[ASP.NET]从ASP.NET Postback机制,到POST/GET方法
写这篇博客的起源来自于自己最近在学习ASP.NET时对于 PostBack机制的困惑。因为自己在解决困惑地同时,会不断产生新的疑问,因此博客最后深入到了http 包的格式和Internet所使用的TCP/IP模型,算是来了一堂基础复习课。但我相信这些基础的牢固性,会影响到web方向的深入学习,因此整理成文,便于复习,便于探讨。
写博的时候并没有将http协议包格式等底层的东西调整到最前面写,因为我觉得既然我是这样思考的,何不这样呈现?为了便于描述,我用下图这棵树表示写这篇博文的思路,IsPostBack是表面的引起疑问的叶子,顺着这片叶子,可以逐渐追溯到http协议这个树干。“Post与Get方法”那一块被安排在树干上,是因为从这里开始,触及了Web开发的主体;枝叶上的ASP.NET部分,只是基于这个主体又加入自己的技术的延伸。别的技术比如JSP,Struts等Java方向的技术,也是基于这个主体的另一种技术方向的延伸,因此它们都会像树枝一样,从主干上发散开。
博文中有任何觉得不对的地方,欢迎在留言中和我探讨。毕竟我也只是刚接触Web不久的Fresh Man,行文之时,心下惴惴,因此欢迎指出错误和讨论。

PostBack机制
什么是Postback?IsPostBack的作用是什么?
PostBack机制是ASP.NET特有的机制,为什么说特有,我们从web请求和响应说起。

web的基本原理就是请求和响应。以asp为例,Browser端的HTML文本,以及javascript代码,运行后向server端发送request,server端的.asp脚本,接受request,处理后发出respond。这种server端script和client端script交互,完成一次次对于用户操作(提交表单,载入新的URL)的响应。
以一个html文件和asp文件为例:
html代码:
<!DOCtype html PUBLIC "-//W3C//DTD XhTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> <html xmlns="http://www.w3.org/1999/xhtml"> <head><title>order</title></head> <body> <h2>Form Example</h2> <p> Please input and submit <form method="POST" ACTION="Response.asp"> <p> 姓: <input NAME="fname" SIZE="48"/> <p> 名: <input NAME="lname" SIZE="48"/> <p> 称呼: <input NAME="title" type=RADIO VALUE="先生"/>先生 <input NAME="title" type=RADIO VALUE="女士"/>女士 <p><input type=SUBMIT VALUE="提交"/><input type=RESET VALUE="清除"/> </form> </body> </html>
Response.asp脚本代码(VB语言)
<HTML> <HEAD></HEAD> <BODY> <% Title = Request.Form("title") LastName = Request.Form("lname") If Title = "先生" Then Response.Write LastName & "先生" ElseIf Title = "女士" Then Response.Write LastName & "女士" Else Response.Write Request.Form("fname") & " " & LastName End If %> </BODY> </HTML>
可以看到HTML文件的form控件中,"action"属性指定了form提交后处理它的Server端脚本。
而在ASP.NET系统中,我们没有Client端和Server端脚本,我们只有aspx文件,而aspx也会被Render为HTML,在Client端通过浏览器显示,因为浏览器只能识别HTML标签。
下面的例子引自Artech的浅谈ASP.NET的Postback,这篇文章讲解了Postback的实现方式,简单说来:Render之后的HTML会自动加入一个form,其中用hidden的input来存储id和事件参数。在__Postback这个函数中,form中的内容会被提交。Artech所给的aspx代码在Browser端的呈现出来的源码如下:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> <html xmlns="http://www.w3.org/1999/xhtml"> <head> <title> Test Page </title> </head> <body> <form name="form1" method="post" action="Default.aspx" id="form1"> <div> <input type="hidden" name="__EVENTTARGET" id="__EVENTTARGET" value="" /> <input type="hidden" name="__EVENTARGUMENT" id="__EVENTARGUMENT" value="" /> <input type="hidden" name="__VIEWSTATE" id="__VIEWSTATE" value="/wEPDwUKMTA0NDQ2OTE5OWRk281L4eAk7iZT10hzg+BeOyoUWBQ=" /> </div> <script type="text/javascript"> <!-- var theForm = document.forms['form1']; if (!theForm) { theForm = document.form1; } function __doPostBack(eventTarget, eventArgument) { if (!theForm.onsubmit || (theForm.onsubmit() != false)) { theForm.__EVENTTARGET.value = eventTarget; theForm.__EVENTARGUMENT.value = eventArgument; theForm.submit(); } } </script> <div> <span id="LabelMessage" style="color:Red;"></span> </div> <div> <input type="submit" name="Button1" value="Button1" id="Button1" /> <input type="button" name="Button2" value="Button2" onclick="javascript:__doPostBack('Button2','')" id="Button2" /> <input type="button" name="Button3" value="Button3" onclick="javascript:__doPostBack('Button3','')" id="Button3" /> </div> </form> </body> </html>
以上代码在Artech博文中也可以找到,我把它贴过来,以方便引述。这段代码是Default.aspx被render到browser端的html源码,Postback的实现机制就是定义了一个form,这个Form中包含隐藏的input,从而保存需要post的值,那么,向哪里post?Form中"action"属性指定了post的目标,那这里呢?我们可以看到其值为"Default.aspx",也就是它自己。这和上面那个ASP的例子中是不同的。
我的理解是:所谓Postback,是指在ASP.NET机制中,不是Client端发post请求到server端脚本,在这个机制中,aspx被render到browser后,其Form的post目标依然是这个aspx。Postback由此得名,因为post回来了。。
因此当我们触发网页的按钮时,若此按钮涉及到后台操作(在后端有C#响应代码,而非仅仅调用前端javascript函数),aspx页面便会重新加载,因为Postback触发了它。(这句话待商榷,我对Postback与page life cycle了解再深刻些后,会再编辑这句话)。
这个机制所需要解决的第一个问题是:当开发人员编写代码时,aspx的加载有两种原因:点击按钮触发post来让aspx加载;用户输入url来加载aspx。对于不同的原因,可能开发人员希望代码进入不同的处理逻辑。IsPostback这个ASP.NET所给的变量,就是用来给developer确定是否这个网页是因为postback而加载,而是通过输入url或者刷新页面的方式来加载。
最简单的例子,在Page_Load()方法里经常会 if(!IsPostBack) BindForm();//给表单所有控件赋值的方法。意思是提交后我就不绑定表单了,而是走Click的具体事件方法。
而IsPostBack是何时被赋值的,ASP.NET代码中是根据什么条件来判断是否是postback的网页,这一个树枝暂时还没有研究下去,如果能有前辈能在留言中给我一些线索的话,感激不尽 :)
有关于Page_Load()方法,它是ASP.NET中的网页载入过程中page load事件的默认响应函数,具体请参见:
ASP.NET 页生命周期概述 以及 [ASP.NET]Page Life Cycle整理
因此Postback的机制本质实现其实是form的post,那么post和get,这些具体是什么?
POST与GET方法
正如之前所说,web实际就是request与respond的交互,那么,这些request与respond,其实就是http包。
对于一个Request,它可能不仅仅是一个要求载入页面的request,也可能是要求发送一些数据的request,或者要求删除服务端一些数据的request,如何区分这些request?http给request定义了四个谓词:POST,GET,PUT,DELETE。从名字就可以看出来他们的功用,分别对应着改,查,增,删。
而最常使用的是GET与POST。
他们的共同点和区别在哪里?
共同点是:GET POST其实都可以实现向服务器传送数据。在HTML中,本身表单form的提交就有两种方式,一种是get的方法,一种是post 的方法。而这两种方法保存参数的方式是不同的,如果使用Fiddler或其他的http包查看工具,可以发现post方法提交的Form,其参数存在body中,而get方法提交的form,其参数则直接加入到url的后面。
通过包来看两者之间本质的差别的例子,可以参见淺談 HTTP Method:表單中的 GET 與 POST 有什麼差別?
通过输入url来访问页面,其request都是get。
两者特性上的差别:form方式因为是将内容放在body中发过去,而get仅仅是发一个get请求过去,内容在url中,因此速度比post快,而安全性则低于post。
GET的response会被cache,而POST的response不会。因为GET的初衷就是获取内容,因此可以通过cache来存储不变的内容,而POST则是用来提交内容,其响应基于所提交的内容可能不断变化。
两者之间其他差别参见下图,图来自[HTTP]Http GET、POST Method

有一篇文章提到了在使用Ajax时,POST会比GET慢数倍,各位有兴趣可以看一下:打破沙鍋-AJAX POST比GET效率差?
之前提到既然request和response实际就是HTTP包,那POST与GET这些谓词又是如何在包中呈现的?
POST与GET报文格式
以Artech的那个例子为例,那个例子如果运行起来,会看到三个按钮,点击其中一个,会显示哪个按钮的click被fire了:

点击Button3后,request与response在fiddler中的内容如图:

在fiddle中,可以看到POST就出现在Request的第一行中。
Response的Header的内容是:HTTP/1.1 200 OK
一个http请求报文的格式如下图 (图片来自计算机网络应用层之HTTP协议)

分为请求行(Request line),首部行(Header line),空行(Brank line)和实体(body),谓词方法的位置就在请求行的开头。
HTTP响应respond的报文格式如下:

其中200为状态码,表示请求成功。返回内容在实体中呈现,比如之前fiddler的截图,响应包中的内容就是原先那个HTML的内容,也就是说,浏览器收到这个response后,用户会看到整个页面被刷新了一下。
我们知道了http的报文格式,那什么是HTTP协议?
HTTP协议
HTTP是HyperText Transfer Protocol即超文本传输协议的缩写,是Web应用层协议之一。
在说这个之前,先提几个HTTP的特性,这部分引用了Tank的 HTTP协议详解 中部分内容
HTTP协议是无状态的:同一个客户端的这次请求和上次请求是没有对应关系,对http服务器来说,它并不知道这两个请求来自同一个客户端。 为了解决这个问题, Web程序引入了Cookie机制来维护状态。引入了ViewState来存储控件内容或者用户自定义信息。
关于Cookie的介绍,读写方式,以及它在ASP.NET form authentication中所起的作用,参见:Fish Li的细说Cookie。
关于ViewState:我的理解是一种在用户端存储控件内容和一些开发人员自定义内容的机制。其实现方式是在用户端的HTML代码中插入名字为"__ViewState"的hidden input,那些需要存储的内容,都经过Base64编码后以字符串的形式存储在这个hidden input中。因为是以字符串的形式存储在客户端的HTML文件中,因此属于长期储存,不会自动过期或消失,用户甚至可以拷贝下来保存。更多内容,参见 [.NET] ASP.NET 狀態管理(State Management):ViewState。
打开一个网页需要浏览器发送很多次Request:
1. 当你在浏览器输入URL http://www.cnblogs.com 的时候,浏览器发送一个Request去获取 http://www.cnblogs.com 的html. 服务器把Response发送回给浏览器.
2. 浏览器分析Response中的 HTML,发现其中引用了很多其他文件,比如图片,CSS文件,JS文件。
3. 浏览器会自动再次发送Request去获取图片,CSS文件,或者JS文件。
4. 等所有的文件都下载成功后。 网页就被显示出来了。
由于HTTP是使用TCP作为其运输协议的,因此http协议也需要连接,也需要三次握手的过程。
TCP连接分为持久连接和非持久连接:
在非持久连接的情况下,服务器在发送响应后,关闭TCP连接。我们定义往返时间RTT为一个小分组从客户机到服务器再回到客户所花费的时间。所以RTT包括分组传播时延、排列时延以及分组处理时延。
若http采用非持久连接时,我们可以估算出完成一次传输所消耗的时间:完成了三次握手的前两部分后,客户机将三次握手的第三部分(确认)与一个HTTP请求报文结合起来发送到该TCP连接。一旦请求报文到达服务器,服务器向该TCP连接发送HTML文件。从上面的描述,我们可以知道,对于一个非持久连接,请求一个HTTP请求/响应需要的总时间为两个RTT+服务器传输HTML文件的时间,也就是两个来回所耗的时间加上传输时间。
网络分层结构
我们知道互联网的框架主要是两种:OSI的七层框架,和TCP/IP体系结构。而Internet网络体系结构以TCP/IP为核心。基于TCP/IP的参考模型将协议分成四个层次。
这两种模型的对应关系如图,图片来自网络互联参考模型(详解)

而我们之前应用层的http报文,从最高层往下经历层层封装,最后到达最底层转换为01流。发往目的地,中间会经过交换机和路由器的中转,解包,确认下一个转发地址后再次封包转发。如下图 (图片来自网络互联参考模型(详解))
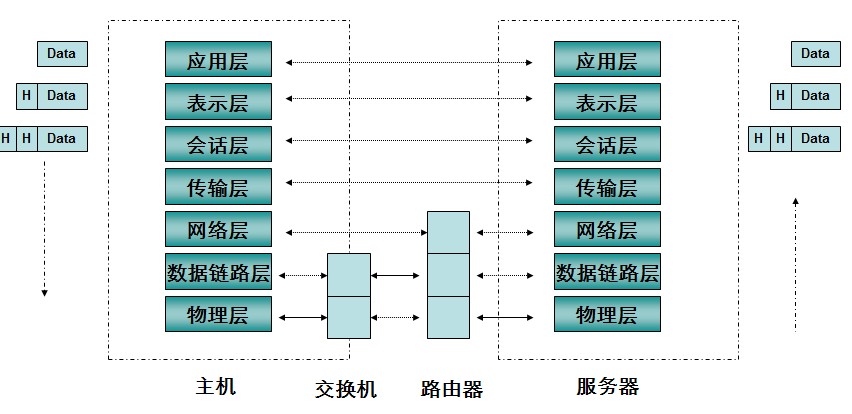
------------------------------------------------
Felix原创,转载请注明出处,感谢博客园!
posted on 2014-01-06 11:52 Felix Fang 阅读(8928) 评论(10) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号