各种编码总结
1、不可逆编码方式
(1)MD4
MD4是麻省理工学院教授Ronald Rivest于1990年设计的一种信息摘要算法。它是一种用来测试信息完整性的密码散列函数的实行。其摘要长度为128位,一般128位长的MD4散列被表示为32位的十六进制数字。这个算法影响了后来的算法如MD5、SHA 家族和RIPEMD等。
MD4(123)=C58CDA49F00748A3BC0FCFA511D516CB
(2)MD5
MD5即Message-Digest Algorithm 5(信息-摘要算法5),用于确保信息传输完整一致。是计算机广泛使用的杂凑算法之一(又译摘要算法、哈希算法),MD5的作用是让大容量信息在用数字签名软件签署私人密钥前被"压缩"成一种保密的格式(就是把一个任意长度的字节串变换成一定长的十六进制数字串)。
对MD5算法简要的叙述可以为:MD5以512位分组来处理输入的信息,且每一分组又被划分为16个32位子分组,经过了一系列的处理后,算法的输出由四个32位分组组成,将这四个32位分组级联后将生成一个128位散列值。
MD5加密后所得到的通常是32位的编码,而在不少地方会用到16位的编码,16位加密就是从32位MD5散列中把中间16位提取出来!其实破解16位MD5散列要比破解32位MD5散列还慢,因为他多了一个步骤,就是使用32位加密后再把中间16位提取出来, 然后再进行对比,而破解32位的则不需要,加密后直接对比就可以了 。
16位:MD5(123)=AC59075B964B0715
32位:MD5(123)=202CB962AC59075B964B07152D234B70
(3)MD6 (了解)
MD6是一种算法。继MD5被攻破后,在Crypto2008上, Rivest提出了MD6算法,该算法的Block size为512 bytes(MD5的Block Size是512 bits), Chaining value长度为1024 bits, 算法增加了并行 机制,适合于多核CPU。
(4)SHA1
安全哈希算法(Secure Hash Algorithm)主要适用于数字签名标准 (Digital Signature Standard DSS)里面定义的数字签名算法(Digital Signature Algorithm DSA)。对于长度小于2^64位的消息,SHA1会产生一个160位的消息摘要。当接收到消息的时候,这个消息摘要可以用来验证数据的完整性。在传输的过程中,数据很可能会发生变化,那么这时候就会产生不同的消息摘要。 SHA1有如下特性:不可以从消息摘要中复原信息;两个不同的消息不会产生同样的消息摘要,(但会有1x10 ^ 48分之一的机率出现相同的消息摘要,一般使用时忽略)。
SH1(123)=40bd001563085fc35165329ea1ff5c5ecbdbbeef
(5)SHA2
SHA-224、SHA-256、SHA-384,和SHA-512并称为SHA-2。新的散列函数并没有接受像SHA-1一样的公众密码社区做详细的检验,所以它们的密码安全性还不被大家广泛的信任。虽然至今尚未出现对SHA-2有效的攻击,它的算法跟SHA-1基本上仍然相似;因此有些人开始发展其他替代的散列算法。
SHA224(123)= 78d8045d684abd2eece923758f3cd781489df3a48e1278982466017f
SHA256(123)= a665a45920422f9d417e4867efdc4fb8a04a1f3fff1fa07e998e86f7f7a27ae3
SHA384(123)= 9a0a82f0c0cf31470d7affede3406cc9aa8410671520b727044eda15b4c25532a9b5cd8aaf9cec4919d76255b6bfb00f
SHA(123)= 3c9909afec25354d551dae21590bb26e38d53f2173b8d3dc3eee4c047e7ab1c1eb8b85103e3be7ba613b31bb5c9c36214dc9f14a42fd7a2fdb84856bca5c44c2
(6)SHA3
由于近年来对传统常用Hash 函数如MD4、MD5、SHA0、SHA1、RIPENMD 等的成功攻击,美国国家标准技术研究所(NIST)在2005年、2006年分别举行了2届密码Hash 研讨会;同时于2007年正式宣布在全球范围内征集新的下一代密码Hash算法,举行SHA-3竞赛·新的Hash算法将被称为SHA-3,并且作为新的安全Hash标准,增强现有的FIPS 180-2标准。算法提交已于2008年10月结束,NIST 将分别于2009年和2010年举行2轮会议,通过2轮的筛选选出进入最终轮(final round)的算法,最后将在2012年公布获胜算法。公开竞赛的整个进程仿照高级加密标准AES 的征集过程。2012年10月2日,Keccak被选为NIST竞赛的胜利者, 成为SHA-3.。
SHA-3,之前名为Keccak算法,是一个加密杂凑算法。SHA-3并不是要取代SHA-2,因为SHA-2目前并没有出现明显的弱点。由于对MD5出现成功的破解,以及对SHA-0和SHA-1出现理论上破解的方法,NIST感觉需要一个与之前算法不同的,可替换的加密杂凑算法,也就是现在的SHA-3。
512位:SHA3(123)=8ca32d950873fd2b5b34a7d79c4a294b2fd805abe3261beb04fab61a3b4b75609afd6478aa8d34e03f262d68bb09a2ba9d655e228c96723b2854838a6e613b9d
SHA3
384位:SHA3(123)= 7dd34ccaae92bfc7eb541056d200db23b6bbeefe95be0d2bb43625113361906f0afc701dbef1cfb615bf98b1535a84c1
256位:SHA3(123)= 64e604787cbf194841e7b68d7cd28786f6c9a0a3ab9f8b0a0e87cb4387ab0107
224位:SHA3(123)=5c52615361ce4c5469f9d8c90113c7a543a4bf43490782d291cb32d8
64位:SHA3(123)= dc7ae5f796c6b703
(7)RIPEMD-160哈希加密算法
RIPEMD-160 是一个 160 位加密哈希函数。它旨在用于替代 128 位哈希函数 MD4、MD5 和 RIPEMD。RIPEMD 是在 EU 项目 RIPE(RACE Integrity Primitives Evaluation,1988-1992)的框架中开发的。
RIPEMD(123)=e3431a8e0adbf96fd140103dc6f63a3f8fa343ab
2、可逆编码方式
(1)url编码
url编码是一种浏览器用来打包表单输入的格式。浏览器从表单中获取所有的name和其中的值 ,将它们以name/value参数编码(移去那些不能传送的字符,将数据排行等等)作为URL的一部分或者分离地发给服务器。
http://www.xxx.com/index.php?parameter=123&code=del
http%3a%2f%2fwww.xxx.com%2findex.php%3fparameter%3d123%26code%3ddel
ASCll编码:
最早的计算机在设计时采用8个比特(bit)作为一个字节(byte),所以,一个字节能表示的最大的整数就是255(二进制11111111=十进制255),0 - 255被用来表示大小写英文字母、数字和一些符号,这个编码表被称为ASCII编码,比如大写字母A的编码是65,小写字母z的编码是122。
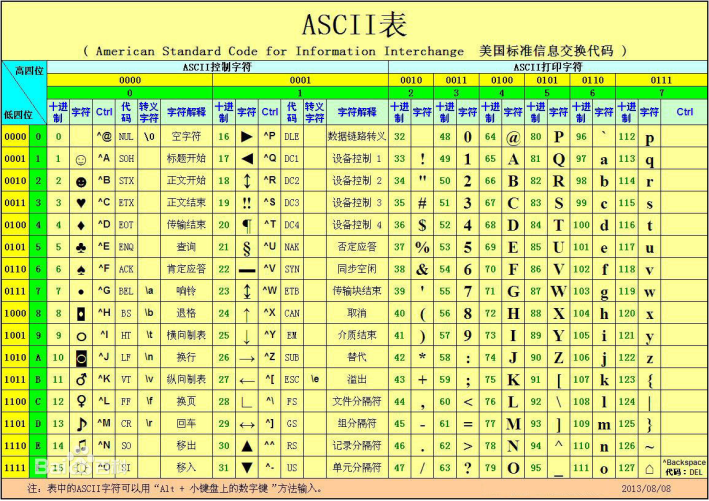
unicode编码:
Unicode 给所有的字符指定了一个数字用来表示该字符,Unicode通常用两个字节表示一个字符,原有的英文编码从单字节变成双字节,只需要把高字节全部填为0就可以。


UTF-8编码:
如果UNICODE字符由2个字节表示,则编码成UTF-8很可能需要3个字节。而如果UNICODE字符由4个字节表示,则编码成UTF-8可能需要6个字节。用4个或6个字节去编码一个UNICODE字符可能太多了,但很少会遇到那样的UNICODE字符。
UTF-8编码规则:如果只有一个字节则其最高二进制位为0;如果是多字节,其第一个字节从最高位开始,连续的二进制位值为1的个数决定了其编码的字节数,其余各字节均以10开头。UTF-8转换表表示如下:
|
Unicode/UCS-4 |
bit数 |
UTF-8 |
byte数 |
备注 |
|
0000 ~ 007F |
0~7 |
0XXX XXXX |
1 |
|
|
0080 ~ 07FF |
8~11 |
110X XXXX 10XX XXXX |
2 |
|
|
0800 ~ FFFF |
12~16 |
1110XXXX 10XX XXXX 10XX XXXX |
3 |
基本定义范围:0~FFFF |
|
1 0000 ~ 1F FFFF |
17~21 |
1111 0XXX 10XX XXXX 10XX XXXX 10XX XXXX |
4 |
Unicode6.1定义范围:0~10 FFFF |
|
20 0000 ~ 3FF FFFF |
22~26 |
1111 10XX 10XX XXXX 10XX XXXX 10XX XXXX 10XX XXXX |
5 |
说明:此非unicode编码范围,属于UCS-4 编码 早期的规范UTF-8可以到达6字节序列,可以覆盖到31位元(通用字符集原来的极限)。尽管如此,2003年11月UTF-8 被 RFC 3629 重新规范,只能使用原来Unicode定义的区域, U+0000到U+10FFFF。根据规范,这些字节值将无法出现在合法 UTF-8序列中 |
|
400 0000 ~ 7FFF FFFF |
27~31 |
1111 110X 10XX XXXX 10XX XXXX 10XX XXXX 10XX XXXX 10XX XXXX |
6 |
实际表示ASCII字符的UNICODE字符,将会编码成1个字节,并且UTF-8表示与ASCII字符表示是一样的。所有其他的UNICODE字符转化成UTF-8将需要至少2个字节。每个字节由一个换码序列开始。第一个字节由唯一的换码序列,由n位连续的1加一位0组成, 首字节连续的1的个数表示字符编码所需的字节数。
Unicode转换为UTF-8时,可以将Unicode二进制从低位往高位取出二进制数字,每次取6位,如上述的二进制就可以分别取出为如下示例所示的格式,前面按格式填补,不足8位用0填补。
注:Unicode转换为UTF-8需要的字节数可以根据这个规则计算:如果Unicode小于0X80(Ascii字符),则转换后为1个字节。否则转换后的字节数为Unicode二进制位数+3再除以5。
示例
UNICODE uCA(1100 1010) 编码成UTF-8将需要2个字节:
uCA -> C3 8A, 过程如下:
uCA(1100 1010)处于0080 ~07FF之间,从上文中的转换表可知对其编码需要2bytes,即两个字节,其对 应 UTF-8格式为: 110X XXXX10XX XXXX。从此格式中可以看到,对其编码还需要11位,而uCA(1100 1010)仅有8位,这时需要在其二进制数前补0凑成11位: 000 1100 1010, 依次填入110X XXXX 10XX XXXX的空位中, 即得 1100 0011 1000 1010(C38A)。
同理,UNICODE uF03F (1111 0000 0011 1111) 编码成UTF-8将需要3个字节:
u F03F -> EF 80 BF,对应格式为:1110XXXX10XX XXXX10XX XXXX,编码还需要16位,将1111 0000 0011 1111(F03F)依次填入,可得 1110 1111 1000 0000 1011 1111(EF 80 BF)。
|
Unicode 16进制 |
Unicode 2进制 |
bit数 |
UTF-8 2进制 |
UTF-8 16进制 |
|
CA |
1100 1010 |
8 |
1100 00111000 1010 |
C3 8A |
|
F0 3F |
11110000 0011 1111 |
16 |
111011111000 00001011 1111 |
EF 80 BF |
UTF-16编码:
UTF-16的大尾序和小尾序储存形式都在用。一般来说,以Macintosh制作或储存的文字使用大尾序格式,以Microsoft或Linux制作或储存的文字使用小尾序格式。
为了弄清楚UTF-16文件的大小尾序,在UTF-16文件的开首,都会放置一个U+FEFF字符作为Byte Order Mark(UTF-16LE以FF FE代表,UTF-16BE以FE FF代表),以显示这个文字档案是以UTF-16编码,其中U+FEFF字符在UNICODE中代表的意义是ZERO WIDTH NO-BREAK SPACE,顾名思义,它是个没有宽度也没有断字的空白。
UTF-32编码:
UTF-32 (或 UCS-4)是一种将Unicode字符编码的协定,对每一个Unicode码位使用恰好32位元。其它的Unicode transformation formats则使用不定长度编码。因为UTF-32对每个字符都使用4字节,就空间而言,是非常没有效率的。特别地,非基本多文种平面的字符在大部分文件中通常很罕见,以致于它们通常被认为不存在占用空间大小的讨论,使得UTF-32通常会是其它编码的二到四倍。虽然每一个码位使用固定长定的字节看似方便,它并不如其它Unicode编码使用得广泛。
Base64编码
计算机单位:
位:bit,是电子计算机中最小的数据单位。每一位的状态只能是0或1。
字节:Byte,8个二进制位构成1个"字节(Byte,可简写为B)",它是存储空间的基本计量单位。1个字节可以储存1个英文字母或者半个汉字,换句话说,1个汉字占据2个字节的存储空间。
字:"字"由若干个字节构成,字的位数叫做字长,不同档次的机器有不同的字长。例如一台8位机,它的1个字就等于1个字节,字长为8位。如果是一台16位机,那么,它的1个字就由2个字节构成,字长为16位。字是计算机进行数据处理和运算的单位。
KB:在一般的计量单位中,通常K表示1000。只是这时K表示1024,也就是2的10次 方。1KB表示1K个Byte,也就是1024个字节。1KB=1024B
1KB=1024B=210B
1MB=1024KB=1024*1024B=220B
1GB=1024MB=1024*2014KB=1024*1024*1024B=230B
1TB=1024GB=240B

