
-
start_requests(self):调用 make_requests_from url() 生成 Requests 对象交给 Scrapy下载并返回response。该方法必须返回一个可迭代对象(iterable),该对象包含了spider用于爬取(默认实现是使用 start_urls 的url)的第一个Request。
当spider启动爬取并且未指定start_urls时,该方法被调用。 -
parse(self, response):每抓取一个URL对应的 Web资源,就会调用该方法,解析 response,并返回 Item 或 Requests(需指定回调函数)。Item 传给 Item pipline 持久化 , 而 Requests 交由 Scrapy下载,并由指定的回调函数处理(默认parse()),一直进行循环,直到处理完所有的数据为止。
当请求 url 返回网页没有指定回调函数时,则该函数作为默认的 Request 对象回调函数,用来处理网页返回的 response,以及生成 Item 或者 Request 对象。 -
Request 对象的用法:
yield Request(url[, callback, method='GET', headers, body, cookies, meta, encoding='utf-8', priority=0, dont_filter=False, errback, flags])-
url:请求的 url;
-
callback:回调函数,用于接收请求后的返回信息,若没指定,则默认为 parse() 函数;
-
meta:用户自定义向回调函数传递的参数,这个参数一般也可在middlewares中处理,键值对形式;
meta = {‘name’ : ‘Zarten’}
回调函数中获取:my_name = response.meta[‘name’] -
method:http请求的方式,默认为GET请求,一般不需要指定。若需要POST请求,用FormRequest即可;
-
headers:请求头信息,一般在settings中设置即可,也可在middlewares中设置;
-
body:str类型,为请求体,一般不需要设置(get和post其实都可以通过body来传递参数,不过一般不用)
-
cookies:dict或list类型,请求的cookie
-
实例:
import scrapy
class HuyaSpider(scrapy.Spider):
name = 'huya'
# allowed_domains = ['huya.com']
# start_urls = ['http://huya.com/']
def start_requests(self):
url = ['https://www.huya.com/cache.php?m=LiveList&do=getLiveListByPage&gameId=1663&tagAll=0&page=1',
'https://www.huya.com/cache.php?m=LiveList&do=getLiveListByPage&gameId=1663&tagAll=0&page=1']
for i in url:
# 框架默认对地址进行了去重
yield scrapy.Request(url=i,dont_filter=False)
def parse(self, response):
print(response)
# <200 https://www.huya.com/cache.php?m=LiveList&do=getLiveListByPage&gameId=1663&tagAll=0&page=1>
(2)middlewares.py
middlewares.py 定义Spider Middlewares 和 Downloader Middlewares 的实现。
1) Spider Middlewares
Spider 中间件是介入到 Scrapy 的 spider 处理机制的钩子框架,您可以添加代码来处理发送给 Spiders 的 response 及 spider 产生的 item 和 request。
要启用 Spider 中间件(Spider Middlewares),就必须在 setting.py 中进行 SPIDER_MIDDLEWARES 设置中。 该设置是一个字典,键为中间件的路径,值为中间件的顺序(order)。
SPIDER_MIDDLEWARES = {
'myproject.middlewares.CustomSpiderMiddleware': 543,
}
SPIDER_MIDDLEWARES 设置会与Scrapy定义的 SPIDER_MIDDLEWARES_BASE 设置合并(但不是覆盖),而后根据顺序(order)进行排序,最后得到启用中间件的有序列表: 第一个中间件是最靠近引擎的,最后一个中间件是最靠近spider的。
关于如何分配中间件的顺序请查看 SPIDER_MIDDLEWARES_BASE 设置,而后根据您想要放置中间件的位置选择一个值。由于每个中间件执行不同的动作,您的中间件可能会依赖于之前(或者之后)执行的中间件,因此顺序是很重要的。
如果您想禁止内置的(在 SPIDER_MIDDLEWARES_BASE 中设置并默认启用的)中间件, 您必须在项目的 SPIDER_MIDDLEWARES 设置中定义该中间件,并将其值赋为 None 。 例如,如果您想要关闭off-site中间件:
SPIDER_MIDDLEWARES = {
'myproject.middlewares.CustomSpiderMiddleware': 543,
'scrapy.contrib.spidermiddleware.offsite.OffsiteMiddleware': None, }
Spider 中间件方法:
process_spider_input(response, spider)
# response (Response 对象) – 被处理的response
# spider (Spider 对象) – 该response对应的spider
当 response 通过 spider 中间件时,该方法被调用,处理该response。process_spider_input() 应该返回 None 或者抛出一个异常(exception)。 如果其返回 None ,Scrapy将会继续处理该response,调用所有其他的中间件直到spider处理该response。如果其抛出一个异常(exception),Scrapy将不会调用任何其他中间件的 process_spider_input() 方法,并调用request的errback。 errback的输出将会以另一个方向被重新输入到中间件链中,使用 process_spider_output() 方法来处理,当其抛出异常时则带调用process_spider_exception() 。
process_spider_output(response, result, spider)
# response (Response 对象) – 生成该输出的response
# result (包含 Request 或 Item 对象的可迭代对象(iterable)) – spider返回的result
# spider (Spider 对象) – 其结果被处理的spider
当 Spider 处理 response 返回 result 时,该方法被调用。process_spider_output() 必须返回包含 Request 或 Item 对象的可迭代对象(iterable)。
process_spider_exception(response, exception, spider)
# response (Response 对象) – 异常被抛出时被处理的response
# exception (Exception 对象) – 被跑出的异常
# spider (Spider 对象) – 抛出该异常的spider
当 spider (或其他spider中间件的) process_spider_input() 抛出异常时, 该方法被调用。process_spider_exception() 必须要么返回 None , 要么返回一个包含 Response 或 Item 对象的可迭代对象(iterable)。 如果其返回 None ,Scrapy 将继续处理该异常,调用中间件链中的其他中间件的 process_spider_exception() 方法,直到所有中间件都被调用,该异常到达引擎(异常将被记录并被忽略)。如果其返回一个可迭代对象,则中间件链的 process_spider_output() 方法被调用, 其他的 process_spider_exception() 将不会被调用。
2)Download Middlewares
下载器中间件是引擎和下载器之间通信的中间件:当引擎传递请求给下载器的过程中,下载中间件可以对请求进行处理 (例如增加http header信息,增加proxy信息等);在下载器完成http请求,传递响应给引擎的过程中, 下载中间件可以对响应进行处理(例如进行gzip的解压等)。
在这个中间件中我们可以设置代理、更换请求头信息等来达到反反爬虫的目的。要写下载器中间,可以在下载器中实现两个方法。一个是process_request(self, request, spider),这个方法是在请求发送之前会执行,还有一个是process_response(self, request, response, spider),这个方法是数据下载到引擎之前执行。
要激活下载器中间件组件,就必须在 setting.py 中进行 DOWNLOADER_MIDDLEWARES 设置。 该设置是一个字典(dict),键为中间件类的路径,值为其中间件的顺序(order)。
DOWNLOADER_MIDDLEWARES = {
'mySpider.middlewares.MyDownloaderMiddleware': 543, }
方法:
process_request(self, request, spider)
# request : 发送请求的request对象。
# spider : 发送请求的spider对象。
这个方法是在下载器发送请求之前会执行的,一般可以在这个里面设置随机代理,随机请求头等。
返回值:
返回Node:如果返回None,Scrapy将继续执行该request,执行中间件中的相应的方法,直到合适的下载器处理函数被调用。
返回Response对象:Scrapy将不会调用其他的process_request方法,将直接返回这个response对象。已经激活的中间件的process_response()方法则会在每个response返回时被调用。
返回Request对象:不再使用之前的request对象去下载数据,而是根据限制返回request对象返回数据。
如果这个方法中抛出了异常,则会调用process_exception方法。
process_response(self, request, response, spider)
# request:request对象。
# response:被处理的response对象。
# spider:spider对象.
这个方法是下载器下载的数据到引擎中间会执行的方法。
返回值:
返回Response对象:会将这个新的response对象传给其他中间件,最终传给爬虫。
返回Request对象:下载器链被切断,返回的resquest会重新被下载器调度下载。
如果这个方法中抛出了异常,那么将会调用request的errorback方法,如果没有指定这个方法,那么会抛出一个异常。
(3)settings.py
settings.py 是 spdier 项目的配置文件。
各字段说明如下:
- BOT_NAME:项目名;
- USER_AGENT:默认是注释的,这个东西非常重要,
如果不写很容易被判断为电脑,简单点设置一个Mozilla/5.0即可; - ROBOTSTXT_OBEY:
是否遵循机器人协议,默认是true,需要改为 false,否则很多东西爬不了; - CONCURRENT_REQUESTS:最大并发数,就是同时允许开启多少个爬虫线程;
- DOWNLOAD_DELAY:下载延迟时间,单位是秒,控制爬虫爬取的频率,根据你的项目调整,不要太快也不要太慢,默认是3秒,即爬一个停3秒,设置为1秒性价比较高,如果要爬取的文件较多,写零点几秒也行
- COOKIES_ENABLED:是否保存 COOKIES,默认关闭,开启可以记录爬取过程中的 COOKIE,非常好用的一个参数;
- DEFAULT_REQUEST_HEADERS:默认请求头,上面写了一个USER_AGENT,其实这个东西就是放在请求头里面的,这个东西可以根据你爬取的内容做相应设置;
- ITEM_PIPELINES:
项目管道,300为优先级,越低越爬取的优先度越高;
# Scrapy settings for ps project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'ps'
SPIDER_MODULES = ['ps.spiders']
NEWSPIDER_MODULE = 'ps.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
# USER_AGENT = 'ps (+http://www.yourdomain.com)'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False # 不遵守协议
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers: 头部
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36'
}
# Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'ps.middlewares.PsSpiderMiddleware': 543,
#}
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {
'ps.middlewares.PsDownloaderMiddleware': 543,
}
# Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
LOG_LEVEL = 'INFO'
LOG_FILE = './ps.log'
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'ps.pipelines.PsPipeline': 300,
}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
(3)items.py
items 提供一个字段存储, spider 会将数据存在这里。
爬虫爬取的主要目标是从非结构化数据源中提取结构化数据,通常是web页面。作为Python语言,Scrapy spiders 可以返回提取的数据。虽然方便而又熟悉,但 Python 却缺乏结构,特别是在一个包含许多 spider 的大型项目中在字段名中输入错误或返回不一致的数据。
为了定义常见的输出数据格式,scrapy 提供了 item 类,Item 对象是用来收集提取数据的简单容器。它们提供了一个类似于字典的API,提供了一种方便的语法,用于声明可用字段。
各种各样的 scrapy 组件使用由 item 提供的附加信息,查看已声明的字段,以找出导出的列,可以使用 item 字段元数据定制序列化,trackref跟踪项目实例以帮助发现内存泄漏。
Item 使用简单的类定义语法和字段对象声明,如下所示:
import scrapy
class Product(scrapy.Item):
# 字段类型就是简单的scrapy.Field
name = scrapy.Field()
price = scrapy.Field()
stock = scrapy.Field()
last_updated = scrapy.Field(serializer=str)
Field 对象用于为每个字段指定元数据,您可以为每个字段指定任何类型的元数据,对 Field 对象的值没有限制。需要注意的是,用于声明该项的字段对象不会被分配为类属性。相反,可以通过Item.fields访问它们。
使用 Item:
创建 items
product = Product(name='Desktop PC', price=1000)
print product
# Product(name='Desktop PC', price=1000)
获取 Field 值
product['name']
# Desktop PC
product.get('name')
# Desktop PC
product['last_updated']
# Traceback (most recent call last):
# ...
# KeyError: 'last_updated'
product.get('last_updated', 'not set')
# not set
product['lala'] # getting unknown field
# Traceback (most recent call last):
# ...
# KeyError: 'lala'
product.get('lala', 'unknown field')
# 'unknown field'
'name' in product
# True
'last_updated' in product
# False
'last_updated' in product.fields
# True
'lala' in product.fields
# False
设置 Field 值
product['last_updated'] = 'today'
product['last_updated']
# today
product['lala'] = 'test' # setting unknown field
# Traceback (most recent call last):
# ...
# KeyError: 'Product does not support field: lala'
获取所有内容
product.keys()
# ['price', 'name']
product.items()
# [('price', 1000), ('name', 'Desktop PC')]
复制 items
product2 = Product(product)
print product2
# Product(name='Desktop PC', price=1000)
product3 = product2.copy() print product3
# Product(name='Desktop PC', price=1000)
从items创建字典
dict(product) # create a dict from all populated values
# {'price': 1000, 'name': 'Desktop PC'}
从字典创建 items
Product({'name': 'Laptop PC', 'price': 1500})
# Product(price=1500, name='Laptop PC')
Product({'name': 'Laptop PC', 'lala': 1500}) # warning: unknown field in dict
# Traceback (most recent call last):
# ...
# KeyError: 'Product does not support field: lala' ```
(5)pipelines.py
Item pipline 的主要责任是负责处理爬虫从网页中抽取的 Item,他的主要任务是清洗、验证和存储数据。当页面被蜘蛛解析后,将被发送到 Item pipline,并经过几个特定的次序处理数据。
每个 Item pipline 的组件都是有一个简单的方法组成的 Python 类。获取 Item 并执行方法,同时还需要确定是否需要 Item 管道中继续执行下一步或是直接丢弃掉不处理。简而言之,通过 spider 爬取的数据都会通过这个 pipeline 处理,可以在 pipeline 中执行相关对数据的操作。
每个 item piple 组件是一个独立的 pyhton 类,必须实现 process_item(self,item,spider)方法,每个 item pipeline 组件都需要调用该方法,这个方法必须返回一个具有数据的 dict 或者 item 对象,或者抛出 DropItem 异常,被丢弃的 item 将不会被之后的 pipeline 组件所处理。
def download_from_url(url):
response = requests.get(url, stream=True)
if response.status_code == requests.codes.ok:
return response.content
else:
print('%s-%s' % (url, response.status_code))
return None
class SexyPipeline(object):
def __init__(self):
self.save_path = '/tmp'
def process_item(self, item, spider):
if spider.name == 'sexy':
# 取出item里内容
img_url = item['img_url']
# 业务处理
file_name = img_url.split('/')[-1]
content = download_from_url(img_url)
if content is not None:
with open(os.path.join(self.save_path, file_name), 'wb') as fw:
fw.write(content)
return item
1)process_item() 方法的参数有两个:item,是 Item 对象,即被处理的 Item;spider,是 Spider 对象,即生成该 Item 的 Spider。
2) process_item() 方法的返回类型:如果它返回的是 Item 对象,那么此 Item 会被低优先级的 Item Pipeline 的 process_item() 方法处理,直到所有的方法被调用完毕。如果它抛出的是 DropItem 异常,那么此 Item 会被丢弃,不再进行处理。
下面的方法也可以选择实现:
open_spider(self,spider)
open_spider() 方法是在 Spider 开启的时候被自动调用的。在这里我们可以做一些初始化操作,如开启数据库连接等。其中,参数 spider 就是被开启的 Spider 对象。
close_spider(self,spider)
close_spider() 方法是在 Spider 关闭的时候自动调用的。在这里我们可以做一些收尾工作,如关闭数据库连接等。其中,参数 spider 就是被关闭的 Spider 对象。
from_crawler(cls,crawler)
from_crawler() 方法是一个类方法,用 @classmethod 标识,是一种依赖注入的方式。它的参数是 crawler,通过 crawler 对象,我们可以拿到 Scrapy 的所有核心组件,如全局配置的每个信息,然后创建一个 Pipeline 实例。参数 cls 就是 Class,最后返回一个 Class 实例。
piplines.py 里的类必须在 settings.py 里的 ITEM_PIPELINES 字段中使用全类名定义,这样才能开启 piplines.py 里的类,否则不能使用。
(6)pipeline 的优先级
在 setting.py 中定义各个管道的优先级别,越低越爬取的优先度越高。
比如我的 pipelines.py 里面写了两个管道,一个爬取网页的管道,一个存数据库的管道。
在 setting.py 中调整他们的优先级,如果有爬虫数据,优先执行存库操作。
'scrapyP1.pipelines.BaiduPipeline': 300,
'scrapyP1.pipelines.BaiduMysqlPipeline': 200, }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号