爬虫(十六):scrapy爬取知乎用户信息
一:爬取思路
首先我们应该找到一个账号,这个账号被关注的人和关注的人都相对比较多的,就是下图中金字塔顶端的人,然后通过爬取这个账号的信息后,再爬取他关注的人和被关注的人的账号信息,然后爬取被关注人的账号信息和被关注信息的关注列表,爬取这些用户的信息,通过这种递归的方式从而爬取整个知乎的所有的账户信息。整个过程通过下面两个图表示:


二:爬虫过程分析
这里我们找的账号地址是:https://www.zhihu.com/people/excited-vczh/answers
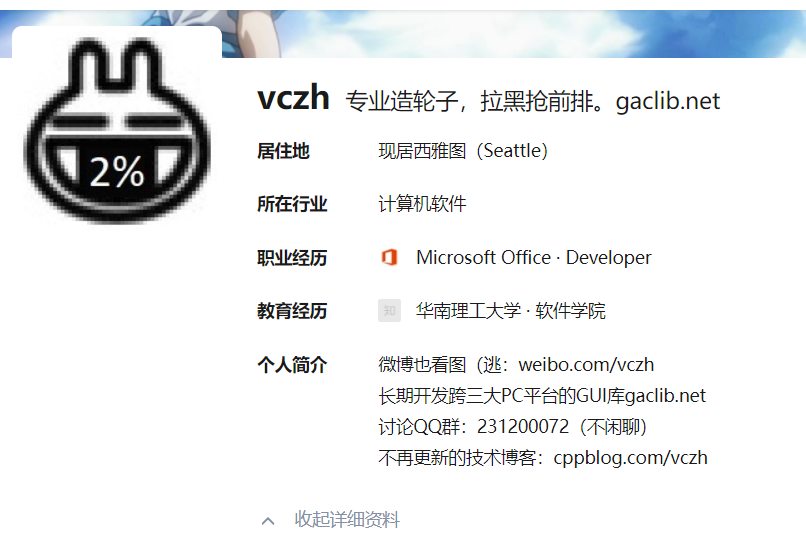
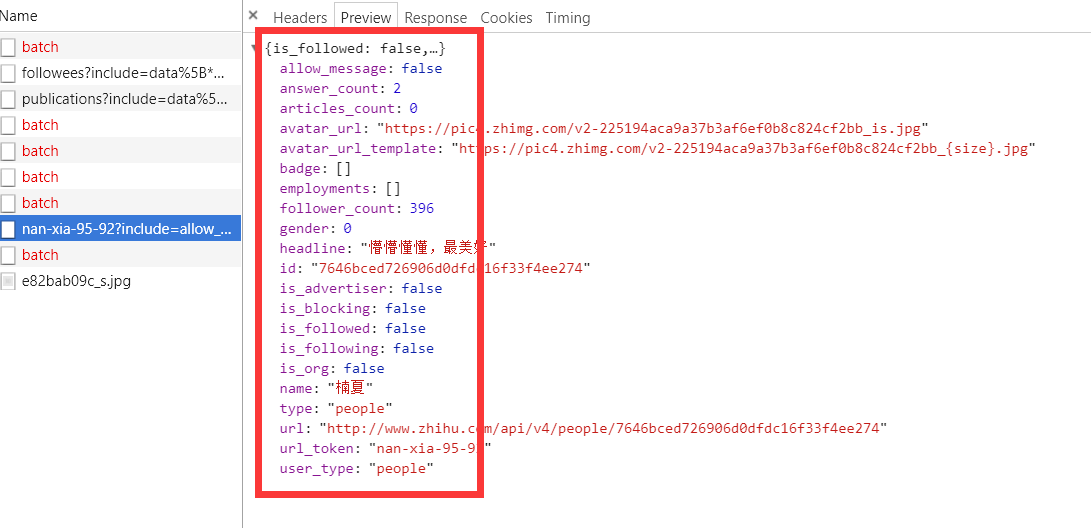
下图是大V的主要信息:
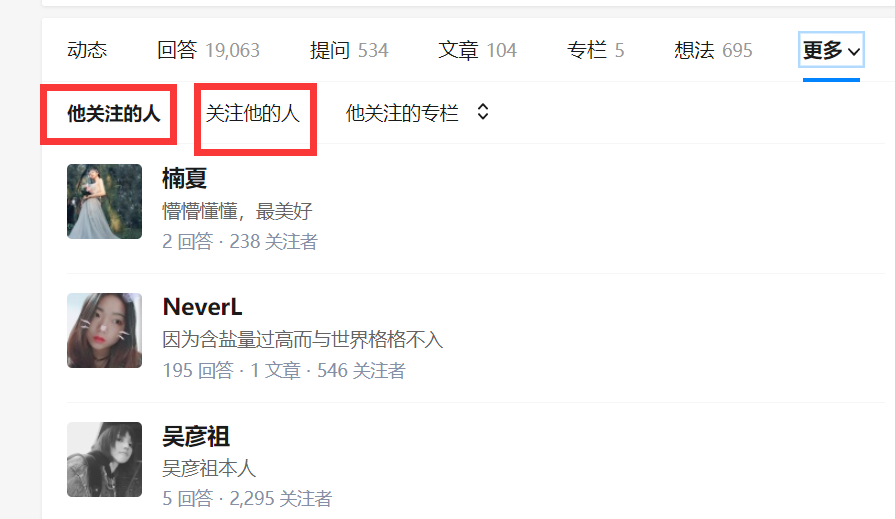
然后我们获取他关注的人和关注他的人的信息:
这里我们需要通过抓包分析如果获取这些列表的信息以及用户的个人信息内容
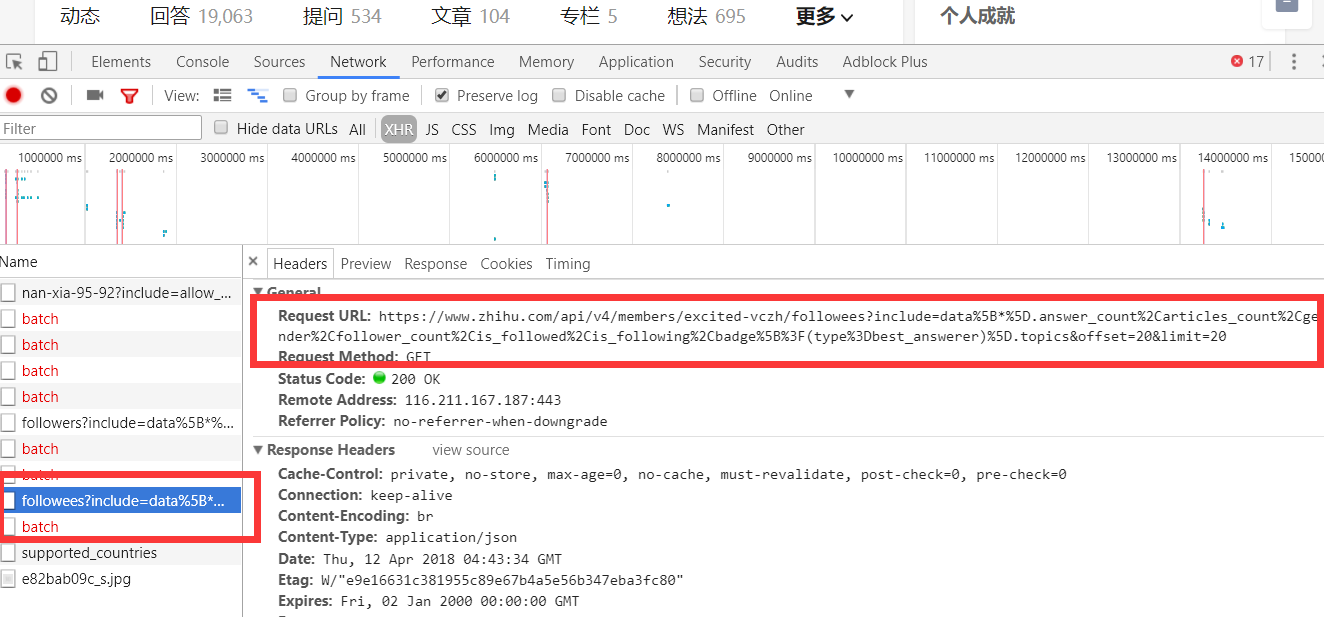
当我们查看他关注人的列表的时候我们可以看到他请求了如下图中的地址,并且我们可以看到返回去的结果是一个json数据,而这里就存着一页关乎的用户信息。
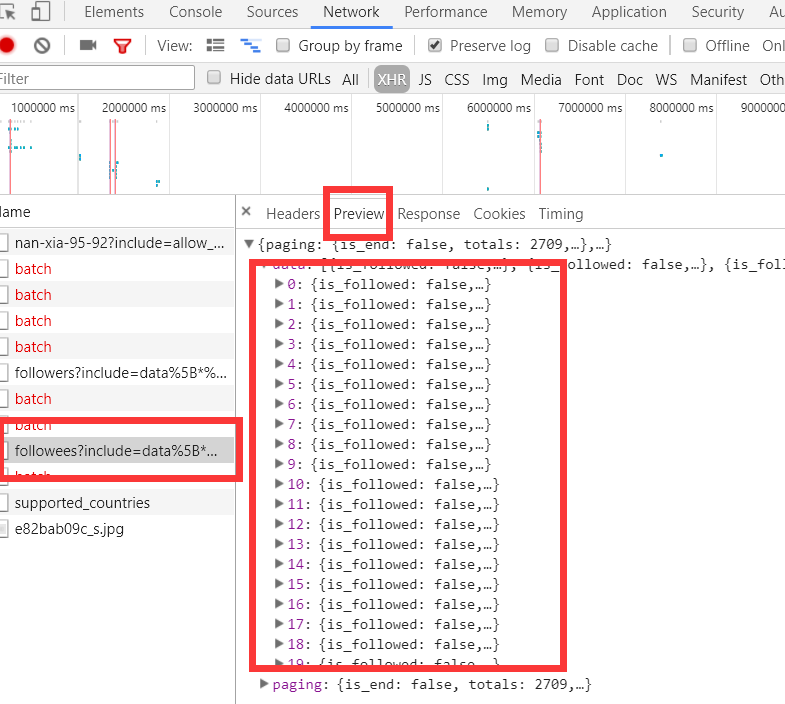
上面虽然可以获取单个用户的个人信息,但是不是特别完整,这个时候我们获取一个人的完整信息地址是当我们将鼠标放到用户名字上面的时候,可以看到发送了一个请求:

我们可以看这个地址的返回结果可以知道,这个地址请求获取的是用户的详细信息:
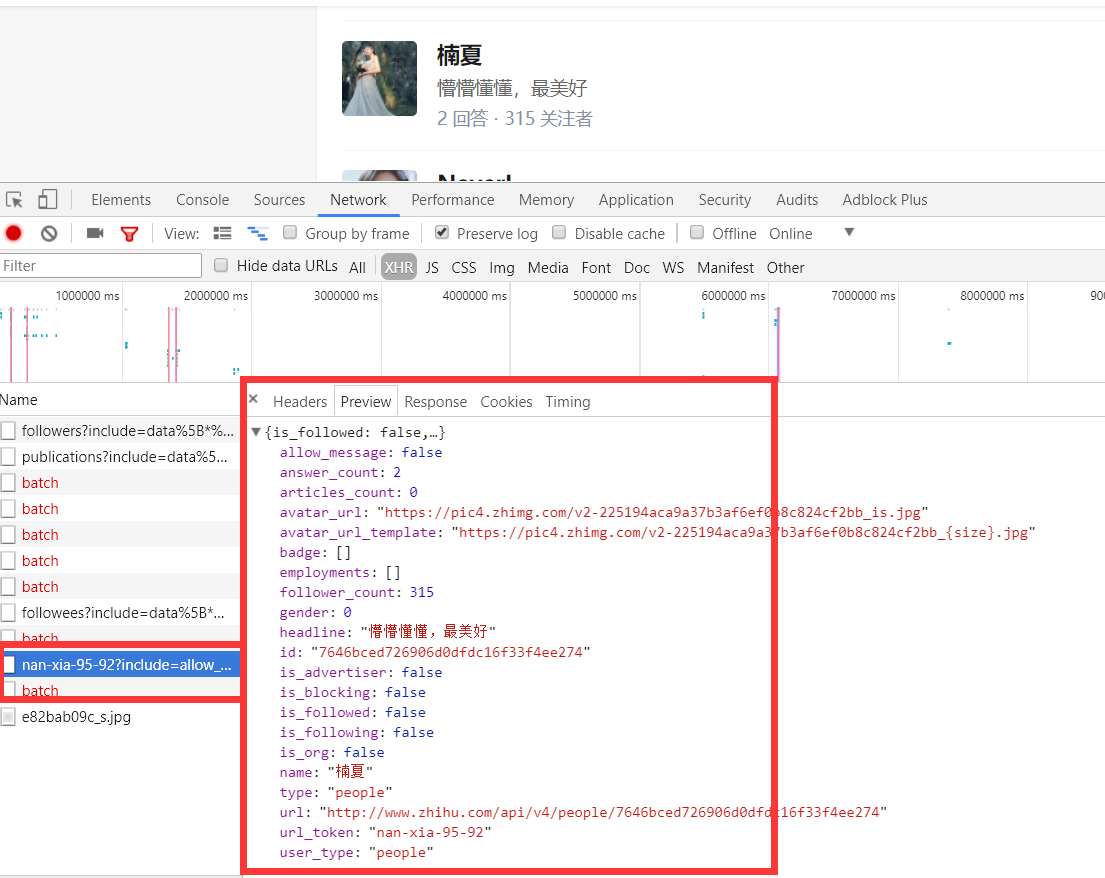
通过上面的分析我们知道了以下两个地址:
1关注列表:https://www.zhihu.com/api/v4/members/excited-vczh/followees?include=data%5B*%5D.answer_count%2Carticles_count%2Cgender%2Cfollower_count%2Cis_followed%2Cis_following%2Cbadge%5B%3F(type%3Dbest_answerer)%5D.topics&offset=0&limit=20
2、详情信息:https://www.zhihu.com/api/v4/members/nan-xia-95-92?include=allow_message%2Cis_followed%2Cis_following%2Cis_org%2Cis_blocking%2Cemployments%2Canswer_count%2Cfollower_count%2Carticles_count%2Cgender%2Cbadge%5B%3F(type%3Dbest_answerer)%5D.topics
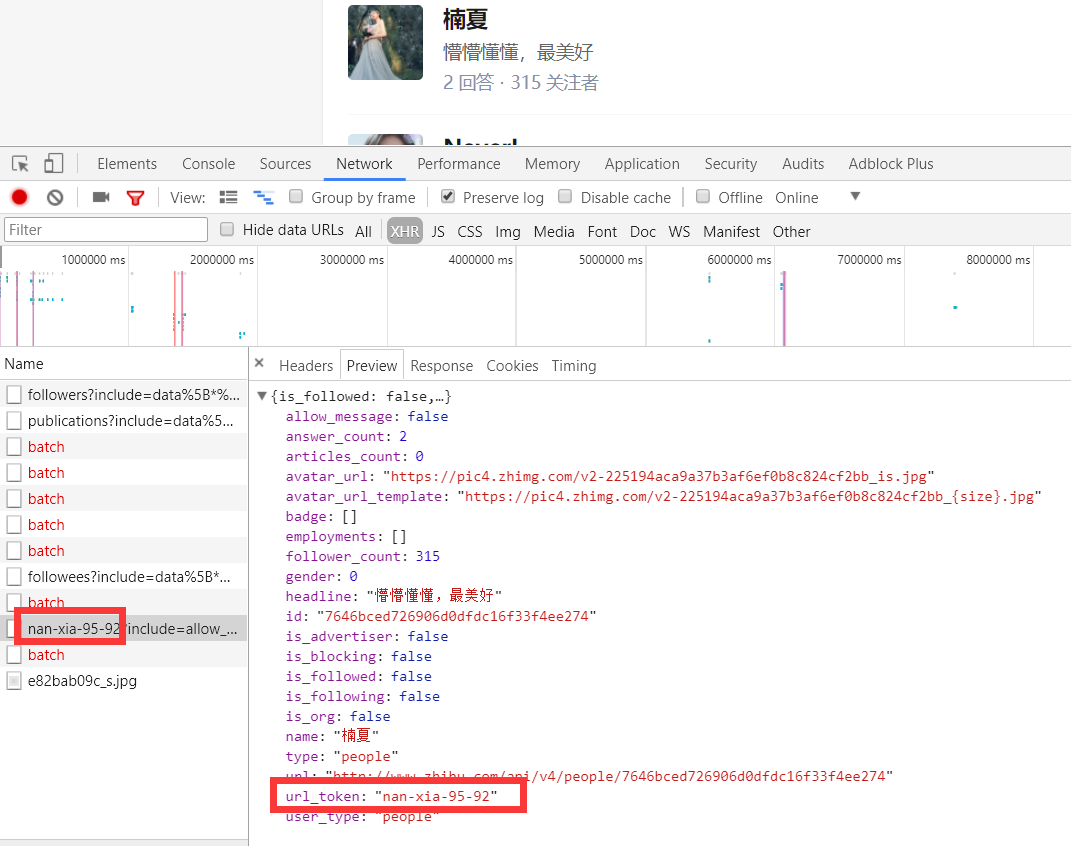
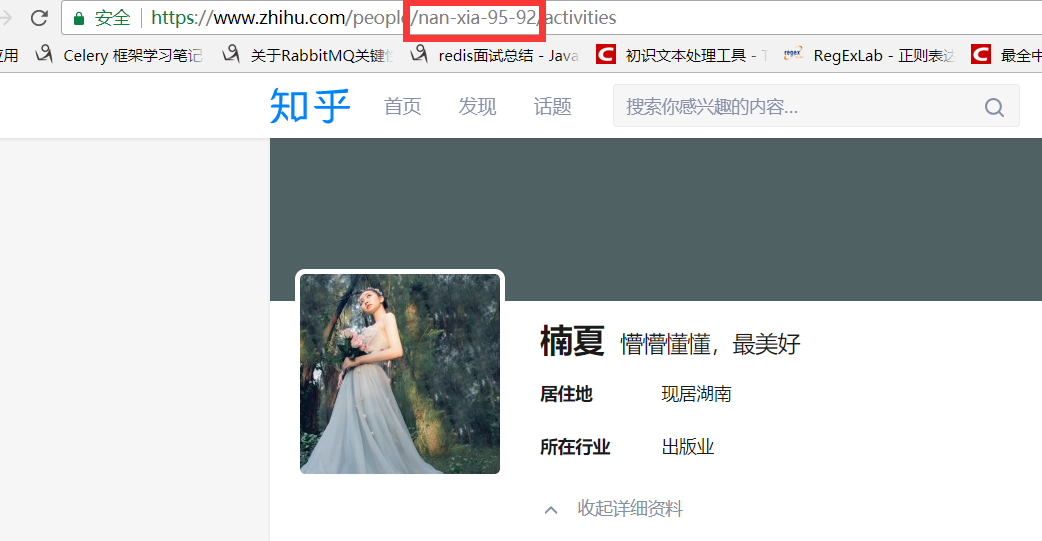
这里我们可以从请求的这两个地址里发现一个问题,关于用户信息里的url_token其实就是获取单个用户详细信息的一个凭证也是请求的一个重要参数,并且当我们点开关注人的的链接时发现请求的地址的唯一标识也是这个url_token。
三:创建项目实战
通过命令创建项目
scrapy startproject zhihu_user
cd zhihu_user
scrapy genspider zhihu zhihu.com
创建好后用pycharm打开:
更改settings文件:
# 是否遵循爬取规则,我们改成False
ROBOTSTXT_OBEY = False
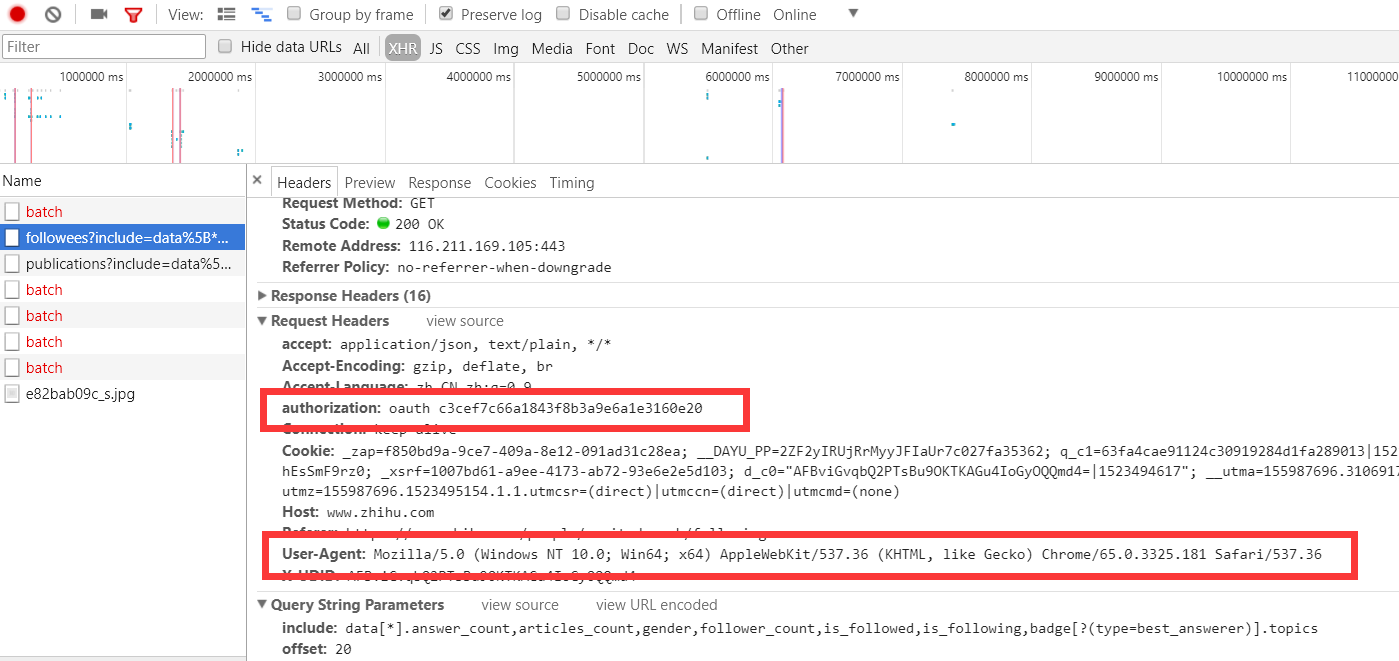
# 添加请求头信息,因为知乎默认检测请求头的
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36',
'authorization': 'oauth c3cef7c66a1843f8b3a9e6a1e3160e20',
}
四:代码实现
(1):items中的代码主要是我们要爬取的字段的定义
import scrapy class UserItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() id = scrapy.Field() name = scrapy.Field() allow_message = scrapy.Field() answer_count = scrapy.Field() articles_count = scrapy.Field() avatar_url = scrapy.Field() avatar_url_template = scrapy.Field() badge = scrapy.Field() employments = scrapy.Field() follower_count = scrapy.Field() gender = scrapy.Field() headline = scrapy.Field() is_advertiser = scrapy.Field() is_blocking = scrapy.Field() is_followed = scrapy.Field() is_following = scrapy.Field() is_org = scrapy.Field() type = scrapy.Field() url = scrapy.Field() url_token = scrapy.Field() user_type = scrapy.Field()
(2):spiders中的主要代码
# -*- coding: utf-8 -*- import json import scrapy from scrapy_zhihuuser.items import UserItem class ZhihuSpider(scrapy.Spider): name = 'zhihu' allowed_domains = ['zhihu.com'] start_urls = ['http://zhihu.com/'] # 起始的大V账号 start_user = 'excited-vczh' # 这里把查询的参数单独存储为user_query,user_url存储的为查询用户信息的url地址 user_url = 'https://www.zhihu.com/api/v4/members/{user}?include={include}' user_query = 'allow_message,is_followed,is_following,is_org,is_blocking,employments,answer_count,follower_count,articles_count,gender,badge[?(type=best_answerer)].topics' # #follows_url存储的为关注列表的url地址,fllows_query存储的为查询参数。这里涉及到offset和limit是关于翻页的参数,0,20表示第一页 follows_url = 'https://www.zhihu.com/api/v4/members/{user}/followers?include={include}&offset={offset}&limit={limit}' follows_query = 'data[*].answer_count,articles_count,gender,follower_count,is_followed,is_following,badge[?(type=best_answerer)].topics' # #followers_url是获取粉丝列表信息的url地址,followers_query存储的为查询参数。 followers_url = 'https://www.zhihu.com/api/v4/members/{user}/followees?include={include}&offset={offset}&limit={limit}' followers_query = 'data[*].answer_count,articles_count,gender,follower_count,is_followed,is_following,badge[?(type=best_answerer)].topics' # 第一次访问的方法重写 def start_requests(self): """ 这里重写了start_requests方法,分别请求了用户查询的url和关注列表的查询以及粉丝列表信息查询 :return: """ yield scrapy.Request(self.user_url.format(user=self.start_user, include=self.user_query), callback=self.parse_user) yield scrapy.Request( self.follows_url.format(user=self.start_user, include=self.follows_query, offset=0, limit=20), callback=self.parse_follows) yield scrapy.Request( self.follows_url.format(user=self.start_user, include=self.followers_query, offset=0, limit=20), callback=self.parse_followers) def parse_user(self, response): """ 因为返回的是json格式的数据,所以这里直接通过json.loads获取结果 :param response: :return: """ result = json.loads(response.text) item = UserItem() # 这里循环判断获取的字段是否在自己定义的字段中,然后进行赋值 for field in item.fields: if field in result.keys(): item[field] = result.get(field) # 这里在返回item的同时返回Request请求,继续递归拿关注用户信息的用户获取他们的关注列表 yield item yield scrapy.Request( self.follows_url.format(user=result.get("url_token"), include=self.follows_query, offset=0, limit=20), callback=self.parse_follows) yield scrapy.Request( self.followers_url.format(user=result.get("url_token"), include=self.followers_query, offset=0, limit=20), callback=self.parse_followers) def parse_follows(self, response): # 用户关注列表的解析,这里返回的也是json数据 这里有两个字段data和page,其中page是分页信息 results = json.loads(response.text) if 'data' in results.keys(): for result in results.get('data'): yield scrapy.Request(self.user_url.format(user=result.get('url_token'), include=self.user_query), self.parse_user) # 这里判断page是否存在并且判断page里的参数is_end判断是否为False,如果为False表示不是最后一页,否则则是最后一页 if 'paging' in results.keys() and results.get('paging').get('is_end') == False: next_page = results.get('paging').get('next') # 获取下一页的地址然后通过yield继续返回Request请求,继续请求自己再次获取下页中的信息 yield scrapy.Request(next_page, self.parse_follows) def parse_followers(self, response): """ 这里其实和关乎列表的处理方法是一样的 用户粉丝列表的解析,这里返回的也是json数据 这里有两个字段data和page,其中page是分页信息 :param response: :return: """ results = json.loads(response.text) if 'data' in results.keys(): for result in results.get('data'): yield scrapy.Request(self.user_url.format(user=result.get('url_token'), include=self.user_query), self.parse_user) if 'paging' in results.keys() and results.get('paging').get('is_end') == False: next_page = results.get('paging').get('next') yield scrapy.Request(next_page, self.parse_followers)
关于上面爬虫的简单描述:
1. 当重写start_requests,一会有三个yield,分别的回调函数调用了parse_user,parse_follows,parse_followers,这是第一次会分别获取我们所选取的大V的信息以及关注列表信息和粉丝列表信息
2. 而parse分别会再次回调parse_follows和parse_followers信息,分别递归获取每个用户的关注列表信息和分析列表信息
3. parse_follows获取关注列表里的每个用户的信息回调了parse_user,并进行翻页获取回调了自己parse_follows
4. parse_followers获取粉丝列表里的每个用户的信息回调了parse_user,并进行翻页获取回调了自己parse_followers
(3):关于数据存储到mongodb
更改pipeline代码:
import pymongo class MongoPipeline(object): collection_name = 'scrapy_items' def __init__(self, mongo_uri, mongo_db): self.mongo_uri = mongo_uri self.mongo_db = mongo_db @classmethod def from_crawler(cls, crawler): return cls(
# 在settings中定义数据库相关的操作 mongo_uri=crawler.settings.get('MONGO_URI'), mongo_db=crawler.settings.get('MONGO_DATABASE', 'items') ) def open_spider(self, spider): self.client = pymongo.MongoClient(self.mongo_uri) self.db = self.client[self.mongo_db] def close_spider(self, spider): self.client.close() def process_item(self, item, spider): self.db['user'].update({'url_token': item['url_token']}, {'$set': item}, True) # 更新去重 # self.db[self.collection_name].insert_one(dict(item)) return item
项目代码--》GitHub地址

 浙公网安备 33010602011771号
浙公网安备 33010602011771号