
Hadoop的mapreduce开发过程,我遇到的错误集锦(持续更新)
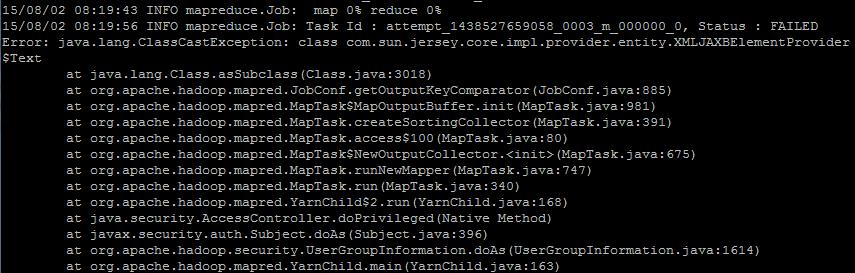
1.Text包导错了。
将import com.sun.jersey.core.impl.provider.entity.XMLJAXBElementProvider.Text;
改为import org.apache.hadoop.io.Text;
.
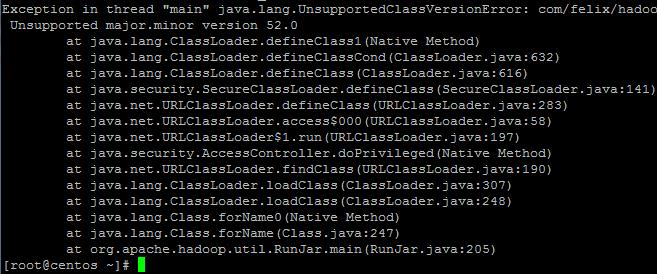
2.本地编译环境和生产环境中的java版本不匹配。有可能是jdk不匹配,也可能是jre不匹配。都匹配就不会有这个问题
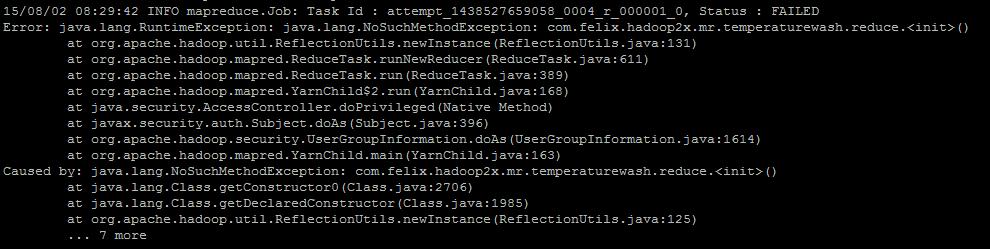
3.map与reduce都要是分别重载Mapper和Reducer类。不能是自己定义的方法
4.Job的写法问题:
第一种写法:Mapper、Reducer、JobRunner等自定义的类均写到单独的类文件中,如:
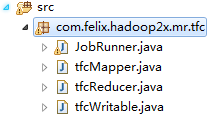
第一种写法:Mapper、Reducer、JobRunner等自定义的类均写到一个类文件中,那么
总结:不管哪种写法,在hadoop2.5.2中,其他的版本我没试,不知道,不过吴超老师在handoop1.1.2中写的代码好像没写这句,也执行成功了!
可能是1x与2x的区别吧。有空再测试一下
job.setJarByClass(你的组装、提交的类名字.class);是必不可少的
Configuration conf=new Configuration(); Job job=new Job(conf, JobRunner.class.getSimpleName());
job.setJarByClass(JobRunner.class);

5.自定义封装数据类型中,实现Writable接口或者WritableComparator接口时候。
实现序列化write()和反序列化readfields()方法中
封装数据中的属性的序列化和反序列化的前后顺序要相对应!如下:
@Override public void readFields(DataInput in) throws IOException { this.upPackNum=in.readLong(); this.downPackNum=in.readLong(); this.upPayLoad=in.readLong(); this.downPayLoad=in.readLong(); } @Override public void write(DataOutput out) throws IOException { out.writeLong(upPackNum); out.writeLong(downPackNum); out.writeLong(upPayLoad); out.writeLong(downPayLoad); }
欢迎关注微信公众号:大数据从业者

 浙公网安备 33010602011771号
浙公网安备 33010602011771号