
结合中断上下文切换和进程上下文切换分析Linux内核的一般执行过程
结合中断上下文切换和进程上下文切换分析Linux内核的一般执行过程
一. 实验准备
- 详细要求
结合中断上下文切换和进程上下文切换分析Linux内核一般执行过程
- 以fork和execve系统调用为例分析中断上下文的切换
- 分析execve系统调用中断上下文的特殊之处
- 分析fork子进程启动执行时进程上下文的特殊之处
- 以系统调用作为特殊的中断,结合中断上下文切换和进程上下文切换分析Linux系统的一般执行过程
完成一篇博客总结分析Linux系统的一般执行过程,以期对Linux系统的整体运作形成一套逻辑自洽的模型,并能将所学的各种OS和Linux内核知识/原理融通进模型中
- 实验环境
发行版本:Ubuntu 18.04.4 LTS
处理器:Intel® Core™ i7-8850H CPU @ 2.60GHz × 3
图形卡:Parallels using AMD® Radeon pro 560x opengl engine
GNOME:3.28.2
二. 实验过程
I 分析中断上下文的切换
中断发生以后,CPU跳到内核设置好的中断处理代码中去,由这部分内核代码来处理中断。这个处理过程中的上下文就是中断上下文。
几乎所有的体系结构,都提供了中断机制。当硬件设备想和系统通信的时候,它首先发出一个异步的中断信号去打断处理器的执行,继而打断内核的执行。中断通常对应着一个中断号,内核通过这个中断号找到中断服务程序,调用这个程序响应和处理中断。当你敲击键盘时,键盘控制器发送一个中断信号告知系统,键盘缓冲区有数据到来,内核收到这个中断号,调用相应的中断服务程序,该服务程序处理键盘数据然后通知键盘控制器可以继续输入数据了。为了保证同步,内核可以使用中止---既可以停止所有的中断也可以有选择地停止某个中断号对应的中断,许多操作系统的中断服务程序都不在进程上下文中执行,它们在一个与所有进程无关的、专门的中断上下文中执行。之所以存在这样一个专门的执行环境,为了保证中断服务程序能够在第一时间响应和处理中断请求,然后快速退出。
对同一个CPU来说,中断处理比进程拥有更高的优先级,所以中断上下文切换并不会与进程上下文切换同时发生。由于中断程序会打断正常进程的调度和运行,大部分中断处理程序都短小精悍,以便尽可能快的执行结束。
一个进程的上下文可以分为三个部分:用户级上下文、寄存器上下文以及系统级上下文。
用户级上下文: 正文、数据、用户堆栈以及共享存储区;
寄存器上下文: 通用寄存器、程序寄存器(IP)、处理器状态寄存器(EFLAGS)、栈指针(ESP);
系统级上下文: 进程控制块task_struct、内存管理信息(mm_struct、vm_area_struct、pgd、pte)、内核栈。
当发生进程调度时,进行进程切换就是上下文切换(context switch)。操作系统必须对上面提到的全部信息进行切换,新调度的进程才能运行。而系统调用进行的是模式切换(mode switch)。模式切换与进程切换比较起来,容易很多,而且节省时间,因为模式切换最主要的任务只是切换进程寄存器上下文的切换。
II 分析fork子进程启动执行时进程上下文及其特殊之处
fork()系统调用会通过复制一个现有进程来创建一个全新的进程. 进程被存放在一个叫做任务队列的双向循环链表当中。链表当中的每一项都是类型为task_struct成为进程描述符的结构。
首先我们来看一段代码
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main(){
pid_t pid;
char *message;
int n;
pid = fork();
if(pid<0){
perror("fork failed");
exit(1);
}
if (pid == 0){
message = "this is the child \n";
n=6;
}else {
message = "this is the parent \n";
n=3;
}
for(;n>0;n--){
printf("%s",message);
sleep(1);
}
return 0;
}
在Linux环境中编写和执行
# 创建一个C文件,名为t.c,将上面的代码拷贝进去
touch t.c
# 进行编译
gcc t.c
# 执行
./a.out

之所以输出是这样的结果,是因为程序的执行流程如下图所示:
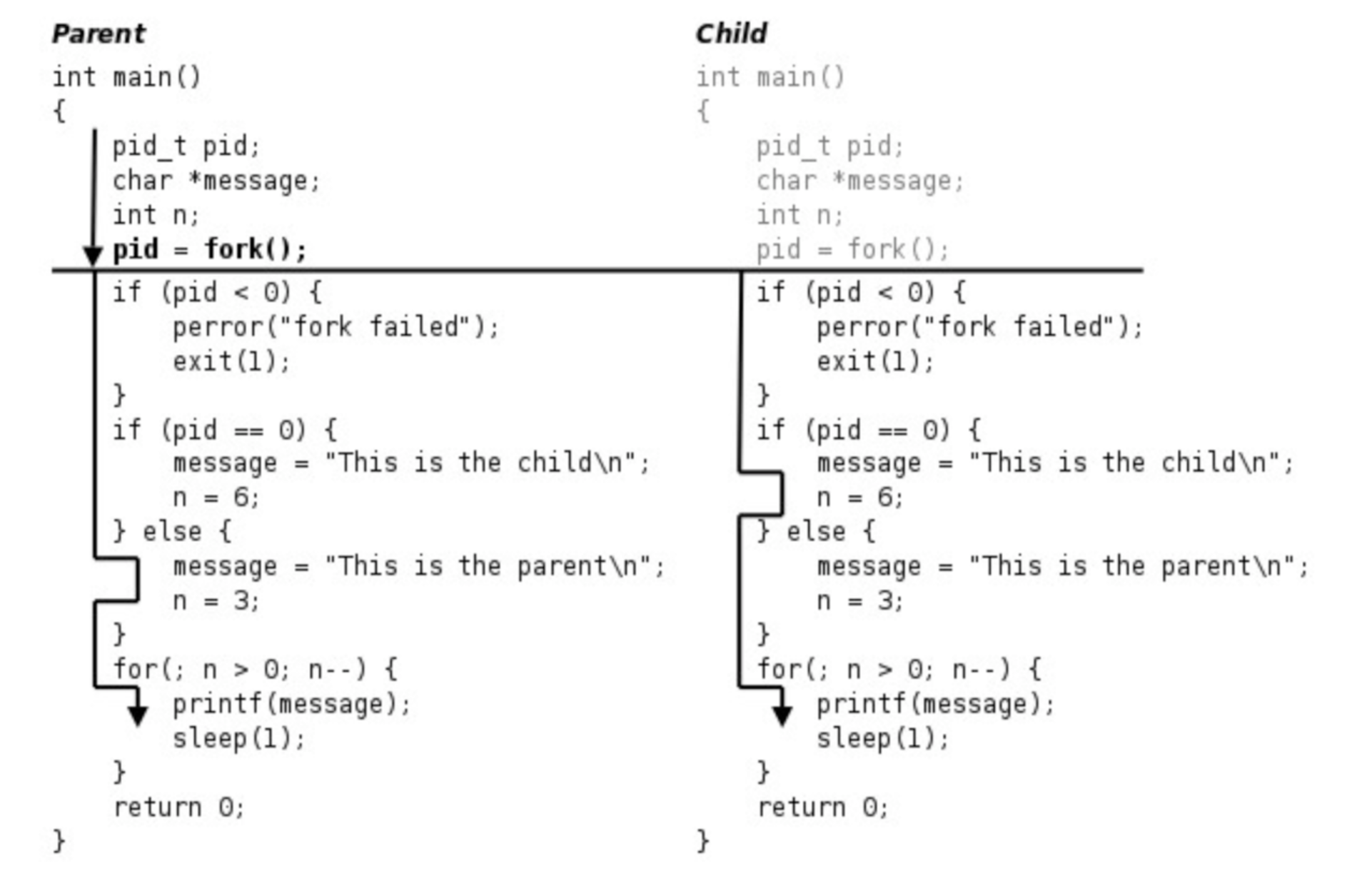
以上的fork()例子的执行流程大致如下:
- 父进程初始化。
- 父进程调用
fork,这是一个系统调用,因此进入内核。 - 内核根据父进程复制出一个子进程,父进程和子进程的PCB信息相同,用户态代码和数据也相同。因此,子进程现在的状态看起来和父进程一样,做完了初始化,刚调用了
fork进入内核,还没有从内核返回。 - 现在有两个一模一样的进程看起来都调用了
fork进入内核等待从内核返回(实际上fork只调用了一次),此外系统中还有很多别的进程也等待从内核返回。是父进程先返回还是子进程先返回,还是这两个进程都等待,先去调度执行别的进程,这都不一定,取决于内核的调度算法。 - 如果某个时刻父进程被调度执行了,从内核返回后就从
fork函数返回,保存在变量pid中的返回值是子进程的id,是一个大于0的整数,因此执下面的else分支,然后执行for循环,打印"This is the parent\n"三次之后终止。 - 如果某个时刻子进程被调度执行了,从内核返回后就从
fork函数返回,保存在变量pid中的返回值是0,因此执行下面的if (pid == 0)分支,然后执行for循环,打印"This is the child\n"六次之后终止。fork调用把父进程的数据复制一份给子进程,但此后二者互不影响,在这个例子中,fork调用之后父进程和子进程的变量message和n被赋予不同的值,互不影响。 - 父进程每打印一条消息就睡眠1秒,这时内核调度别的进程执行,在1秒这么长的间隙里(对于计算机来说1秒很长了)子进程很有可能被调度到。同样地,子进程每打印一条消息就睡眠1秒,在这1秒期间父进程也很有可能被调度到。所以程序运行的结果基本上是父子进程交替打印,但这也不是一定的,取决于系统中其它进程的运行情况和内核的调度算法,如果系统中其它进程非常繁忙则有可能观察到不同的结果。另外,读者也可以把
sleep(1);去掉看程序的运行结果如何。 - 这个程序是在Shell下运行的,因此Shell进程是父进程的父进程。父进程运行时Shell进程处于等待状态,当父进程终止时Shell进程认为命令执行结束了,于是打印Shell提示符,而事实上子进程这时还没结束,所以子进程的消息打印到了Shell提示符后面。最后光标停在
This is the child的下一行,这时用户仍然可以敲命令,即使命令不是紧跟在提示符后面,Shell也能正确读取。
fork()最特殊之处在于:成功调用后返回两个值,是由于在复制时复制了父进程的堆栈段,所以两个进程都停留在fork函数中,等待返回。所以fork函数会返回两次,一次是在父进程中返回,另一次是在子进程中返回,这两次的返回值不同,
其中父进程返回子进程pid,这是由于一个进程可以有多个子进程,但是却没有一个函数可以让一个进程来获得这些子进程id,那谈何给别人你创建出来的进程。而子进程返回0,这是由于子进程可以调用getppid获得其父进程进程ID,但这个父进程ID却不可能为0,因为进程ID0总是有内核交换进程所用,故返回0就可代表正常返回了。
从fork函数开始以后的代码父子共享,既父进程要执行这段代码,子进程也要执行这段代码.(子进程获得父进程数据空间,堆和栈的副本. 但是父子进程并不共享这些存储空间部分. (即父,子进程共享代码段.)。现在很多实现并不执行一个父进程数据段,堆和栈的完全复制. 而是采用写时拷贝技术。这些区域有父子进程共享,而且内核地他们的访问权限改为只读的.如果父子进程中任一个试图修改这些区域,则内核值为修改区域的那块内存制作一个副本, 也就是如果你不修改我们一起用,你修改了之后对于修改的那部分内容我们分开各用个的。
再一个就是,在重定向父进程的标准输出时,子进程标准输出也被重定向。这就源于父子进程会共享所有的打开文件。 因为fork的特性就是将父进程所有打开文件描述符复制到子进程中。当父进程的标准输出被重定向,子进程本是写到标准输出的时候,此时自然也改写到那个对应的地方;与此同时,在父进程等待子进程执行时,子进程被改写到文件show.out中,然后又更新了与父进程共享的该文件的偏移量;那么在子进程终止后,父进程也写到show.out中,同时其输出还会追加在子进程所写数据之后。
在fork之后处理文件描述符一般有以下两种情况:
- 父进程等待子进程完成。此种情况,父进程无需对其描述符作任何处理。当子进程终止后,它曾进行过读,写操作的任一共享描述符的文件偏移已发生改变。
- 父子进程各自执行不同的程序段。这样fork之后,父进程和子进程各自关闭它们不再使用的文件描述符,这样就避免干扰对方使用的文件描述符了。这类似于网络服务进程。
同时父子进程也是有区别的:它们不仅仅是两个返回值不同;它们各自的父进程也不同,父进程的父进程是ID不变的;还有子进程不继承父进程设置的文件锁,子进程未处理的信号集会设置为空集等不同
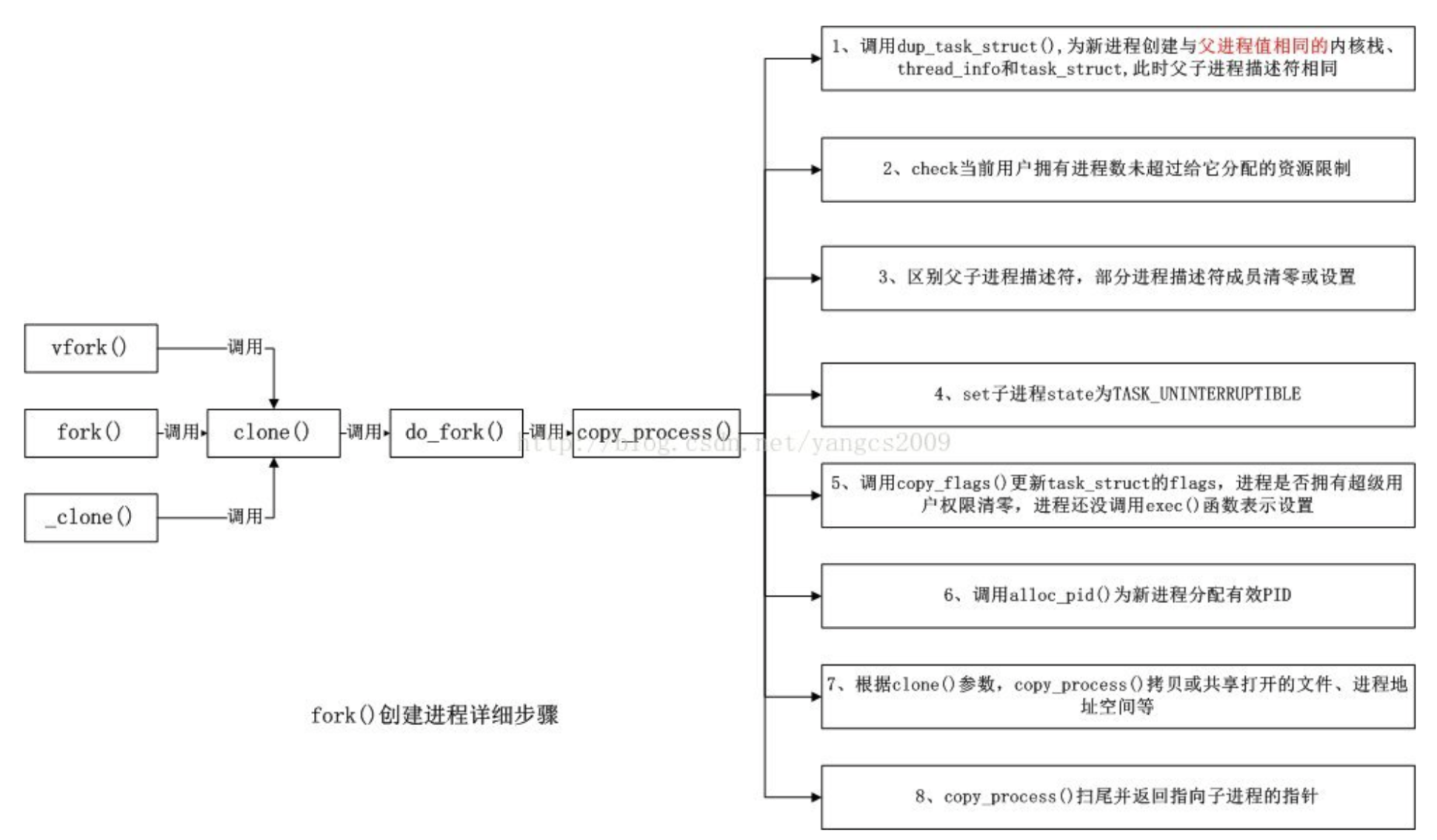
事实上linux平台通过clone()系统调用实现fork()。fork(),vfork()和clone()库函数都根据各自需要的参数标志去调用clone(),然后由clone()去调用do_fork(). 再然后do_fork()完成了创建中的大部分工作,他定义在kernel/fork.c当中.该函数调用copy_process()。
具体的流程可以参考下图:
III 分析execve系统调用中断上下文及其特殊之处
execve() 系统调用的作用是运行另外一个指定的程序。它会把新程序加载到当前进程的内存空间内,当前的进程会被丢弃,它的堆、栈和所有的段数据都会被新进程相应的部分代替,然后会从新程序的初始化代码和 main 函数开始运行。同时,进程的 ID 将保持不变。
execve() 系统调用通常与 fork() 系统调用配合使用。从一个进程中启动另一个程序时,通常是先 fork() 一个子进程,然后在子进程中使用 execve() 变身为运行指定程序的进程。 例如,当用户在 Shell 下输入一条命令启动指定程序时,Shell 就是先 fork() 了自身进程,然后在子进程中使用 execve() 来运行指定的程序。
Linux提供了execl、execlp、execle、execv、execvp和execve等六个用以执行一个可执行文件的函数(统称为exec函数,其间的差异在于对命令行参数和环境变量参数的传递方式不同)。这些函数的第一个参数都是要被执行的程序的路径,第二个参数则向程序传递了命令行参数,第三个参数则向程序传递环境变量。以上函数的本质都是调用在arch/i386/kernel/process.c文件中实现的系统调用sys_execve来执行一个可执行文件。
asmlinkage int sys_execve(struct pt_regs regs)
{
int error;
char * filename;
//将可执行文件的名称装入到一个新分配的页面中
filename = getname((char __user *) regs.ebx);
error = PTR_ERR(filename);
if (IS_ERR(filename))
goto out;
//执行可执行文件
error = do_execve(filename,
(char __user * __user *) regs.ecx,
(char __user * __user *) regs.edx,
®s);
if (error == 0) {
task_lock(current);
current->ptrace &= ~PT_DTRACE;
task_unlock(current);
set_thread_flag(TIF_IRET);
}
putname(filename);
out:
return error;
}
该系统调用所需要的参数pt_regs在include/asm-i386/ptrace.h文件中定义。该参数描述了在执行该系统调用时,用户态下的CPU寄存器在核心态的栈中的保存情况。通过这个参数,sys_execve可以获得保存在用户空间的以下信息:可执行文件路径的指针(regs.ebx中)、命令行参数的指针(regs.ecx中)和环境变量的指针(regs.edx中)。
struct pt_regs {
long ebx;
long ecx;
long edx;
long esi;
long edi;
long ebp;
long eax;
int xds;
int xes;
long orig_eax;
long eip;
int xcs;
long eflags;
long esp;
int xss;
};
regs.ebx保存着系统调用execve的第一个参数,即可执行文件的路径名。因为路径名存储在用户空间中,这里要通过getname拷贝到内核空间中。getname在拷贝文件名时,先申请了一个page作为缓冲,然后再从用户空间拷贝字符串。为什么要申请一个页面而不使用进程的系统空间堆栈?首先这是一个绝对路径名,可能比较长,其次进程的系统空间堆栈大约为7K,比较紧缺,不宜滥用。用完文件名后,在函数的末尾调用putname释放掉申请的那个页面。
sys_execve的核心是调用do_execve函数,传给do_execve的第一个参数是已经拷贝到内核空间的路径名filename,第二个和第三个参数仍然是系统调用execve的第二个参数argv和第三个参数envp,它们代表的传给可执行文件的参数和环境变量仍然保留在用户空间中。简单分析一下这个函数的思路:先通过open_err()函数找到并打开可执行文件,然后要从打开的文件中将可执行文件的信息装入一个数据结构linux_binprm,do_execve先对参数和环境变量的技术,并通过prepare_binprm读入开头的128个字节到linux_binprm结构的bprm缓冲区,最后将执行的参数从用户空间拷贝到数据结构bprm中。内核中有一个formats队列,该队列的每个成员认识并只处理一种格式的可执行文件,bprm缓冲区中的128个字节中有格式信息,便要通过这个队列去辨认。do_execve()中的关键是最后执行一个search_binary_handler()函数,找到对应的执行文件格式,并返回一个值,这样程序就可以执行了。
do_execve 定义在 <fs/exec.c> 中,关键代码解析如下。
int do_execve(char * filename, char __user *__user *argv,
char __user *__user *envp, struct pt_regs * regs)
{
struct linux_binprm *bprm; //保存要执行的文件相关的数据
struct file *file;
int retval;
int i;
retval = -ENOMEM;
bprm = kzalloc(sizeof(*bprm), GFP_KERNEL);
if (!bprm)
goto out_ret;
//打开要执行的文件,并检查其有效性(这里的检查并不完备)
file = open_exec(filename);
retval = PTR_ERR(file);
if (IS_ERR(file))
goto out_kfree;
//在多处理器系统中才执行,用以分配负载最低的CPU来执行新程序
//该函数在include/linux/sched.h文件中被定义如下:
// #ifdef CONFIG_SMP
// extern void sched_exec(void);
// #else
// #define sched_exec() {}
// #endif
sched_exec();
//填充linux_binprm结构
bprm->p = PAGE_SIZE*MAX_ARG_PAGES-sizeof(void *);
bprm->file = file;
bprm->filename = filename;
bprm->interp = filename;
bprm->mm = mm_alloc();
retval = -ENOMEM;
if (!bprm->mm)
goto out_file;
//检查当前进程是否在使用LDT,如果是则给新进程分配一个LDT
retval = init_new_context(current, bprm->mm);
if (retval 0)
goto out_mm;
//继续填充linux_binprm结构
bprm->argc = count(argv, bprm->p / sizeof(void *));
if ((retval = bprm->argc) 0)
goto out_mm;
bprm->envc = count(envp, bprm->p / sizeof(void *));
if ((retval = bprm->envc) 0)
goto out_mm;
retval = security_bprm_alloc(bprm);
if (retval)
goto out;
//检查文件是否可以被执行,填充linux_binprm结构中的e_uid和e_gid项
//使用可执行文件的前128个字节来填充linux_binprm结构中的buf项
retval = prepare_binprm(bprm);
if (retval 0)
goto out;
//将文件名、环境变量和命令行参数拷贝到新分配的页面中
retval = copy_strings_kernel(1, &bprm->filename, bprm);
if (retval 0)
goto out;
bprm->exec = bprm->p;
retval = copy_strings(bprm->envc, envp, bprm);
if (retval 0)
goto out;
retval = copy_strings(bprm->argc, argv, bprm);
if (retval 0)
goto out;
//查询能够处理该可执行文件格式的处理函数,并调用相应的load_library方法进行处理
retval = search_binary_handler(bprm,regs);
if (retval >= 0) {
free_arg_pages(bprm);
//执行成功
security_bprm_free(bprm);
acct_update_integrals(current);
kfree(bprm);
return retval;
}
out:
//发生错误,返回inode,并释放资源
for (i = 0 ; i MAX_ARG_PAGES ; i++) {
struct page * page = bprm->page;
if (page)
__free_page(page);
}
if (bprm->security)
security_bprm_free(bprm);
out_mm:
if (bprm->mm)
mmdrop(bprm->mm);
out_file:
if (bprm->file) {
allow_write_access(bprm->file);
fput(bprm->file);
}
out_kfree:
kfree(bprm);
out_ret:
return retval;
}
该函数用到了一个类型为linux_binprm的结构体来保存要执行的文件相关的信息,该结构体在include/linux/binfmts.h文件中定义:
struct linux_binprm{
char buf[BINPRM_BUF_SIZE]; //保存可执行文件的头128字节
struct page *page[MAX_ARG_PAGES];
struct mm_struct *mm;
unsigned long p; //当前内存页最高地址
int sh_bang;
struct file * file; //要执行的文件
int e_uid, e_gid; //要执行的进程的有效用户ID和有效组ID
kernel_cap_t cap_inheritable, cap_permitted, cap_effective;
void *security;
int argc, envc; //命令行参数和环境变量数目
char * filename; //要执行的文件的名称
char * interp; //要执行的文件的真实名称,通常和filename相同
unsigned interp_flags;
unsigned interp_data;
unsigned long loader, exec;
};
在该函数的最后,又调用了fs/exec.c文件中定义的search_binary_handler函数来查询能够处理相应可执行文件格式的处理器,并调用相应的load_library方法以启动进程。这里,用到了一个在include/linux/binfmts.h文件中定义的linux_binfmt结构体来保存处理相应格式的可执行文件的函数指针如下:
struct linux_binfmt {
struct linux_binfmt * next;
struct module *module;
// 加载一个新的进程
int (*load_binary)(struct linux_binprm *, struct pt_regs * regs);
// 动态加载共享库
int (*load_shlib)(struct file *);
// 将当前进程的上下文保存在一个名为core的文件中
int (*core_dump)(long signr, struct pt_regs * regs, struct file * file);
unsigned long min_coredump;
};
Linux内核允许用户通过调用在include/linux/binfmt.h文件中定义的register_binfmt和unregister_binfmt函数来添加和删除linux_binfmt结构体链表中的元素,以支持用户特定的可执行文件类型。
在调用特定的load_binary函数加载一定格式的可执行文件后,程序将返回到sys_execve函数中继续执行。该函数在完成最后几步的清理工作后,将会结束处理并返回到用户态中,最后,系统将会将CPU分配给新加载的程序。
execve系统调用的过程总结如下:
- execve系统调用陷入内核,并传入命令行参数和shell上下文环境
- execve陷入内核的第一个函数:do_execve,该函数封装命令行参数和shell上下文
- do_execve调用do_execveat_common,后者进一步调用__do_execve_file,打开ELF文件并把所有的信息一股脑的装入linux_binprm结构体
- do_execve_file中调用search_binary_handler,寻找解析ELF文件的函数
- search_binary_handler找到ELF文件解析函数load_elf_binary
- load_elf_binary解析ELF文件,把ELF文件装入内存,修改进程的用户态堆栈(主要是把命令行参数和shell上下文加入到用户态堆栈),修改进程的数据段代码段
- load_elf_binary调用start_thread修改进程内核堆栈(特别是内核堆栈的ip指针)
- 进程从execve返回到用户态后ip指向ELF文件的main函数地址,用户态堆栈中包含了命令行参数和shell上下文环境
IV 以系统调用作为特殊的中断,结合中断上下文切换和进程上下文切换分析Linux系统的一般执行过程
Linux系统的一般执行过程
正在运行的用户态进程X切换到运行用户态进程Y的过程
-
发生中断 ,完成以下步骤:
save cs:eip/esp/eflags(current) to kernel stack
load cs:eip(entry of a specific ISR) and ss:esp(point to kernel stack) -
SAVE_ALL //保存现场,这里是已经进入内核中断处里过程
-
中断处理过程中或中断返回前调用了schedule(),其中的switch_to做了关键的进程上下文切换
-
标号1之后开始运行用户态进程Y(这里Y曾经通过以上步骤被切换出去过因此可以从标号1继续执行)
-
restore_all //恢复现场
-
继续运行用户态进程Y
进程间的特殊情况
- 通过中断处理过程中的调度时机,用户态进程与内核线程之间互相切换和内核线程之间互相切换
- 与最一般的情况非常类似,只是内核线程运行过程中发生中断没有进程用户态和内核态的转换;
- 内核线程主动调用schedule(),只有进程上下文的切换,没有发生中断上下文的切换,与最一般``的情况略简略;
- 创建子进程的系统调用在子进程中的执行起点及返回用户态,如fork;
- 加载一个新的可执行程序后返回到用户态的情况,如execve;0-3G内核态和用户态都可以访问,3G以上只能内核态访问。内核是所有进程共享的。内核是各种中断处理过程和内核线程的集合。
三. 总结
这次实验主要做了如下的事情:
- 学习并完成实验环境的配置的搭建
- 学习并了解Linux内核中系统调用相关知识
- 学习了中断相关的知识
- 学习并实践了fork()与execve()系统调用的知识
- 思考代码执行的流程与原理

