
用sqoop将mysql的数据导入到hive表中
1:先将mysql一张表的数据用sqoop导入到hdfs中
准备一张表

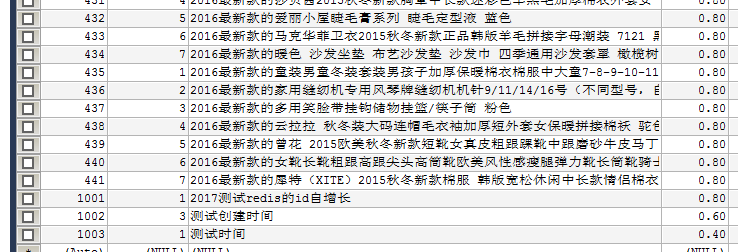
需求 将 bbs_product 表中的前100条数据导 导出来 只要id brand_id和 name 这3个字段
数据存在 hdfs 目录 /user/xuyou/sqoop/imp_bbs_product_sannpy_ 下

bin/sqoop import \ --connect jdbc:mysql://172.16.71.27:3306/babasport \ --username root \ --password root \ --query 'select id, brand_id,name from bbs_product where $CONDITIONS LIMIT 100' \ --target-dir /user/xuyou/sqoop/imp_bbs_product_sannpy_ \ --delete-target-dir \ --num-mappers 1 \ --compress \ --compression-codec org.apache.hadoop.io.compress.SnappyCodec \ --fields-terminated-by '\t'
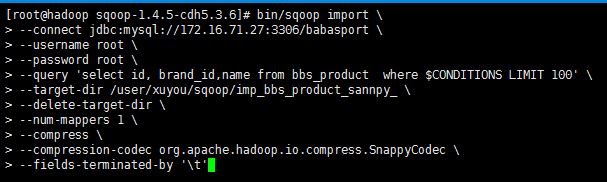
ps: 如果导出的数据库是mysql 则可以添加一个 属性 --direct
1 bin/sqoop import \ 2 --connect jdbc:mysql://172.16.71.27:3306/babasport \ 3 --username root \ 4 --password root \ 5 --query 'select id, brand_id,name from bbs_product where $CONDITIONS LIMIT 100' \ 6 --target-dir /user/xuyou/sqoop/imp_bbs_product_sannpy_ \ 7 --delete-target-dir \ 8 --num-mappers 1 \ 9 --compress \ 10 --compression-codec org.apache.hadoop.io.compress.SnappyCodec \ 11 --direct \ 12 --fields-terminated-by '\t'
加了 direct 属性在导出mysql数据库表中的数据会快一点 执行的是mysq自带的导出功能
第一次执行所需要的时间

第二次执行所需要的时间 (加了direct属性)

执行成功

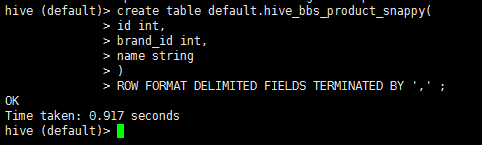
2:启动hive 在hive中创建一张表
1 drop table if exists default.hive_bbs_product_snappy ; 2 create table default.hive_bbs_product_snappy( 3 id int, 4 brand_id int, 5 name string 6 ) 7 ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' ;
3:将hdfs中的数据导入到hive中
1 load data inpath '/user/xuyou/sqoop/imp_bbs_product_sannpy_' into table default.hive_bbs_product_snappy ;

4:查询 hive_bbs_product_snappy 表
1 select * from hive_bbs_product_snappy;

此时hdfs 中原数据没有了

然后进入hive的hdfs存储位置发现

注意 :sqoop 提供了 直接将mysql数据 导入 hive的 功能 底层 步骤就是以上步骤
创建一个文件 touch test.sql 编辑文件 vi test.sql
1 use default; 2 drop table if exists default.hive_bbs_product_snappy ; 3 create table default.hive_bbs_product_snappy( 4 id int, 5 brand_id int, 6 name string 7 ) 8 ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' ;
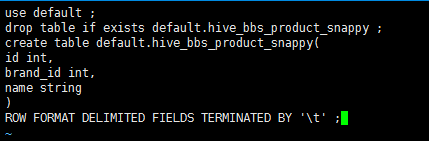
在 启动hive的时候 执行 sql脚本
bin/hive -f /opt/cdh-5.3.6/sqoop-1.4.5-cdh5.3.6/test.sql


执行sqoop直接导入hive的功能
1 bin/sqoop import \ 2 --connect jdbc:mysql://172.16.71.27:3306/babasport \ 3 --username root \ 4 --password root \ 5 --table bbs_product \ 6 --fields-terminated-by '\t' \ 7 --delete-target-dir \ 8 --num-mappers 1 \ 9 --hive-import \ 10 --hive-database default \ 11 --hive-table hive_bbs_product_snappy
看日志输出可以看出 在执行map任务之后 又执行了load data

查询 hive 数据

欢迎关注微信公众号:大数据从业者

 浙公网安备 33010602011771号
浙公网安备 33010602011771号