
Spark1.6之后为何使用Netty通信框架替代Akka
解决方案:
一直以来,基于Akka实现的RPC通信框架是Spark引以为豪的主要特性,也是与Hadoop等分布式计算框架对比过程中一大亮点。
但是时代和技术都在演化,从Spark1.3.1版本开始,为了解决大块数据(如Shuffle)的传输问题,Spark引入了Netty通信框架,到了1.6.0版本,Netty居然完成取代了Akka,承担Spark内部所有的RPC通信以及数据流传输。
网络IO扫盲贴
在Linux操作系统层面,网络操作即为IO操作,总共有:阻塞式,非阻塞式,复用模型,信号驱动和异步五种IO模型。其中
- 阻塞式IO操作请求发起以后,从网卡等待/读取数据,内核/到用户态的拷贝,整个IO过程中,用户的线程都是处于阻塞状态。
- 非阻塞与阻塞的区别在于应用层不会等待网卡接收数据,即在内核数据未准备好之前,IO将返回EWOULDBLOCK,用户端通过主动轮询,直到内核态数据准备好,然后再主动发起内核态数据到用户态的拷贝读操作(阻塞)。
- 在非阻塞IO中,每个IO的应用层代码都需要主动地去内核态轮询直到数据OK,在IO复用模型中,将“轮询/事件驱动”的工作交给一个单独的select/epoll的IO句柄去做,即所谓的IO复用。
- 信号驱动IO是向内核注册信号回调函数,在数据OK的时候自动触发回调函数,进而可以在回调函数中启用数据的读取,即由内核告诉我们何时可以开始IO操作。
- 异步IO是将IO数据读取到用户态内存的函数注册到系统中,在内核数据OK的时候,自动完成内核态到用户态的拷贝,并通知应用态数据已经读取完成,即由内核告诉我们何时IO操作已经完成;
JAVA IO也经历来上面几次演化,从最早的BIO(阻塞式/非阻塞IO),到1.4版本的NIO(IO复用),到1.7版本的NIO2.0/AIO(异步IO);
基于早期BIO来实现高并发网络服务器都是依赖多线程来实现,但是线程开销较大,BIO的瓶颈明显,NIO的出现解决了这一大难题,基于IO复用解决了IO高并发;但是NIO有也有几个缺点:
- API可用性较低(拿ByteBuffer来说,共用一个curent指针,读写切换需要进行flip和rewind,相当麻烦);
- 仅仅是API,如果想在NIO上实现一个网络模型,还需要自己写很多比如线程池,解码,半包/粘包,限流等逻辑;
- 最后就是著名的NIO-Epoll死循环的BUG 因为这几个原因,促使了很多JAVA-IO通信框架的出现,Netty就是其中一员,它也因为高度的稳定性,功能性,性能等特性,成为Javaer们的首选。
那么Netty和JDK-NIO之间到底是什么关系?是JDK-NIO的封装还是重写?
首先是NIO的上层封装,Netty提供了NioEventLoopGroup/NioSocketChannel/NioServerSocketChannel的组合来完成实际IO操作,继而在此之上实现数据流Pipeline以及EventLoop线程池等功能。
另外它又重写了NIO,JDK-NIO底层是基于Epoll的LT模式来实现,而Netty是基于Epoll的ET模式实现的一组IO操作EpollEventLoopGroup/EpollSocketChannel/EpollServerSocketChannel;
Netty对两种实现进行完美的封装,可以根据业务的需求来选择不同的实现(Epoll的ET和LT模式真的有很大的性能差别吗?单从Epoll的角度来看,ET肯定是比LT要性能好那么一点。
但是如果为了编码简洁性,LT还是首选,ET如果用户层逻辑实现不够优美,相比ET还会带来更大大性能开销;不过Netty这么大的开源团队,相信ET模式应该实现的不错吧!!纯属猜测!!)。
那么Akka又是什么东西?
从Akka出现背景来说,它是基于Actor的RPC通信系统,它的核心概念也是Message,它是基于协程的,性能不容置疑;基于scala的偏函数,易用性也没有话说。
但是它毕竟只是RPC通信,无法适用大的package/stream的数据传输,这也是Spark早期引入Netty的原因。
注:
Akka is a concurrency framework built around the notion of actors and composable futures, Akka was inspired by Erlang which was built from the ground up around the Actor paradigm. It would usually be used to replace blocking locks such as synchronized, read write locks and the like with higher level asynchronous abstractions.
Akka是一个建立在Actors概念和可组合Futures之上的并发框架,,Akka设计灵感来源于Erlang,Erlang是基于Actor模型构建的。它通常被用来取代阻塞锁如同步、读写锁及类似的更高级别的异步抽象。
Netty is an asynchronous network library used to make Java NIO easier to use.
Netty是一个异步网络库,使JAVA NIO的功能更好用。
Notice that they both embrace asynchronous approaches, and that one could use the two together, or entirely separately.
注意:它们两个都提供了异步方法,你可以使用其中一个,或两个都用
Where there is an overlap is that Akka has an IO abstraction too, and Akka can be used to create computing clusters that pass messages between actors on different machines. From this point of view, Akka is a higher level abstraction that could (and does) make use of Netty under the hood
Akka针对IO操作有一个抽象,这和netty是一样的。使用Akka可以用来创建计算集群,Actor在不同的机器之间传递消息。从这个角度来看,Akka相对于Netty来说,是一个更高层次的抽象
那么Netty为什么可以取代Akka?首先不容置疑的是Akka可以做到的,Netty也可以做到,但是Netty可以做到,Akka却无法做到,原因是啥?
在软件栈中,Akka相比Netty要Higher一点,它专门针对RPC做了很多事情,而Netty相比更加基础一点,可以为不同的应用层通信协议(RPC,FTP,HTTP等)提供支持。
在早期的Akka版本,底层的NIO通信就是用的Netty;其次一个优雅的工程师是不会允许一个系统中容纳两套通信框架,恶心!
最后,虽然Netty没有Akka协程级的性能优势,但是Netty内部高效的Reactor线程模型,无锁化的串行设计,高效的序列化,零拷贝,内存池等特性也保证了Netty不会存在性能问题。
那么Spark是怎么用Netty来取代Akka呢?一句话,利用偏函数的特性,基于Netty“仿造”出一个简约版本的Actor模型!!
Spark Network Common的实现
Byte的表示
对于Network通信,不管传输的是序列化后的对象还是文件,在网络上表现的都是字节流。在传统IO中,字节流表示为Stream;在NIO中,字节流表示为ByteBuffer;在Netty中字节流表示为ByteBuff或FileRegion;在Spark中,针对Byte也做了一层包装,支持对Byte和文件流进行处理,即ManagedBuffer;
ManagedBuffer包含了三个函数createInputStream(),nioByteBuffer(),convertToNetty()来对Buffer进行“类型转换”,分别获取stream,ByteBuffer,ByteBuff或FileRegion;NioManagedBuffer/NettyManagedBuffer/FileSegmentManagedBuffer也是针对这ByteBuffer,ByteBuff或FileRegion提供了具体的实现。
更好的理解ManagedBuffer:比如Shuffle BlockManager模块需要在内存中维护本地executor生成的shuffle-map输出的文件引用,从而可以提供给shuffleFetch进行远程读取,此时文件表示为FileSegmentManagedBuffer,shuffleFetch远程调用FileSegmentManagedBuffer.nioByteBuffer/createInputStream函数从文件中读取为Bytes,并进行后面的网络传输。如果已经在内存中bytes就更好理解了,比如将一个字符数组表示为NettyManagedBuffer。
Protocol的表示
协议是应用层通信的基础,它提供了应用层通信的数据表示,以及编码和解码的能力。在Spark Network Common中,继承AKKA中的定义,将协议命名为Message,它继承Encodable,提供了encode的能力。
<ignore_js_op>
Message根据请求响应可以划分为RequestMessage和ResponseMessage两种;对于Response,根据处理结果,可以划分为Failure和Success两种类型;根据功能的不同,z主要划分为Stream,ChunkFetch,Rpc。
Stream消息就是上面提到的ManagedBuffer中的Stream流,在Spark内部,比如SparkContext.addFile操作会在Driver中针对每一个add进来的file/jar会分配唯一的StreamID(file/[]filename],jars/[filename]);worker通过该StreamID向Driver发起一个StreamRequest的请求,Driver将文件转换为FileSegmentManagedBuffer返回给Worker,这就是StreamMessage的用途之一;
ChunkFetch也有一个类似Stream的概念,ChunkFetch的对象是“一个内存中的Iterator[ManagedBuffer]”,即一组Buffer,每一个Buffer对应一个chunkIndex,整个Iterator[ManagedBuffer]由一个StreamID标识。Client每次的ChunkFetch请求是由(streamId,chunkIndex)组成的唯一的StreamChunkId,Server端根据StreamChunkId获取为一个Buffer并返回给Client; 不管是Stream还是ChunkFetch,在Server的内存中都需要管理一组由StreamID与资源之间映射,即StreamManager类,它提供了getChunk和openStream两个接口来分别响应ChunkFetch与Stream两种操作,并且针对Server的ChunkFetch提供一个registerStream接口来注册一组Buffer,比如可以将BlockManager中一组BlockID对应的Iterator[ManagedBuffer]注册到StreamManager,从而支持远程Block Fetch操作。
Case:对于ExternalShuffleService(一种单独shuffle服务进程,对其他计算节点提供本节点上面的所有shuffle map输出),它为远程Executor提供了一种OpenBlocks的RPC接口,即根据请求的appid,executorid,blockid(appid+executor对应本地一组目录,blockid拆封出)从本地磁盘中加载一组FileSegmentManagedBuffer到内存,并返回加载后的streamId返回给客户端,从而支持后续的ChunkFetch的操作。
RPC是第三种核心的Message,和Stream/ChunkFetch的Message不同,每次通信的Body是类型是确定的,在rpcHandler可以根据每种Body的类型进行相应的处理。 在Spark1.6.*版本中,也正式使用基于Netty的RPC框架来替代Akka。
Server的结构
Server构建在Netty之上,它提供两种模型NIO和Epoll,可以通过参数(spark.[module].io.mode)进行配置,最基础的module就是shuffle,不同的IOMode选型,对应了Netty底层不同的实现,Server的Init过程中,最重要的步骤就是根据不同的IOModel完成EventLoop和Pipeline的构造,如下所示:
//根据IO模型的不同,构造不同的EventLoop/ClientChannel/ServerChannel
EventLoopGroup createEventLoop(IOMode mode, int numThreads, String threadPrefix) { switch (mode) { case NIO: return new NioEventLoopGroup(numThreads, threadFactory); case EPOLL: return new EpollEventLoopGroup(numThreads, threadFactory); } } Class<? extends Channel> getClientChannelClass(IOMode mode) { switch (mode) { case NIO: return NioSocketChannel.class; case EPOLL: return EpollSocketChannel.class; } } Class<? extends ServerChannel> getServerChannelClass(IOMode mode) { switch (mode) { case NIO: return NioServerSocketChannel.class; case EPOLL: return EpollServerSocketChannel.class; } } //构造pipelet responseHandler = new TransportResponseHandler(channel); TransportClient client = new TransportClient(channel, responseHandler); requestHandler = new TransportRequestHandler(channel, client,rpcHandler); channelHandler = new TransportChannelHandler(client, responseHandler, requestHandler, conf.connectionTimeoutMs(), closeIdleConnections); channel.pipeline() .addLast("encoder", encoder) .addLast(TransportFrameDecoder.HANDLER_NAME, NettyUtils.createFrameDecoder()) .addLast("decoder", decoder) .addLast("idleStateHandler", new IdleStateHandler()) .addLast("handler", channelHandler);
其中,MessageEncoder/Decoder针对网络包到Message的编码和解码,而最为核心就TransportRequestHandler,它封装了对所有请求/响应的处理;TransportChannelHandler内部实现也很简单,它封装了responseHandler和requestHandler,当从Netty中读取一条Message以后,根据判断路由给相应的responseHandler和requestHandler。
public void channelRead0(ChannelHandlerContext ctx, Message request) throws Exception { if (request instanceof RequestMessage) { requestHandler.handle((RequestMessage) request); } else { responseHandler.handle((ResponseMessage) request); } }
Sever提供的RPC,ChunkFecth,Stream的功能都是依赖TransportRequestHandler来实现的;从原理上来说,RPC与ChunkFecth/Stream还是有很大不同的,其中RPC对于TransportRequestHandler来说是功能依赖,而ChunkFecth/Stream对于TransportRequestHandler来说只是数据依赖。
怎么理解?即TransportRequestHandler已经提供了ChunkFecth/Stream的实现,只需要在构造的时候,向TransportRequestHandler提供一个streamManager,告诉RequestHandler从哪里可以读取到Chunk或者Stream。
而RPC需要向TransportRequestHandler注册一个rpcHandler,针对每个RPC接口进行功能实现,同时RPC与ChunkFecth/Stream都会有同一个streamManager的依赖,因此注入到TransportRequestHandler中的streamManager也是依赖rpcHandler来实现,即rpcHandler中提供了RPC功能实现和streamManager的数据依赖。
//参考TransportRequestHandler的构造函数 public TransportRequestHandler(RpcHandler rpcHandler) { this.rpcHandler = rpcHandler;//****注入功能**** this.streamManager = rpcHandler.getStreamManager();//****注入streamManager**** } //实现ChunkFecth的功能 private void processFetchRequest(final ChunkFetchRequest req) { buf = streamManager.getChunk(req.streamId, req.chunkIndex); respond(new ChunkFetchSuccess(req.streamChunkId, buf)); } //实现Stream的功能 private void processStreamRequest(final StreamRequest req) { buf = streamManager.openStream(req.streamId); respond(new StreamResponse(req.streamId, buf.size(), buf)); } //实现RPC的功能 private void processRpcRequest(final RpcRequest req) { rpcHandler.receive(reverseClient, req.body().nioByteBuffer(), new RpcResponseCallback() { public void onSuccess(ByteBuffer response) { respond(new RpcResponse(req.requestId, new NioManagedBuffer(response))); } }); }
Client的结构
Server是通过监听一个端口,注入rpcHandler和streamManager从而对外提供RPC,ChunkFecth,Stream的服务,而Client即为一个客户端类,通过该类,可以将一个streamId/chunkIndex对应的ChunkFetch请求,streamId对应的Stream请求,以及一个RPC数据包对应的RPC请求发送到服务端,并监听和处理来自服务端的响应;其中最重要的两个类即为TransportClient和TransportResponseHandler分别为上述的“客户端类”和“监听和处理来自服务端的响应"。
那么TransportClient和TransportResponseHandler是怎么配合一起完成Client的工作呢?
<ignore_js_op>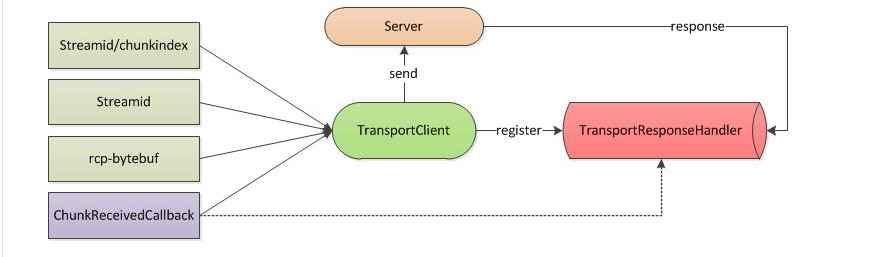
如上所示,由TransportClient将用户的RPC,ChunkFecth,Stream的请求进行打包并发送到Server端,同时将用户提供的回调函数注册到TransportResponseHandler,在上面一节中说过,TransportResponseHandler是TransportChannelHandler的一部分,在TransportChannelHandler接收到数据包,并判断为响应包以后,将包数据路由到TransportResponseHandler中,在TransportResponseHandler中通过注册的回调函数,将响应包的数据返回给客户端
//以TransportResponseHandler中处理ChunkFetchSuccess响应包的处理逻辑 public void handle(ResponseMessage message) throws Exception { String remoteAddress = NettyUtils.getRemoteAddress(channel); if (message instanceof ChunkFetchSuccess) { resp = (ChunkFetchSuccess) message; listener = outstandingFetches.get(resp.streamChunkId); if (listener == null) { //没有监听的回调函数 } else { outstandingFetches.remove(resp.streamChunkId); //回调函数,并把resp.body()对应的chunk数据返回给listener listener.onSuccess(resp.streamChunkId.chunkIndex, resp.body()); resp.body().release(); } } } //ChunkFetchFailure/RpcResponse/RpcFailure/StreamResponse/StreamFailure处理的方法是一致的
Spark Network的功能应用--BlockTransfer&&Shuffle
无论是BlockTransfer还是ShuffleFetch都需要跨executor的数据传输,在每一个executor里面都需要运行一个Server线程(后面也会分析到,对于Shuffle也可能是一个独立的ShuffleServer进程存在)来提供对Block数据的远程读写服务。
在每个Executor里面,都有一个BlockManager模块,它提供了对当前Executor所有的Block的“本地管理”,并对进程内其他模块暴露getBlockData(blockId: BlockId): ManagedBuffer的Block读取接口,但是这里GetBlockData仅仅是提供本地的管理功能,对于跨远程的Block传输,则由NettyBlockTransferService提供服务。
NettyBlockTransferService本身即是Server,为其他其他远程Executor提供Block的读取功能,同时它即为Client,为本地其他模块暴露fetchBlocks的接口,支持通过host/port拉取任何Executor上的一组的Blocks。
NettyBlockTransferService作为一个Server
NettyBlockTransferService作为一个Server,与Executor或Driver里面其他的服务一样,在进程启动时,由SparkEnv初始化构造并启动服务,在整个运行时的一部分。
val blockTransferService =
new NettyBlockTransferService(conf, securityManager, hostname, numUsableCores)
val envInstance = new SparkEnv(executorId,rpcEnv,serializer, closureSerializer,
blockTransferService,//为SparkEnv的一个组成
....,conf)
在上文,我们谈到,一个Server的构造依赖RpcHandler提供RPC的功能注入以及提供streamManager的数据注入。对于NettyBlockTransferService,该RpcHandler即为NettyBlockRpcServer,在构造的过程中,需要与本地的BlockManager进行管理,从而支持对外提供本地BlockMananger中管理的数据
"RpcHandler提供RPC的功能注入"在这里还是属于比较“简陋的”,毕竟他是属于数据传输模块,Server中提供的chunkFetch和stream已经足够满足他的功能需要,那现在问题就是怎么从streamManager中读取数据来提供给chunkFetch和stream进行使用呢?
就是NettyBlockRpcServer作为RpcHandler提供的一个Rpc接口之一:OpenBlocks,它接受由Client提供一个Blockids列表,Server根据该BlockIds从BlockManager获取到相应的数据并注册到streamManager中,同时返回一个StreamID,后续Client即可以使用该StreamID发起ChunkFetch的操作。
//case openBlocks: OpenBlocks => val blocks: Seq[ManagedBuffer] = openBlocks.blockIds.map(BlockId.apply).map(blockManager.getBlockData) val streamId = streamManager.registerStream(appId, blocks.iterator.asJava) responseContext.onSuccess(new StreamHandle(streamId, blocks.size).toByteBuffer)
NettyBlockTransferService作为一个Client
从NettyBlockTransferService作为一个Server,我们基本可以推测NettyBlockTransferService作为一个Client支持fetchBlocks的功能的基本方法:
- Client将一组Blockid表示为一个openMessage请求,发送到服务端,服务针对该组Blockid返回一个唯一的streamId
- Client针对该streamId发起size(blockids)个fetchChunk操作。
核心代码如下:
//发出openMessage请求 client.sendRpc(openMessage.toByteBuffer(), new RpcResponseCallback() { @Override public void onSuccess(ByteBuffer response) { streamHandle = (StreamHandle)response;//获取streamId //针对streamid发出一组fetchChunk for (int i = 0; i < streamHandle.numChunks; i++) { client.fetchChunk(streamHandle.streamId, i, chunkCallback); } } });
同时,为了提高服务端稳定性,针对fetchBlocks操作NettyBlockTransferService提供了非重试版本和重试版本的BlockFetcher,分别为OneForOneBlockFetcher和RetryingBlockFetcher,通过参数(spark.[module].io.maxRetries)进行配置,默认是重试3次,除非你蛋疼,你不重试!!!
在Spark,Block有各种类型,可以是ShuffleBlock,也可以是BroadcastBlock等等,对于ShuffleBlock的Fetch,除了由Executor内部的NettyBlockTransferService提供服务以外,也可以由外部的ShuffleService来充当Server的功能,并由专门的ExternalShuffleClient来与其进行交互,从而获取到相应Block数据。功能的原理和实现,基本一致,但是问题来了?为什么需要一个专门的ShuffleService服务呢?主要原因还是为了做到任务隔离,即减轻因为fetch带来对Executor的压力,让其专心的进行数据的计算。
其实外部的ShuffleService最终是来自Hadoop的AuxiliaryService概念,AuxiliaryService为计算节点NodeManager常驻的服务线程,早期的MapReduce是进程级别的调度,ShuffleMap完成shuffle文件的输出以后,即立即退出,在ShuffleReduce过程中由谁来提供文件的读取服务呢?即AuxiliaryService,每一个ShuffleMap都会将自己在本地的输出,注册到AuxiliaryService,由AuxiliaryService提供本地数据的清理以及外部读取的功能。
在目前Spark中,也提供了这样的一个AuxiliaryService:YarnShuffleService,但是对于Spark不是必须的,如果你考虑到需要“通过减轻因为fetch带来对Executor的压力”,那么就可以尝试尝试。
同时,如果启用了外部的ShuffleService,对于shuffleClient也不是使用上面的NettyBlockTransferService,而是专门的ExternalShuffleClient,功能逻辑基本一致!
Spark Network的功能应用--新的RPC框架
Akka的通信模型是基于Actor,一个Actor可以理解为一个Service服务对象,它可以针对相应的RPC请求进行处理,如下所示,定义了一个最为基本的Actor:
class HelloActor extends Actor { def receive = { case "hello" => println("world") case _ => println("huh?") } } // Receive = PartialFunction[Any, Unit]
Actor内部只有唯一一个变量(当然也可以理解为函数了),即Receive,它为一个偏函数,通过case语句可以针对Any信息可以进行相应的处理,这里Any消息在实际项目中就是消息包。
另外一个很重要的概念就是ActorSystem,它是一个Actor的容器,多个Actor可以通过name->Actor的注册到Actor中,在ActorSystem中可以根据请求不同将请求路由给相应的Actor。ActorSystem和一组Actor构成一个完整的Server端,此时客户端通过host:port与ActorSystem建立连接,通过指定name就可以相应的Actor进行通信,这里客户端就是ActorRef。所有Akka整个RPC通信系列是由Actor,ActorRef,ActorSystem组成。
Spark基于这个思想在上述的Network的基础上实现一套自己的RPC Actor模型,从而取代Akka。其中RpcEndpoint对于Actor,RpcEndpointRef对应ActorRef,RpcEnv即对应了ActorSystem。
下面我们具体进行分析它的实现原理。
private[spark] trait RpcEndpoint { def receive: PartialFunction[Any, Unit] = { case _ => throw new SparkException() } def receiveAndReply(context: RpcCallContext): PartialFunction[Any, Unit] = { case _ => context.sendFailure(new SparkException()) } //onStart(),onStop() }
RpcEndpoint与Actor一样,不同RPC Server可以根据业务需要指定相应receive/receiveAndReply的实现,在Spark内部现在有N多个这样的Actor,比如Executor就是一个Actor,它处理来自Driver的LaunchTask/KillTask等消息。
RpcEnv相对于ActorSystem:
- 首先它作为一个Server,它通过NettyRpcHandler来提供了Server的服务能力,
- 其次它作为RpcEndpoint的容器,它提供了setupEndpoint(name,endpoint)接口,从而实现将一个RpcEndpoint以一个Name对应关系注册到容器中,从而通过Server对外提供Service
- 最后它作为Client的适配器,它提供了setupEndpointRef/setupEndpointRefByURI接口,通过指定Server端的Host和PORT,并指定RpcEndpointName,从而获取一个与指定Endpoint通信的引用。
RpcEndpointRef即为与相应Endpoint通信的引用,它对外暴露了send/ask等接口,实现将一个Message发送到Endpoint中。
这就是新版本的RPC框架的基本功能,它的实现基本上与Akka无缝对接,业务的迁移的功能很小,目前基本上都全部迁移完了。
RpcEnv内部实现原理
RpcEnv不仅从外部接口与Akka基本一致,在内部的实现上,也基本差不多,都是按照MailBox的设计思路来实现的;
<ignore_js_op>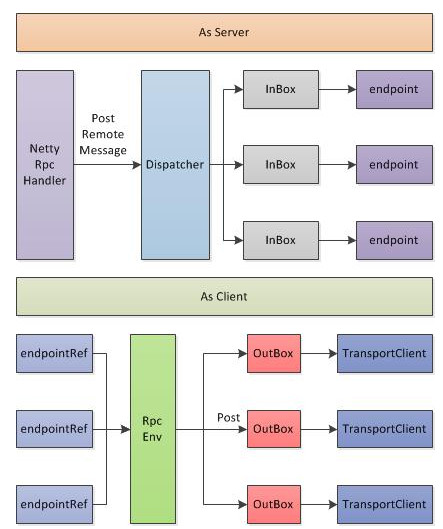
与上图所示,RpcEnv即充当着Server,同时也为Client内部实现。 当As Server,RpcEnv会初始化一个Server,并注册NettyRpcHandler,在前面描述过,RpcHandler的receive接口负责对每一个请求进行处理,一般情况下,简单业务可以在RpcHandler直接完成请求的处理,但是考虑一个RpcEnv的Server上会挂载了很多个RpcEndpoint,每个RpcEndpoint的RPC请求频率不可控,因此需要对一定的分发机制和队列来维护这些请求,其中Dispatcher为分发器,InBox即为请求队列;
在将RpcEndpoint注册到RpcEnv过程中,也间接的将RpcEnv注册到Dispatcher分发器中,Dispatcher针对每个RpcEndpoint维护一个InBox,在Dispatcher维持一个线程池(线程池大小默认为系统可用的核数,当然也可以通过spark.rpc.netty.dispatcher.numThreads进行配置),线程针对每个InBox里面的请求进行处理。当然实际的处理过程是由RpcEndpoint来完成。
这就是RpcEnv As Server的基本过程!
其次RpcEnv也完成Client的功能实现,RpcEndpointRef是以RpcEndpoint为单位,即如果一个进程需要和远程机器上N个RpcEndpoint服务进行通信,就对应N个RpcEndpointRef(后端的实际的网络连接是公用,这个是TransportClient内部提供了连接池来实现的),当调用一个RpcEndpointRef的ask/send等接口时候,会将把“消息内容+RpcEndpointRef+本地地址”一起打包为一个RequestMessage,交由RpcEnv进行发送。注意这里打包的消息里面包括RpcEndpointRef本身是很重要的,从而可以由Server端识别出这个消息对应的是哪一个RpcEndpoint。
和发送端一样,在RpcEnv中,针对每个remote端的host:port维护一个队列,即OutBox,RpcEnv的发送仅仅是把消息放入到相应的队列中,但是和发送端不一样的是:在OutBox中没有维护一个所谓的线程池来定时清理OutBox,而是通过一堆synchronized来实现的,这点值得商讨。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号