爬虫(十八):scrapy分布式部署
scrapy部署神器-scrapyd --》GitHub地址 --》官方文档
一:安装scrapyd
安装:pip3 install scrapyd
这里我在另外一台ubuntu linux虚拟机中同样安装scrapy以及scrapyd等包,保证所要运行的爬虫需要的包都完成安装.
在这里有个小问题需要注意,默认scrapyd启动是通过scrapyd就可以直接启动,这里bind绑定的ip地址是127.0.0.1端口是:6800,这里为了其他虚拟机访问讲ip地址设置为0.0.0.0
修改scrapyd的配置文件:sudo vim /usr/local/lib/python3.5/dist-packages/scrapyd/default_scrapyd.conf

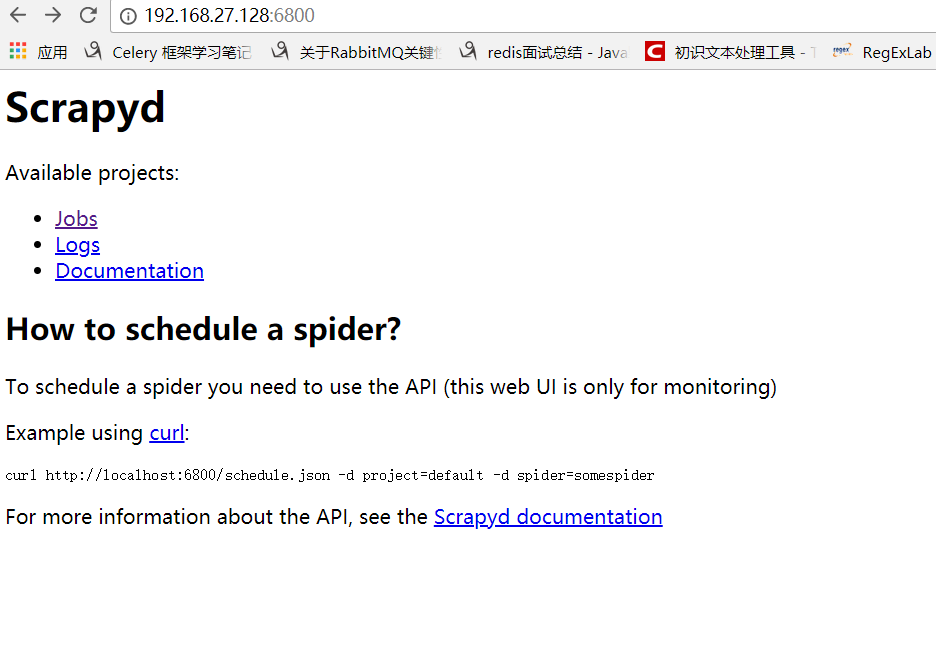
这样配置好之后就可以在windows下访问了
二:关于部署
通过scrapyd-client进行部署操作:--》官方文档
这里的scrapyd-client主要实现以下内容:
- 把我们本地代码打包生成egg文件
- 根据我们配置的url上传到远程服务器上
我们将我们本地的scrapy项目中scrapy.cfg配置文件进行配置:
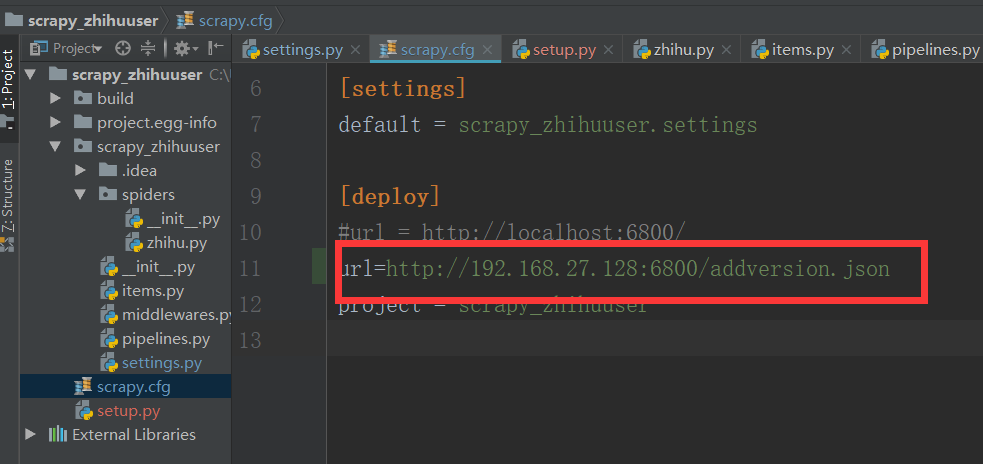
我们其实还可以设置用户名和密码,不过这里没什么必要,只设置了url
这里设置url一定要注意:url = http://192.168.27.128:6800/addversion.json
最后的addversion.json不能少
我们在本地安装pip3 install scrapyd_client,安装完成后执行:scrapyd-deploy(我是在git下执行的) 先从github下载项目
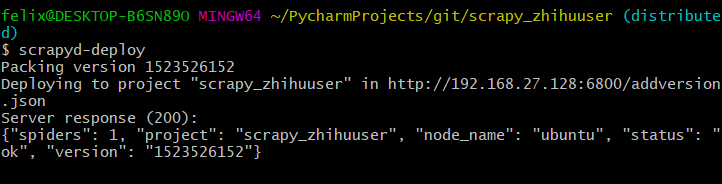
看到status:200表示已经成功看到status:200表示已经成功
三:常用API
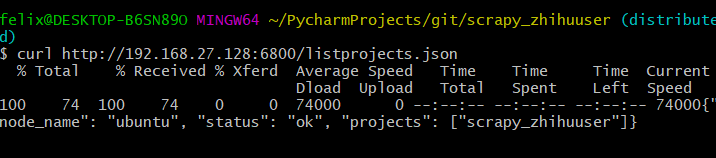
listprojects.json列出上传的项目列表
listversions.json列出有某个上传项目的版本

schedule.json远程任务的启动
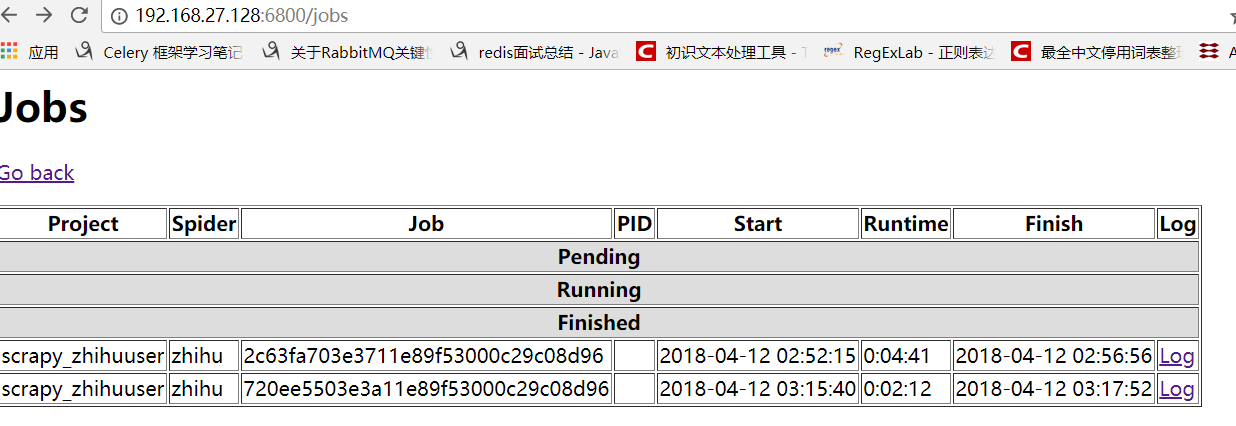
下面我们启动的三次就表示我们启动了三个任务,也就是三个调度任务来运行zhihu这个爬虫
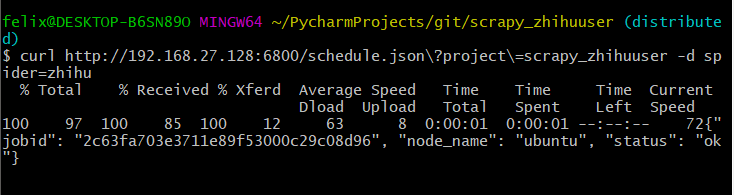
启动后就可以在界面中看到启动的任务了:

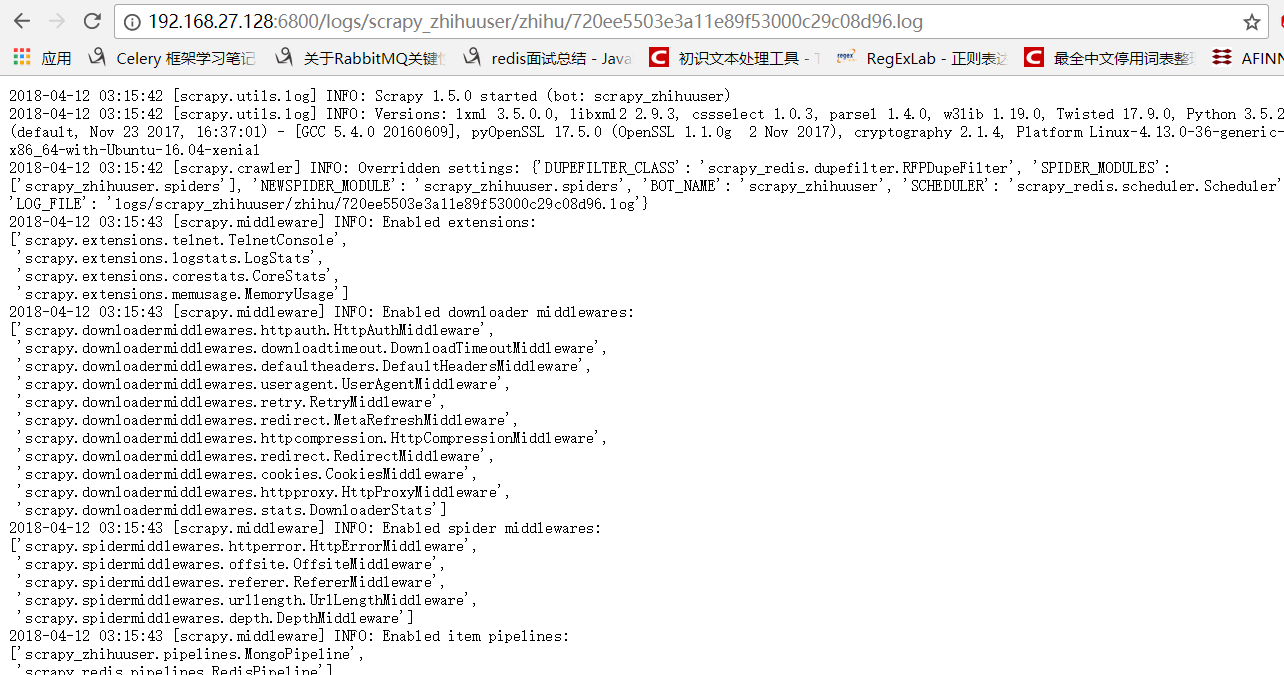
也可以看到日志:
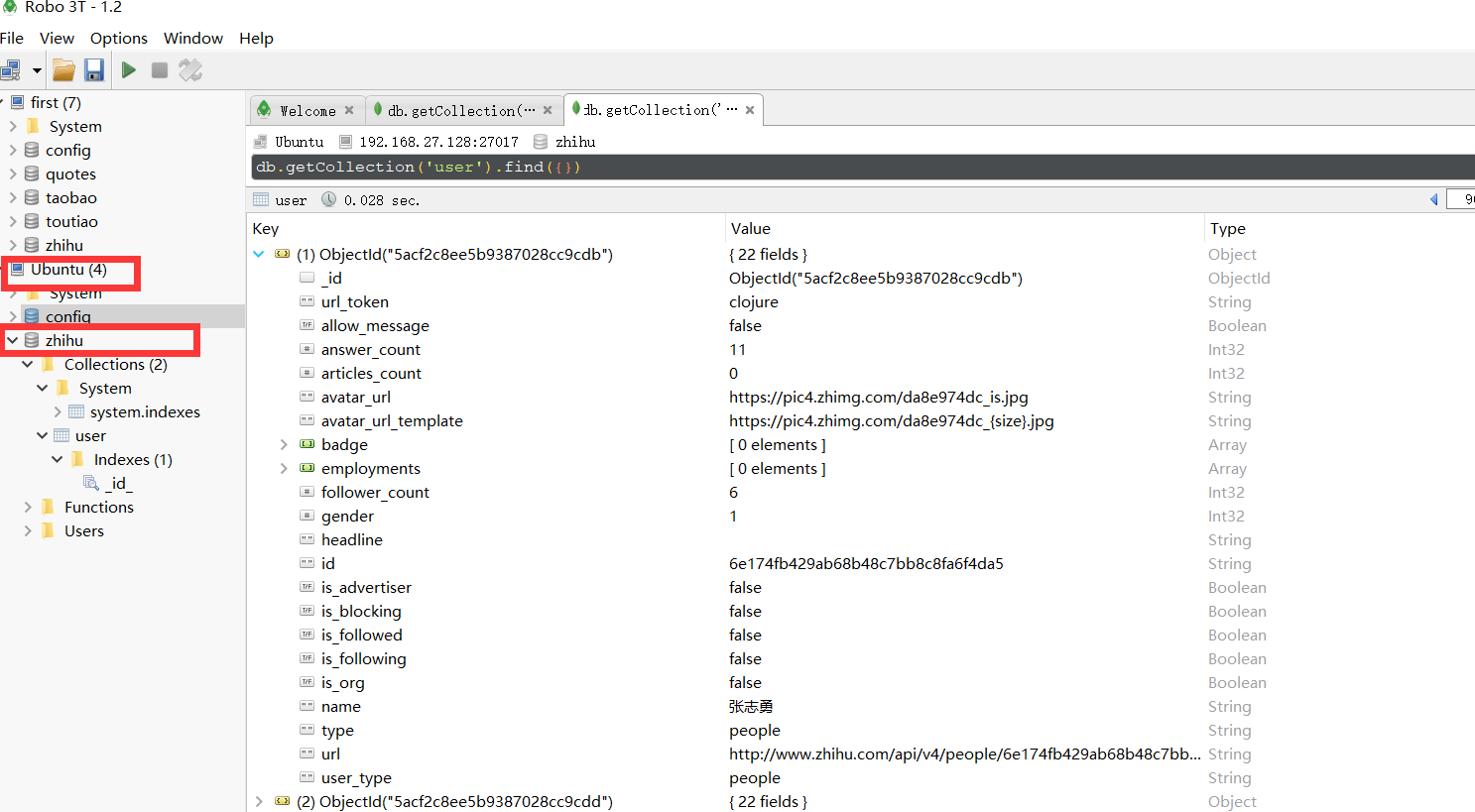
MongoDB中存入了刚才爬取的数据。
listjobs.json列出所有的jobs任务
上面是通过页面显示所有的任务,这里是通过命令获取结果

cancel.json取消所有运行的任务
这里可以将上面启动的所有jobs都可以取消:
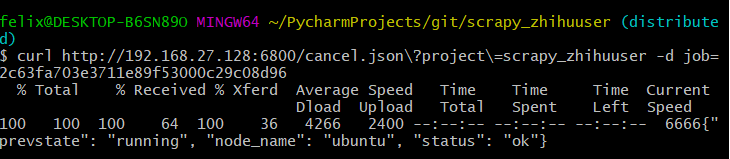
这样当我们再次通过页面查看,就可以看到所有的任务都是finshed状态:
我相信看了上面这几个方法你一定会觉得真不方便还需要输入那么长,所以有人替你干了件好事把这些API进行的再次封装:
--》GitHub地址
四:关于python-scrapyd-api
该模块可以让我们直接在python代码中进行上述那些api的操作
首先先安装该模块:pip install python-scrapyd-api
使用方法如下,这里只演示了简单的例子,其他方法其实使用很简单按照规则写就行:

from scrapyd_api import ScrapydAPI
scrapyd = ScrapydAPI('http://192.168.1.9:6800')
res = scrapyd.list_projects()
res2 = scrapyd.list_jobs('zhihu_user')
print(res)
print(res2)
Cancel a scheduled job
scrapyd.cancel('project_name', '14a6599ef67111e38a0e080027880ca6')
Delete a project and all sibling versions
scrapyd.delete_project('project_name')
Delete a version of a project
scrapyd.delete_version('project_name', 'version_name')
Request status of a job
scrapyd.job_status('project_name', '14a6599ef67111e38a0e080027880ca6')
List all jobs registered
scrapyd.list_jobs('project_name')
List all projects registered
scrapyd.list_projects()
List all spiders available to a given project
scrapyd.list_spiders('project_name')
List all versions registered to a given project
scrapyd.list_versions('project_name')
Schedule a job to run with a specific spider
scrapyd.schedule('project_name', 'spider_name')
Schedule a job to run while passing override settings
settings = {'DOWNLOAD_DELAY': 2}
Schedule a job to run while passing extra attributes to spider initialisation
scrapyd.schedule('project_name', 'spider_name', extra_attribute='value')

 浙公网安备 33010602011771号
浙公网安备 33010602011771号