
hadoop yarn application 资源本地化机制
一. 前言
在YARN中, 分布式缓存是一种分布式文件分发与缓存机制,主要作用是将用户应用程序执行时所需的外部文件资源自动透明地下
载并缓存到各个节点上, 从而省去了用户手动部署这些文件的麻烦。
二. 工作流程
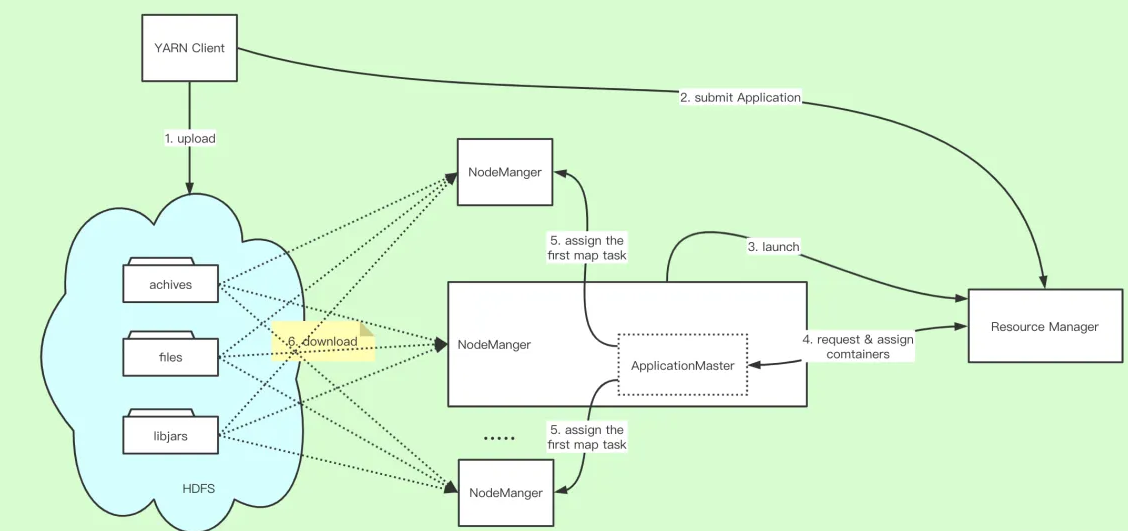
YARN分布式缓存工作流程具体如下:
步骤1 客户端将应用程序所需的文件资源(外部字典、 JAR包、 二进制文件等) 提交到HDFS上。
步骤2 客户端将应用程序提交到ResourceManager上。
步骤3 ResourceManager与某个NodeManager通信, 启动应用程序ApplicationMaster,NodeManager收到命令后, 首先从HDFS下载文件(缓存) , 然后启动ApplicationMaster。
步骤4 ApplicationMaster与ResourceManager通信, 以请求和获取计算资源。
步骤5 ApplicationMaster收到新分配的计算资源后, 与对应的NodeManager通信, 以启动任务。
步骤6 如果该应用程序第一次在该节点上启动任务, 则NodeManager首先从HDFS上下载文件缓存到本地, 然后启动任务。
步骤7 NodeManager后续收到启动任务请求后, 如果文件已在本地缓存, 则直接运行任务, 否则等待文件缓存完成后再启动。
各节点上的缓存文件由对应的NodeManager管理和维护。 NodeManager采用了一定的缓存置换算法定期清理失效文件 .
在Hadoop中, 分布式缓存并不是将文件缓存到集群中各个节点的内存中, 而是将文件缓存到各节点的本地磁盘上, 以便执行任务时直接从本地磁盘上读取文件.
三.资源可见性与分类
分布式缓存机制是由各个NodeManager实现的, 主要功能是将应用程序需要的文件资源(一般是只读的) 缓存到本地, 以方便后续任务运行。 资源缓存是用时触发的, 也就是说, 由第一个用到该资源的任务触发的, 后续同类任务无须再次进行缓存, 直接使用已经缓存好的即可
按照可见性(LocalResourceVisibility) ,NodeManager将资源分为三类:
❑ PUBLIC: 节点上所有用户共享该资源, 只要有一个用户的应用程将这些资源缓存到本地, 其他所有用户的所有应用程序均可使用它们。
❑ PRIVATE: 节点上同一用户的所有应用程序共享该资源, 一旦该用户的第一个应用程序将之缓存到本地, 该用户后续所有的应用程序均可共享该资源。
❑ APPLICATION: 节点上同一应用程序的所有Container共享, 其他用户或者通用户的其他程序不可使用该资源。 默认情况下, MapReduce作业的split元信息文件job.splitmetainfo和属性文件job.xml的可见性是APPLICATION。
**按照资源类型(LocalResourceType) , NodeManager将资源分为三类: **
❑ ARCHIVE: 归档文件, 当前支持后缀为".jar"、 “.zip”、 “.tar.gz”、 “.tgz"和”.tar"的5种归档文件, NodeManager能自动在工作目录中对这5类归档文件进行解压缩(如果是后缀为".jar"的文件, 还可自动将其加到CLASSPATH中) , 方便用户程序使用。
❑ FILE: 普通文件, NodeManager只是简单地将这类文件下载到工作目录中, 不做任何处理。
❑ PATTERN: 以上两种类型的混合体, 有多种类型文件存在, 而用户可通过一个正则表达式指定哪些属于ARCHIVE文件, 需要自动解压缩
YARN是通过比较resource、 timestamp、 type和pattern四个字段是否相同来判断两个资源请求是否相同的。 如果一个已经被缓存到各个节点上的文件被用户修改了, 则下次使用时会自动触发一次缓存更新, 以重新从HDFS上下载该文件。
message LocalResourceProto {
optional URLProto resource = 1; //通常是存在HDFS上的文件的路径
optional int64 size = 2; //文件大小
optional int64 timestamp = 3; //最后修改时间
optional LocalResourceTypeProto type = 4; //资源类型
optional LocalResourceVisibilityProto visibility = 5; //资源可见性
optional string pattern = 6; //正则表达式, 当资源可见性为PATTERN时有用
optional bool should_be_uploaded_to_shared_cache = 7;
}
YARN MapReduce是采用目录权限方式判断资源可见性的, 如果一个HDFS文件的父目录的用户执行权限、 组执行权限和其他组执行权限都是打开的(比如可以为"drwxr-xr-x") , 则认为它具有PUBLIC可见性, 否则是PRIVATE可见性。 换句话说,如果你想将一个文件可见性设置为PUBLIC, 必须在运行MapReduce应用程序之前将它上传到HDFS上, 并修改它在所目录的权限。 需要注意的是, 每次运行时临时由客户端自动从本地上传到HDFS上的文件默认全部是PRVIATE权限。
//添加归档文件 void addCacheArchive(URI uri, Configuration conf) void setCacheArchives(URI[] archives, Configuration conf) //添加普通文件 void addCacheFile(URI uri, Configuration conf) void setCacheFiles(URI[] files, Configuration conf) //将三方JAR包或者动态库添加到classpath中 void addFileToClassPath(Path file, Configuration conf) //在任务工作目录下建立文件软连接 void createSymlink(Configuration conf)
ARN MapReduce客户端从Configuration中解析出各个属性之后(比如mapred.cache.files、 mapred.cache.archives、 mapred.job.classpath.files、mapred.create.symlink等) , 需将之转换成Protocol Buffers对象的定义方式 (YARN MapReduce客户端将作业配置文件job.xml、 split文件可见性设置为 APPLICATION)
/**
* 创建 Application Resource 资源文件
* @param fs
* @param p
* @param fileSymlink
* @param type
* @param viz
* @param uploadToSharedCache
* @return
* @throws IOException
*/
private LocalResource createApplicationResource(FileContext fs, Path p,
String fileSymlink, LocalResourceType type, LocalResourceVisibility viz,
Boolean uploadToSharedCache) throws IOException {
//
// 文件缓存限定
// 获取本地文件
LocalResource rsrc = recordFactory.newRecordInstance(LocalResource.class);
// 获取资源文件的状态
FileStatus rsrcStat = fs.getFileStatus(p);
// We need to be careful when converting from path to URL to add a fragment
// so that the symlink name when localized will be correct.
// 限定路径
Path qualifiedPath = fs.getDefaultFileSystem().resolvePath(rsrcStat.getPath());
URI uriWithFragment = null;
boolean useFragment = fileSymlink != null && !fileSymlink.equals("");
try {
if (useFragment) {
uriWithFragment = new URI(qualifiedPath.toUri() + "#" + fileSymlink);
} else {
uriWithFragment = qualifiedPath.toUri();
}
} catch (URISyntaxException e) {
throw new IOException(
"Error parsing local resource path."
+ " Path was not able to be converted to a URI: " + qualifiedPath,
e);
}
// 设置资源文件
rsrc.setResource(URL.fromURI(uriWithFragment));
// 设置资源文件 大小
rsrc.setSize(rsrcStat.getLen());
// 设置资源文件 时间戳
rsrc.setTimestamp(rsrcStat.getModificationTime());
// 设置资源文件 类型
rsrc.setType(type);
// 设置资源文件 可见性
rsrc.setVisibility(viz);
// // 设置资源文件 缓存
rsrc.setShouldBeUploadedToSharedCache(uploadToSharedCache);
return rsrc;
}
四.分布式缓存实现
按可见性YARN将资源分为3类, 分别是PUBLIC、 PRIVATE和APPLICATION, 不同可见性的资源开放给用户的权限不同, 这是通过设置特殊的目录位置和目录权限实现的NodeManager采用轮询分配策略将这三类资源存放在yarn.nodemanager.local-dirs指定的目录列表中, 在每个目录中, 资源将按照以下方式存放:
❑ PUBLIC资源:存放在${yarn.nodemanager.local-dirs}/filecache/目录下, 每个资源将单独存放在以一个随机整数命名的目录中, 且目录的访问权限均为755 (rwxr-xr-x)。
❑ PRIVATE资源: 存放在${yarn.nodemanager.local-dirs}/usercache/${user}/filecache/目录下(其中, ${user}是应用程序提交者, 默认情况下, 均为NodeManager启动者) , 每个资源将单独存放在以一个随机整数命名的目录中,
且目录的访问权限均为710 (rwx–x—)。
❑ APPLICATION资源: 存放在${yarn.nodemanager.localdirs}/usercache/${user}/${appcache}/${appid}/filecache/目录下(其中,${appid}是应用程序ID) , 每个资源将单独存放在以一个随机整数命名的目录中, 且目录的访问权限均为710 (rwx–x—);
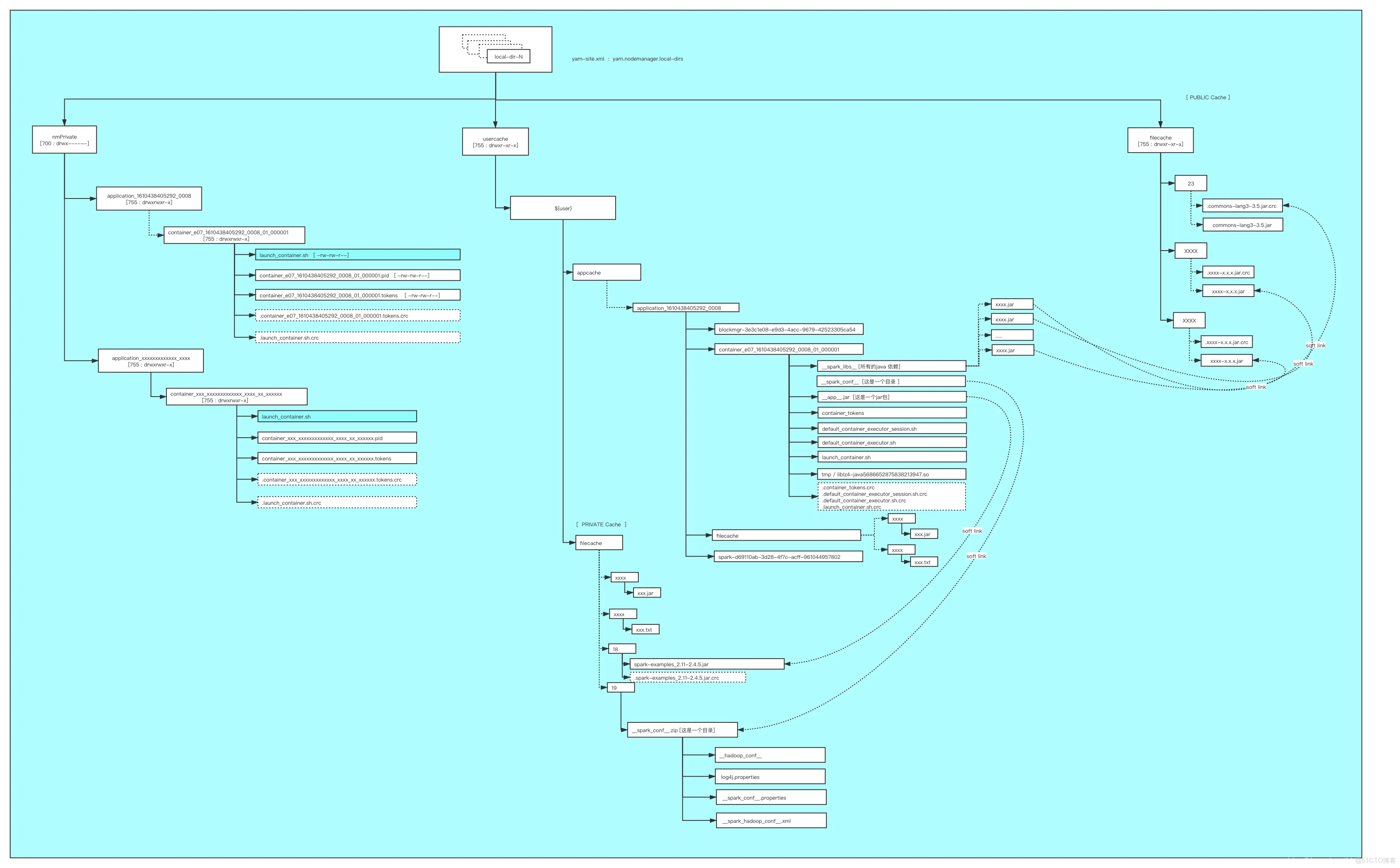
Container的工作目录位于${yarn.nodemanager.localdirs}/usercache/${user}/${appcache}/${appid}/${containerid}目录下(其中, ${containerid }是Container ID) , 它运行所需的外部资源, 比如JAR包、 字典文件等, 处于各个filecache
目录中, 为了避免文件复制带来性能影响, 它会建立一个到这些文件的软连接。
不同可见性资源的缓存机制实现不同:
对于PUBLIC资源, 由公共服务ResourceLocalizationService中的一个公用线程PublicLocalizer下载, 它内部维护了一个线程池并行下载资源; 对于PRIVATE和APPLICATION资源, 则由公共服务ResourceLocalizationService中一个专门线程LocalizerRunner(一个Container对应一个LocalizerRunner线程) 下载, 同一个Container的所有资源是串行下载的 。
考虑到PRIVATE和APPLICATION资源通常是用户或者应用程序私有的, 不允许其他用户看到,因此对应的目录需有严格的权限设置, 这是由ContainerExecutor组件设置的(目前有DefaultContainerExecutor和LinuxContainerExecutor两种实现) 。
ResourceLocalizationService内部启动了一个(实现了LocalizationProtocol协议的) RPC服务器, 而ContainerExecutor则启动了一个资源下载客户端ContainerLocalizer, 它不断地从服务端获取待下载资源信息(ResourceLocalizationService维护了各种待下载资源列表) , 然后下载到被设置了特定权限的目录中
分布式缓存完成的主要功能是文件下载, 涉及大量的磁盘读写, 因此整个过程采用了异步并发模型以加快文件下载速度, 同时避免同步模型带来的性能开销。
为了避免缓存的文件过多导致磁盘“撑爆”, NodeManager会定期清理过期的缓存文件, 具体方法如下: 每隔一定时间yarn.nodemanager.localizer.cache.cleanup.interval-ms(单位是毫秒, 默认值是10×60×1000, 即10分钟) 启动一次清理工作, 确保每个缓存目录中文件容量小于yarn.nodemanager.localizer.cache.target-size-mb(单位是MB, 默认是10240,即10GB) , 如果超过该值, 则采用LRU(Least Recently Used) 算法清除已不再使用的缓存文件, 直至文件容量低于设定值。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号