
DB-SQLServer:执行计划----执行计划的生成
SQL Server使用许多技术来优化资源消耗:
- 基于语法的查询优化;
- 无用计划匹配以避免对简单查询的深度优化;
- 根据当前分布统计的索引和连接策略;
- 多阶段的查询优化以控制优化开销;
- 执行计划缓冲以避免重新生成执行计划;
以上技术按以下顺序执行:
- 解析器;
- 代数化器;
- 查询优化器;
- 执行计划生成,缓冲和hash计划生成;
- 查询执行;
其执行顺序如下:
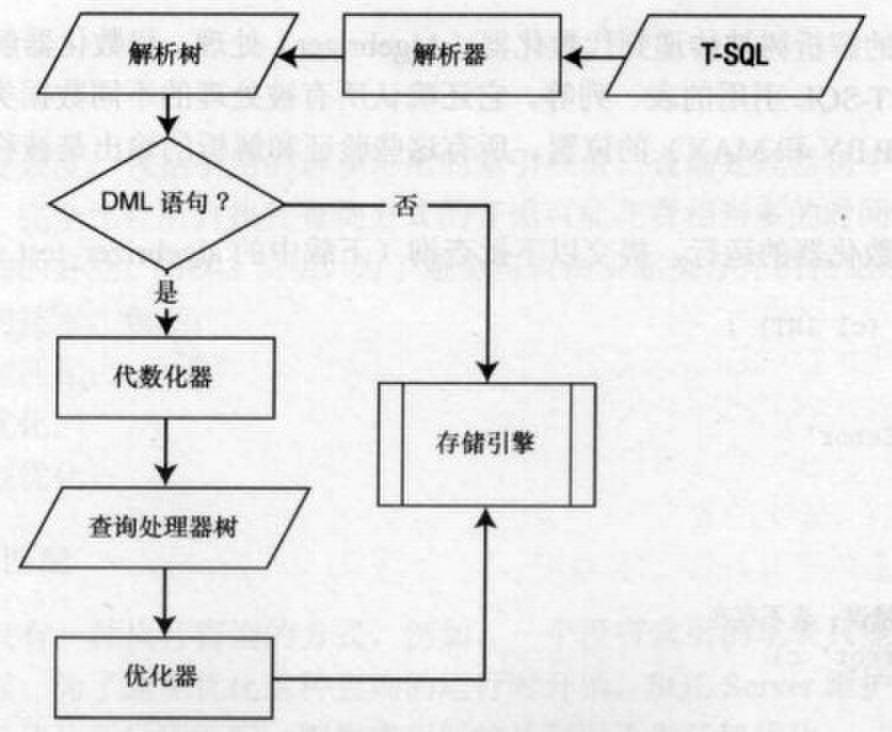
一、解析器(parser)
当查询被提交时,SQL Server将它传递给关系引擎中的解析器。
- 关系引擎-负责解析、名称和类型解析、优化和按照查询执行计划执行查询并从存储引擎请求数据;
- 存储引擎-负责数据访问、修改、缓冲;
解析器检查进入的查询,验证其语法是否正确。如果发现一个语法错误则查询被终止。如果多个查询作为一个批被一起提交,如下:
CREATE TABLE t1(c1 INT)
INSERT INTO t1 VALUES(1)
AELECE * FROM t1 --注意,SELECT拼写错误
GO
解析器检查整个批的语法并在发现语法错误时撤销整个批(批中可能出现多个语法错误,但是解析器发现第一个错误后就不再继续,所以批中有语法错误时代码是一行都不会执行的。)在验证查询的语法时,解析器为代数化器生成一个称为解析树的内部数据结构。解析器和代数化器被统称为查询编译。
二、代数化器(Algebrizer)
解析器生成的解析树被传递到代数化器处理。代数化器解析不同对象的所有名称,也就是T-SQL引用的表、列等。它还确认所有被处理的不同数据类型,甚至还检查聚合(GROUP BY、MAX)的位置。所有这些验证和解析的输出是被称为查询处理器树的二进制数据集。
为了了解代数化器的运行,提交以下批查询:
CREATE TABLE t1(c1 INT);
INSERT INTO t1 VALUES(1);
SELECT 'Before Error',c1 FROM t1 AS t; --下面的没执行
SELECT 'error',c1 FROM no_t1; --no_t1表不存在
SELECT 'after error' c1 FROM t1 AS t;
对于以上语句,头3条被执行了。错误及之后的语句被撤销了。
如果查询包含一个隐含的数据转换,规范化进程在查询树中添加一个正确的步骤。该进程还执行一些基于语法的优化。如:
SELECT * FROM Person WHERE Id BETWEEN 100 and 150
则基于语法的优化将转换该查询的语法。
对于大部分数据定义语言(DDL)语句(如CREATE TABLE、CREATE PROC等)来说,在通过代数化器之后,该查询直接被编译以执行,因为优化器不需要在多种处理策略中选择。对于特别的DDL语句CREATE INDEX,优化器可以根据其他表上现有的索引来决定一个有效的处理策略。
因此,执行计划中不会看到对CREATE TABLE的引用,但是会看到CREATE INDEX的引用。如果规范化的查询时一条数据操纵语言(DML)语句,则查询处理器树被传递给优化器以决定该查询的处理策略。

三、优化
根据查询的复杂度,包括引用的表和可用的索引数量,查询处理器树中包含的查询可能由多种知心方式。完全比较所有执行查询方式的开销可能要花费较多的时间,有时即使找到最优化查询也是得不偿失。为了避免过多的优化开销,优化器采用不同的技术,包括:
- 无用计划匹配;
- 多阶段优化;
- 并行计划优化;
1、无用计划匹配
有时候可能只有一种执行查询的方式。例如,堆表只能通过表扫描来获取数据,为了避免浪费时间来优化这种查询,SQL Server维护了一个无用计划列表供选择,如果优化器在无用列表中发现与查询有匹配的计划,则生成相似的计划而不再做任何优化。
2、多阶段优化
对于复杂的查询,需要分析的替代处理策略数量可能很大,评估每个选择可能花费很长的时间。因此,优化器不分析所有可能的处理策略,而是将他们分为几种配置,每个配置含不同的索引和连接技术。
索引变种考虑不同的索引特性,单列索引、复合索引、索引列顺序、索引密度等。相似地,连接变种考虑SQL Server中可用的不同连接技术:嵌套循环连接、合并连接和哈希匹配。
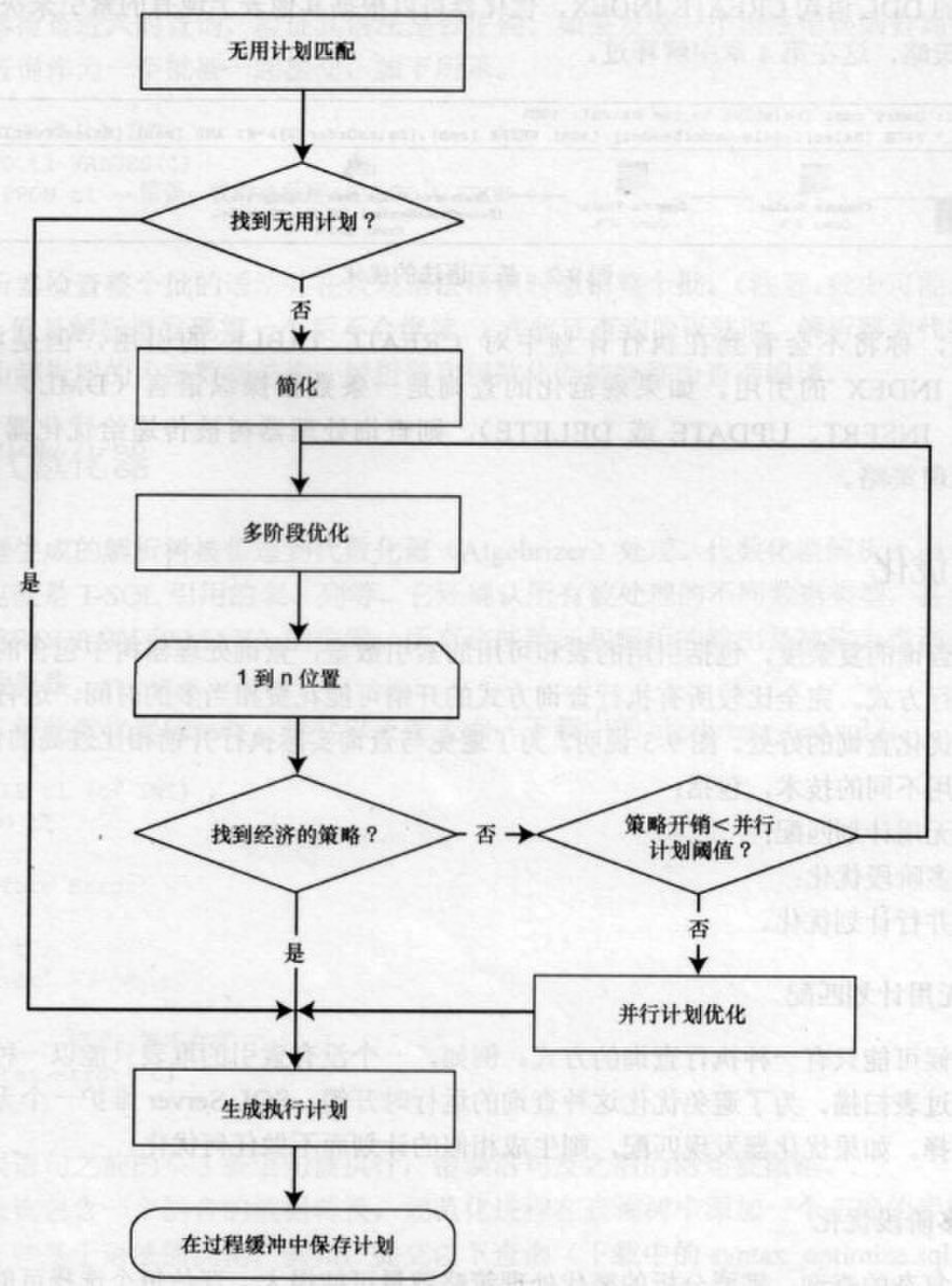
优化器考虑WHERE子句中引起的列的统计以评估索引和连接策略的有效性。根据当前的统计,它在多个优化阶段中评估配置的开销。开销包括许多因素,包含执行查询所需要的CPU、内存的使用和磁盘I/O。每个优化阶段之后,优化器评估处理策略的开销。如果开销足够经济,优化器停止在优化阶段进一步循环并退出优化过程。否则继续在优化阶段中循环以确定一个高成本效益的处理策略。
有时候查询可能太复杂,以至优化器必须广泛地在优化阶段中循环。在优化查询时,如果发现处理策略的开销高于并行开下阈值,则使用多个CPU评估处理该查询的开销。否则,优化器使用串行计划。
- 缓冲计划的大小;
- 用于编译该计划的CPU周期;
- 使用的内存量;
- 编译时间;
优化水平属性说明优化器中出现的处理类型。在这个例子中,FULL表示优化器进行了完全优化。这在属性“语句终端原因”中进一步提示,原因是“找到足够好的计划”。所以,优化器花费21ms来捕捉到这种情形下被认为足够好的计划。还可以查看执行计划的查询计划hash值。
第二个优化器信息原来是动态管理视图sys.dm_exec_query_optimizer_info。这个DMV是优化事件的集合体,它不会显示给定查询的单独优化,但是可以跟踪行的优化。这不能直接用于调整单个查询,但是如果打算随时减少工作负载的开销,跟踪这些信息能够能帮助确定查询调整是否产生正面的影响,至少在优化时间方面,一些返回的数据只用于SQL Server内部。.
执行如下查询:
SELECT Counter,Occurrence,Value FROM sys.dm_exec_query_optimizer_info
在一组优化之前和之后运行这个查询,可以看到完成的优化数量和类型的变化。
3、并行计划优化
优化器在评估处理查询的开销时使用并行计划考虑各种因素。
- 可用于SQL Server的CPU数量;
- SQL Server版本;
- 可用内存;
- 执行的查询类型;
- 给定流中处理的行数;
- 活动的冰法连接数量;
如果只有一个CPU可用于SQL Server,优化器不会考虑并行计划。可用于SQL Server的CPU数量可以使用SQL Server配置的affinity mask设置来显示。affinity mask值是一个位图,一位代表一个CPU,最右边的位置代表CPU0。例如,在8路的计算机只允许SQL Server使用CPU0-CPU3,执行如下语句:
USE master
EXEC sp_configure 'show advanced option', '1'
RECONFIGURE
EXEC sp_configure 'affinity mask', 15 --位图:00001111
RECONFIGURE
这个配置立即生效。affinity mask是一个特殊的设置,建议只在剥夺SQL Server控制权有意义的情况下使用它,例如有多个运行在相同计算机上的SQL Server实例并且希望它们互相隔离时, 要设置超过32个处理器,必须使用只在SQL Server64位版本上可用的affinity64 mask选项。还 可以使用affinity mask I/O选项来将I/O绑定到特定的处理器集。
即使多个CPU可用于SQL Server。一个并行查询可以使用的CPU最大数量由SQL Server配置中的max degree of parallelism设置管理。默认值为0,允许所有CPU(affinity mask设置可用的)用于并行查询。
如果希望运行并行查询使用不超过CPU0-CPU3中的2个CPU,执行以下语句:
USE master
EXEC sp_configure 'show advanced option','1'
RECONFIGURE
EXEC sp_configure 'max degree of parallelism',2 --设置查询最高可使用2个CPU RECONFIGURE
这个修改立即生效,不需要重启。max degree of parallelism设置页可以使用MAXDOP查询提示
在查询级别上控制:
SELECT * FROM Person WHERE Name='张三' OPTION(MAXDOP 2)
修改max degree of parallelism设置最好由系统需求决定。为了限制与操作系统争用,通常将 max degree of parallelism设置为比服务器CPU数量少1,并将affinity mask也设置为这些CPU。
因为并行查询需要更多内存,所以优化器在选择并行计划之前需确定可用内存的数量。所需内存的数量随着并行程序而增加。如果给定并行程度的并行计划内存需求不能满足,SQL Server将自动降低并行程度或者在给定的工作负载上下文中完全放弃并行计划。
具有非常高的CPU开销的查询时并发计划的最佳候选。如包含连接大的表,执行大量的聚合运算,以及排序大的结果集。对于通常在事务处理应用程序中找到的简单查询来说,初始化、同步和停止并行计划所需的额外调整超过了潜在的性能优势。
查询是否简单通过比较估算的执行时间和开销阈值来确定。这个开销阈值由SQL Server配置的cost threshold for parallelism设置控制。默认情况下,这个设置为5,意味着如果串行计划估算的执行时间超过5秒,则优化器考虑使用并行计划。例如,要将开销阈值修改为6秒,执行以下语句:
USE master
EXEC sp_configure 'show advances option','1'
RECONFIGURE
EXEC sp_configure 'cost threshold for parallelism',6
RECONFIGURE
这个修改不需要重启立即生效。如果只有一个CPU可用于SQL Server,这个设置将被忽略。OLTP系统会因为并行性阈值设置太低而受到损害。通常将这些值增加到15-25秒之间比较有利。
DML操作查询(INSERT、UPDATE和DELETE)串行查询。但是,INSERT语句的SELECT部分和UPDATE或DELETE语句的WHERE语句可以并行执行。实际的数据修改被严格地应用到数据库。而且,如果优化器确定所影响的行太少,它不会引入并行操作符。
注意,即使在执行时,SQL Server确定当前系统工作负载和配置信息是否允许并行查询计划。如果允许并行查询计划,SQL Server确定现成的最有数量并将查询的执行分布到这些线程。当查询开始并行执行,它使用相同的线程数量直到完成。SQL Server在下次执行并行查询时重新检查最优线程数量。
处理策略被使用串行或并行计划定稿之后,优化器为查询生成后执行计划。该执行计划包括优化器确定的执行该查询的详细处理策略。这包括诸如数据检索、结果集连接、结果集排序等步骤。
生成的查询计划被保存在计划缓冲中供未来使用。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号