
面试必问知识点
1.什么是面向对象?(谈谈你对面向对象的理解?)
可以和面向过程对比理解,比如洗衣机洗衣服.
面向过程会将任务拆解成多个步骤,一个步骤分为一个函数
1.打开洗衣机
2.放衣服
3.放洗衣粉
4.清洗
5.烘干
面向对象编程将任务拆解成对象:人和洗衣机
人:
1.打开洗衣机
2.放衣服
3.放洗衣粉
洗衣机:
1.清洗衣服
2.烘干
面向过程更注重事情的步骤以及顺序,面向对象更注重事情的参与者(对象)以及每个对象它需要做什么事情
优缺点:
- 面向过程更注重事情的本身,性能更加高效
- 面向对象将任务拆分成多个对象,这样更加易于复用,扩展和维护
面向对象的三大特性:继承,多态,封装
1.封装性:它是将类中的一些隐私数据隐藏在类的内部,并且让其无法被外界访问和修改
2.继承性:子类可以通过继承来接受父类所有的公有的成员变量和方法(public修饰符)、受到保护的成员变量和方法protect修饰符)、默认的成员变量和方法
3.多态性:程序在运行过程中,同一类型在不同那个条件下表现不同的结果
封装性体现方式:用private修饰符修饰的成员变量和成员方法,外界无法通过创建该类对象的方法对其中的私有变量进行修改。私有化属性之后,通过对外提供setter和getter方法来使外界访问属性,也可以通过对外开放接口,控制程序中属性的访问级别。
封装的目的就是增强安全性,外界只有通过提供的外部接口才能访问类的私有成员和属性。
继承
关于继承,java中一个类只能直接继承一个父类(可以实现多个接口),并且只能继承访问非私有(private)的属性和方法。子类可以通过重写,来改变父类中方法的具体内容,方法的命名必须和父类中的方法相同。
继承的主要目的就是代码复用,当父类中已经有所需要的方法或属性时,新创建的子类只要新添新的方法与属性,而无需重新定义父类的方法或属性。
多态
多态可以分成两种形式:设计时多态和运行时多态
设计时多态:重载
运行是多态:重写
多态的主要目的是增强代码的灵活性,可以在特定的情况下使用特定的方法。
java应该尽量减少继承关系,来降低耦合度,使用多态时,父类在调用方法时,优先调用子类的方法,如果子类未重写,则再调用父类的方法
面向对象的方法主要是把事物给对象化,包括其属性和行为。面向对象编程更贴近实际生活
的思想。总体来说面向对象的底层还是面向过程
面向对象的原则 (口诀):jdk醉了呀 接单开最里依
1.接口隔离原则
2.单一职责原则
3.开闭原则
4.最少知识原则
5.里氏替换原则
6.依赖倒置原则
2.JDK、JRE、JVM三者间的联系与区别

JDK
JDK(Java SE Development Kit),Java标准开发包,它提供了编译、运行Java程序所需的各种工具和资源,包括Java编译器、Java运行时环境,以及常用的Java类库等。
JRE
JRE( Java Runtime Environment) 、Java运行环境,用于解释执行Java的字节码文件。普通用户而只需要安装 JRE(Java Runtime Environment)来运行 Java 程序。而程序开发者必须安装JDK来编译、调试程序。
JVM
JVM(Java Virtual Mechinal),Java虚拟机,是JRE的一部分。它是整个java实现跨平台的最核心的部分,负责解释执行字节码文件,是可运行java字节码文件的虚拟计算机。所有平台的上的JVM向编译器提供相同的接口,而编译器只需要面向虚拟机,生成虚拟机能识别的代码,然后由虚拟机来解释执行。
当使用Java编译器编译Java程序时,生成的是与平台无关的字节码,这些字节码只面向JVM。不同平台的JVM都是不同的,但它们都提供了相同的接口。JVM是Java程序跨平台的关键部分,只要为不同平台实现了相应的虚拟机,编译后的Java字节码就可以在该平台上运行。
区别与联系
- JDK 用于开发,JRE 用于运行java程序 ;如果只是运行Java程序,可以只安装JRE,无序安装JDK。
- JDk包含JRE,JDK 和 JRE 中都包含 JVM。
- JVM 是 java 编程语言的核心并且具有平台独立性。
3.==和equals的区别
1)对于==,比较的是值是否相等
如果作用于基本数据类型的变量,则直接比较其存储的 值是否相等,
如果作用于引用类型的变量,则比较的是所指向的对象的地址是否相等。
其实==比较的不管是基本数据类型,还是引用数据类型的变量,比较的都是值,只是引用类型变量存的值是对象的地址
2)对于equals方法,比较的是是否是同一个对象
首先,equals()方法不能作用于基本数据类型的变量,
另外,equals()方法存在于Object类中,而Object类是所有类的直接或间接父类,所以说所有类中的equals()方法都继承自Object类,在没有重写equals()方法的类中,调用equals()方法其实和使用==的效果一样,也是比较的是引用类型的变量所指向的对象的地址,不过,Java提供的类中,有些类都重写了equals()方法,重写后的equals()方法一般都是比较两个对象的值,比如String类。
先看下Object类equals()方法源码:
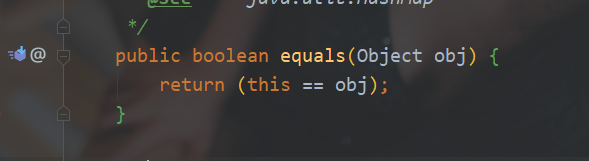
再看String类equals()方法源码:
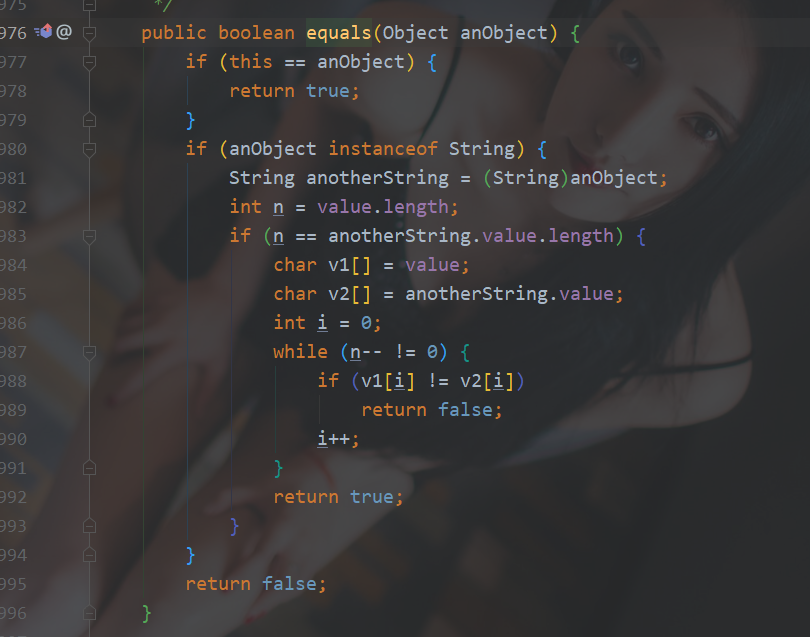
4.final的作用
- 修饰类(表明该类不可被继承,类中的所有成员方法都隐式的被指定为final方法,成员变量则可以定义为final,也可以不定义为final)
- 修饰方法
(锁定这个方法,防止任何继承类修改它的含义;
提高效率:在方法前面添加final进行修饰可以提高效率,其原理是基于内联/内嵌(inline)机制,它会使你在调用final方法时,直接将方法的主体插入到调用处,从而省去调用函数所花费的开销。但是如果方法过于庞大或者其中有循环的话,这种提高效率的方法可能会失效) - 修饰变量(final对变量的修饰的作用,是防止变量值的改变)
如果修饰的是基本类型数据变量,则该变量的值不能发生改变;
如果修饰的是引用类型数据变量,则该变量不会被二次初始化.
** 强调:**
- 由于引用类型数据变量被初始化后,其值是一个地址,所以不会被二次初始化,则地址不改变。
- 当用final作用于类的成员变量时,成员变量(注意是类的成员变量,局部变量只需要保证在使用之前被初始化赋值即可)必须在定义时或者构造器中进行初始化赋值,而且final变量一旦被初始化赋值之后,就不能再被赋值了。
- 引用变量被final修饰之后,虽然不能再指向其他对象,但是它指向的对象的内容是可变的。
- static作用于成员变量用来表示只保存一份副本,而final的作用是用来保证变量不可变。
5.String,StringBuffer,StringBuilder区别和使用场景
String

可以看到它是final修饰的,是不可变的字符串,也就是说在做一些操作比如拼接字符串,其实是产生一个新的对象,当业务对字符串的内容操作频繁,每一次都会创建一个新的字符串对象,这样就会造成一些内存浪费,建议使用StringBuffer,StringBuilder.
StringBuffer和StringBuilder
相同点:
可变字符串,做字符串拼接的时候,始终操作的是原对象,就不会去不断产生一个新的对象
区别:
StringBuffer:线程安全,因为内部方法都加了synchronized关键字,不需要额外加锁
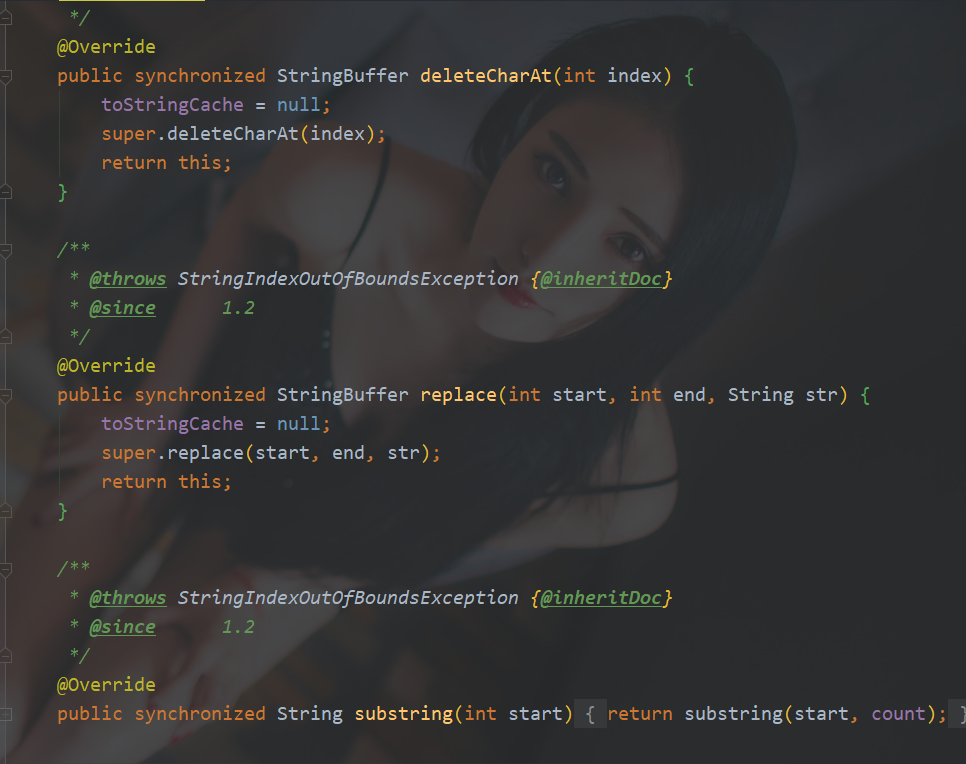
StringBuilder:线程不安全,实现线程安全需要额外加锁实现
三者使用场景总结
1.如果要操作少量的数据用 String
2.单线程操作字符串缓冲区下操作大量数据 StringBuilder
3.多线程操作字符串缓冲区下操作大量数据 StringBuffer
6.重载(Overload)和重写(Override)的区别
方法的重载和重写都是实现多态的方式,区别在于前者实现的是编译时的多态性,而后者实现的是运行时的多态性。
重载发生在一个类中,同名的方法如果有不同的参数列表(参数类型不同、参数个数不同或者二者都不同)则视为重载;
重写发生在子类与父类之间,重写要求子类被重写方法与父类被重写方法有相同的参数列表,相同的返回类型和相同的方法名,不能比父类被重写方法声明更多的异常(里氏代换原则)。
重载对返回类型没有特殊的要求,不能根据返回类型进行区分。
注意:
1.子类中不能重写父类中的final方法
2.子类中必须重写父类中的abstract方法
7.抽象类和接口的区别
抽象类
抽象方法必须用abstract关键字进行修饰。如果一个类含有抽象方法,则称这个类为抽象类,抽象类必须在类前用abstract关键字修饰。因为抽象类中含有无具体实现的方法,所以不能用抽象类创建对象。
抽象类可以拥有成员变量和普通的成员方法。
抽象类和普通类的主要有三点区别:
1)抽象方法必须为public或者protected(因为如果为private,则不能被子类继承,子类便无法实现该方法),缺省情况下默认为public。
2)抽象类不能用来创建对象;
3)如果一个类继承于一个抽象类,则子类必须实现父类的抽象方法。如果子类没有实现父类的抽象方法,则必须将子类也定义为为abstract类。
接口
接口中的变量会被隐式地指定为public static final变量,并且只能是public static final变量,用private修饰会报编译错误,而方法会被隐式地指定为public abstract方法且只能是public abstract方法,用其他关键字,比如private、protected、static、 final等修饰会报编译错误,并且接口中所有的方法不能有具体的实现,也就是说,接口中的方法必须都是抽象方法。
抽象类和接口的区别:
语法层面上的区别
1)一个类只能继承一个抽象类,而一个类却可以实现多个接口;
2)抽象类中的成员变量可以是各种类型的,而接口中的成员变量只能是public static final类型的;
3)接口中不能含有静态代码块以及静态方法,而抽象类可以有静态代码块和静态方法;
4)抽象类可以提供成员方法的实现细节,而接口中只能存在public abstract 方法;
5)抽象类的抽象方法可以是public,protected,default类型,而接口的方法只能是public。
设计层面上的区别
1)抽象类的设计目的是达到代码的一种复用,是对类的本质的一个抽象,包括属性、行为,表达的是"is a"关系,而接口的设计目的是约束类的一个行为,约束这一个"有"的行为,提供了一种机制去让不同的类具有相同的行为,只能约束行为的"有无",对行为的具体实现是不做约束的,是对行为的一个抽象,表达的是 "like a"的关系。
继承是一个 "是不是"的关系,而 接口 实现则是 "有没有"的关系。
2)设计层面不同,抽象类作为很多子类的父类,它是一种模板式设计。而接口是一种行为规范,它是一种辐射式设计。
8.hashCode和equals
hashCode(哈希码),hashCode方法是去获取这个哈希码
我们知道我们的对象都是保存在堆里面的,堆里面其实维护了一个hash表,哈希码是为了确认对象在哈希表中的一个索引位置,哈希表是以key-value形式存储的,通过key(哈希码)快速找到对象在堆里面的一个具体位置.
比如说有个对象要加入到hashSet里面去,hashSet首先通过hashCode()方法会去获取它的一个哈希值,通过哈希值在哈希表中找到具体位置,看是不是有值,如果没有就加入,有的话在进行equals进行比较,如果结果为true(对象相等)就不加入,为fasle(对象不相等)就重新将这个对象散列到别的位置去.
如果没有hashCode,我们需要将哈希表的所有对象拿出来与新对象进行equals比较,由于equals对比的是内存,性能是很慢的,有了hashCode就不需要进行全部对比,就会大大提升执行的速度
两个obj,如果equals()相等,hashCode()一定相等。
两个obj,如果hashCode()相等,equals()不一定相等(Hash散列值有冲突的情况,虽然概率很低)。
equals方法被覆盖的话,hashCode方法也必须被覆盖
所以:
可以考虑在集合中,判断两个对象是否相等的规则是:
第一步,如果hashCode()相等,则查看第二步,否则不相等;
第二步,查看equals()是否相等,如果相等,则两obj相等,否则还是不相等。
9.使用static修饰属性或方法后,属性和方法有什么特征?
static修饰属性或方法后,属性和方法不在属于某个特定的对象,成为类对象,被所有此类的实例所共享,在类加载时就被初始化。Static修饰的属性或方法,可以直接使用类名调用,而不用先实例化对象再调用。
10.final, finally, finalize的区别
final:
final是一个修饰符,可以修饰变量、方法和类,如果final修饰变量,意味着变量的值在初始化后不能被改变;
防止编译器把final域重排序到构造函数外;(面试的时候估计答出这个估计会加分哦!面试加分项)
finalize:
finalize方法是在对象被回收之前调用方法,可以给对象自己最后一个复活的机会;
finally:
finally与try和catch一起用于异常处理,finally块一定会被执行,无论在try块中是否发生异常;
11.sleep() 和 wait() 有什么区别?
sleep 是线程类(Thread)的方法,导致此线程暂停执行指定时间,给执行机会给其他线程,但是监控状态依然保持,到时后会自动恢复。调用sleep 不会释放对象锁。
wait 是Object 类的方法,对此对象调用wait方法导致本线程放弃对象锁,进入等待此对象的等待锁定池,只有针对此对象发出notify方法(或notifyAll)后本线程才进入对象锁定池准备获得对象锁进入运行状态。
12.数据库事务的几大特性,针对数据库事务,以mysql为例,该数据库有几种隔离级别,请阐述每种隔离级别所产生的效果
数据库事务的4大特性——ACID特性
原子性A(Atomicity):事务是不可分割的最小工作单元,整个事务的操作要么全部成功,要么全部回滚失败
一致性C(Consistency):事务对同一数据的读取结果是相同的
隔离性I(Isolation):一个事务所做的修改在最终提交以前,对其他事务是不可见的
持久性D(Durability):事务一旦提交,其所做的修改会永久保存在数据库中
隔离级别
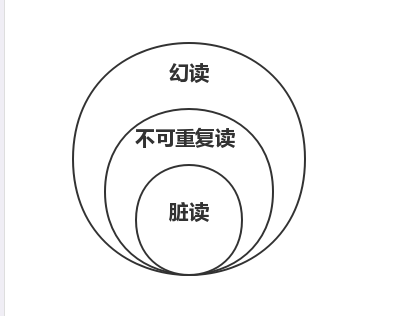
此图可以理解为 如果发生了脏读,那么不可重复读和幻读是一定发生的。因为拿脏读的现象,用不可重复读,幻读的定义也能解释的通。但是反过来,拿不可重复读的现象,用脏读的定义就不一定解释的通了!
未提交读:事务中的修改即使没有提交,对其他事务也是可见的(一个事务可以读到另一个事务未提交的数据)
提交读:事务所做的修改在提交之前,对其他事务是不可见的(防止脏读)
可重复读:保证同一事务中多次读取同一数据的结果是相同的(防止脏读、不可重复读)
可串行化:强制串行执行,事务之间互不干扰(防止脏读、不可重复读、幻读)
总结:
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| 未提交读 | 是 | 是 | 是 |
| 不可重复读(提交读) | 否 | 是 | 是 |
| 可重复读 | 否 | 否 | 是 |
| 可串行化 | 否 | 否 | 否 |
13.synchronized 和 Lock的区别
1.synchronized是一个关键字,而Lock是一个类
2.synchronized无法判断 获取锁的状态, Lock可以
3.synchronized会自动释放锁, Lock必须手动上锁和解锁
4.synchronized线程阻塞会一直等待 Lock却不一定
5.synchronized适用于少量代码同步, Lock适用于大量代码同步
14.手写单例模式
饿汉式
class Singleton {
private static Singleton instance=new Singleton();
private Singleton(){}
static Singleton getInstance() {
return instance;
}
}
懒汉式
class Singleton {
private static Singleton instance=null;
private Singleton(){}
static Singleton getInstance() {
if(instance==null)
instance=new Singleton();
return instance;
}
}


 ヾ(≧O≦)〃嗷~,
ヾ(≧O≦)〃嗷~,




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异
· 三行代码完成国际化适配,妙~啊~