
TDH大数据平台数据入库方案
一、数据入库方式
目前批量数据入库TDH大数据平台主要有如下几种方式
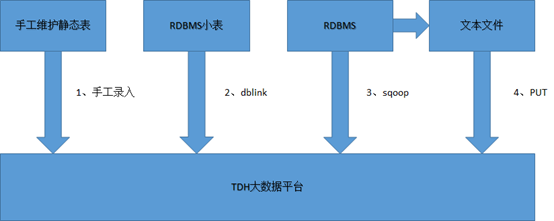
1、手工入录
一些静态表手工维护的数据,可以直接采用insert导入,或者使用waterdrop客户端工具导入,只适用少数据量的导入和更新
2、dblink
TDH inceptor支持建立dblink直接连接db2,oracle,mysql等关系数据库,对于一些数据量不大的静态表,手工维护的表,可以通过建立dblink的方式获取数据
优点:简单方便
缺点:1)对大数据量的表,效率较差
2)初次使用相应数据库的dblink时,需要导入对应数据库的驱动jar包到 inceptor 的lib目录,重启才能生效
3、sqoop直接抽取
可以使用sqoop的方式从RDBMS关系型数据库抽取数据到TDH大数据平台
优点:1)支持各种类型的关系型数据库;
2)数据可以直接导入到HDFS;
缺点:1)sqoop单map导入数据不快,多map导入速度快,但是同时导出的表多时,关系型数据库需要抗压
2)当生产系统的数据导出要给多个系统使用或者数据重采,每个系统都需要再次从源系统抽取数据,源系统压力较大
3)对ORACLE的colb,blob等字段,导出速度慢
4)RDBMS-文件服务器-TDH平台
先使用相应的数据库导数工具导出成文本文件,然后把文本文件上传到TDH大数据平台
优点:1)使用数据库相对应的导数工具,数据导出速度快,put到hdfs数据也快 特别适合数据量大,导出表多的情况
2)当有多个系统需要使用源系统导出的数据时,可以直接共享导出的文件
3)可以制定统一的数据入库规范
缺点:1)需要文件采集服务器,增加服务器和存储成本
二、数据入库流程
3,4 两种是目前主要采用的数据入库方案,详细流程见下图
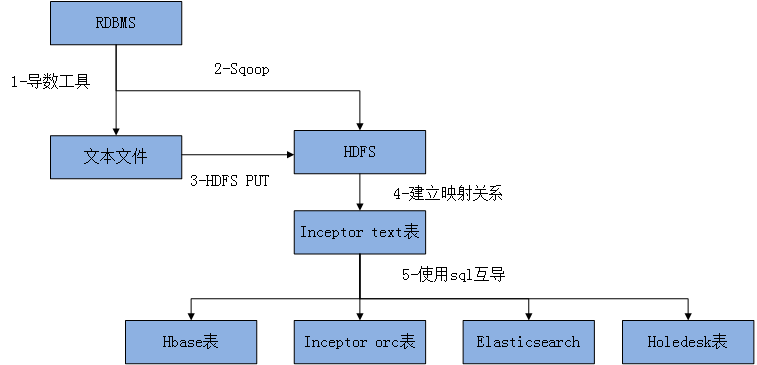
流程1
1)关系型数据库通过导数工具导出文件到采集服务器
2)采集服务把本地文件put到HDFS上
3)对PUT到hdfs上的文件建立inceptor text映射表
4) 此时可以通过sql的方式根据不同的需要把数据导入 TDH的不同类型的表里了
注:
inceptor是一个强大的分布式数据库引擎,各个不同类型表的数据可以通过inceptor使用SQL的方式互相导,简单方便快捷
流程2
1)直接通过sqoop 把RDBMS中的数据导出成hdfs文件
2)对PUT到hdfs上的文件建立inceptor text映射表
3) 此时可以通过sql的方式根据不同的需要把数据导入 TDH的不同类型的表里了
流程3
如果是文本文件
参照流程1从第二步开始导入即可

