
Open Sourcing Kafka Cruise Control Automating Kafka’s Operation at Scale
Apache Kafka's popularity has grown tremendously over the past few years. In fact, LinkedIn's deployment recently surpassed 2 trillion messages per day, with over 1,800 Kafka servers (i.e., brokers). While Kafka has proven to be very stable, there are still operational challenges when running Kafka at such a scale. Brokers fail on a daily basis, which results in unbalanced workloads on our clusters. As a result, SREs expend significant time and effort to reassign partitions in order to restore balance to Kafka clusters.
Intelligent automation is critical under these circumstances, which is why we developed Cruise Control: a general-purpose system that continually monitors our clusters and automatically adjusts the resources allocated to them to meet pre-defined performance goals. In essence, users specify goals, Cruise Control monitors for violations of these goals, analyzes the existing workload on the cluster, and automatically executes administrative operations to satisfy those goals. You can see a video here about Cruise Control at the Stream Processing Meet Up last fall.
Today we are pleased to announce that we have open sourced Cruise Control and it is now available on Github. In this post, we’ll describe Cruise Control’s uses both generally and at LinkedIn, its architecture, and some unique challenges we faced when creating it. For further details about Kafka terminology used throughout this post, this reference can be a helpful guide.
Design goals
There are a few important requirements that we had in mind when we designed Cruise Control:
-
Reliable automation: Cruise Control should be capable of accurately analyzing cluster workloads and generating execution plans that can be trusted to run without any human intervention.
-
Resource-efficient: Cruise Control should be intelligent enough to execute actions in a manner that does not adversely impact the availability of the cluster to handle normal workloads.
-
Extensibility: Kafka users will have different requirements for the availability and performance of their Kafka deployments, and will use various deployment tools, administrative endpoints, and metrics-collection mechanisms. Cruise Control must be able to satisfy arbitrary user-defined goals and execute user-defined actions.
-
Generality: We realized early on that other distributed systems can also benefit from similar operational automation that requires such application-aware monitor-analysis-action cycles. While there are existing products that help balance resource utilization in a cluster, most of them are application-agnostic and perform the rebalance by migrating the entire application process. While this works well for stateless systems, it usually falls short when it comes to stateful systems (e.g., Kafka) due to the large amount of state associated with the process. Therefore, we wanted Cruise Control to be a general framework that could understand the application and migrate only a partial state and be used in any stateful distributed system.
Cruise Control at LinkedIn
Our current deployment of Cruise Control for Kafka aims to address the following key operational and reporting goals:
-
Kafka clusters must be continually balanced with respect to disk, network, and CPU utilization.
-
When a broker fails, we need to automatically reassign replicas that were on that broker to other brokers in the cluster and restore the original replication factor.
-
We need to be able to identify the topic-partitions that consume the most resources in the cluster.
-
We need to support low-touch cluster expansions and broker de-commissions. These operations are otherwise arduous, due to the need to manually reassign partitions after adding or removing a broker from a cluster.
-
It is useful to be able to run clusters with heterogeneous hardware (e.g., to quickly remediate hardware failures when there is a shortage of identical hardware). However, heterogeneity compounds operational overhead, since SREs need to be minutely aware of hardware differences when balancing such clusters. Cruise Control should be able to support heterogeneous Kafka clusters and multiple brokers per machine.
How does it work?
Cruise Control follows a monitor-analysis-action working cycle. The following diagram illustrates the architecture of Cruise Control. A number of its components are pluggable, as the diagram highlights (e.g., metric sampler, analyzer, etc.).
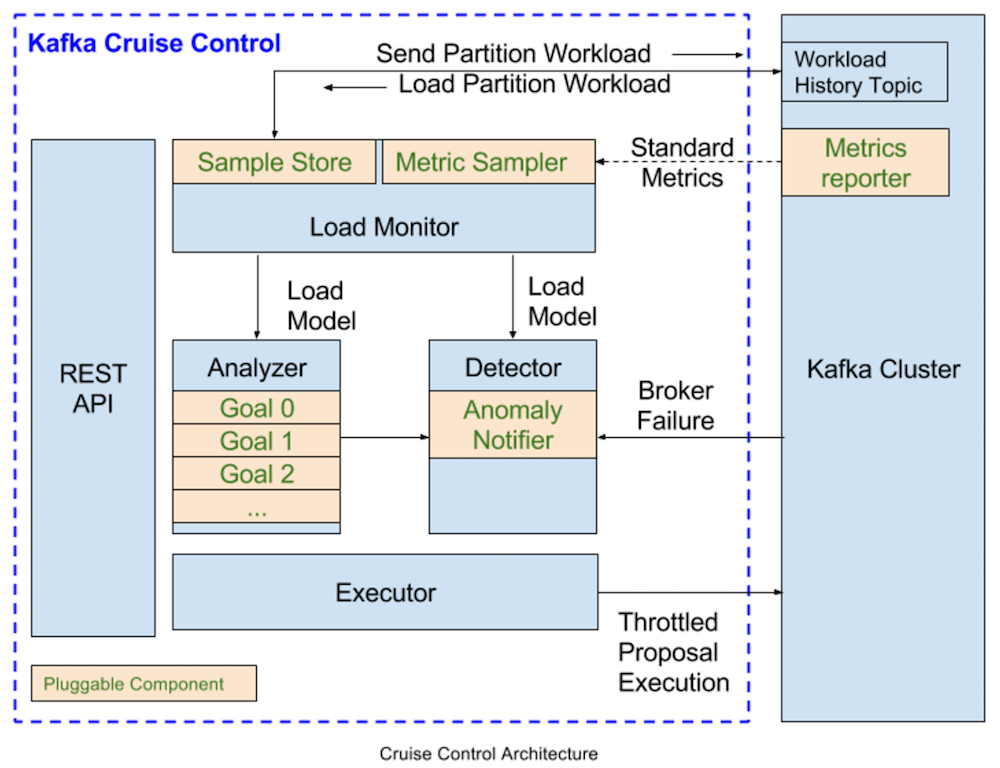
REST API
Cruise Control provides a REST API to allow users to interact with it. The REST API supports querying the workload and optimization proposals of the Kafka cluster, as well as triggering admin operations.
Load Monitor
The Load Monitor collects standard Kafka metrics from the cluster and derives per partition resource metrics that are not directly available (e.g., it estimates CPU utilization on a per-partition basis). It then generates a cluster workload model that accurately captures cluster resource utilization, which includes disk utilization, CPU utilization, bytes-in rate, and bytes-out rate, at replica-granularity. It then feeds the cluster model into the detector and analyzer.
Analyzer
The Analyzer is the "brain" of Cruise Control. It uses a heuristic method to generate optimization proposals based on the user-provided optimization goals and the cluster workload model from the Load Monitor.
The optimization goals have priorities based on the user configuration. A higher priority goal is more likely to be met than a low-priority goal. The optimization of a low-priority goal cannot cause violation of the high priority goals.
Cruise Control also allows for specifying hard goals and soft goals. A hard goal is one that must be satisfied (e.g., replica placement must be rack-aware). Soft goals, on the other hand, may be left unmet if doing so makes it possible to satisfy all the hard goals. The optimization would fail if the optimized results violate a hard goal. Usually, the hard goals will have a higher priority than the soft goals. We have implemented the following hard and soft goals so far:
Hard Goals
-
Replica placement must be rack-aware. The replicas of the same partition are put on different racks so that when a rack is down, there will be at most one replica lost for any partition. This helps control the failure boundary and makes Kafka more robust.
-
Broker resource utilization must be within pre-defined thresholds.
-
Network utilization must not be allowed to go beyond a pre-defined capacity, even when all replicas on the broker become leaders. In this case, all the consumer traffic will be redirected to that broker, which will result in higher network utilization than usual.
Soft Goals
-
Attempt to achieve uniform resource utilization across all brokers.
-
Attempt to achieve uniform bytes-in rate of leader partitions (i.e. the bytes-in rate from the clients instead of replication) across brokers.
-
Attempt to evenly distribute partitions of a specific topic across all brokers.
-
Attempt to evenly distribute replicas (globally) across all brokers.
At a high level, the goal optimization logic is as follows:
Anomaly detector
The anomaly detector identifies two types of anomalies:
-
Broker failures: i.e., a non-empty broker leaves a cluster, which results in under-replicated partitions. Since this can happen during normal cluster bounces as well, the anomaly detector provides a configurable grace period before it triggers the notifier and fixes the cluster.
-
Goal violations: i.e., an optimization goal is violated. If self-healing is enabled, Cruise Control will proactively attempt to address the goal violation by automatically analyzing the workload, and executing optimization proposals.
Executor
The executor is responsible for carrying out the optimization proposals from the analyzer. Rebalancing a Kafka cluster usually involves partition reassignment. The executor ensures that the execution is resource-aware and does not overwhelm any broker. The partition reassignment could also be a long-running process—it may take days to finish in a large Kafka cluster. Sometimes, users may want to stop the ongoing partition reassignment. The executor is designed in a way that it is safe to interrupt when executing the proposals.
Interesting challenges
We’ve encountered many interesting challenges while developing and using Cruise Control. A few of these are listed below.
Building a reliable cluster workload model for Kafka
This is not as simple as it sounds. There are quite a few nuances to be aware of. For example, it is straightforward to collect CPU utilization metrics from brokers, but how do we quantify the impact of each partition on CPU utilization? This wiki page explains our efforts to answer this question.
How long are you willing to wait for an optimization proposal?
The analyzer component has come a long way. We initially used a general-purpose optimizer with a complicated parameterized loss function. It would take weeks (if not years) to get the optimization proposals on a medium-size Kafka cluster. We then switched to the current heuristic optimizer solution, which gives us a reasonably good result in a few minutes.
Memory or speed?
Cruise Control is very memory-intensive due to the quantity of metrics that we have to keep for a period (e.g. a week) in order to profile the traffic pattern of the partitions in the Kafka cluster. It is also a CPU-intensive application because of the involved computation that is necessary to generate optimization proposals. Those two things are sort of conflicting with each other, however. To accelerate proposal generation, we would want to do more caching and parallel proposal computation, but doing that uses more memory. We ultimately made some design decisions to strike a balance between these two. For example, we pre-compute the optimization proposals and cache them to avoid long waiting times when user queries arrive. On the other hand, we also stagger the execution of the memory-heavy tasks (e.g., proposal precomputing, anomaly detection, etc.) to avoid simultaneous high-memory consumption.
Future work
More Kafka cluster optimization goals!
Since the optimization goals of Cruise Control are pluggable, users may come up with sophisticated and nuanced goals to optimize their own Kafka clusters as needed. For example, we use Kafka Monitor at LinkedIn to monitor our cluster availability. Since Kafka Monitor reports availability for each broker based on its ability to send messages to a "monitor" topic, we need to ensure that the leaders of this topic's partitions have coverage across all brokers. As an open source project, we would also like to encourage users to create their own goals and contribute them to the community.
Integration with Cloud Management Systems (CMS)
Currently, Cruise Control heals a cluster by moving partitions off dead brokers. We envision that Cruise Control could integrate with other CMS to automatically expand clusters when their utilization reaches a certain threshold, or to replace a dead broker with a new one from a spare pool if necessary. As noted above, we welcome community input and contributions to this future functionality.
Empower operations with insights
Cruise Control facilitates deep analysis on metrics collected from Kafka. We believe it will equip SREs with the ability to quantify the impact of various resource usage metrics and derive insights that will aid in capacity planning and performance tuning.
Generalization
We developed Cruise Control with the realization that a dynamic load balancer is a useful facility for any distributed system. Cruise Control's components for metric aggregation, resource utilization analysis, and the generation of optimization proposals are equally applicable to other distributed systems as well. We want to abstract those core components in the long term and make them available to other projects as well. Our vision for Cruise Control is to build it in a manner that allows for straightforward integration with any distributed system to facilitate application-specific performance analysis, optimization, and execution.
Acknowledgements
Cruise Control began as an intern project by Efe Gencer. Many members on the Kafka development team have participated in brainstorming, design, and reviews. Cruise Control has also received many valuable contributions and insights from the Kafka SRE team at LinkedIn.
Editor's Note: If you are interested in following some of the cool work we are doing in Stream Processing, both at LinkedIn and in our extended open source communities, you can register for our quarterly meetups where we invite speakers to talk about the latest improvements in Apache Kafka and Apache Samza.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号